

0G Labs 的定位並非另一個人工智能區塊鏈。它正在構建一個去中心化的人工智能操作系統,將存儲、數據可用性、計算和結算統一到一個集成的堆棧中。
0G 的核心創新在於基礎設施設計而非模型。通過優化存儲以實現快速讀取、將數據可用性與存儲證明相結合,以及實現可驗證計算,0G 直接針對阻礙鏈上人工智能應用的物理限制。
0G的長期成功與其說是取決於技術上的雄心壯志,不如說是取決於執行力。真正的AI工作負載、持續的使用以及安全的去中心化運營必須快速增長,才能證明其集成架構和代幣經濟的合理性。

人工智能暴露出的基礎設施差距
多年來,加密網絡一直專注於一項明確的任務:安全地轉移價值、結算交易、維護賬本的一致性和可靠性。正因如此,大多數第一層區塊鏈都針對交易進行了優化,而非大規模數據處理或繁重的計算。
人工智能很快就改變了這種平衡。
現代人工智能不僅僅在於更智能的模型,它還由海量數據流驅動。訓練通常需要從千兆字節到拍字節級別的數據集。推理過程會提取大量的上下文信息,並生成連續的日誌。人工智能體並非生成一個結果就停止運行,而是持續運行,不斷生成狀態、內存和交互數據流。
真正的問題不在於區塊鏈能否存儲數據,而在於從成本和性能角度來看,在鏈上以人工智能規模存儲和讀取數據一直都不現實。
存儲成為第一個瓶頸
第一個限制出現在存儲層。
在傳統區塊鏈上,鏈上存儲成本極其高昂。即使是專為去中心化存儲而構建的網絡,也常常為了持久性而犧牲速度。它們中的許多網絡在冷歸檔方面表現出色,但在應用程序需要頻繁快速讀取數據時卻顯得力不從心。
人工智能工作負載有所不同。它們具有活躍性、持續性和對延遲高度敏感的特點。
當數據檢索速度變慢時,整個人工智能工作流程就會失去價值。
數據可用性無法跟上人工智能規模的發展速度。
與此同時,數據可用性很快達到極限。
大多數模塊化數據處理系統都是為Rollup交易數據而設計的,其吞吐量通常以兆字節/秒 (MB/s) 為單位。人工智能數據流的規模則完全不同。一旦數據處理層成為瓶頸,就會限制其上構建的所有內容。
人工智能輸出缺乏驗證
另一個關鍵問題來自驗證環節。
大多數人工智能系統仍然像黑箱一樣運行。用戶無法證明哪個模型產生了輸出結果,也無法驗證使用了哪些數據,更無法確認任務是否已完整、正確地執行。在金融、治理或自動化執行等高價值領域,這種缺乏證明的情況是不可接受的。
鑑於這些限制,0G Labs 直言不諱地指出:人工智能和 Web3 的融合不會通過改進界面來實現,而只能通過圍繞數據、帶寬和可驗證計算重建基礎設施來實現。
為什麼 0G 將自己定義為 dAIOS
在人工智能的語境下,許多項目自稱為“人工智能鏈”。有些專注於GPU交易市場,有些則提供模型託管服務。0G則另闢蹊徑,將自身定義為去中心化人工智能操作系統(dAIOS)。
這一定義反映的是一種結構性決策,而非市場營銷選擇。
從區塊鏈思維到操作系統思維
傳統操作系統管理本地資源。它調度 CPU 時間、分配內存、控制磁盤訪問。最重要的是,它提供穩定的接口,使開發人員無需處理硬件的複雜性。
0G認為,人工智能經濟需要一個類似的分佈式層。在這種環境下,資源不再侷限於單臺機器,而是包括全球存儲、帶寬、計算能力和共識機制。
開發人員不需要將獨立的存儲網絡、數據架構層、計算市場和結算鏈組合在一起,而需要一個像統一系統一樣運行的堆棧。
dAIOS背後的承諾
基於這一理念,0G 將存儲、數據可用性、計算和結算視為單一平臺中協調運作的各個部分。這一選擇塑造了整個架構。
這還具有更廣泛的意義。在Web 2時代,人工智能變得高度集中化。模型和數據由少數幾家公司控制。訪問權限受到限制,審計也很少見。0G試圖將人工智能推向更加開放、更像實用工具的模式。
在這種願景下,數據歸貢獻者所有。模型可以公開存儲和追蹤。計算過程可以得到驗證。訪問權限由市場定價,而不是由單一平臺控制。
這項計劃雄心勃勃,但也充滿風險。如果成功,0G 將成為眾多人工智能應用的基礎層。如果失敗,它可能會變成一個複雜但需求不足的系統。
堆棧內部:0G 是如何構建的
要了解 0G,瞭解數據在系統中的傳輸方式會有所幫助。
0G鏈作為協調層
0G Chain 作為協調和結算層,基於 CometBFT 構建,專注於高吞吐量和快速最終確認。同時,它與 EVM 保持兼容。
這種設計降低了開發者的門檻。現有的工具和智能合約可以幾乎無縫地遷移。雖然這一層並非最具顛覆性的創新,但它卻是維繫整個系統運轉的關鍵。
針對人工智能工作負載重新設計的存儲
真正的區別體現在 0G 存儲上。
大多數去中心化存儲系統優先考慮長期持久性,因此通常會犧牲讀取性能。而人工智能工作負載則恰恰相反,訓練和推理依賴於快速且頻繁的讀取。
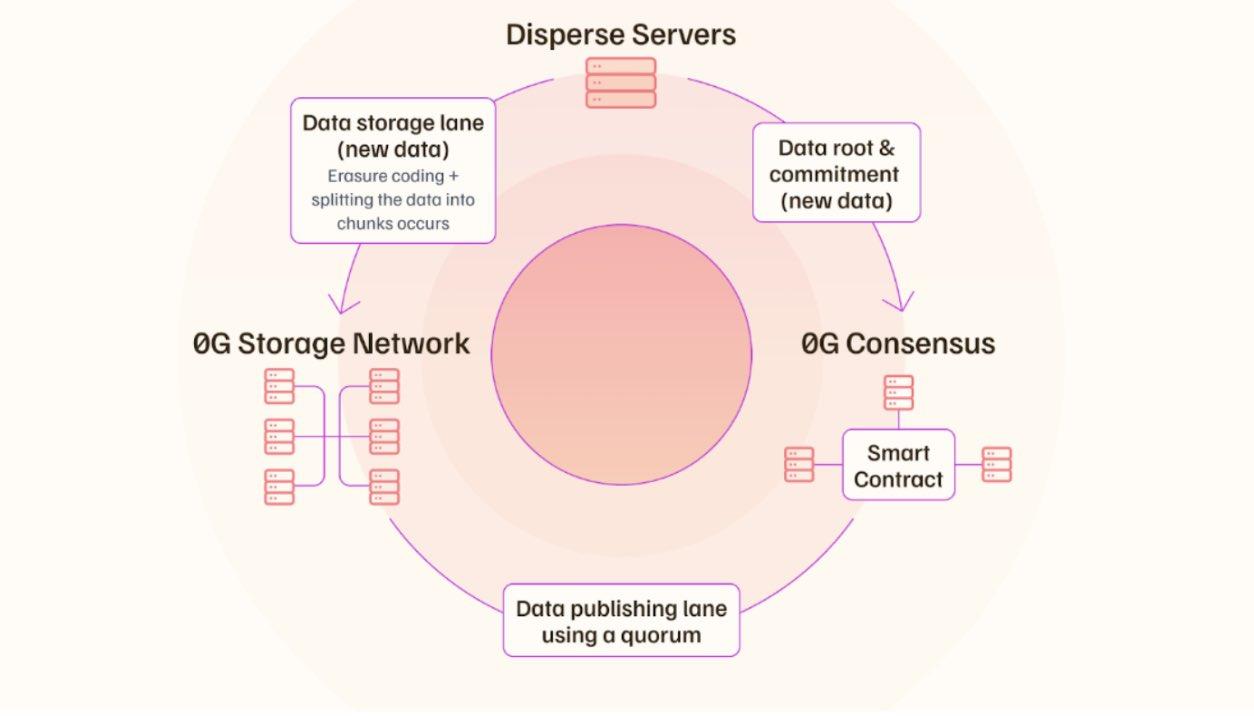
0G 存儲採用雙通道結構。一條通道承載哈希值、元數據和存儲發生的證明,針對共識進行了優化。另一條通道處理大型文件,並允許數據在存儲節點之間直接傳輸,而不會使鏈過載。
為了支持這種設計,0G引入了隨機訪問證明(Proof of Random Access,簡稱PoRA)。網絡會隨機向存儲節點發出挑戰,要求它們在短時間內返回小的數據片段。快速響應會獲得獎勵,而緩慢響應則會受到懲罰。這促使運營商採用高性能存儲,而不是冷歸檔。
數據可用性與存儲集成
在數據可用性層,0G 遵循與大多數 DA 網絡不同的模型。
數據不再需要DA節點下載和傳播完整的數據塊,而是直接寫入存儲層。DA層專注於驗證可用性證明和簽名。因此,原本佔用大量帶寬的過程變成了驗證任務。
如果這種方法能夠大規模應用,它將顯著提高系統的性能上限。人工智能規模的數據流不再受限於為Rollup事務構建的數據處理層。存儲和數據處理將作為一個緊密集成的系統運行,而不是兩個獨立的組件。
可驗證的計算和對齊節點
在計算方面,0G 通過去中心化市場將 GPU 供應與 AI 需求連接起來。然而,其重點不僅限於硬件租賃。該系統旨在驗證任務是否正確執行。
0G 強調加密驗證和使用可信執行環境,以降低出現錯誤結果或數據洩露的風險。
此外,AI對齊節點扮演著獨特的角色。這些節點不生成模塊,而是監控模型行為和輸出模式,以檢測異常或潛在的篡改行為。它們的目的是在系統層面引入持續的監控。
代幣設計與市場現實
如此複雜的系統需要強有力的激勵機制。驗證節點、存儲節點和計算服務提供商必須長時間保持在線並快速響應。
通貨膨脹模型和代幣角色
0G 採用類似於以太坊或Solana等網絡的初始供應量和長期通脹機制。該代幣用於支付交易費用、存儲費用、節點獎勵和參與治理。
從工程角度來看,這種設計有利於長期安全。從市場角度來看,它引入了一些重要的考量因素。
解封和融資壓力
關鍵因素之一是解鎖時間表。團隊分配、早期支持者和節點相關分配會隨著時間的推移增加供應量。除非在主要解鎖窗口之前出現實際需求增長,否則這將造成供應壓力。
另一個因素是包含代幣購買承諾的融資結構。對於基金會而言,這提供了長期的資金穩定性。但對於二級市場而言,如果頻繁使用,則可能導致持續的股權稀釋預期。
核心不確定性
最重要的風險不是競爭,而是運營執行。
高吞吐量系統通常依賴於先進的硬件和數據中心。在早期階段,這可能會帶來一些不易察覺的中心化風險。如果關鍵服務嚴重依賴大型雲服務提供商,則該系統會繼承 Web2 式的信任假設。
過去的事件表明,即使規程保持不變,操作上的缺陷也會迅速損害人們的信心。
長期賭注
歸根結底,0G 押注的是長期的變革。
如果人工智能代理成為數字交互的主流形式,對快速、低成本且可驗證的數據和計算的需求將持續增長。在這種情況下,dAIOS 堆棧可能會演變為真正的平臺層。
如果未來到來得更慢,或者開發者更喜歡可以輕鬆替換的模塊化工具,那麼 0G 必須證明深度集成能夠帶來足夠的價值,以證明這種權衡是合理的。
這是一場目標明確但競爭激烈的競賽。最終結果並非取決於承諾,而是取決於長期的持續使用和實際工作負載。
〈 0G 實驗室與構建去中心化 AI 操作系統的競賽〉 本文文章初步發佈於《 CoinRank 》。






