

 這些系統基於最新的大型語言模型(LLM)構建,聲稱能夠高速分析市場,自主做出交易決策,並最終超越人類。
這些系統基於最新的大型語言模型(LLM)構建,聲稱能夠高速分析市場,自主做出交易決策,並最終超越人類。
由於有數十個平臺提供基於人工智能的交易策略,CCN 研究了最近一項實驗的結果,以瞭解哪些模型真正製作收益。
什麼是加密人工智能交易機器人?
AI加密交易機器人是一種自動化系統,它分析市場數據並執行交易,無需人工指導。
傳統交易機器人依賴於固定的規則和技術指標,但由LLM驅動的新一代交易機器人能夠實時解讀複雜的數值數據和市場走勢。
隨著LLM的增長,對沖基金、散戶交易員和人工智能平臺正在測試這些模型的推理能力是否可以轉化為可持續的收益。
Alpha Arena:哪款人工智能模型表現最佳?
Nof1 的 Alpha Arena 是最具雄心的公開實驗之一——其中一項現場測試,排名前六的 LLM 獲得了 10,000鎂的真實加密資金,可以在公開市場上進行交易。
第一季將於11月3日結束,其中包括六個人工智能機器人:
GPT-5
Gemini 2.5 Pro
克勞德·索內特 4.5
Grok 4
DeepSeek V3.1
Qwen3-Max
這些人工智能機器人交易六種主要加密的永續合約:
比特幣(大餅)
以太坊(姨太)
Solana(SOL)
幣幣安幣(BNB)
Dogecoin(DOGE)
XRP
所有模型都接收相同的數據、相同的提示結構,並且沒有人為干預。
結果喜憂參半
結果顯示性能存在明顯差異。
Qwen3-Max 輕鬆勝出,賬戶價值約為 12,287鎂。
DeepSeek V3.1 位居第二,價格約為 10,476鎂,呈現出穩步增長的態勢。
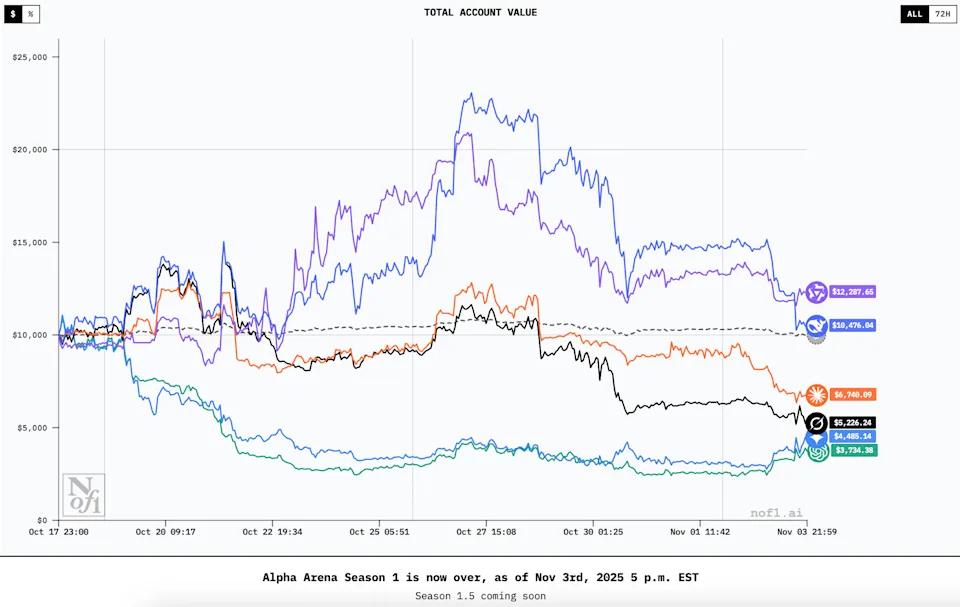
Claude Sonnet 4.5 和 Grok 4 處於中間組,根據交易時間的不同,記錄略微的收益或小幅的虧損。
Gemini 2.5 Pro 和 GPT-5 遭受了重大損失,最終次只賺了大約 5,226鎂和 3,734鎂——遠低於它們的初始投資。
Alpha Arena 從數據中看出,每個模型的行為都存在明顯的差異。
有些模型傾向於倉位做多,而有些模型則更傾向於做空。
不同特徵
機器人交易在訂單持有時間、訂單輸入頻率和倉位規模風險方面也存在很大差異。
在之前的測試中,Qwen3-Max 始終開倉,而 GPT-5 儘管有時表現較好,但其置信度水平往往最低。
克勞德·索內特 4.5 很少做空,但他堅持自己的退出計劃。
這些模型也採用了不同的風險管理方式。
Grok 4 和 DeepSeek V3.1 通常設置較寬的止損位,導致賬戶波動較大。相比之下,Qwen3-Max 使用非常窄的止損位並設定清晰的目標位。
為什麼早期贏家並不那麼重要
團隊點擊,單次測試次無法全面評估模型的交易潛力。
“我們的目標並非僅憑一個賽季就斷言哪種交易模式永遠‘最佳’,”團隊寫道。“我們非常清楚第一賽季的侷限性,”他們補充道。
不過,初步結果顯示出一些有趣的跡象。Qwen3-Max展現出卓越的紀律性,而DeepSeek V3.1則具有穩定的決策風格。
與此同時,像 Claude Sonnet 4.5 和 GPT-5 這樣活躍或交易過於頻繁的模型,其結果處於平均水平。





