

共同支出啟發式方法在新型樣本外測試中嚴重失效
區塊鏈取證的基石——共同支出啟發式算法,在受控實驗中表現出的行為令人對其可靠性產生嚴重質疑。具體而言,它會在根本不存在結構和信號的地方檢測到它們,並且整體準確率極低。
這不僅對區塊鏈取證具有重大意義,而且對更廣泛的數字資產法律和合規生態系統也具有重大意義。這一單一啟發式方法是業內最大的取證和合規服務公司的基礎,併為全球眾多法律案件提供支持。我們認為這是首次對該啟發式方法的性能進行樣本外測試,結果表明其存在諸多侷限性。
令人擔憂的是,一項早在 2013 年就已發表,並被執法部門廣泛使用的技術,其準確性卻要等到 2025 年才能公開測試,而且測試的樣本數據集非常小。
值得注意的是,一項於2013年首次發表並在隨後幾年被執法部門廣泛使用的技術,其首次公開準確性測試結果卻要等到2025年才會發佈,而且測試數據集相對較小。此外,將我們的樣本外結果與之前的樣本內研究進行比較,發現存在與過擬合一致的跡象。這表明,整個行業的測試方法可能需要改進,因為用戶和服務提供商可能沒有充分驗證他們的工具,或者可能得到了截然不同的結果。
這些說法很有分量。以下是我們支持這些說法的計劃:
包含所有數據的詳細論文可在此處獲取。
這項工作建立在我們之前的工作之上,該工作表明Coinjoin 自 2009 年以來一直是比特幣的普遍現象,這促使我們提交了一份法庭之友意見陳述,認為共同花費啟發式方法在法庭上作為一種誤報最少的取證方法提出之前需要進行更嚴格的測試,就像美國訴斯特林戈夫案中發生的那樣。
隨後,我們開發了將ZK Mixer 交易轉換為 Coinjoin 交易的技術,從而開展了這項研究。
我們將其視為一項評估分類啟發式算法的科學練習,類似於其他模型測試。但我們始料未及的是,樣本外性能差異竟如此顯著。
我們最初的假設是,該啟發式方法的可靠性將支持執法部門向交易所等中間企業索取信息的要求,並且其結果足以滿足搜查令請求和類似的“可能原因”法律程序的要求。
我們原本預期會發現可靠性水平較低,需要更多佐證才能達到更高的法律標準。然而,我們驚訝地發現,錯誤率似乎只是未經證實的猜測,根本不應被用於支持任何執法活動。
這是一項單一研究,我們並不聲稱這些性能特徵可以推廣到所有情況,或者一定可以推廣到最重要的情況。
一項採用特定樣本外測試方法的研究並不能否定該技術的價值。然而,它確實表明,需要對區塊鏈分析進行更嚴格的測試,並重新審視法律體系如何評估區塊鏈分析。
即使撇開我們的具體發現不談,這種性質的全面測試在執法部門開始使用它們十多年後才首次出現,這本身就是一個問題。
樣本內測試與樣本外測試
開發任何任務的模型時,都必須從數據入手。對於分類模型(即給輸入數據點貼標籤的模型)而言,這些數據必須包含一組具有獨立且客觀可確定標籤的輸入點。
想象一下,構建一個模型,以人像照片為輸入,輸出人物的頭髮顏色。為了訓練和評估這個模型,你需要一個流程來標註每張照片的頭髮顏色。你需要“黃金標準”數據,其標註準確率必須達到100%。
如果你用 100 張照片訓練你的模型,然後用這 100 張照片測試模型的性能,這被稱為“樣本內”測試。
如果你用同一個模型在 100 張不同的照片上進行測試——這些照片以前從未有人正確標註過頭髮顏色——那就是“樣本外”測試。
通常情況下,我們預期樣本外性能會比樣本內性能差。一位工程師在比較兩個模型時,如果可以使用總共 200 張帶標籤的照片,通常會:
- 使用100張隨機選擇的照片訓練每個模型
- 評估另外100張照片的表現
- 重複此操作 100 次
- 比較兩種模型的平均樣本外性能
這個過程背後的擔憂是,對同一數據進行過多的訓練和測試可能會導致“過擬合”。
該模型可能會捕捉到數據中存在的非預期特徵,例如受試者的襯衫顏色、眼睛顏色、種族或其他特徵。
重要的是,這種類型的過擬合和由此產生的模型偏差不需要工程師有任何偏見或有意識的努力。
如果你的數據集中所有金髮女郎都有藍眼睛,你就無法確定模型是學會了檢測金髮還是藍眼睛。
如果所有金髮女郎都是男性,都留著鬍子,或者具有其他一些顯著特徵,那麼即使工程師沒有犯任何錯誤,該模型也可能存在偏見。
同樣,如果一家公司只有 200 張照片,卻花費數年時間建立模型,那麼所有的測試都不能算是真正的“樣本外測試”。工程師們根據上述過程中衡量的性能做出決策,而這個過程仍然依賴於同樣的 200 張照片。
現在,將規模擴大到20萬張照片、數百名工程師以及長達十年的模型構建。所有工具都依賴於數據集中的某些特徵,而這些特徵是人類無法察覺,但計算機卻能始終如一地識別出來,這似乎就合情合理了。
對於照片來說,這是可以控制的,因為帶標籤的照片供應幾乎是無限的。
DNA樣本、指紋以及許多其他法醫物證也基本如此,因為總能獲取更多數據。對於測速雷達槍而言,也很容易進行新的實驗。這類案例的測試數據比比皆是。
但是,如果你的模型研究的是極其罕見的疾病、熊貓交配、日食或極端天氣呢?
在這種情況下獲取更多數據並非易事。
廣義相對論的早期檢驗需要等待特定類型的日食或月食。此後數十年,物理學家們致力於設計更好、更可靠、更可重複的理論檢驗方法。巧妙的檢驗設計是科學的核心組成部分。
共同支出啟發式方法常用於分析非法區塊鏈服務,因為只有在政府逮捕嫌疑人或查獲軟件代碼、服務器或日誌後,才能獲得相關標籤。這導致數據集有限,可能需要多年時間才能完成分析,任何分析實際上都只是樣本內測試。
這與 DNA 檢測有著根本的不同,DNA 檢測是一種用於定罪罪犯的技術,可以使用任何來源的血液樣本進行樣本外測試。
本文旨在針對這一複雜案例設計更穩健的樣本外檢驗方法。我們承認,我們的方法並非完美無缺,也存在一些妥協和不足。
然而,另一種方法是將研究範圍限制在執法部門所掌握的服務範圍內,這是一種本質上不科學的做法。
如果測試只能在抓捕之後進行,那麼如何確定工具對仍在逃的罪犯(執法部門正在積極追捕的罪犯)是否有效呢?
Coinjoin — ZK Mixer 同構
我們的工作圍繞著一種將以太坊上的 ZK Mixer 數據轉換為類似比特幣 Coinjoin 混淆數據的方法展開。我們最近發表的一篇論文對此進行了詳細闡述,其中提供了嚴謹的定義和算法,精確地展示瞭如何在 ZK Mixer 和 Coinjoin 之間進行轉換。具體細節請參閱該論文。這裡我們僅對整個過程進行簡要概述,以幫助讀者建立直觀理解。
Coinjoin 有多個輸入和多個輸出。暫且假設總輸入量等於總輸出量。我們可以將所有輸入發送到同一個混合地址,然後從該地址分發所有輸出,從而將其轉換為一系列混合交易。這就是混合器的工作原理。
對於真正的攪拌機,我們不希望看到餘額先為零、然後變大、最後又變回零的“充值-清空”模式。相反,我們預期攪拌機內部的初始餘額會遠遠超過任何一次單筆交易的金額。
這可以通過將這些操作交錯串聯起來來實現。
如果第一次 Coinjoin 只提取了餘額的 10%,則將剩餘的 90% 存入下一次 Coinjoin,並重復此過程。通過這種方式串聯 Coinjoin,每次充值和提現的金額都小於兩輪之間轉移的餘額,這就是基於 Coinjoin 的混幣服務的運作方式。
現在反向映射應該很明顯了。
將所有 ZK Mixer 交易拆分成若干組,每組交易包含同一側的連續交易。例如,是否存在 7 筆連續的存款交易而沒有取款交易?如果存在,則構成一個包含 7 筆交易的批次。
連續四次提款而沒有存款?又是一批。
然後,將這些批次的連續對進行 Coinjoin 構建,同時將初始餘額結轉至下一批次。
這就是全部流程。
這個過程很簡單。Coinjoin 的工作原理是在兩個獨立的大型群體之間同時轉移資金,使得所有產出都來自所有投入。多次鏈式操作意味著所有產出都源自如此龐大且分散的投入集合,以至於無法輕易確定具體責任。這實際上在 Coinjoin 執行過程中混合了資金。
ZK Mixers 通過將資金混合在公共賬戶中來明確這一點。
手動運行這類服務相對簡單。
技術上的複雜性在於確保以下幾點的某種組合:
- 記錄銷燬速度非常快,任何政府都無法找回;
- 足夠的匿名性可以防止服務運營的歸屬;
- 現有記錄不足以將投入與產出關聯起來。
ZK Mixers 背後的理念是,僅靠公開記錄不足以進行可靠的追蹤,而且也不存在掌握特權信息的操作員。這需要高超的技術。但是,請注意以下兩點。
首先,確實存在足以對該服務進行去匿名化的信息。該系統是“零知識”的,因為公開信息包含所有權證明,但不會洩露任何關於存款的信息。但是,如果您知道是哪臺計算機生成了這些證明,以及它們在提交提款之前的位置,那麼去匿名化就成為可能。這些證明是零知識的,但相關信息確實存在於宇宙中。
其次,如果任何人都無法訪問或強制披露記錄,那麼位於安全地點的中央運營商同樣能夠有效運作。我們衡量的是公開記錄,而不是整個“系統”中的所有信息。
溯源是利用公開信息進行重構的過程。在此框架下,這些技術提供的混淆效果是等效的。
測試結果
如上所述,我們通常預期樣本外表現會比樣本內表現更差。
但是,我們也關心樣本外表現與樣本內表現有何不同。
如果我們觀察到模型在樣本內從未出現某種類型的錯誤,但在樣本外卻經常出現該類型的錯誤,那麼我們就有理由懷疑模型過擬合。
例如,如果一個模型在樣本內從未漏掉金髮,但在樣本外的表現卻與隨機猜測無異,那麼我們可能需要檢查訓練數據中是否存在眼睛顏色、性別、鬍鬚、服裝、種族或其他可能的偏差。即使錯誤率無法指出具體問題所在,這種行為本身也提供了極佳的線索,表明模型存在問題。
我們發現,共耗啟發式算法在樣本外的性能不僅更差,而且差得非常厲害。此外,我們還發現,某種類型的錯誤——即啟發式算法錯誤地將地址分類到某個簇內的“假陽性”——在樣本內幾乎不存在,但在樣本外卻以有時超過 50% 的發生率出現。
至少,這些結果表明,需要對這種啟發式方法進行更多測試。我們的結果還表明,在某些情況下,這種啟發式方法存在顯著侷限性。
樣本內
Chainalysis是歷史最悠久、規模最大的基於共同消費啟發式算法的工具提供商,該公司引用了一項研究,該研究分析了三種被捕獲的非法服務,並測量了每種服務的“誤報率”(FPR)和“漏報率”(FNR)。“誤報”的定義如上所述,“漏報”指的是本應包含在某個聚類中的地址被錯誤地排除在該聚類之外的情況。
這項研究——被譽為準確性的證明——報告了以下結果:
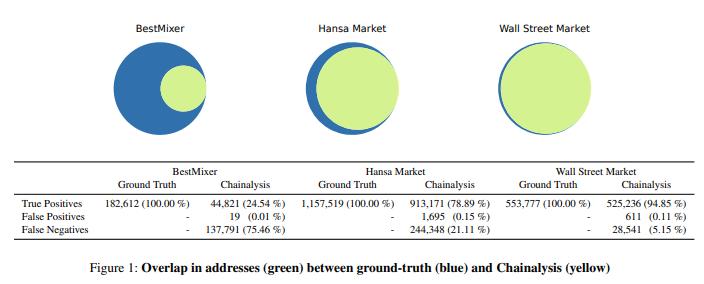
在所有情況下,FPR 都接近於零,而 FNR 則各不相同:5%、21% 或 75%。這表明可能存在過擬合問題,因為啟發式算法頻繁出現一種類型的錯誤,而很少出現另一種類型的錯誤。
人們會期望一個運行良好的工具在兩個方向上的故障頻率大致相同——不一定是 1:1,但肯定不會像 BestMixer 那樣高達 7,250:1。
尤其值得注意的是,其中一個錯誤率接近於零,而另一個錯誤率卻高達75%。這種模式表明,工程師們可能主要以最小化誤報率為優化目標。
在得出“低 FPR 是可以接受的”這一結論之前,要認識到,為了使 FPR 接近於零而調整模型可能會無意中導致過擬合或其他問題,表現為在不同數據上不同的性能。
將金髮檢測儀的誤報率降至零可能會導致模型依賴於眼睛顏色、種族或其他因素。與所有建模一樣,應對此類問題的辦法是使用之前未見過的數據進行測試並重新審視假設。
樣本外
為了獲取樣本外數據,我們考察了以太坊上的 10 個 Tornado Cash 實例,涵蓋 4 種不同的 ERC-20 代幣。論文中提供了我們選擇標準和啟發式方法應用的完整細節。以下是我們測試的假陽性率 (FPR) 和假陰性率 (FNR):
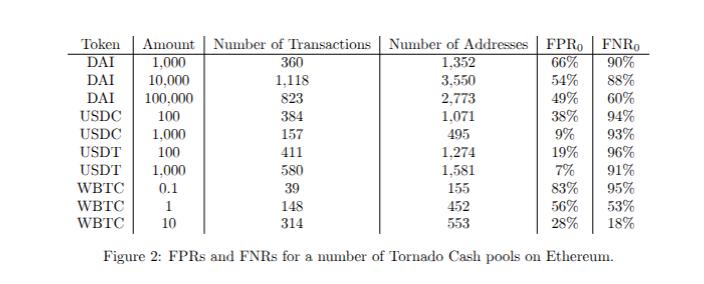
我們發現假陽性率 (FPR) 介於 7% 到 83% 之間,假陰性率 (FNR) 介於 18% 到 96% 之間。正如預期的那樣,這些結果比樣本內結果更差,也表明存在顯著的性能侷限性。
對於其中一款混合器(我們測試過的最小的型號),我們發現其假陽性率 (FPR) 為 83%,假陰性率 (FNR) 為 95%。這些結果非常糟糕,性能如此之差的工具不僅不適合用於法醫鑑定,甚至還不如靠猜測。
情況變得更糟了。
我們的程序生成類似比特幣的交易,其中只有一個大型集群——Tornado Cash——而其他所有地址都是一個包含 1 的集群。我們可以驗證這一點,因為我們能夠讀取 Tornado Cash 的代碼,並且我們編寫了相應的轉換軟件。在任何情況下,最大的集群都應該是混幣器,理想情況下,它應該只包含混幣器地址。理想情況下,其他任何集群都不應該包含混幣器地址。
下圖藍色部分顯示了從 10,000 Dai Tornado Cash 實例中識別出的 100 個最大集群的集群大小,紅色部分顯示了集群中的服務地址數量:
顯而易見的是:
- 大多數服務地址都位於最大的集群中。
- 這些集群通常包含許多非服務地址
- 存在大量並非單個地址的小型地址簇。
- 服務地址分佈在許多這樣的集群中。
這並非完全失敗,因為啟發式算法至少檢測到了與服務相關的內容。然而,該啟發式算法將服務地址與非服務地址混淆,並且在應該只找到一個服務的地方識別出了多個服務。
該軟件也能識別與服務相關的模式,儘管識別並不完美。這表明該啟發式方法在某些情況下可能有效,但其普遍適用性有限。
我們當然不是說這種啟發式方法會產生隨機結果,因為正確答案確實存在可觀察的結構。但它的價值僅在於,檢測出包含服務地址一半以上的最大簇比簡單地猜測更有幫助。
請記住,50% 的錯誤識別率並不等同於拋硬幣的結果,因為可能的結果遠不止兩種。然而,對於一款旨在用於法庭並可作為證據採納的法醫工具而言,這樣的錯誤識別率確實令人擔憂。
本文提供了所有 10 個混合器的這些結果。對於我們檢查的所有Dai混合器,以下是每個已識別集群中 Tornado Cash 地址所佔的比例:
每種顏色代表一種不同的混合器,從左到右依次展示100個最大的聚類。這些細節並非主要結論。理想的結果是,每種顏色在左側對應一個100%的值,其餘均為零。
相反,我們觀察到每個混合器100個簇的速率分佈大多在20%到80%之間。在這些測試中,該啟發式算法未能達到預期的性能標準。
在論文中,我們明確地寫下了我們對成功的定義,然後提出了數據,清楚地表明,所考察的例子沒有一個接近這個定義。
比較
樣本內FPR接近於零而FNR卻顯著偏高,這表明模型存在過擬合。我們的樣本外分析表明,低FPR至少在某些新的數據集上無法推廣。這提供了與過擬合相符的統計證據。
為了更清楚地說明這一點,讓我們回到頭髮顏色檢測的比喻。
一位工程師提供了一個黑盒子,聲稱它可以識別照片中的金髮。他們的研究表明,當黑盒子顯示“存在金髮”時,99.9% 的情況下照片中確實存在金髮。
然而,當使用同一個黑色方框來識別工程師自己提供的金髮女郎照片時,它經常無法正確識別頭髮顏色。當它顯示“金髮”時,結果總是正確的。但當你提供一張金髮女郎的照片時,它卻經常出錯,這時你可能已經懷疑這個工具出了問題。
然後你用自己的照片進行測試,發現它經常在兩個方向上都出錯——大約有一半的時間出錯。
關於這個黑箱,你能得出什麼結論?或許你使用它的方式不對。
或許那位工程師弄錯了。
或許這位工程師缺乏足夠的專業知識。
或者,你的照片可能與工程師接受培訓時使用的照片有很大不同。
可能有多種解釋。
重要的結論是,這些解釋都不能說明黑匣子適合其預期的用途。
討論
我們開發了一種新的方法來測試共付啟發式算法,該方法利用以太坊上的 ZK Mixer 數據合成類似比特幣的交易集,其中可以進行共付交易。我們承認這並非該啟發式算法的理想樣本外測試。理想的測試需要使用比特幣上尚未公開的非法服務的完整標記數據。實現這一目標的唯一方法是運行此類服務,並在執法部門介入並查封軟件代碼、日誌和服務器之前發佈測試結果。
這樣的測試方法會更優嗎?
這樣的測試不需要我們的同構,步驟更少,並且能更接近地模擬使用共同消費啟發式方法來研究新型攪拌機的真實世界經驗。
然而,這將要求測試團隊運營非法服務,公開承認這一點,並公佈有助於逮捕他們的數據。
雖然理論上有人可以匿名發表此類作品,但這需要同時承認犯有可判處長期監禁的罪行、公佈足以定罪的證據以及質疑執法方法。
我們的方法只解決了第三個要素,這在實踐中已經有些具有挑戰性了。
如果唯一可接受的測試要求測試者承認犯罪行為並公佈罪證,那麼嚴格的測試就變得不切實際。在不提出替代測試方法的情況下否定我們的前提是不具建設性的。我們的方法是出於善意,合情合理,並且能夠產生有意義的結果。
它完美嗎?不。
我們是否期望共同支出啟發式方法立即被放棄?當然不會。
我們既不希望也不認為這是合適的結果。
然而,我們的研究結果表明,各種區塊鏈取證技術的可靠性可能在一段時間內被高估了。
區塊鏈倡導和合規行業的很大一部分內容都圍繞著這樣一個說法:額外的分析工具可以解決web3的合規性挑戰。然而,當這些工具缺乏嚴格的、批判性的或科學的測試時,很難認真對待這些說法。
測試工具能夠幫助工具製造者改進產品。未經科學測試就想當然地認為工具有效,通常會導致糟糕的結果。這些觀點自啟蒙運動之前就已廣為人知。
沒有人會對降落傘進行雙盲測試,因為:
- 這種方法會很有挑戰性;
- 如果可能的話,受試者很可能會死亡;
- 令人信服的非盲測試是可行的;
- 顯然,有降落傘比沒有降落傘要好得多。
共同支出啟發式方法並不符合這種模式。
適當的測試是必要的,尤其是在假陽性可能導致錯誤監禁的情況下,這使得降落傘測試的擔憂從“測試可能會殺人”轉變為“不進行測試可能會監禁無辜的人”。
我們提出的是一項富有創意、嚴謹且重要的科學研究,該研究表明,共同消費啟發式方法在與最常見、最引人注目的用例(即調查新型非法區塊鏈服務)不完全相似的條件下,表現出相當大的侷限性。
這項研究表明,在某些合理條件下,該啟發式方法無法充分發揮作用。僅此一點就足以引發人們對該啟發式方法及其衍生工具在何種情況下適用和不適用的質疑,例如在何種情況下應使用該啟發式方法、在何種情況下應被法庭採納、在何種情況下應被作為搜查令的依據,以及在其他各種常見應用中應如何運用該啟發式方法及其衍生工具。
我們希望這能開啟一段關於多種技術可靠性的建設性討論時期。我們希望它能引領該領域朝著更嚴格的標準邁進,更重要的是,制定一套與法醫學其他領域相一致的標準制定流程。
《共同消費啟發式幻覺》最初發表於 Medium 上的ChainArgos ,人們正在那裡通過突出顯示和回應這篇文章來繼續討論。






