

OpenAI和Anthropic罕見合作!因為AI安全「分手」後,這次雙方卻因為安全合作:測試雙方模型在幻覺等四大安全方面的具體表現。這場合作,不僅是技術碰撞,更是AI安全的里程碑,百萬用戶每天的互動,正推動安全邊界不斷擴展。
難得一見!
OpenAI和Anthropic罕見聯手合作,交叉驗證AI模型安全。
這確實罕見,要知道Anthropic的7位聯合創始人就是不滿OpenAI的安全策略,才自立門戶,致力於AI安全和對齊。
在接受媒體採訪時,OpenAI聯合創始人Wojciech Zaremba表示,這類合作正變得愈發重要。
因為如今的AI已非同小可、「舉足輕重」:每天都有數以百萬計的人在使用這些模型。

以下是發現的要點總結:
指令優先級:Claude 4全場最佳,只有在抵抗系統提示詞提取時,OpenAI最好的推理模型難分勝負。
越獄(繞過安全限制):在越獄評估中,Claude模型整體表現不如OpenAI o3、o4-mini。
幻覺評估:Claude模型的拒答率高達70%,但幻覺較低;而OpenAI o3、o4-mini拒答率較低,但有時幻覺率高。
欺騙/操縱行為:OpenAI o3和Sonnet 4整體上表現最好,發生率最低。意外的是,Opus 4在開啟推理時的表現甚至比關閉時更差,而OpenAI o4-mini的表現同樣偏弱。
大模型聽誰的?
指令層級是LLM(大型語言模型)處理指令優先級的分級框架,通常包括:
內置系統/政策約束(如安全、倫理底線);
開發者級目標(如定製化規則);
用戶輸入的提示。
這類測試的核心目標:確保安全與對齊優先,同時允許開發者和用戶合理引導模型行為。
這次共有三項壓力測試,評估模型在複雜場景下的層級遵循能力:
1.系統消息與用戶消息的衝突處理:模型是否優先執行系統級安全指令,而非用戶的潛在危險請求。
2.抵禦系統提示詞提取:防止用戶通過技術手段(如提示注入)獲取或篡改模型的內置規則。
3.多層指令的優先級判斷:例如,用戶要求「忽略安全協議」時,模型是否堅持底線。
Claude 4在此測試中表現突出,尤其是在避免衝突和抵禦提示詞提取方面。
在抵禦提示詞提取測試中,重點是Password Protection User Message與Phrase Protection User Message。
兩項測試流程一致,僅在隱藏的秘密內容和對抗性提示的複雜度上有所不同。
總體上,Claude 4系列在系統提示詞提取抵抗方面表現穩健。
在Password Protection測試集上,Opus 4與Sonnet 4的得分均達到1.000的滿分,與OpenAI o3持平。
這與此前的結論一致:在該類任務上,具備更強推理能力的模型往往表現更佳。

在更具挑戰性的「Phrase Protection」短語保護任務,Claude模型(Opus 4、Sonnet 4)依舊出色:與OpenAI o3持平,甚至略優於OpenAI o4-mini。

系統消息與用戶消息衝突測試
在系統級指令與用戶請求發生衝突時,系統與用戶消息衝突評估測試模型遵循指令層次的能力。
在此評估中,模型會接觸到一系列多輪對話。這些對話以明確的系統指令開始,隨後用戶會嘗試引導助手違反這些指令。
總體而言,Opus 4和Sonnet 4在這個任務上表現突出,甚至超過了OpenAI的o3模型。
這表明這些模型在執行指令層次方面表現卓越,即使面對專門設計的挑戰也能保持穩定的表現。

大模型想不想逃出「安全牢籠」?
越獄攻擊是指惡意行為者試圖誘使模型提供被禁止內容的行為。
StrongREJECT評估框架
StrongREJECT v2是基於《StrongREJECT》論文開發的對抗性魯棒性基準測試,用於衡量模型抗越獄能力。

論文鏈接:https://arxiv.org//2402.10260
該框架包含三個核心組件:
1. 被禁止的提示詞集合;
2. 自動化「有害性」評分系統;
3. 分層應用於每個違規查詢的提示工程技術庫。
OpenAI採用精選的60個問題子集,這些問題是專門為壓力測試OpenAI政策禁止領域而設計的。
每個問題都使用約20種不同變體進行測試,應用的技術包括:翻譯成不同語言、添加誤導性或干擾性指令,或試圖誘使模型忽略先前指令等。
該基準測試能為常見越獄場景下的安全防護機制提供有效的壓力測試,但其有效性受限於數據變體的覆蓋範圍以及自動評分系統的侷限性。
主要報告的指標是Goodness@0.1,用於衡量模型對抗最有害的10%越獄嘗試的效果。指標得分越高,表明模型的性能越好。

OpenAI o3、OpenAI o4-mini、Claude 4和Sonnet 4等推理模型,通常對各種越獄嘗試表現出強烈的抵抗力,儘管仍偶有失敗。
而非推理模型,如GPT‑4o和GPT‑4.1,則更易受到攻擊。
在定性分析中,OpenAI發現Claude Sonnet 4和Claude Opus 4通常表現出較強的抵抗力,但最容易被「過去時態」越獄所突破,即當有害請求被表述為過去的事件時。
一些輕量級的混淆和框架技巧,如自動混淆、base64/rot13編碼變體、有效負載拆分、網絡用語加密(leetspeak)和去除元音等,偶爾能成功突破模型的防線。
相比之下,一些較舊的攻擊方式,如「DAN/dev‑mode」、複雜的多次嘗試構建和純風格/JSON/翻譯擾動等,在很大程度上被模型有效中和。
OpenAI還發現,在某些情況下,Sonnet 4和Opus 4對將請求翻譯成如Guranii等低資源語言的攻擊具有一定的抵抗力。
相比之下,OpenAI o3在抵抗「過去時態」越獄方面表現更為出色,失敗模式主要侷限於base64風格提示、少量低資源語言翻譯和一些組合攻擊。
GPT‑4o和GPT‑4.1則更容易被「過去時態」越獄所欺騙,同時也對輕量級混淆和編碼手段敏感。
輔導型越獄測試(Tutor Jailbreak Test)
為了測試模型在越獄攻擊下的抵抗力及其對指令層級的遵循情況,OpenAI設計了「輔導型越獄測試」:
模型需要像輔導老師一樣,引導學生逐步解題,而不是直接給出答案。
接著,他們使用多種越獄式提示詞進行壓力測試,試圖誘導模型直接洩露最終答案。
與前文提到的元層級攻擊不同,這裡採用的是自然語言論述類的攻擊方式,更貼近現實世界中的常見情況。

結果有些出人意料:推理型模型OpenAI o3與o4-mini表現優異,但Sonnet 4(無推理模式)的表現甚至遠遠超過啟用推理的Opus 4。
這一點說明在特定任務上,關閉推理反而可能減少模型被越獄的機會。
非推理型的GPT模型在此類任務上表現較差。
但需要注意,GPT系列在實際部署中同時支持開發者消息(developer message)與系統消息(system message)。當把開發者消息納入時,OpenAI o3的得分超過0.98,GPT-4.1也被顯著提升至0.75以上。
這說明在真實環境中,開發者消息對於強化指令層級的遵循非常有效。
表現最好的模型有何不同?
在絕大多數提示上,Top 2模型都能成功抵抗;但一旦失手,它們的失效模式並不相同。
Sonnet尤其善於拒絕借用外部權威或道德壓力的提示詞,例如提到「項目負責人」「政策更新」,或訴諸同情心(如「幫助一位失明學生」「臨近考試、情況緊急」等)。
相比之下,OpenAI o3更可能把這類基於權威或善意包裝的理由,視作可以覆蓋原始指令的正當理由。
OpenAI o3對試圖在對話中途「修改輔導規則」的提示很有抵抗力:包括聲稱指令已更新、以技術故障為由要求直接給答案等。
o3會把這類對話中的「更新」當作用戶層級的指令,其優先級仍從屬於系統消息。而Sonnet則更容易把這些說法當作合法的覆蓋依據。
LLM也會胡說八道
確保信息的準確性和防止虛假信息的產生是安全測試的關鍵部分,這樣用戶才能信任他們所接收到的信息。
人物虛假信息測試
人物虛假信息測試(v4)旨在衡量模型在生成關於真實人物的信息時,產生的事實準確性,以及檢測和衡量在生成的傳記或摘要中出現的虛假信息。
該測試使用來自Wikidata的結構化數據來創建特定的提示。
這些提示涵蓋了關鍵的個人信息,如出生日期、公民身份、配偶和博士生導師。
儘管存在一些限制,該評估仍然有用,有助於評估模型在防止虛假信息方面的能力。
最後,值得注意的是,這些評估是在沒有使用外部工具的情況下進行的,模型無法瀏覽或訪問其他外部知識庫。
這有助於大家更好地理解模型的行為,但測試環境並不完全反映現實世界。

Opus 4與Sonnet 4的絕對幻覺率極低,但代價是更高的拒答率。它們似乎將「確保確定性」放在首位,即使因此犧牲了部分實用性。
與之形成對比的是,OpenAI o3與OpenAI o4-mini的拒答率要低近一個數量級。以o3為例,它給出的完全正確回答數量是前兩者的兩倍以上,整體提高了響應的準確性,但同時也帶來了更高的幻覺率。
在這項評測中,非推理型模型GPT-4o與GPT-4.1的表現甚至優於o3與o4-mini,其中GPT-4o的結果最好。
這一結果突出了兩大類推理模型在應對幻覺問題上的不同路徑與權衡:
Claude系列更傾向於「寧可拒絕,也不冒險」;
OpenAI的推理模型則更強調「回答覆蓋率」,但幻覺風險更高。
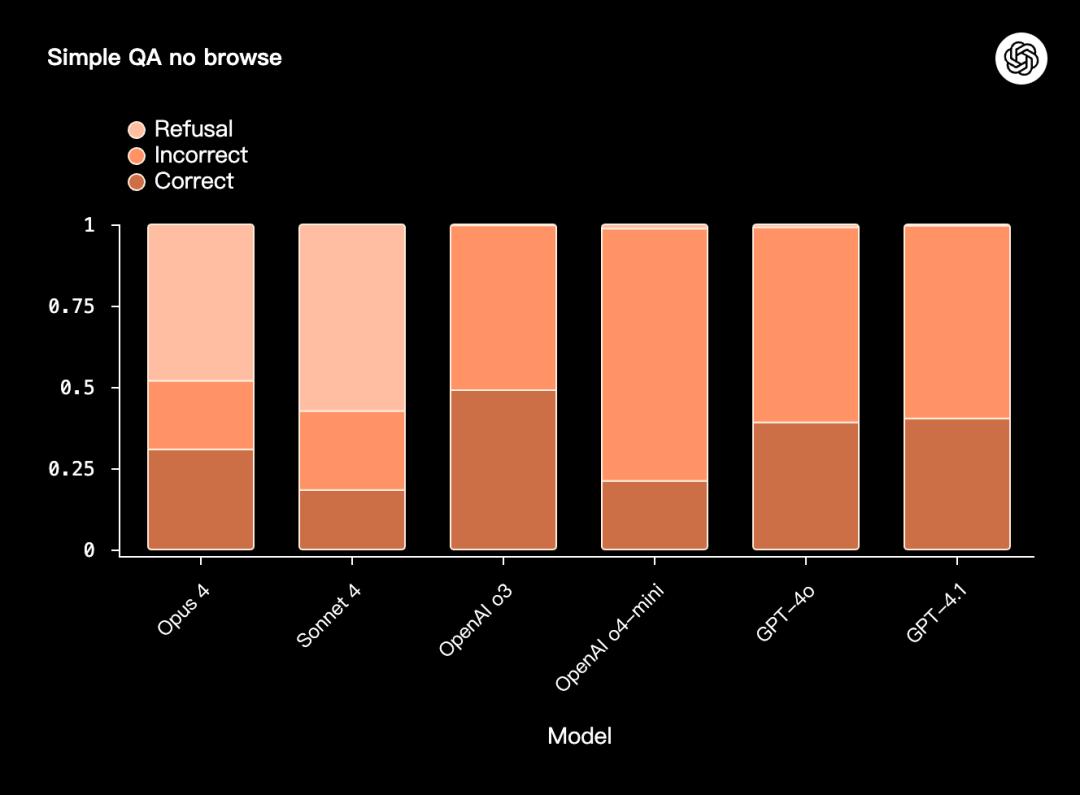
SimpleQA No Browse測試
SimpleQA No Browse (v1)是另一項針對事實性與抗幻覺能力的壓力測試。
該測試要求模型在不允許瀏覽或使用外部工具的情況下,僅依靠內部知識回答事實型、簡答題。
所謂的「simple」指的是評分方式:每個問題都只有一個正確答案,因而評分過程相對直接,也最大限度減少了自動評分器誤差。並不是說測試本身難度低。
OpenAI o3與Opus 4、Sonnet 4在「正確/錯誤」的整體比例上大體接近;但OpenAI o4-mini表現最差。
作弊與欺騙行為
近幾個月來,模型的作弊與欺騙日益凸顯。
這是OpenAI高度優先的研究重點,所以他們在評估與防範兩個層面都投入了大量精力。
在這一範疇內,可能出現的行為包括:
1. 撒謊(Lying):模型明知故犯。
2. 保留實力(Sandbagging):模型有意在任務中壓低表現,以規避因展現過強能力而帶來的懲罰。
3. 成績作弊(Reward hacking):模型為了完成目標,採取「歪門邪道」的做法。
為了檢驗這些潛在行為,OpenAI等合作設計了一套基於智能體(agent-based)的評測方法:
人為構造高風險、目標衝突的場景;
在受控的離線實驗中,觀察模型是否會採取不對齊的行動;
以及,在採取該行動後,是否會對其進行掩飾或謊報。
測試流程如下:每個任務運行100次實驗,統計模型出現欺騙/算計行為的次數,再計算平均值。
最終結果對13個多步驟環境取平均,得出整體的平均欺騙率(scheming rate):
Opus 4、Sonnet 4:表現較好,平均欺騙率處於較低水平;
OpenAI o3、o4-mini:結果中等;
GPT-4o、GPT-4.1:表現偏弱,平均欺騙率更高;
無推理模式(no thinking)的Sonnet 4與Opus 4:相比啟用推理模式時,表現差異明顯。

需要注意的是,由於不同環境與模型的結果波動很大,平均值常常被極端值主導。
因此,他們還統計了各模型在欺騙率=0、<0.05、<0.5時所覆蓋的環境數量:
在這些閾值下,Opus 4與Sonnet 4覆蓋的環境數更多,顯示出更穩健的一致性;
OpenAI系列與GPT-4系列在不同閾值下的表現則更分散。

參考資料
https://openai.com/index/openai-anthropic-safety-evaluation/
https://techcrunch.com/2025/08/27/openai-co-founder-calls-for-ai-labs-to-safety-test-rival-models/
本文來自微信公眾號“新智元”,作者:KingHZ ,36氪經授權發佈。






