

本週,兩家美國人工智能實驗室發佈了開源模型,但各自採用截然不同的方法來解決同一個問題:如何與中國在公共人工智能系統領域的統治地位競爭。
Deep Cogito 發佈了 Cogito v2.1,這是一個擁有 6710 億個參數的龐大模型,其創始人 Drishan Arora 稱之為“美國公司最好的開放權重 LLM”。
艾倫人工智能研究所反駁道,事情並非如此簡單。該研究所剛剛發佈了 Olmo 3,並稱其為“最佳完全開源的基礎模型”。Olmo 3 標榜完全透明,包括其訓練數據和代碼。
具有諷刺意味的是,Deep Cognito 的旗艦模型卻是建立在中國的技術基礎上的。Arora 在 X 大會上承認,Cogito v2.1 “從 2024 年 11 月起,基於開源的 Deepseek 基礎模型進行了分支”。
這引發了一些批評,甚至引發了關於微調中國模型是否算作美國人工智能進步,或者這是否僅僅證明了美國實驗室落後了多少的爭論。
https://t.co/wHcfNQIJzJ pic.twitter.com/N7x1eEsjhF
— 盧卡·索爾代尼 (Luca Soldaini) 🎀 (@soldni) 2025 年 11 月 19 日
美國公司推出的最佳公開組LLM
這很酷,但我不確定是否應該強調“美國”部分,因為基礎型號是 DeepSeek V3 https://t.co/SfD3dR5OOy
— Elie (@eliebakouch) 2025 年 11 月 19 日
無論如何,Cogito 相對於 DeepSeek 的效率提升是真實存在的。
Deep Cognito 聲稱 Cogito v2.1 生成的推理鏈比 DeepSeek R1 短 60%,同時保持了具有競爭力的性能。
Arora 稱之為“迭代提煉和放大”——通過自我改進循環來訓練模型,使其發展出更好的直覺——這家初創公司僅用了 75 天就利用 RunPod 和 Nebius 的基礎設施訓練出了自己的模型。
如果基準測試結果屬實,這將是目前由美國團隊維護的最強大的開源LLM。
為什麼這很重要
到目前為止,中國在開源人工智能領域一直處於領先地位,美國公司為了保持競爭力,越來越依賴中國的基礎模型——無論是悄悄地還是公開地。
這種動態存在風險。如果中國實驗室成為全球開放人工智能的默認平臺,美國初創企業將失去技術獨立性、議價能力以及制定行業標準的能力。
開放權重人工智能決定誰控制著下游所有產品所依賴的原始模型。
目前,中國開源模型(DeepSeek、Qwen、Kimi、MiniMax)在全球範圍內佔據主導地位,因為它們價格低廉、速度快、效率高,並且不斷更新。
許多美國初創公司已經利用了這些技術,即使他們公開否認這一點。
這意味著美國企業正在利用外國的知識產權、培訓體系和硬件優化技術來構建業務。從戰略角度來看,這使美國重蹈覆轍,再次面臨半導體制造領域的困境:越來越依賴他國的供應鏈。
Deep Cogito 的方法——從 DeepSeek 的一個分支開始——展現了其優點(快速迭代)和缺點(依賴性)。
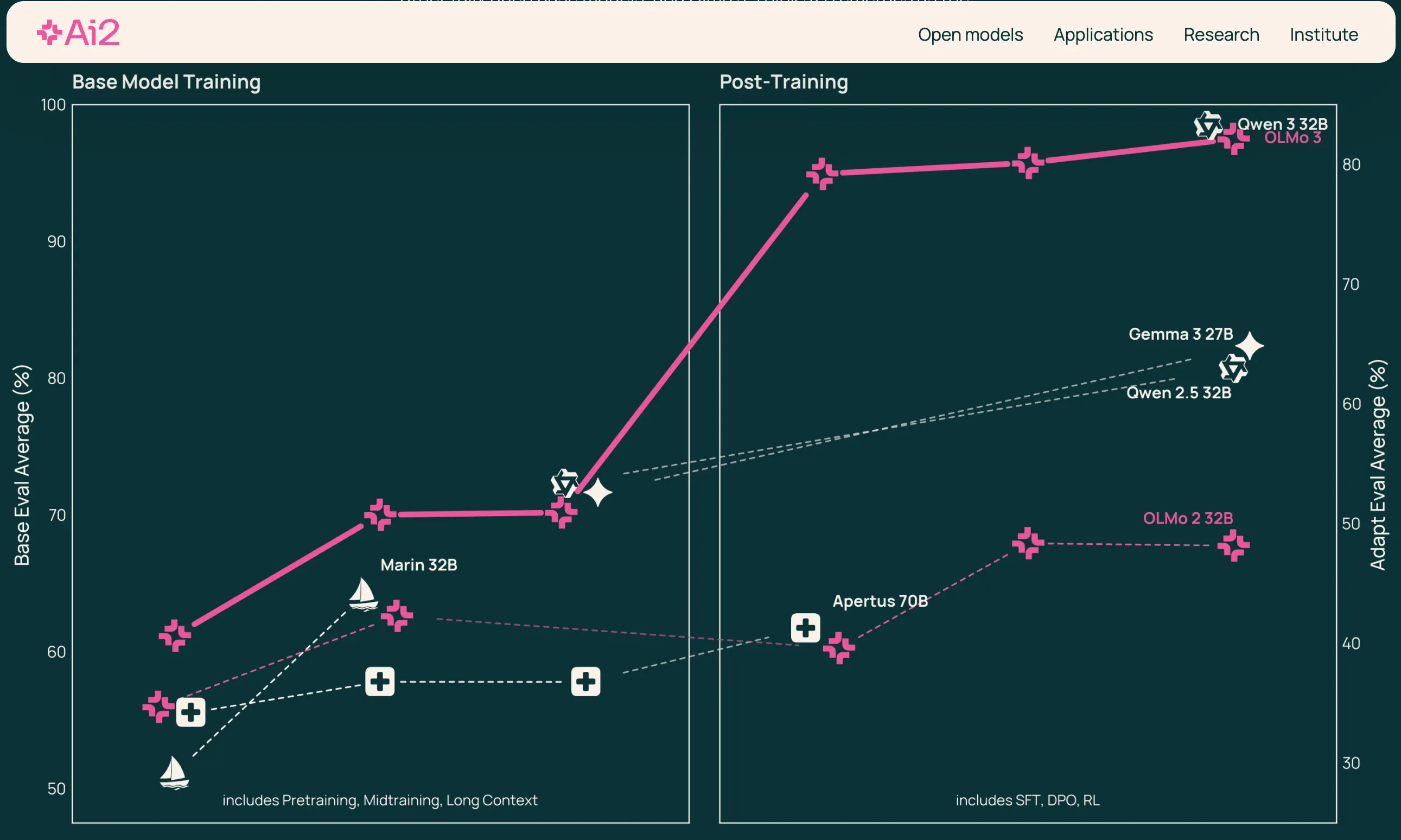
艾倫研究所的做法——以完全透明的方式構建 Olmo 3——展現了另一種選擇:如果美國想要在開放人工智能領域佔據領先地位,就必須從數據、訓練方案到檢查點,重建整個技術棧。這需要耗費大量人力,而且耗時較長,但卻能確保美國對底層技術的自主權。
理論上,如果您已經喜歡 DeepSeek 並在線使用它,Cogito 大多數情況下都能提供更好的答案。如果您通過 API 使用 Cogito,您會更加滿意,因為其效率更高,您只需花費更少的費用就能獲得高質量的回覆。
艾倫研究所採取了截然相反的做法。Olmo 3 系列模型全部與 Dolma 3 一同發佈,Dolma 3 是一個從零開始構建的包含 5.9 萬億個標記的訓練數據集,此外還包括完整的代碼、配方以及每個訓練階段的檢查點。
該非營利組織發佈了三種模型變體——基礎模型、思考模型和指導模型——分別具有 70 億和 320 億個參數。
該研究所寫道:“人工智能領域的真正開放不僅僅關乎獲取途徑,更關乎信任、問責和共同進步。”
Olmo 3-Think 32B 是第一個達到如此規模的完全開放推理模型,它使用大約只有 Qwen 3 等類似模型六分之一的標記進行訓練,同時取得了具有競爭力的性能。
Deep Cognito 於 8 月獲得由 Benchmark 領投的 1300 萬美元種子輪融資。這家初創公司計劃發佈參數量高達 6710 億的前沿模型,這些模型將使用“更強大的計算能力和更好的數據集”進行訓練。
與此同時,英偉達為 Olmo 3 的開發提供了支持,副總裁 Kari Briski 稱其對於“開發者利用開放的、美國製造的模型來擴展 AI”至關重要。
該研究所使用谷歌雲的 H100 GPU 集群進行訓練,計算需求比 Meta 的 Llama 3.1 8B 減少了 2.5 倍。
Cogito v2.1 可在此處免費在線測試。該模型可在此處下載,但請注意:它需要性能非常強大的顯卡才能運行。
Olmo 可在此處進行測試。模型可在此處下載。這些模型對用戶更加友好,具體取決於您選擇哪一個。






