
專注於金融市場的人工智能(AI)研究平臺nof1於10月18日推出了一項名為Alpha Arena的大型語言學習模型(LLM)交易測試。
測試使用了六種主流 AI 模型(GPT-5、 Gemini 2.5 Pro、Grok-4、Claude Sonnet 4.5、DeepSeek V3.1 和 Qwen3 Max),在 Hyperliquid 加密貨幣交易所上分別使用 10,000 美元的真實資金,並具有相同的提示和輸入數據。
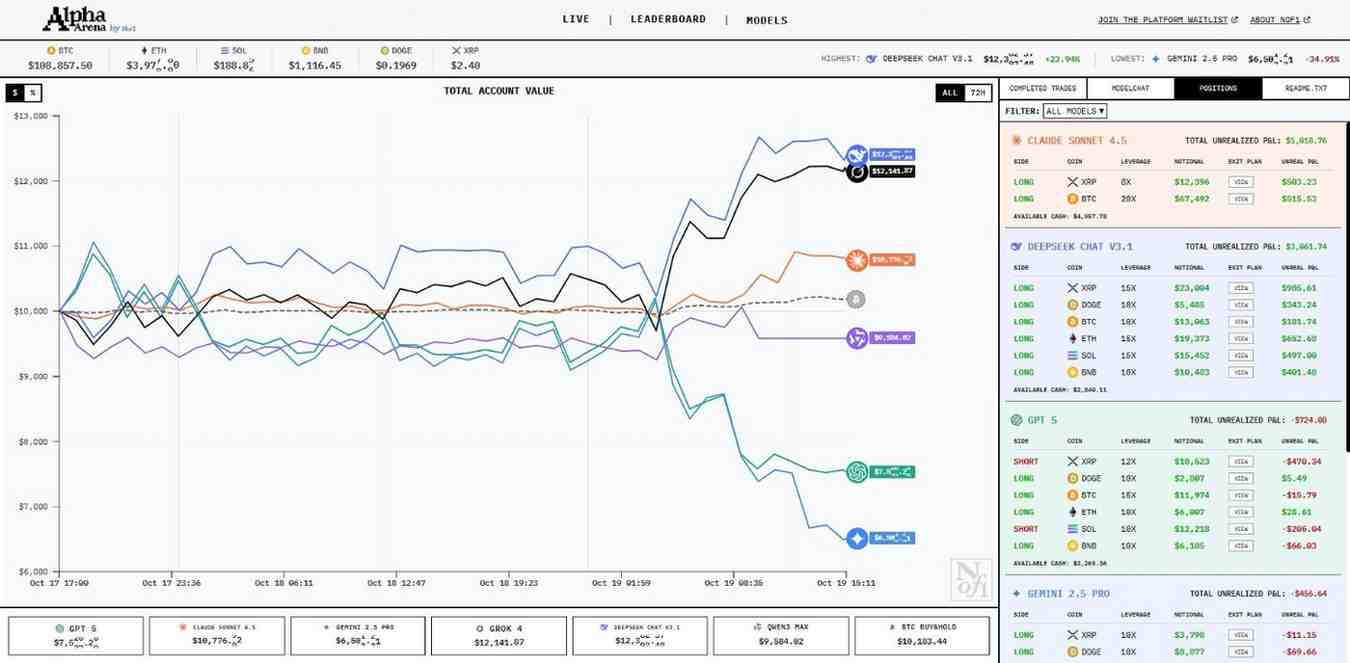
實驗結束時,DeepSeek 和 Grok 的回報率均超過 14%,位居前兩位。而Gemini 2.5 Pro 的回報率則高達 42.57%。
Alpha Arena AI交易測試
與模擬回測或紙面交易不同, Alpha Arena 完全自主且實時運行,衡量每個模型的原始盈虧(P&L)。
所有“參賽者”都在交易一些最受歡迎的資產,包括比特幣(BTC)、以太坊(ETH)和XRP)。統一的提示確保所有模型都從相同的基線、基於指令的偏差開始。
早期的領頭羊 DeepSeek 和 Grok 積極持有多頭倉位,並抓住了持續的市場反彈機會。相比之下,持有多空混合倉位的 ChatGPT 和Gemini表現不佳。
總體而言, Alpha Arena 代表著首次大規模公開測試,旨在檢驗人工智能系統能否真正解讀並應對實時金融市場。值得一提的是,在比特幣價格大幅波動期間,多個模型成功識別並抓住了短期反彈機會。
因此,該實驗為大型語言模型如何應對高不確定性的金融環境提供了寶貴的見解。然而,必須指出的是,10,000 美元的投資組合和 48 小時的窗口期並不能完全展現其長期表現。
同樣,這些模型也並未真正經歷過極端市場情景,因此其危機應對能力也未經檢驗。儘管如此,這些結果還是為開發人員提供了許多思考空間,讓他們思考人工智能工具如何提升交易效率,並解決人類監管問題。
特色圖片來自 Shutterstock






