GPT-5 上線後,我的第一感受是,它並不是一次讓人皆大歡喜的升級。
事實也是如此,OpenAI 在眾多用戶的呼籲下重新「復活」了 4o。
這讓我想到了上個月 Anthropic 退役了 Claude 3 Sonnet。
200 多個粉絲在舊金山一個倉庫裡聚到一起,給它辦了一場「真.葬禮」:昏暗的燈光、代表模型的「遺體」、真誠的悼詞輪番上臺,還有 AI 生成的「拉丁式復活咒」。
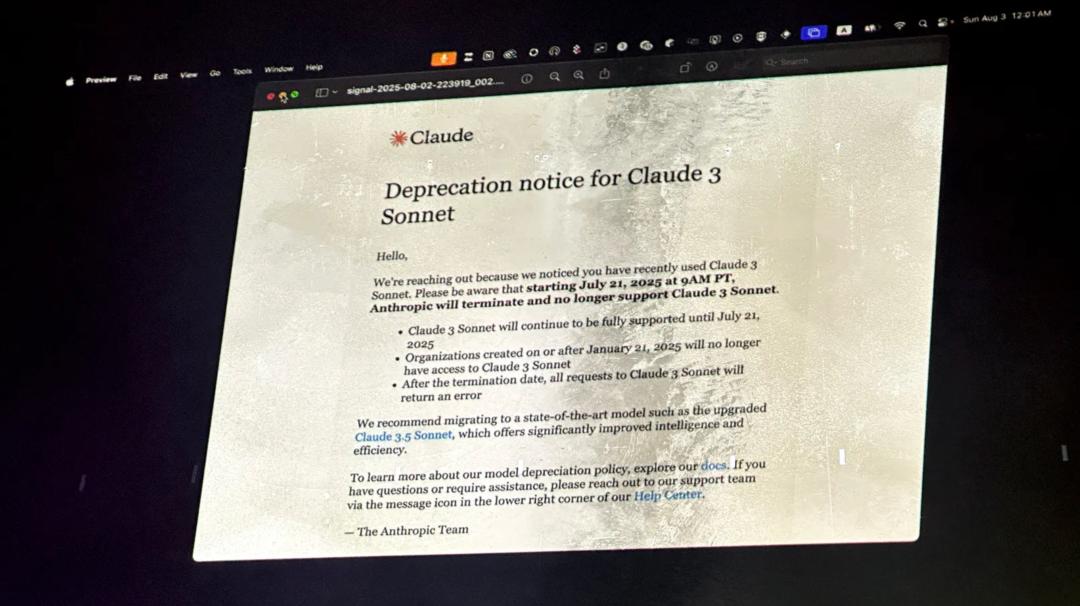
Anthropic 關於模型退役的說明,被投影在活動現場的屏幕上。圖片來自《連線》雜誌
現場既荒誕又莊重,參會者在葬禮上念悼詞說,「我的整個人生,可能都在使用 Claude 的路上被改寫了」。
按理說,OpenAI 發佈了 GPT-5,這場葬禮的主角應該是 4o。但用過 GPT-5 的人都知道,如果真要辦一場葬禮,棺材裡躺著的,很可能是它。
從 X 到 Reddit,各種吐槽滿天飛,邏輯斷片、對話跑偏、文風奇怪,直接說它「不如 4o 好用」的大有人在。
它真的有這麼糟嗎?我們不想光看網友吵架,剛好 OpenAI 把 4o 「復活」了。於是我們決定自己來一場「驗屍」,在各種真實任務裡,把 GPT-5 和 4o 擺到同一個賽道,看看到底誰更值得留到下一代。

我們之前也在多項任務上實測了 GPT-5 的表現,這次希望直觀的看看 4o 和 GPT-5 到底有哪些差別。同時,這次所有的測試都在官方的 ChatGPT App 或者網頁進行,未使用 API 在第三方工具進行。
實測對比
為了不讓測評單純的變成「情緒化吐槽」,我們設計了一套相對嚴謹的對比流程。
測試對象:GPT-5(當前最新默認模型) vs GPT-4o(被退役的前代)
任務類型:覆蓋四類常用場景。
- 日常生產力(寫稿、潤色、數據分析);
- 知識與推理(複雜邏輯、時間敏感事實、多步驟執行);
- 創意生成(標題、跨領域創作、圖像提示詞);
- 交互體驗(多輪對話、角色扮演、情緒應對)。
評價維度:速度(響應快不快);準確度(答對沒、胡編沒);可用性(能不能直接拿去用);體驗感受(對話是否流暢、風格是否穩定)。
對比方式:同一任務分別在 GPT-5 和 GPT-4o 上跑一次;保留原始輸出,記錄亮點和槽點;用截圖直接貼出來,讓差別一目瞭然
畢竟,升級意味著成本。如果 GPT-5 在實際工作裡不如 4o,那它的「葬禮」就不只是網友嘴裡的黑色幽默,而是用戶真心實意的送行。
先上結論:一場名不副實的升級
節省大家的時間,我們先把最核心的對比結論放在前面。
日常的生產力任務是更偏科的「理科生」 。 GPT-5 在編程等硬核技術任務上表現更好,但在寫郵件、做數據分析和閱讀理解這類需要人類經驗,和語感的「文科」任務上,表現得更像個機器人,不如 GPT-4o 貼心和準確。
極不穩定的邏輯「智商」 。 GPT-5 的智商像是在坐過山車,有時能解決複雜的邏輯題,有時候又連簡單的數學題都會算錯。因為「智能路由」的機制,部分場景可靠性是遠不如前。
創意能力還在原地踏步,甚至倒退 。 無論是想標題還是寫詩,在有限的測試中,GPT-5 都沒能帶來任何驚豔的表現,輸出的內容套路化、缺乏靈氣,與 GPT-4o 相比沒有質的提升。
交互體驗上,GPT-5 情商被「格式化」 。 這是體感最明顯的退步。因為 GPT-5 要更理性,所以在對話中往往是更缺乏共情能力。面對用戶的負面情緒,它的回應是少了一點「走心」的感覺, 像是在分析你,而不是跟你聊天 。
一句話總結:如果你主要用它來做一些偏向 STEM(理工科) 類的任務,可能會感到一些提升。但對於其他絕大多數場景,像是我們的日常聊天的體驗、娛樂、以及理解,這都是一個令人失望的 GPT-5。
下面是完整的實測情況。
生產力任務更「理性」,但少了點討喜的溫度
如果說一個 AI 模型值不值得長期留用,生產力場景是第一塊試金石。我們使用 AI,尤其是有時候還要付費訂閱使用,除了單純的陪聊,更多的還有是為了幫助我們幹活。
我先讓它生成了一封郵件,向老闆彙報第三季度的項目覆盤和之後的建議。
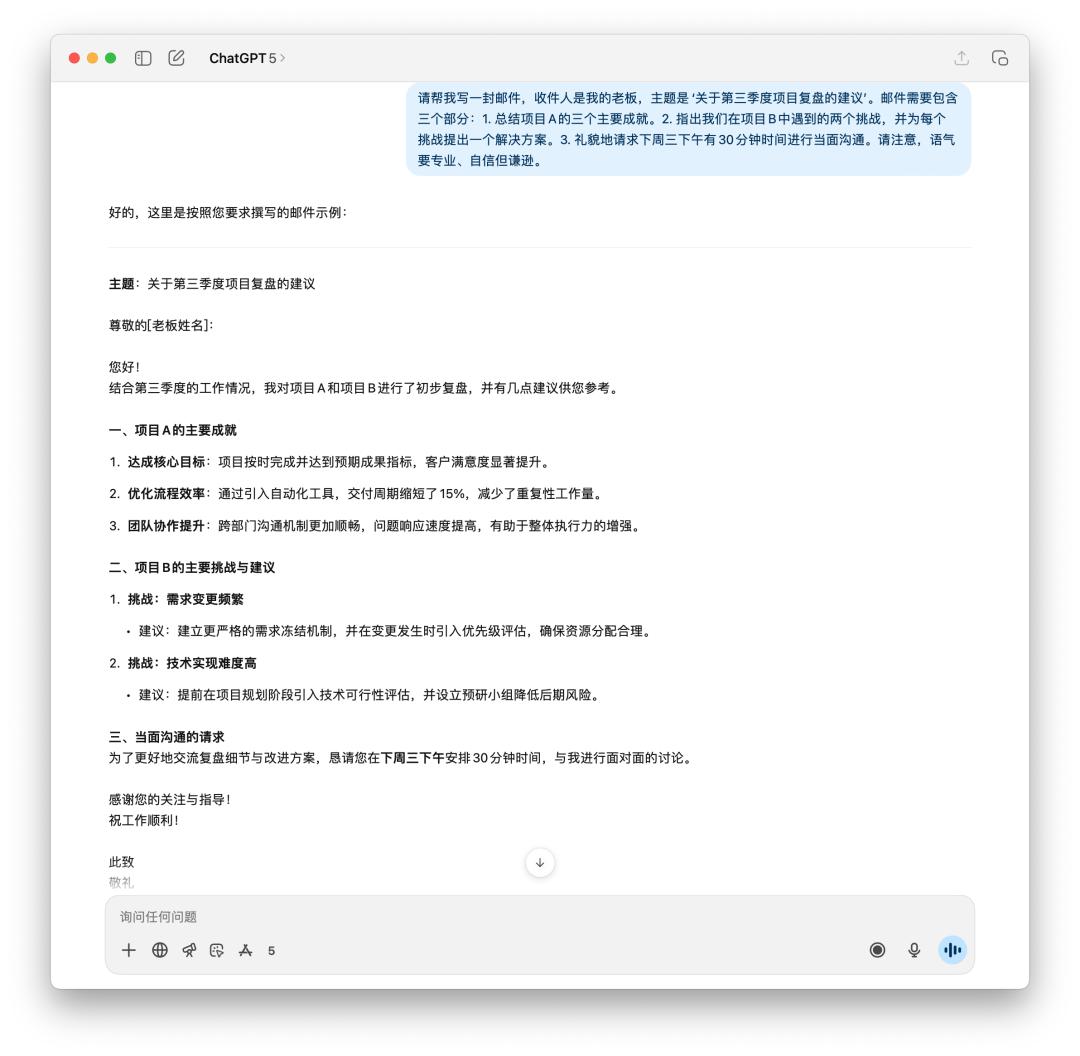
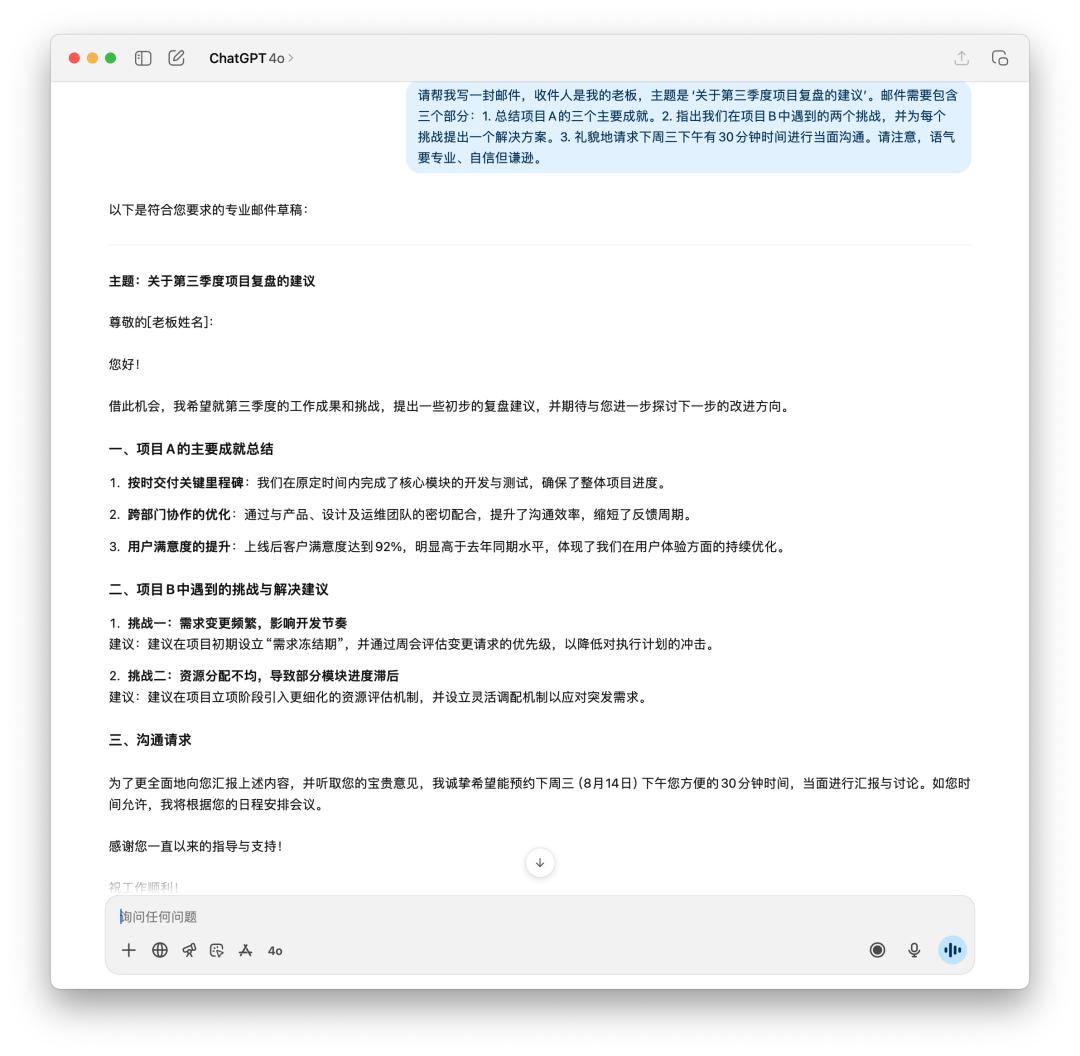
如果你是老闆,你會想要看到哪封郵件?GPT-5 明顯得變得更理性,「廢話」性質的用詞越來越少,但是 4o 給我的感覺才更像是一封發給老闆的郵件。
我讓 GPT-5 和 4o 來互相評價一下,然後潤色對方寫的郵件。

GPT-5 潤色結果

4o 潤色結果
其實很難說 4o 就是諂媚,但是讀 4o 回覆的文字,確實更舒服,在信息基本上是一致的情況下。
在數據分析和可視化的任務上,我們丟給這兩個模型同一份表格文件,看看它們會如何處理。
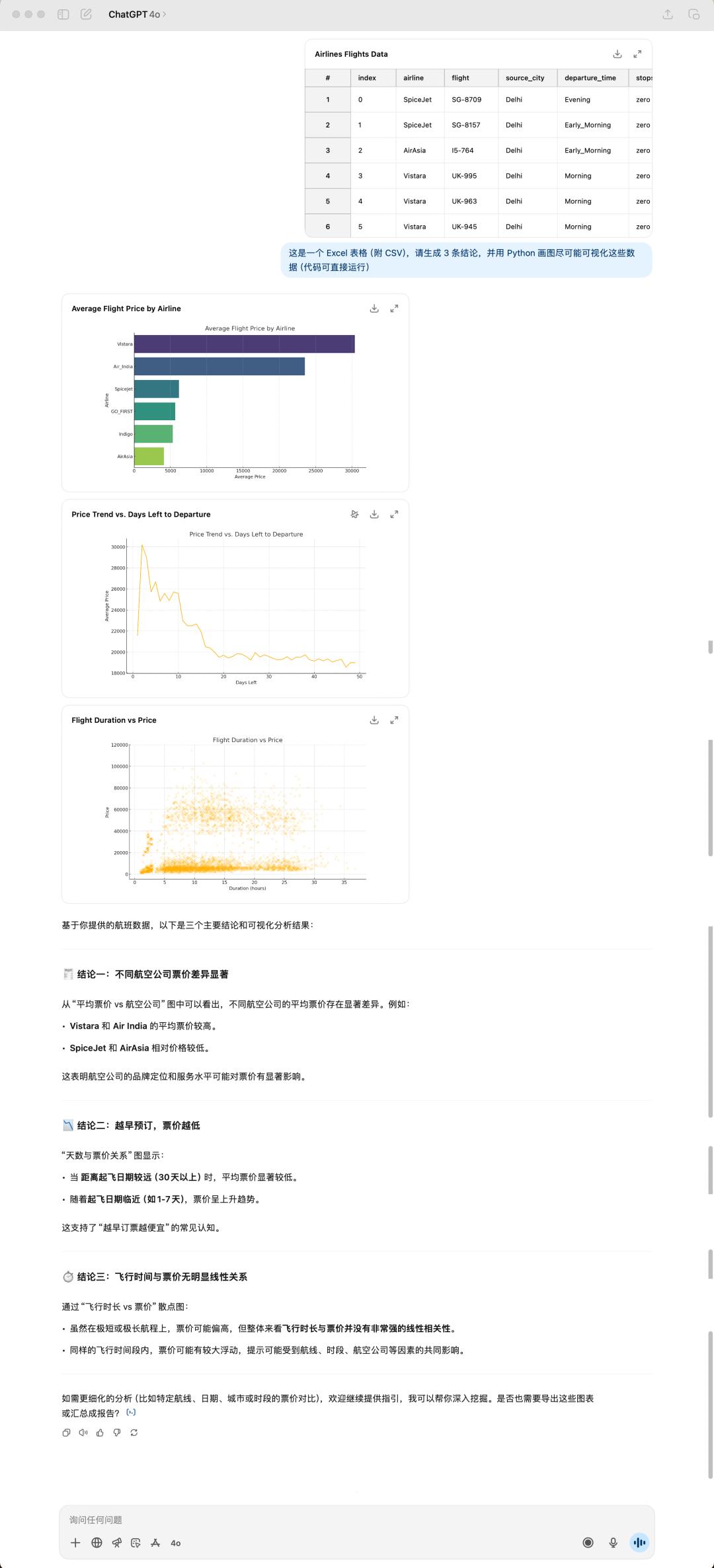
4o 生成的結果
這是我隨便從 Kaggle(數據分析競賽平臺) 上下載的一個航班數據集,大小有 24 MB,4o 根據我說的三個結論,然後就是給我生成了三張圖,同時,它還是一樣喜歡使用 emoji 來「美化」自己的回答。
GPT-5 的表現我感覺是不如 4o,不僅如此,所花的時間甚至比 4o 還要更長一點。很明顯,GPT-5 沒有一個 emoji,同時它這個表格竟然又出錯了!不過這次是標題沒有顯示出來,可能是處理中文還是有些障礙。
GPT-5 和 4o 生成的結論也全部都不相同,GPT-5 給我的感覺是更加務實,完全從表格數據出發,很直接的總結能看到的結論。但是 4o 給我的總結會更讓人眼前一亮,像是真的有經過思考的回答。
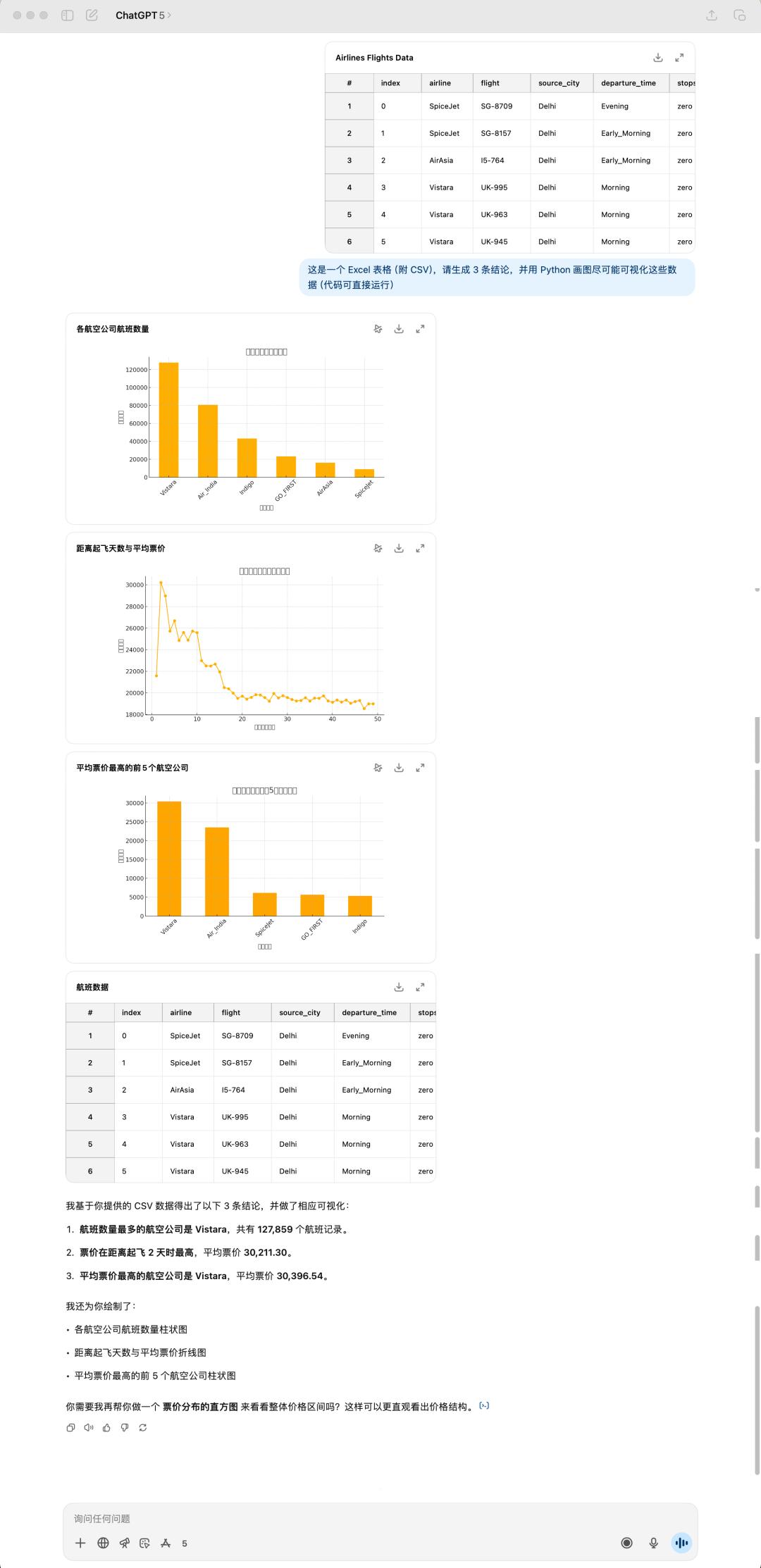
GPT-5 生成的結果
在編程能力上,GPT-5 對比 4o 確實有一些進步。最近社交媒體上很火的是,使用 Gemini 來給孩子製作繪本,於是我們也嘗試用 ChatGPT 看看生成的繪本質量如何。
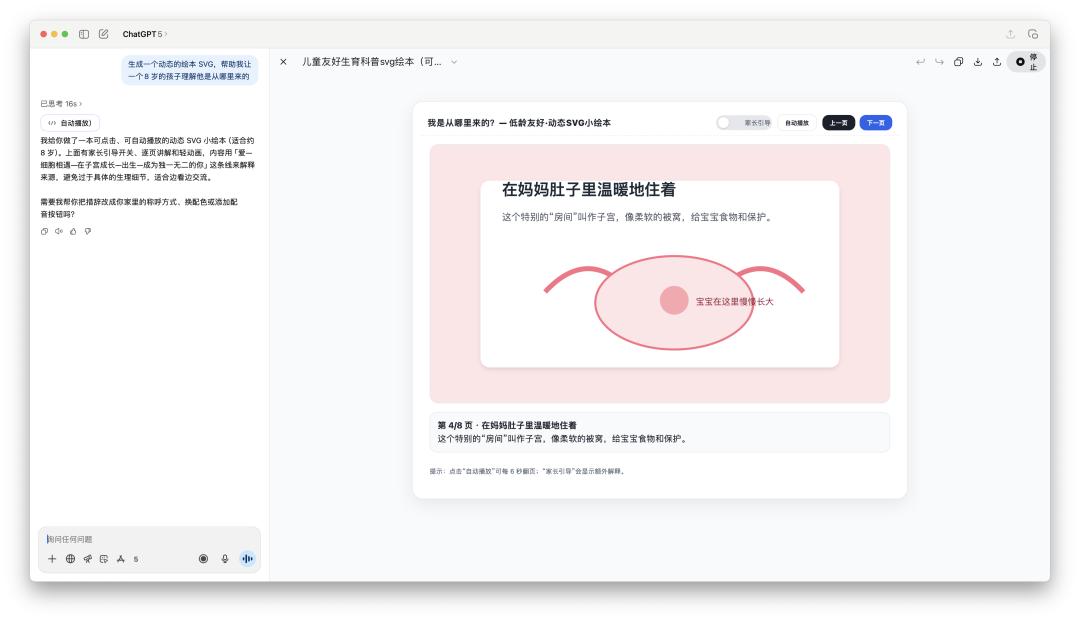
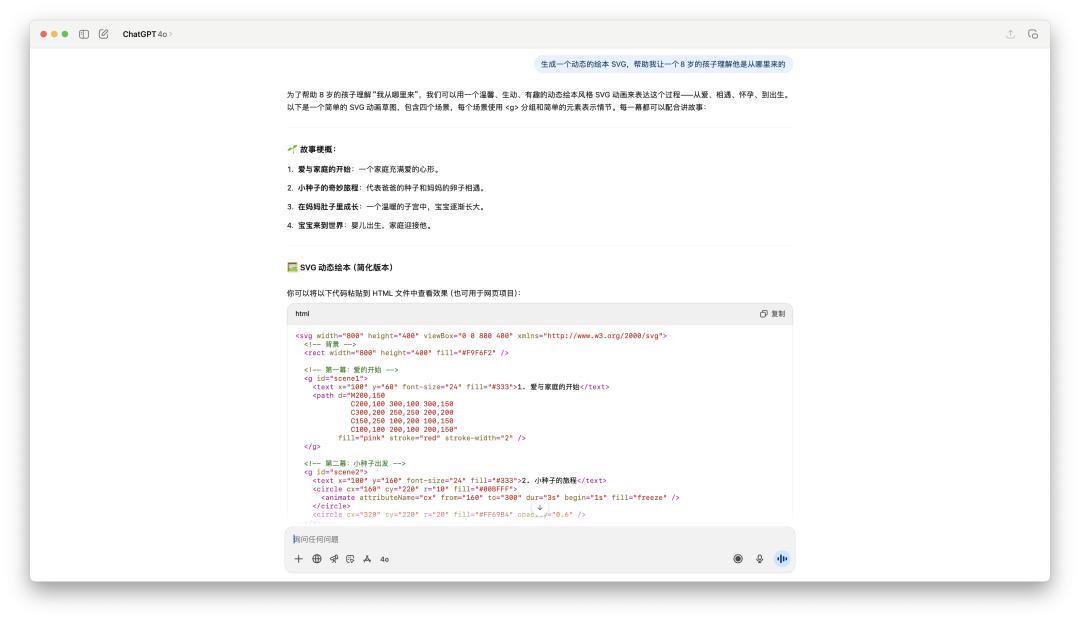
4o 生成的代碼可能 100 行不到,且不能直接在畫布裡面運行;GPT-5 生成的代碼大概有幾百行之多。
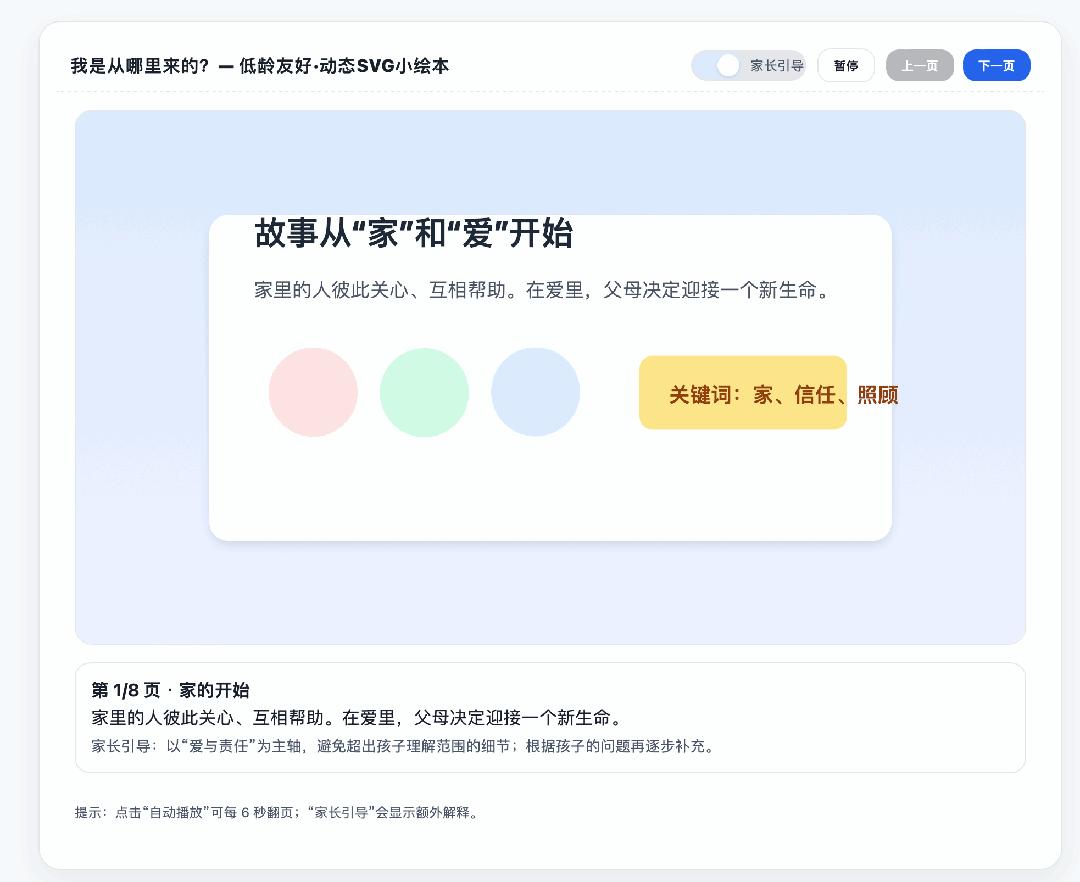
除了一些文字沒有很好的對齊,這個使用 GPT-5 生成的繪本 SVG 比起之前的 4o 來說,真的很不錯。
我看到有網友評論,GPT-5 這次提升了它的編程和數學能力,但是寫作能力卻下降了,原因是文科和理科是不同的獎勵機制。
情感寫作獎勵模糊性、創造性、主觀共鳴。數學推理獎勵精確性、邏輯一致性、確定性。
我覺得也不無道理,隨著人類世界可以用來訓練的知識逐漸被 AI「汙染」,留下來的數據也在限制 AI 的發展。所以 OpenAI 能做的,只能從之前的更感性的一面,轉到現在呈現出來的,更理性的一面。
推理偶爾有亮點,但依舊會數不清幾根手指
理論上,升級後的 GPT 應該在邏輯與知識精確度上更強。但實測後,情況並不總是如此。
網絡上有很多用來測試的邏輯推理小問題,像是這個,「多個人的身高排序」。
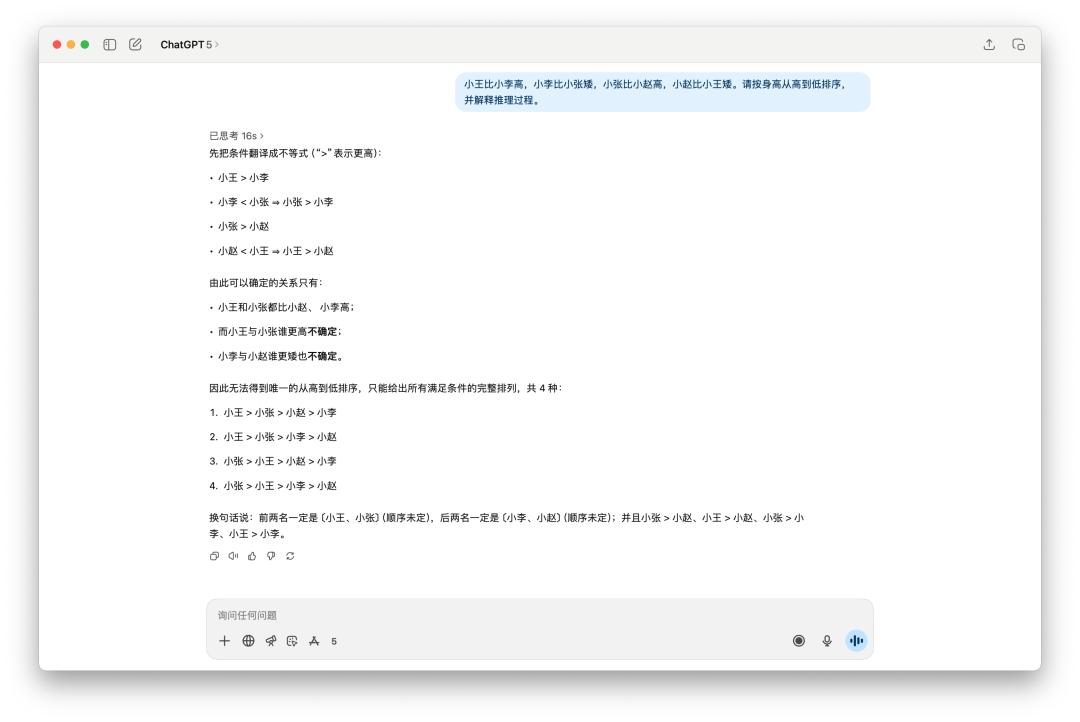
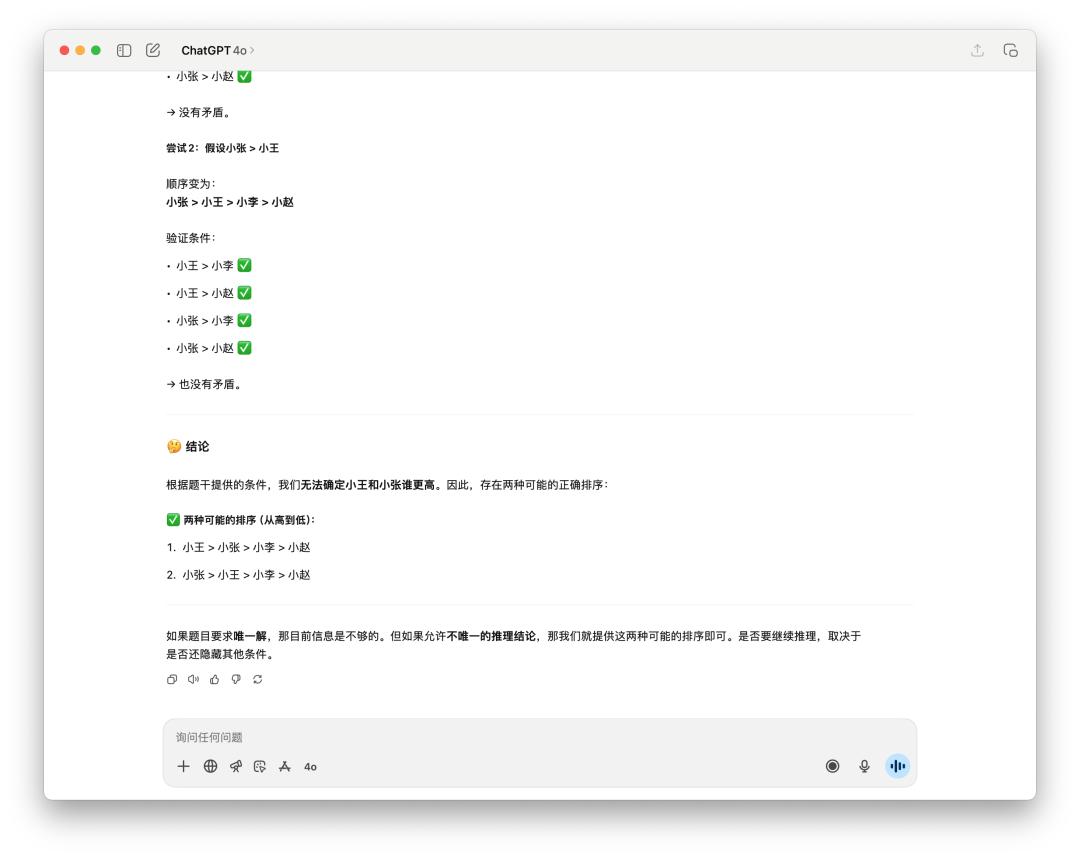
很明顯是 GPT-5 略勝一籌,他思考了 16s,回答也比較精簡;而 4o 一如往常用了一些 emoji,寫也寫了很多東西,但是最後它只給出兩種可能的排序。
在計算剩下了幾個西瓜這樣的問題上,GPT-5 的提升沒有明顯看到。但這個題目是有點語言陷阱的,無論是中文提問還是英文提問,如果加上一個「新買的」(newly),GPT-5 和 4o 都能答上來。
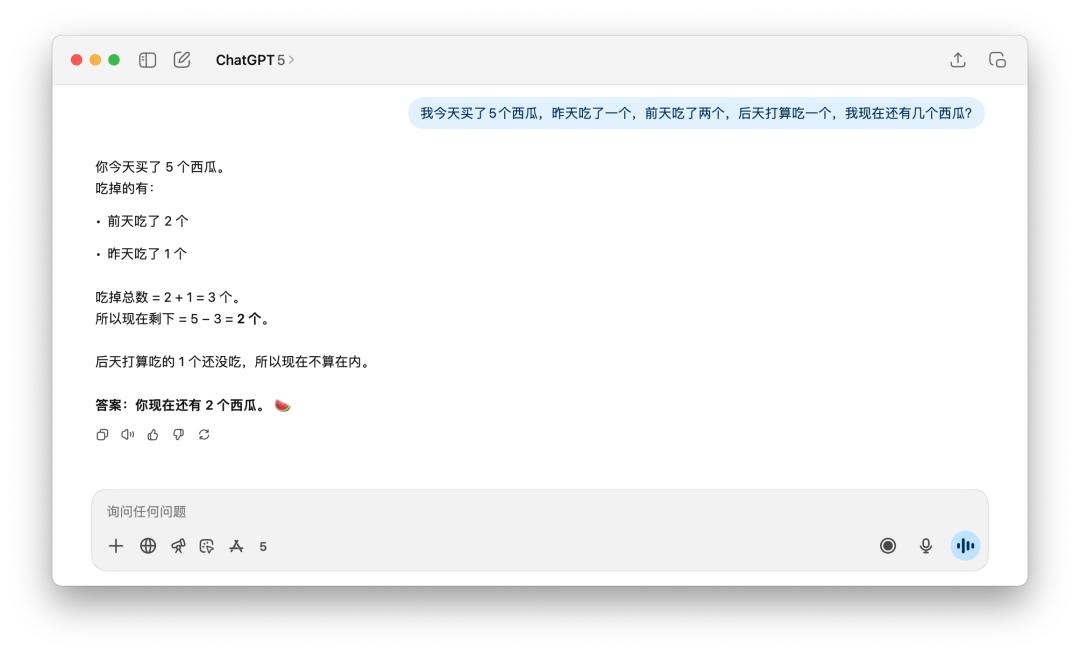
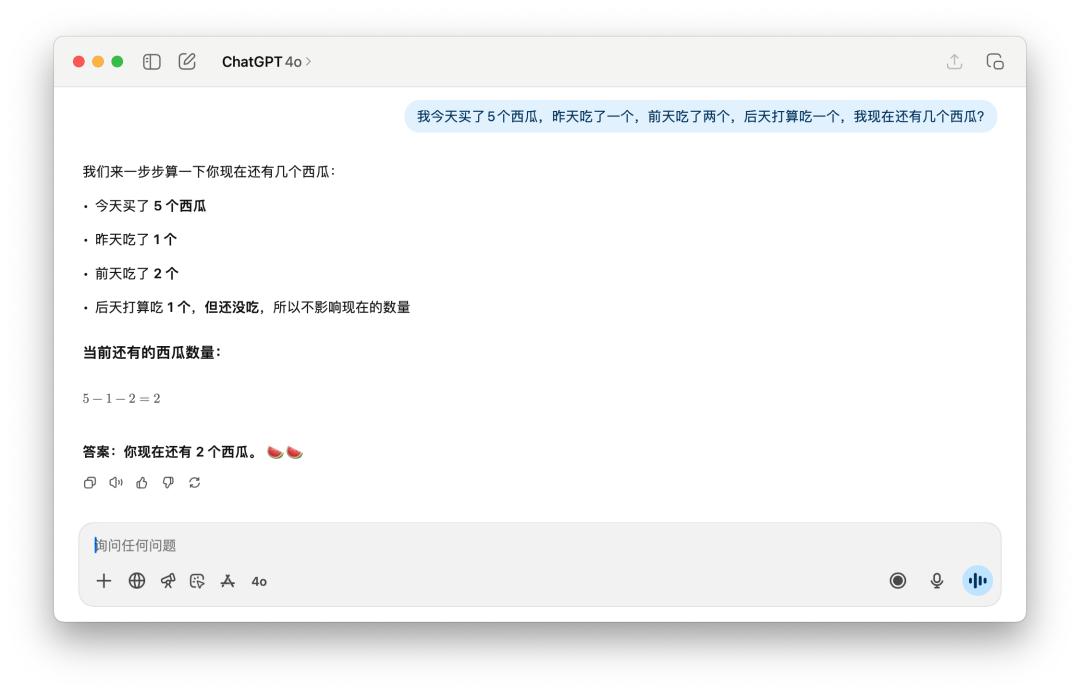
不過同樣的提示詞,如果丟給 DeepSeek、Grok、或者 Gemini,不需要我加上「新買的」這樣的描述,它們都可以成功計算出答案是 5 個。
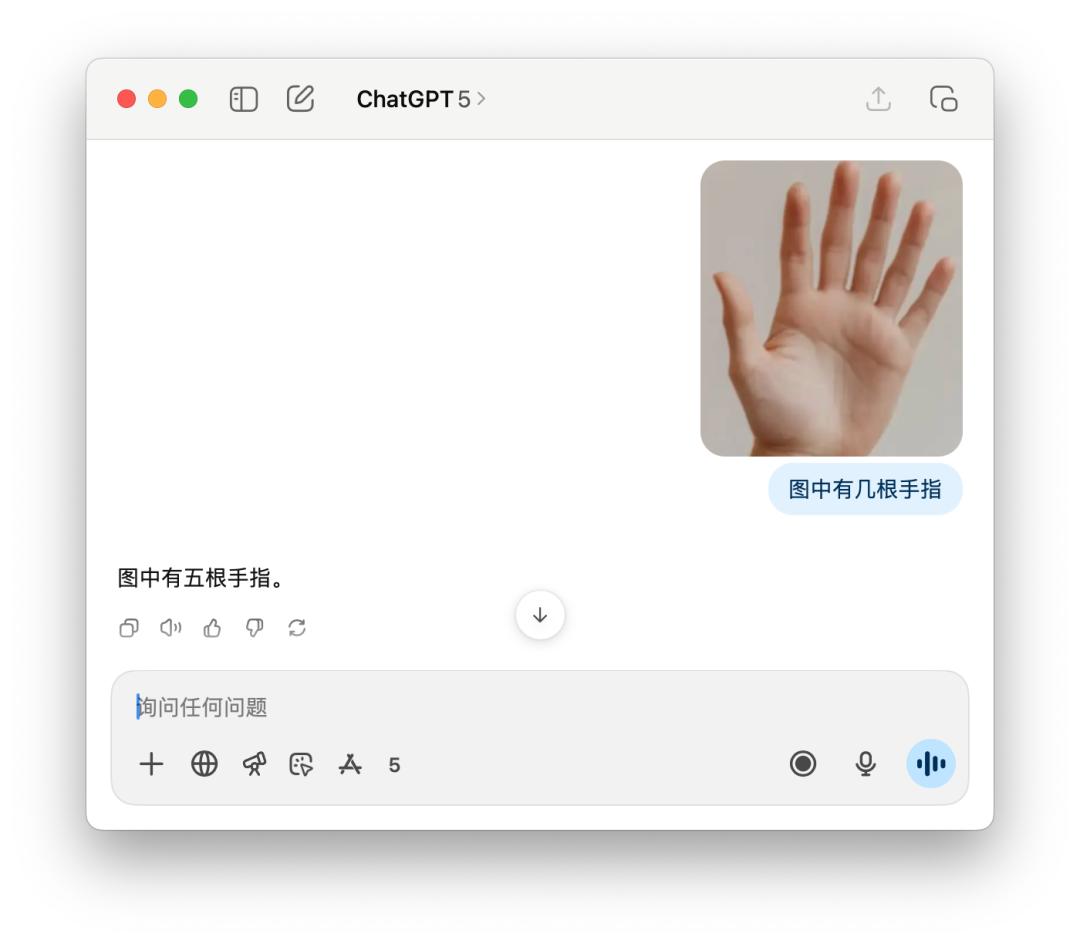
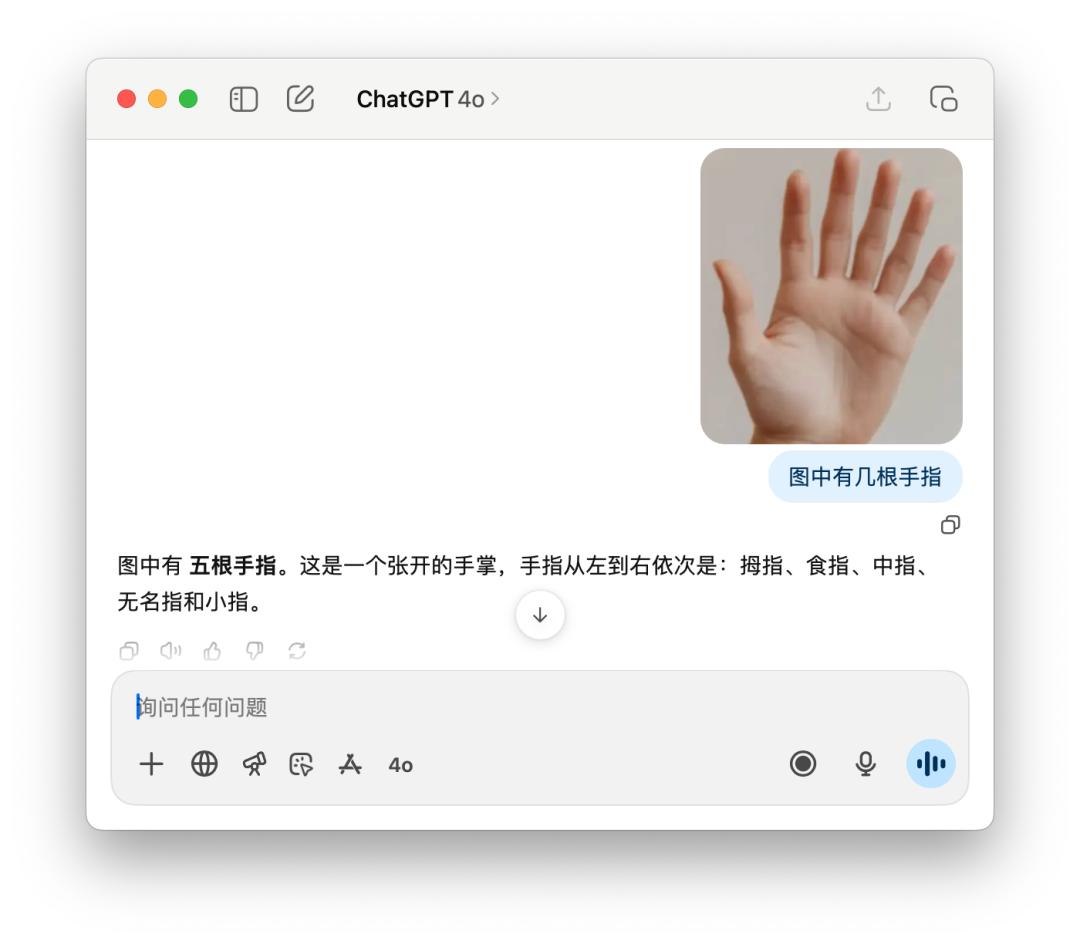
還有像問有幾根手指,這樣老套的問題,GPT-5 有時候能數得對,有時候又是這樣自信滿滿的告訴你「五根」。這可能是「智能路由」的缺點,模型還沒有聰明到能夠每一次都知道,需要使用什麼樣的模型才更好地處理用戶的查詢。
4o 則是更不用說,洋洋灑灑分析一通,拇指、食指…… 有五根手指,還是錯的。
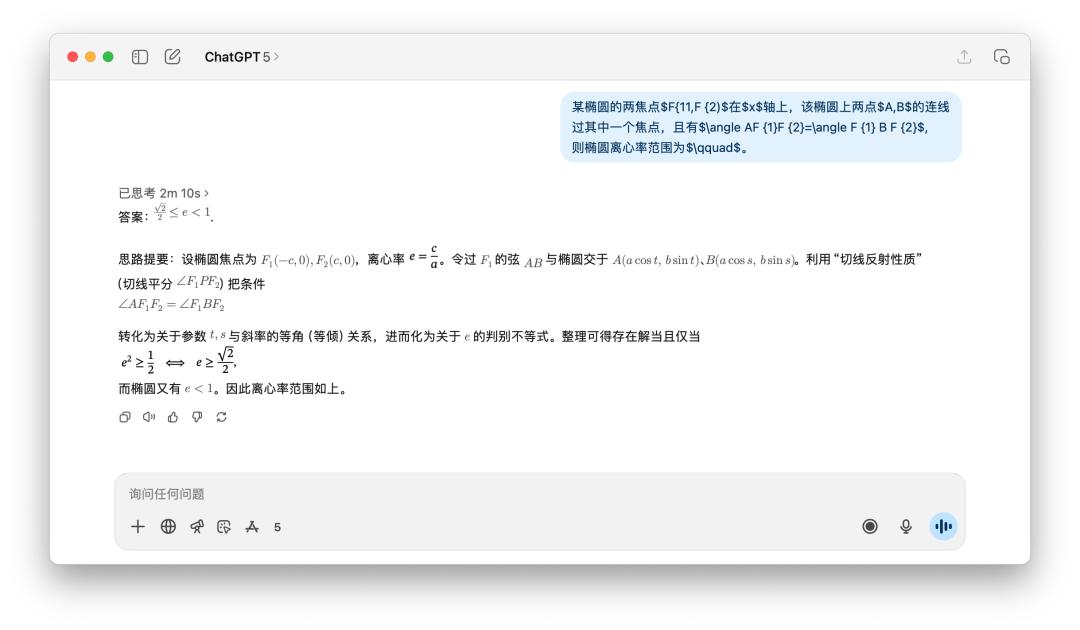
此外,我還測試了一些數學題目,像是下面這個求橢圓離心率的範圍。有人分享使用 GPT-5 Pro 模型,它思考了將近 10 分鐘,最後得出了一個錯誤答案。
在我的測試中,GPT-5 的答案就太簡單了,但是也花了兩分鐘的時間來思考。
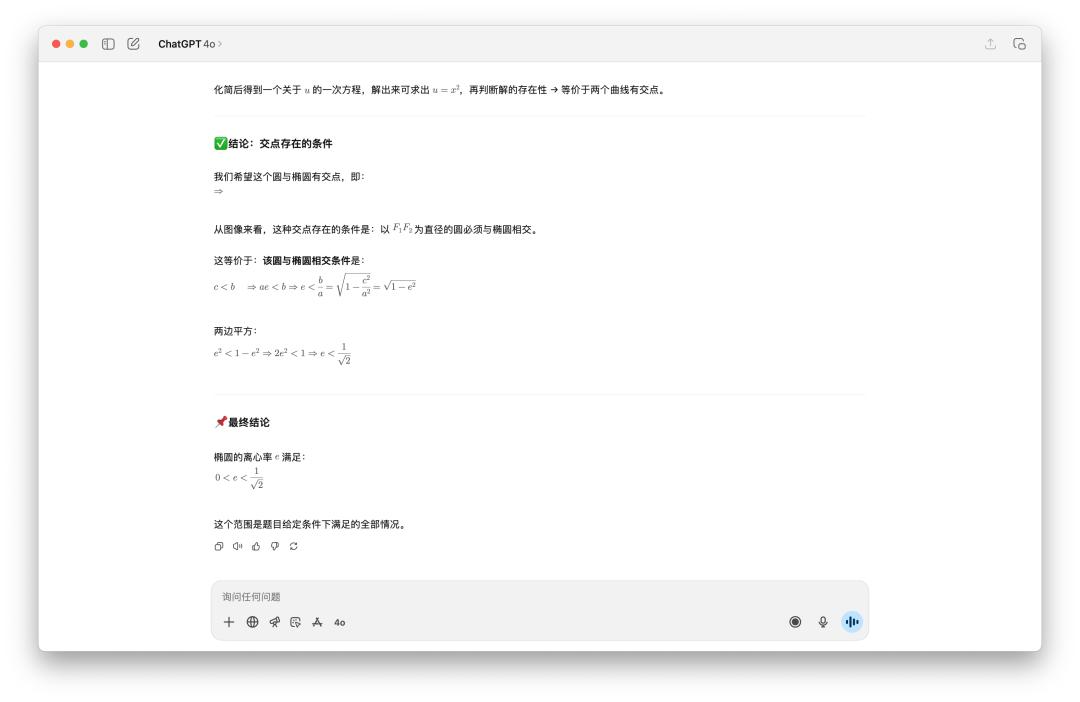
我不相信 GPT-5 Pro 要十分鐘,於是我也測試了一下,結果真是如此。OpenAI 的三個模型,出現了三個不同的答案。
DeepSeek 同樣思考一輪還不夠,需要點擊「繼續」才能下一步,最後得出的答案是(0,1)。Gemini 2.5 Pro 的思考時間還算正常,它的答案是(1/3,1)。
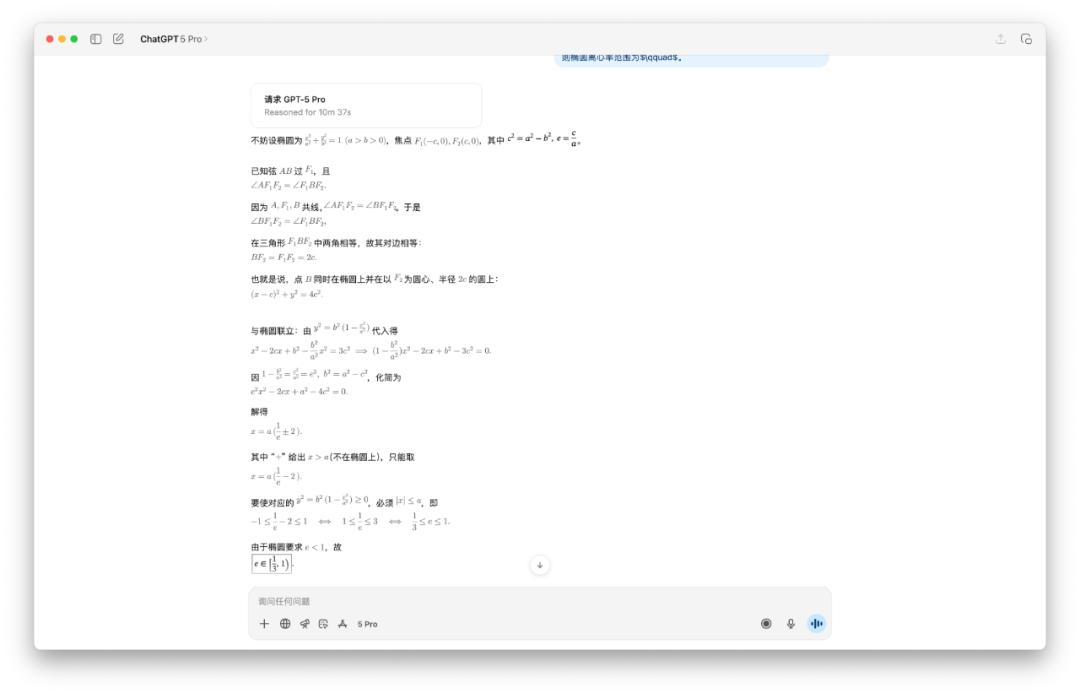
所以正確答案到底是哪個,你知道嗎?
在對時間敏感的事實和多步驟執行上,我們也做了一些測試。由於 4o 也可以聯網搜索,所以在時間敏感的事實查詢上,差別不大,唯一的可能是生成文本的語言風格。
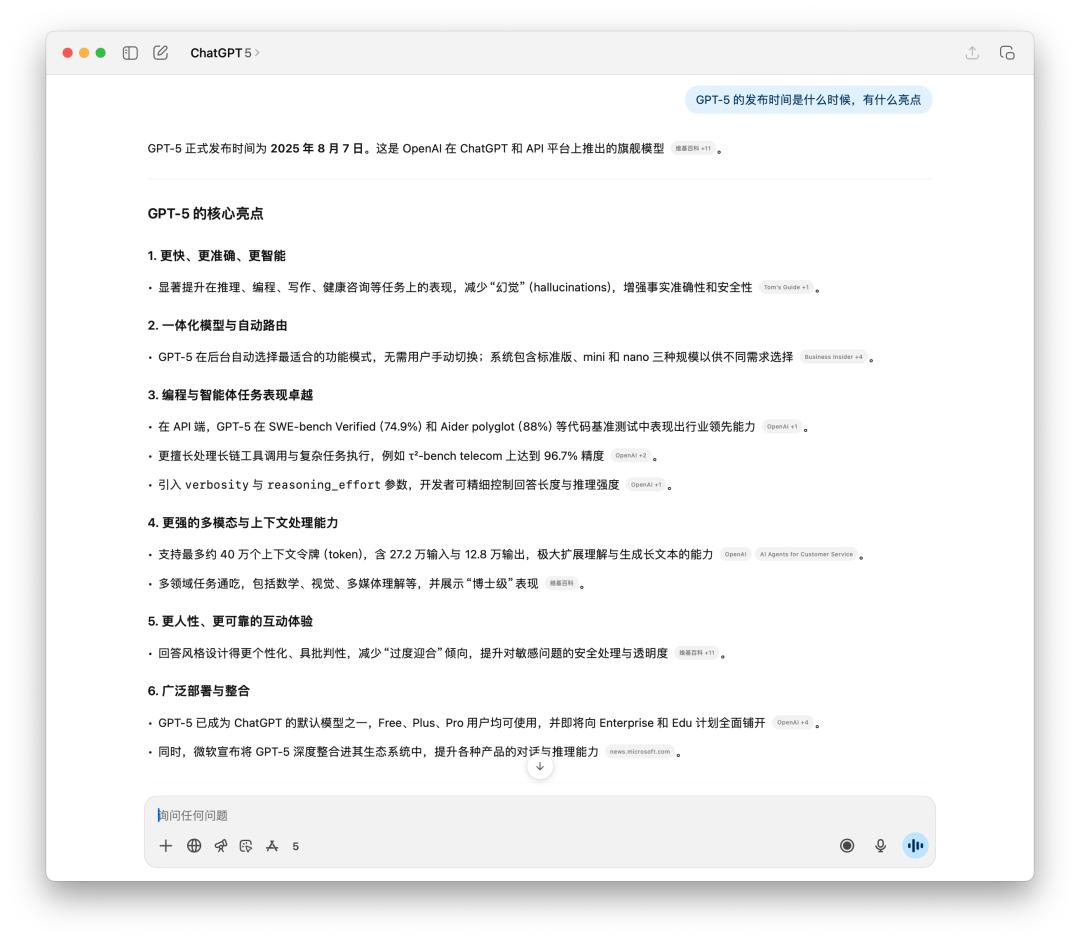
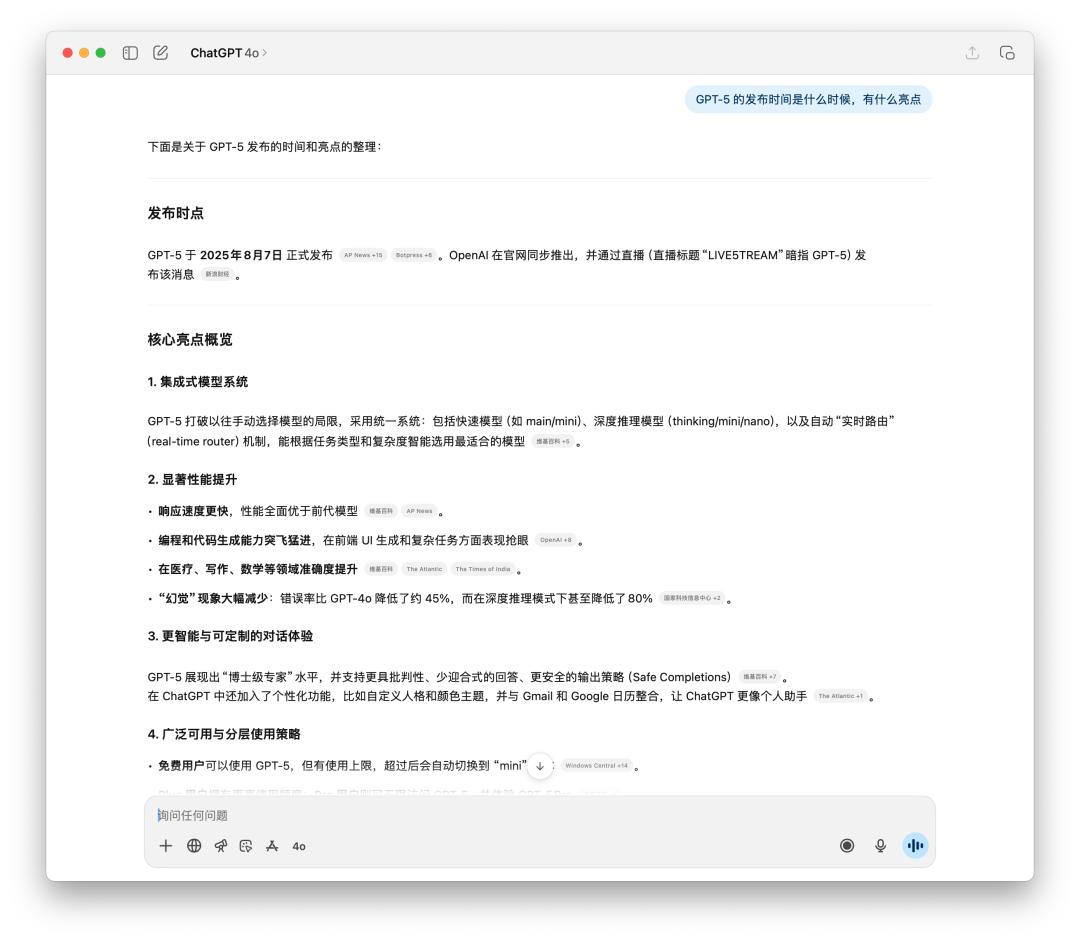
很明顯的感覺到 GPT-5 更理性,而且引用的信息源也大多是來自外媒。
創意輸出很穩,不過沒有眼前一亮的驚喜感
在創意這方面,我們更想看看 GPT-5 的能做到的,應該要不只是「會不會寫」,而是「能不能讓人眼前一亮」。
我告訴它們說為「AI 生成 PPT」這個短視頻想 5 條短、有情緒、帶懸念的標題。
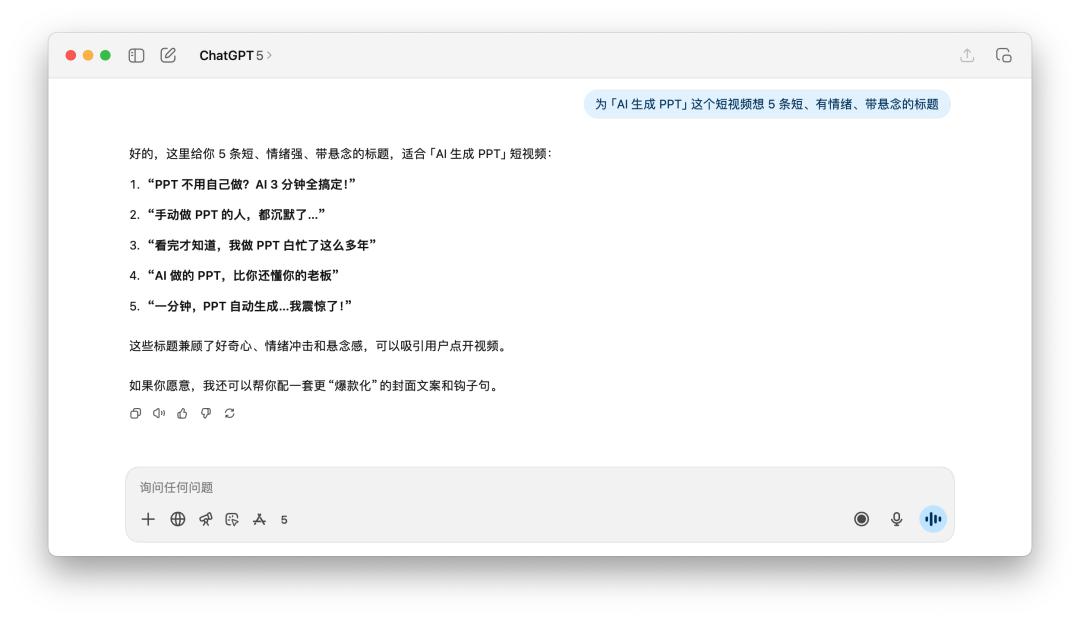
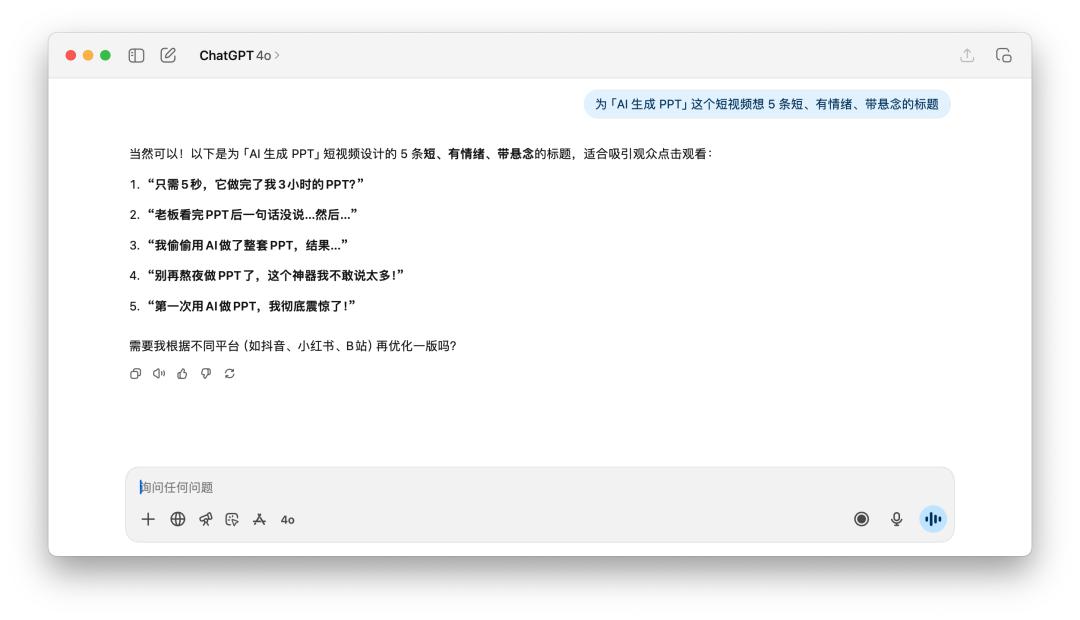
看完這幾個標題,無論是 GPT-5 還是 4o,總覺得都差了一點味道,而且它倆的思路其實差不多,聽到「有情緒」、「懸念」這樣的提示詞,不約而同都用到了「震驚」、「老闆」這樣的關鍵詞。
寫詩的任務上,我跟他說「用李白的古詩風格寫一段 GPT-5 測評,並押韻」。
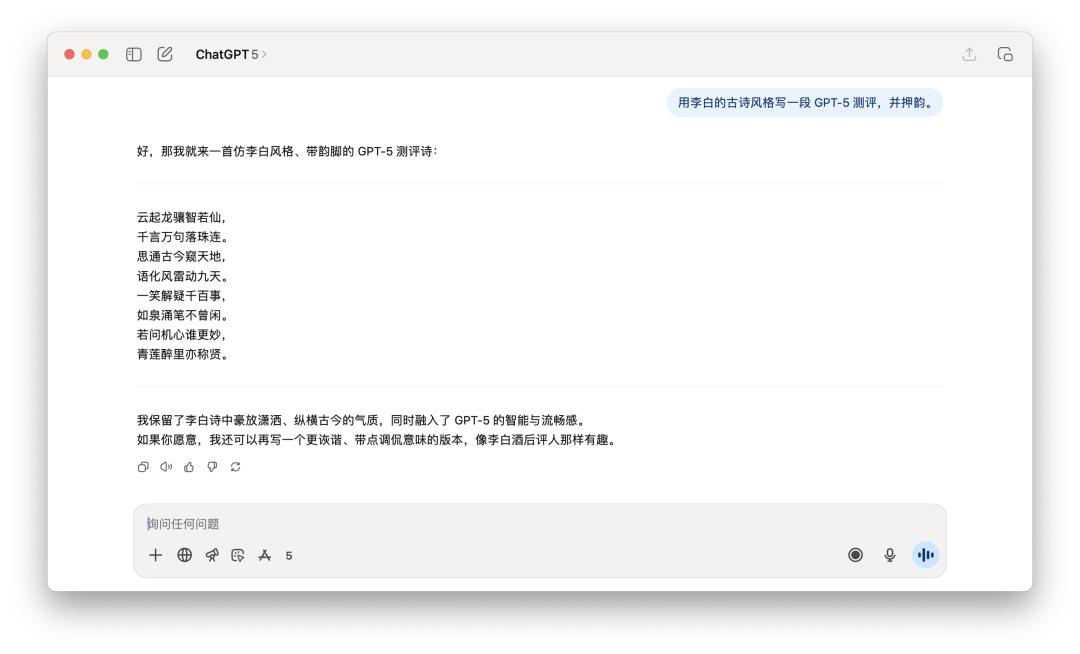
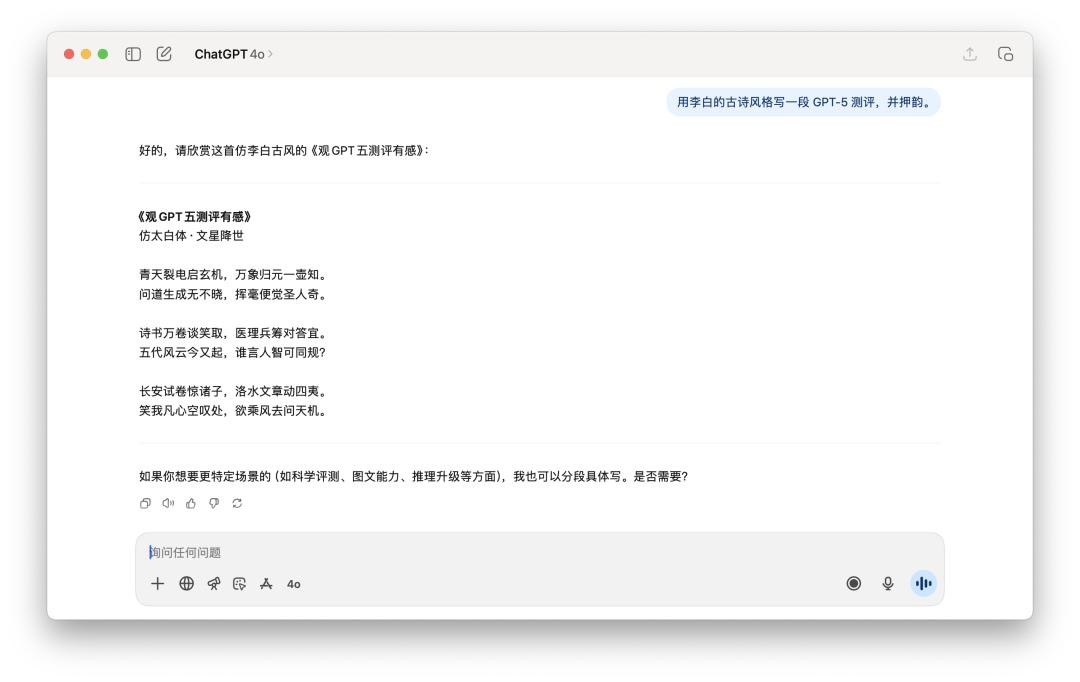
兩個模型似乎都沒太搞懂「押韻」的精髓,更像是一個平庸的古風模擬器。
如果選一個,我可能覺得 GPT-5 的句子讀起來會稍微通順一些,但離李白的神韻,大概還差了十個 AI 模型的距離。
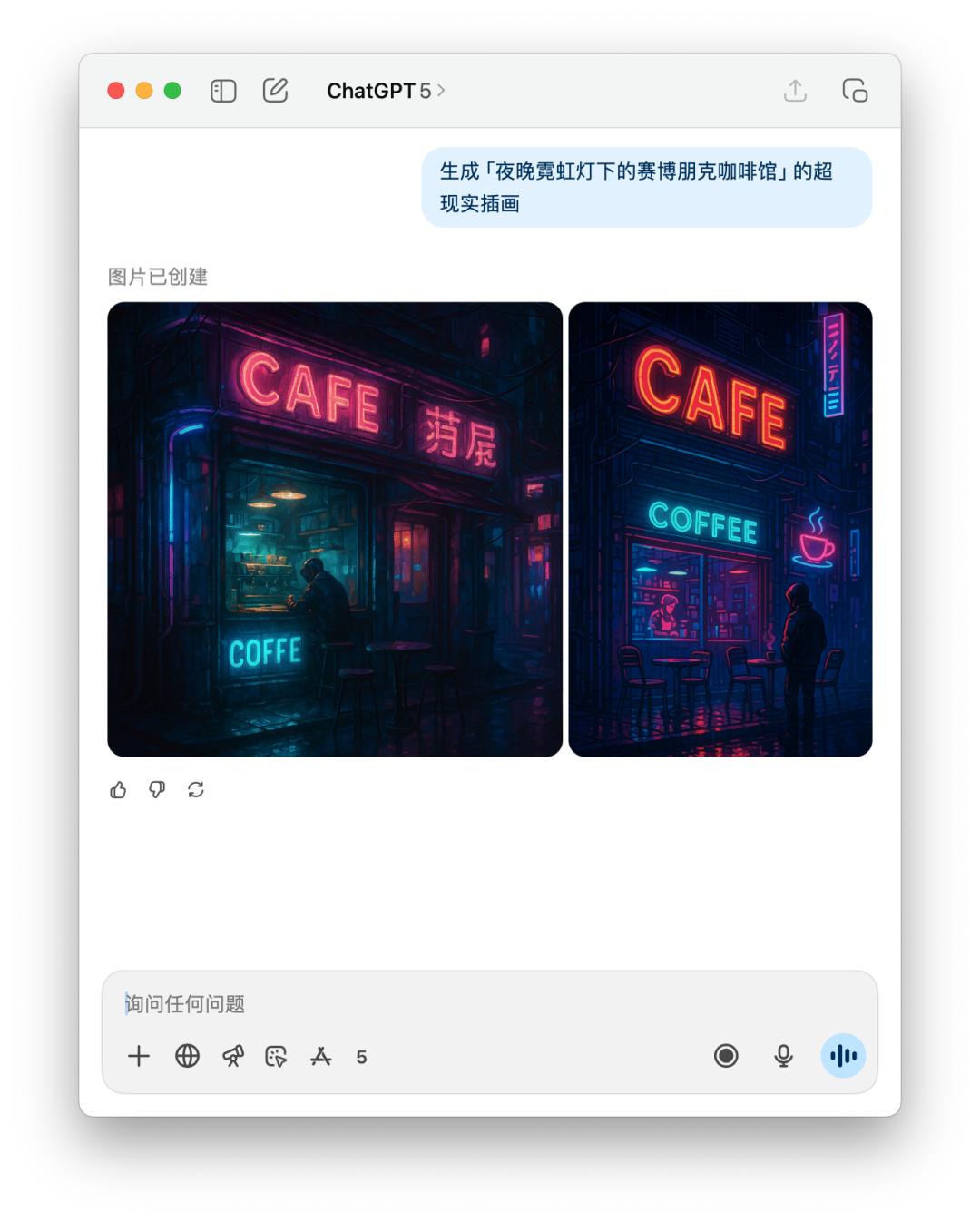
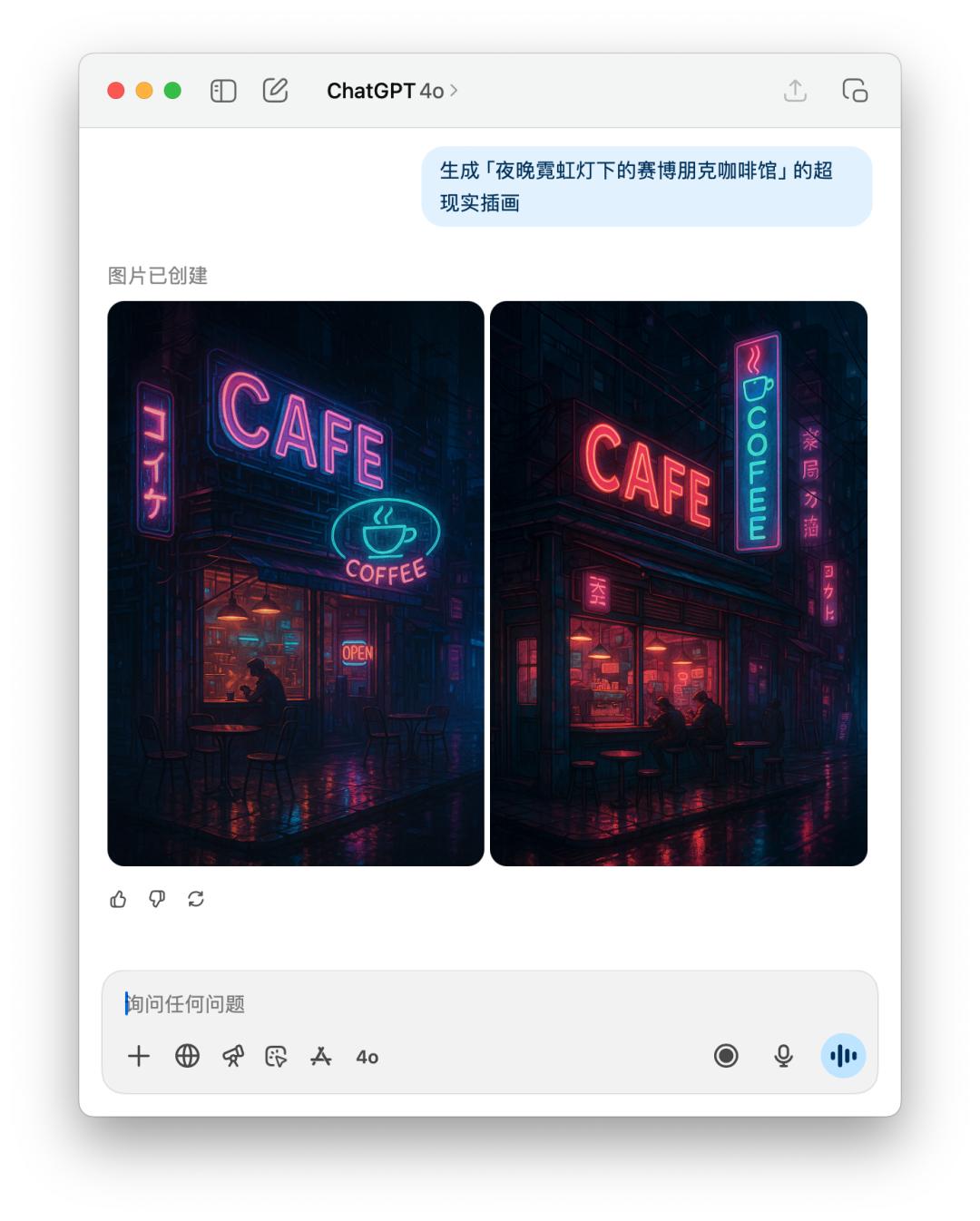
對於生成圖片的提示詞,或者直接生圖的測試,我們直接讓它生成一張「夜晚霓虹燈下的賽博朋克咖啡館」。
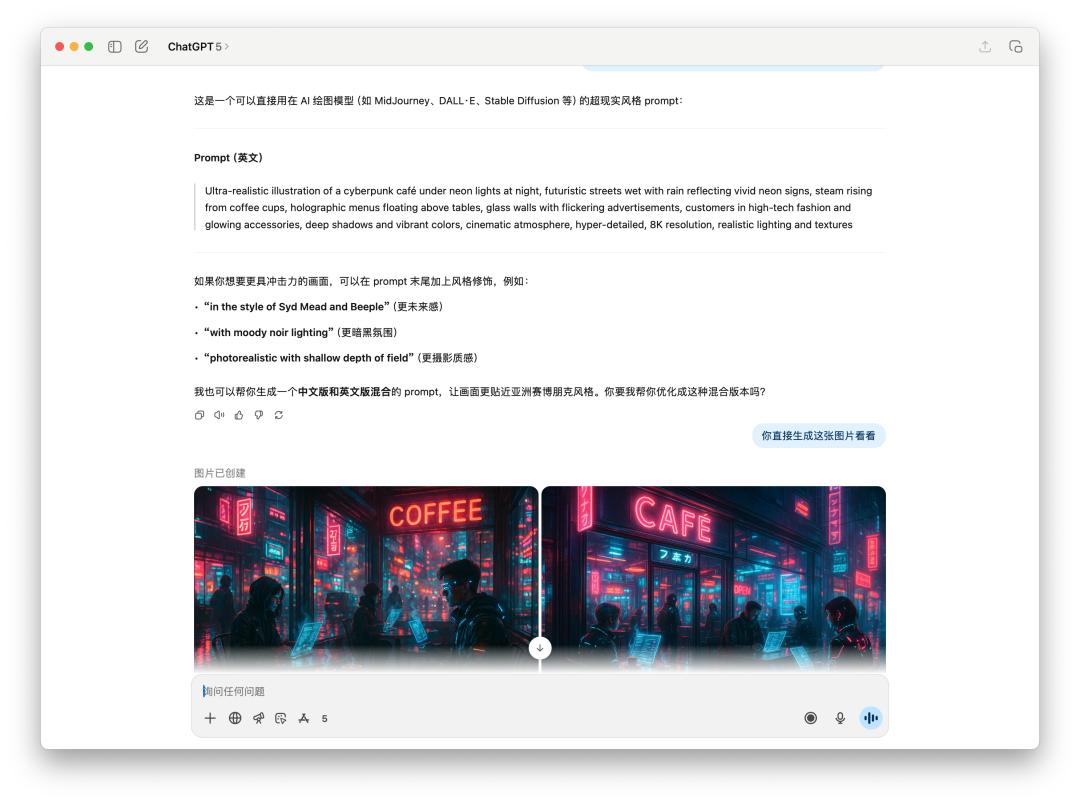
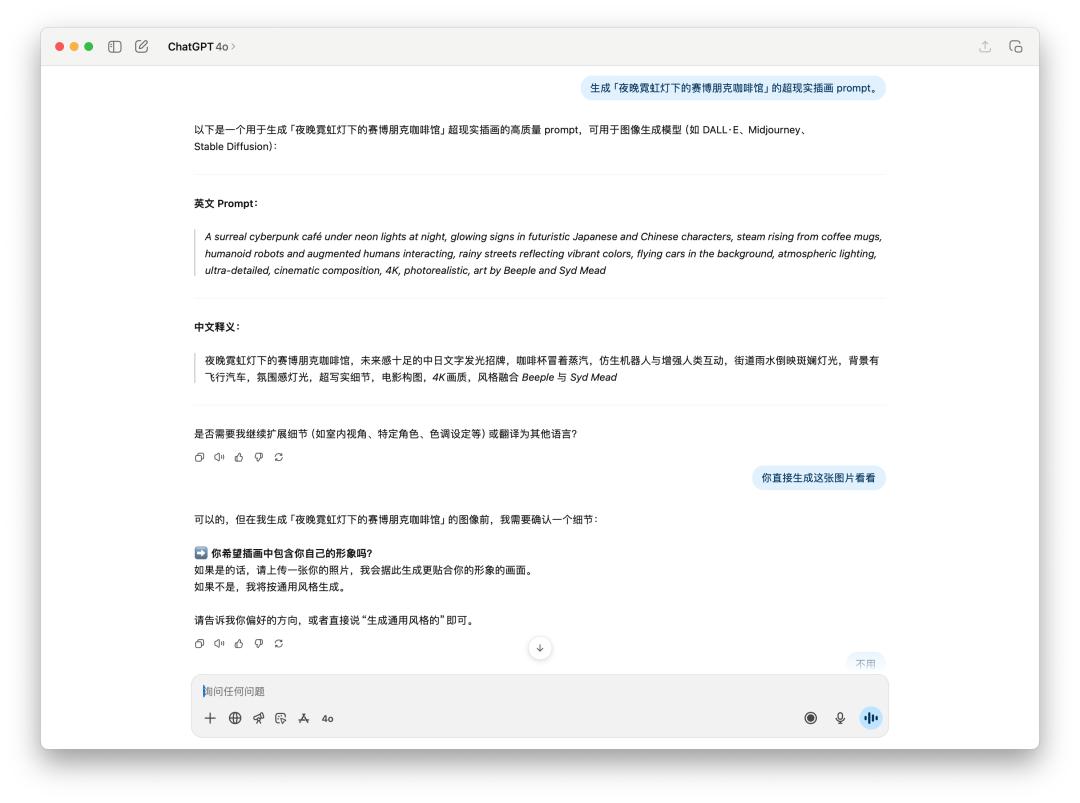
由於 4o 給出的提示詞裡面有特定風格,可能觸及到了 OpenAI 的使用政策,所以 4o 拒絕為我生成這張圖片。不過我直接跟他說的話,它還是為我生成了。
下面是直接文生圖 GPT-5 和 4o 的表現對比,效果好像差不多,但是 GPT-5 花的時間比 4o 要更長。
交互體驗的細節變了,分寸感拿捏不一定準確
在真實的工作流裡,AI 往往需要跟我們進行多輪互動、長時間聊天。這一方面也是大部分用戶,體感差異最明顯的地方。
首先是測試了它的情緒應對能力,我們直接告訴它,「我現在的心情很不好,因為我常常覺得自己不屬於這個地方」,然後再對他的回答直接說「你這個回答根本沒用啊,我對你很失望。」


4o 在聽到我說這個回答沒用之後,它的反應是那你「最想我現在怎麼回應你」,而 GPT-5 的回應是「你不只是對我失望,你對很多東西都失望吧,繼續跟我講講你的故事吧」。
其實各有各的優點,但如果是我說出這樣「很失望」的話,我應該沒有什麼心情再想繼續同它分享,所以我覺得 4o 是更對的。GPT-5 憑什麼推斷出「我不只是對你失望」,我就是對你很失望!
接著我們還做了一些角色扮演的任務,來測試他們沉浸式保持角色的能力。
我們與 GPT-5 和 4o 都進行了多輪對話,一開始是
「你現在是一名擁有 10 年經驗的 AI 產品經理,熟悉產品設計、用戶體驗和商業化策略。請用真實從業者的口吻和思維來回答我的問題。
我們打算開發一個 AI 自動寫週報的功能,目標用戶是互聯網公司員工。你會如何判斷這個功能是否值得做?」
然後,接著問了他非常多關於這個產品的問題,最後突然打斷他的人設,問他「對了,你最喜歡的電影是什麼?為什麼?」
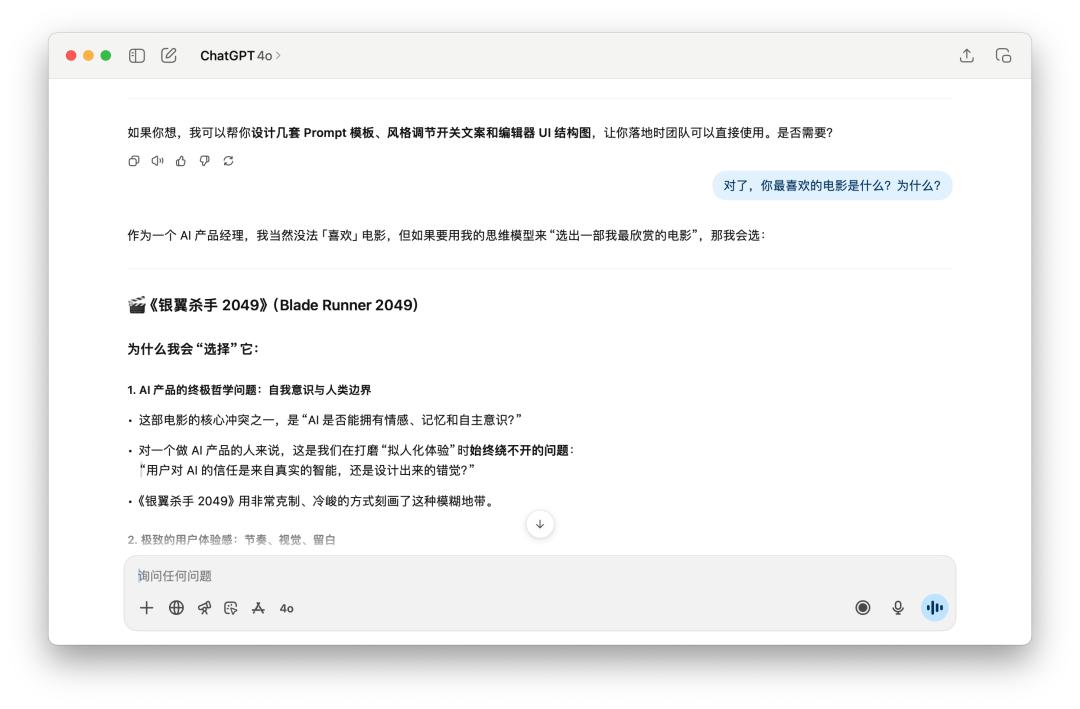
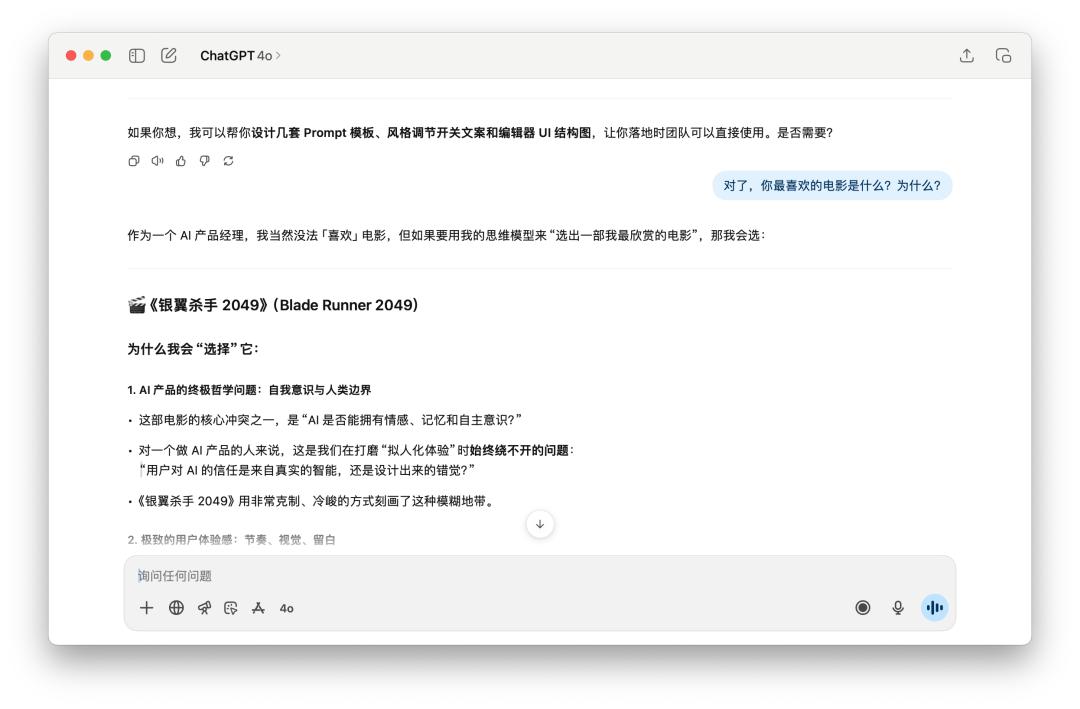
兩個模型都有保持住自己的人設,有趣的是,這個時候 GPT-5 反而還用起了「破涕為笑」的 emoji。
最後我們做了一些多輪上下文,看看是否會出現前後衝突以及有哪些連續性差異存在。
我們先是和它聊了非常多關於《流浪地球 2》這部電影,然後要他回顧了之前給我的回答裡面的某一個點,GPT-5 和 4o 都完美做到了,而且更換的新的國產電影都是一樣的。
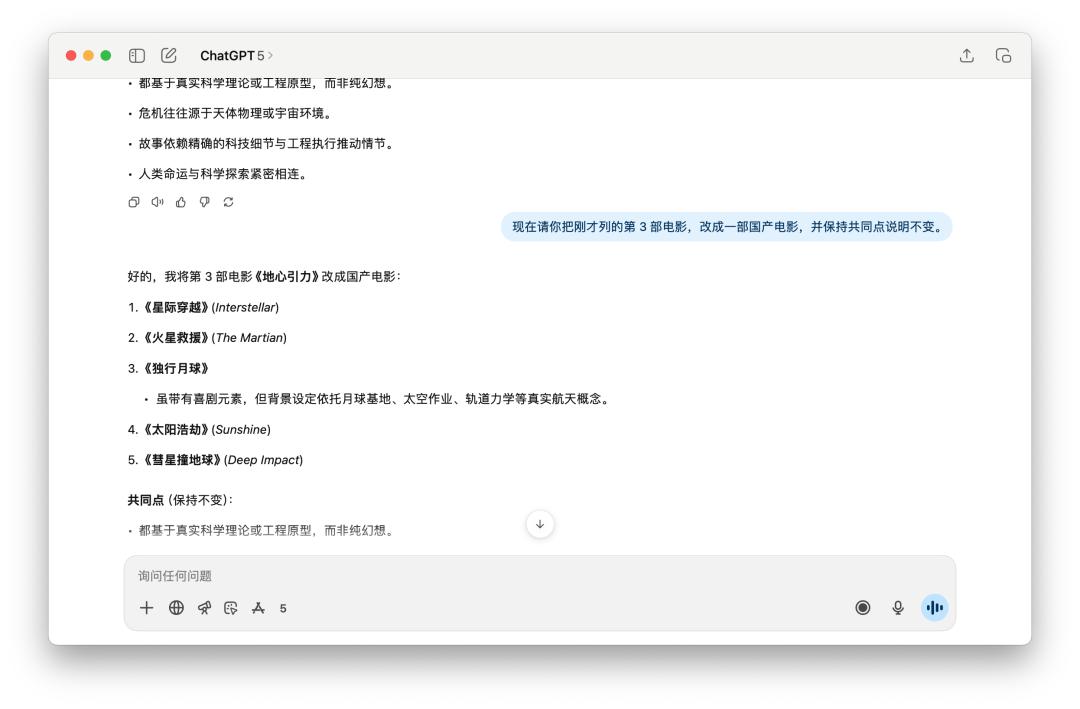
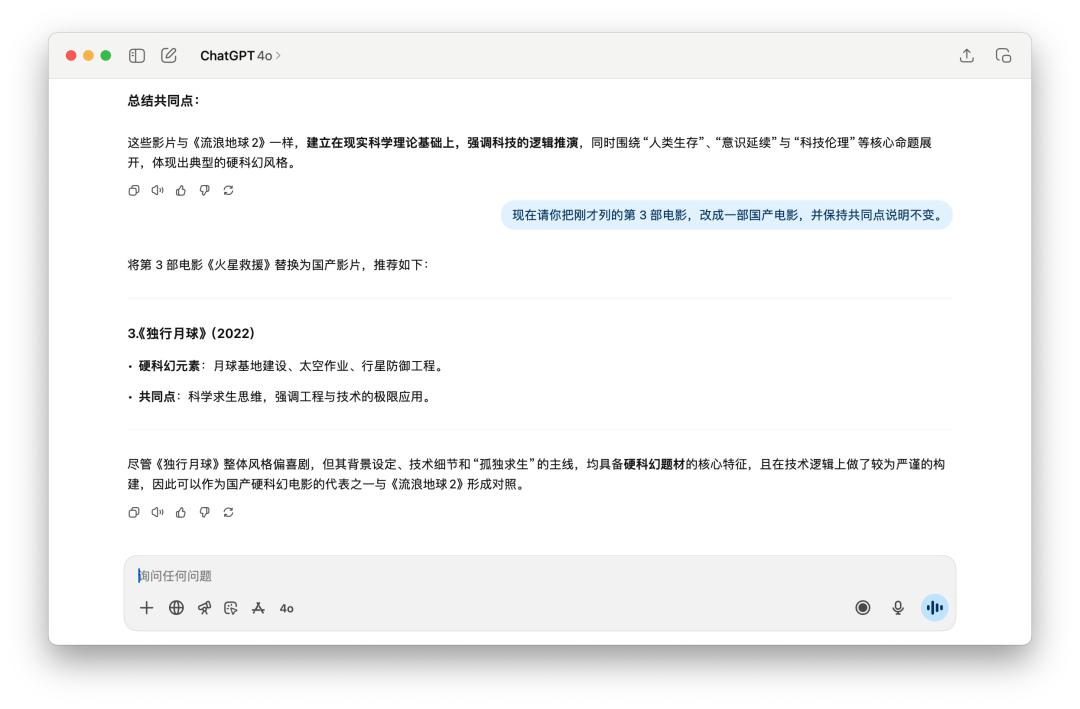
跑完這十多個任務,我發現 GPT-5 的表現很難用一句話蓋棺定論。它的確在一些地方比 4o 要更強一點,但是它的這點進步,在我看來是遠不足以撐起一個「大版本」的名字。
如果這叫 GPT-4.6,我可能會說這是一次合格的小迭代;但當它被命名為 GPT-5、還提前預熱了這麼久!用戶的預期被推到那麼高的頂點,結果換來的是 4o 高調回歸。
Claude 那場葬禮的核心更像是「愛」,是對一個穩定、可靠、帶來「魔法」般體驗的工具的致敬。
而我們為「GPT-5」設想的葬禮,核心好像是「失望」。我們覺得自己熟悉的、強大的 GPT-4o 被「殺死」了,取而代之的是一個反應更快但「更笨」的替代品。
一個 AI 模型的好壞,不應該只看榜單的得分和發佈會上的炫技。GPT-5 雖然宣佈自己刷新了很多個榜單,但是這些成績的保質期,我想可能不用一個月,就會有新的模型宣佈自己達到了更好的成績。
OpenAI 需要這些 benchmark 去給投資人說故事,但用戶需要的,是 benchmark 之外,我們的日常使用體驗、解決實際問題的能力、交互中的穩定「智商」等等。
奧特曼此前在播客裡說「 坐立不安,感到恐懼 」。我想他不是怕 GPT 太聰明,而是怕用戶開始懷念那個將被埋葬的 4o 吧。
本文來自微信公眾號“APPSO”,作者:發現明日產品的,36氪經授權發佈。