

本文已轉載至Chainbound 博客的“使用 PeerDAS 進行區塊和 Blob 傳播”版塊。
由Chainbound 的Pierre-Louis和mempirate撰寫
簡而言之,本文分析了以太坊網絡的各項關鍵指標,以衡量 PeerDAS 和不斷增加的 blob 數量的影響。這些指標包括區塊和 blob 驗證延遲、證明率和孤塊率。我們發現,PeerDAS 引入後,更高的 blob 數量與上述指標的負面變化之間存在明顯的關聯(結果摘要鏈接)。我們認為,尤其是在 PBS 這種競爭激烈且對延遲高度敏感的機制下,這可能會人為地限制 blob 數量,使其低於協議定義的任何限制。針對這些問題,我們提出了一個超級節點網絡的設計方案,旨在緩解部分問題。
| 斑點計數是否會影響: | 阻止延遲? | 認證率? | 孤塊率? |
|---|---|---|---|
| 主網不帶 PeerDAS(基線) | 是的,所有方面都是如此。 | 是的,但僅適用於p99 | 結果不確定 |
| 主網(含 PeerDAS-BPO1) | 是的,所有方面都是如此。 | 是的,所有方面都是如此。 | 數據不足 |
| Hoodi 和 PeerDAS-BPO2 | 是的,斑點數量≥9 | 是的,斑點計數≥14 | 不 |
介紹
PeerDAS 。以太坊最近部署了Fusaka,這是其以Rollup為中心的路線圖上的一個重要里程碑,它引入了PeerDAS作為其首個支持數據可用性採樣(DAS)的功能集。PeerDAS的具體目標是幫助網絡支持每個區塊中更多的blob。在Fusaka部署之前,以太坊網絡支持的blob數量(目標,最大值)為6,9,預計到2026年將支持高達48,72。PeerDAS對blob機制進行了重大修改;它改變了blob的創建、引用、分發/託管和驗證方式。因此,PeerDAS自然會帶來一些權衡取捨。
DAS 的侷限性。雖然 PeerDAS 的出現使得驗證者無需再下載和驗證完整的區塊,但提議者卻需要執行更多計算並上傳更多數據。PeerDAS 使用 Reed-Solomon 編碼,導致編碼後的區塊大小是 PeerDAS 之前的兩倍(128 kB → 256 kB)。區塊提議者將區塊的編碼區塊組織成一個二維矩陣,其中每個區塊對應矩陣的一行。提議者將矩陣分割成 128 列,計算每列的KZG 承諾,並將每列分別分發給 128 個驗證者子網絡。與 PeerDAS 之前相比,提議者需要計算和上傳更多數據,這主要是由於 Reed-Solomon 編碼造成的。隨著 BPO 的推出,每個區塊將包含更多區塊,這個問題將會更加嚴重。一些值得關注的 DAS 未來提案,包括FullDAS和FullDASv2 ,都旨在實現 2D 編碼,這將使編碼開銷進一步翻倍,從而進一步加劇建設者、提議者和中繼的帶寬成本,並對所有驗證者的傳播延遲產生影響。
實證分析。本文檔主要基於 ethPandaOps 的Xatu 數據庫中記錄的觀測數據,分析了每個區塊的 blob 數量對以太坊的影響。具體而言,該分析研究了 blob 數量對以下三個方面的影響:(1)驗證者接收區塊和 blob 的延遲;(2)驗證者成功驗證區塊的概率;(3) 區塊未被最終確認而成為孤兒的概率。測量基於以下數據:
- 主網在 PeerDAS 部署之前,將作為基線,其 blob 計數為
(6, 9) - 主網在 PeerDAS 和 BPO1 之後,因此 blob 計數為
(10, 15) - Hoodi post-PeerDAS 和 BPO2,blob 計數為
(14, 21)
結果[彙總表] 。在幾乎所有觀察的網絡中,無論在PeerDAS實施前後,增加blob數量都會顯著惡化區塊延遲和認證率。此外,我們觀察到PeerDAS實施後的尾延遲比實施前更嚴重,並且隨著blob數量的增加,尾延遲的惡化程度也隨之增加。然而,增加blob數量對孤兒率沒有明顯影響;部分結果尚無定論,總體而言,需要更多數據才能對孤兒率得出有意義的結論。
提議:  種子網絡。考慮到分析結果,我們建議在以太坊網絡中添加一個由專用超級節點組成的網絡,旨在加速區塊、blob 和 blob 列從區塊提議者(PBS 中的中繼節點)向網絡其他部分的傳播。這項新增服務將起到輔助網絡的作用,確保 PBS 供應鏈中的專用參與者不會因為擔心包含 blob 的風險而人為地限制 blob 的數量,正如本次演示中所討論的。
種子網絡。考慮到分析結果,我們建議在以太坊網絡中添加一個由專用超級節點組成的網絡,旨在加速區塊、blob 和 blob 列從區塊提議者(PBS 中的中繼節點)向網絡其他部分的傳播。這項新增服務將起到輔助網絡的作用,確保 PBS 供應鏈中的專用參與者不會因為擔心包含 blob 的風險而人為地限制 blob 的數量,正如本次演示中所討論的。
斑點計數實證分析
目前在以太坊網絡中,我們已經可以觀察到blob對某些指標的影響。以下分析重點闡述了我們關於每個區塊中blob數量的主要觀察結果,並表明在PeerDAS部署後,仍有改進空間。
分析範圍
本分析主要關注以下問題:增加斑點數量是否會影響:
- 驗證器接收區塊和所需blob列需要多長時間?
- 驗證者能否在 4 秒截止時間前對區塊進行認證?
- 一個區塊最終成為孤立區塊的概率是多少?
分析結構
我們研究了四種網絡和分支的組合,每種組合都有四種不同的斑點數量:
- 主網基於 Pectra 分叉,擁有20,000 個穩定節點,支持
(6, 9)blob(target, max)。該數據集可作為 PeerDAS 的基線數據。 - 主網基於 Fusaka 分叉,啟用了 PeerDAS 和 BPO1,以支持 blob 數量為
(10, 15)。我們觀察到 BPO1 啟用後噪聲顯著降低,因此選擇不包含啟用前的數據,即 Fusaka 的第一週數據。該數據集可作為 PeerDAS 啟用後穩定的案例研究。 - Hoodi 測試網基於 Fusaka 分支,採用 PeerDAS 架構,由2000 個節點運行,並啟用了 BPO2 以支持
(14, 21)個 blob。該網絡穩定性較差,規模也小於主網,但已啟用 BPO2。作為測試網,Hoodi 的架構與主網最為接近,因此比 Sepolia 更適合研究。本數據集可作為 PeerDAS 和 BPO2 的案例研究。
設置
來源:所有結果均提取自 ethPandaOps 維護的 Xatu 數據庫。用於獲取圖表的確切查詢可在GitHub 上公開獲取以供復現 - chainbound/blob-seeder-data:與 PeerDAS 分析相關的數據,這些數據激發了 blob 種子網絡的構建。
圖表:部分圖表使用箱線圖來展示結果分佈。箱體採用經典的箱線圖形式:箱體的兩端分別代表第25和第75百分位數(分別標記為p25和p75),箱體內的橫線代表中位數(p50)。以下圖表包含兩對須線,以便更清晰地展示尾部潛伏期行為;須線一端代表p1和p5,另一端代表p95和p99。異常值用位於須線範圍之外的半透明彩色圓圈表示。箱線圖的參數標註在圖表的右上角。
結果總結
| 斑點計數是否會影響: | 阻止延遲? | 認證率? | 孤塊率? |
|---|---|---|---|
| 主網不帶 PeerDAS(基線) | 是的,所有方面都是如此。 | 是的,但僅適用於p99 | 結果不確定 |
| 主網(含 PeerDAS-BPO1) | 是的,所有方面都是如此。 | 是的,所有方面都是如此。 | 數據不足 |
| Hoodi 和 PeerDAS-BPO2 | 是的,斑點數量≥9 | 是的,斑點計數≥14 | 不 |
- 延遲:blob 數量對延遲有明顯影響。
- 比較 PeerDAS 啟用前後相同 blob 數量的區塊的延遲,數據顯示,即使 blob 數量較低(3 到 9), PeerDAS 也比 Pectra 改善了主網上 95% 驗證者的驗證延遲,但對剩餘的少數驗證者而言,延遲卻有所增加。然而,啟用 PeerDAS 後區塊的分發速度比未啟用時更快,這表明對於剩餘的 5% 驗證者而言,啟用 PeerDAS 後用於驗證的 blob 數據的分發速度實際上比未啟用時更慢。
- 主網未啟用 PeerDAS 時:延遲隨 blob 數量線性增加。這一趨勢貫穿整個分佈,從 p5 到 p99 值均可見。此外,所有 blob 數量的 p99 值均達到或超過 4 秒的截止時間;9 個 blob 的 p99 值甚至超過 5 秒。
- 啟用 PeerDAS-BPO1 的主網:線性增長的趨勢在啟用 PeerDAS 後依然存在,從上到下,p5 到 p99 的所有值都呈現出這種趨勢。與未啟用 PeerDAS 的節點相比,大多數啟用 PeerDAS 的節點延遲略有改善,因為大多數 p50 和 p75 值都降低了 100-200 毫秒。然而,對於最不理想的 1% 的驗證節點,由於 blob 數量 ≥ 3 時 p99 值均有所增加,因此啟用 PeerDAS 後區塊延遲反而更高。當 blob 數量 ≥ 9 時,p99 值均超過 5 秒;當 blob 數量為 14 時,p99 值超過 6 秒;當 blob 數量達到最大值 15 時,p99 值甚至達到 12.4 秒。
- 使用 PeerDAS-BPO2 的 Hoodi 分析顯示:blob 計數 ≥ 9 的值呈現明顯的增長趨勢,且在所有 p1 到 p99 節點上基本呈線性增長。這表明,一旦 BPO2 在主網上部署,該趨勢很可能繼續保持線性增長。
- 認證率:斑點計數對認證率有明顯影響。
- 主網沒有 PeerDAS:當 blob 計數 ≥ 4 時,較高的 blob 計數會增加 p99 的失敗證明率。否則,blob 計數對證明率幾乎沒有影響。
- 啟用 PeerDAS-BPO1 的主網:啟用 PeerDAS 後,認證失敗率總體上顯著高於未啟用時。啟用 PeerDAS 前,p75 在所有 blob 數量下均穩定在 0.6%,但啟用 PeerDAS 後,隨著 blob 數量的增加,p75 從 0.9% 上升至 1.8%。同樣,p95 也從 1 個 blob 時的 2.4% 上升至 15 個 blob 時的 7%。
- 使用 PeerDAS-BPO2 的 Hoodi:當 blob 數量 ≥ 14 時,失敗的證明率隨 blob 數量的增加呈線性增長。未證明最終區塊的驗證者的中位數率從 14 個 blob 的 4% 增加到 21 個 blob 的 5%,p99 從 14 個 blob 的 11% 增加到 21 個 blob 的 37%。
- 孤立塊率:blob 數量對孤立塊率幾乎沒有影響。
- 不使用 PeerDAS 的主網:結果尚無定論。基於總槽位數計算孤塊率(絕對值)的圖表顯示,blob 數量增加與孤塊率增加之間存在相關性。然而,基於包含相同數量 blob 的已完成區塊數量計算孤塊率(即比例值)的圖表則未顯示任何規律。
- 主網上的 PeerDAS-BPO1:孤兒節點很少見,而且目前數據還不夠。
- 使用 PeerDAS-BPO2 的 Hoodi:Hoodi 上似乎沒有發現 blob 數量與孤立塊發生率之間的相關性。顯示絕對發生率的圖表主要突出顯示了兩個異常值,而顯示比例發生率的圖表則主要突出顯示了 6 到 13 個 blob 之間塊延遲的模式。
主網延遲比較
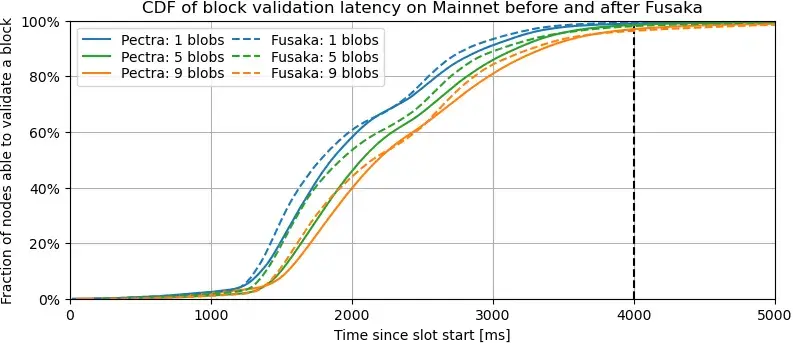
描述。此圖展示了在主網上,當區塊包含 1、5 和 9 個 blob 時,使用 Pectra 共識規則和 Fusaka 共識規則,已收到足夠數據以驗證區塊的驗證者比例的變化情況。更準確地說,它描繪了區塊驗證延遲的累積分佈函數 (CDF),我們將區塊驗證延遲定義為驗證者能夠根據共識規則驗證區塊的最早時間。在 Pectra 共識規則下,驗證者必須收到區塊及其所有 blob sidecar 才能驗證區塊;而在 Fusaka 共識規則下,驗證者只需收到區塊及其至少 8 個 blob 列(包括其必須保管的所有 blob 列)即可。Pectra 和 Fusaka 數據集的詳細信息(分別為 PeerDAS 之前的主網和 PeerDAS-BPO1 之後的主網)將在各自的延遲圖描述中進一步解釋。
要點:按blob數量配對的三組曲線呈現出相似的模式:與Pectra相比,Fusaka中的大多數驗證者能夠更早地驗證區塊,即虛線大多位於實線之上。此外,在區塊中添加blob自然會增加延遲。我們觀察到在2.3-2.5秒左右傳播速度略有下降,這可能是由於密集驗證者集群之間的跨洲延遲造成的。
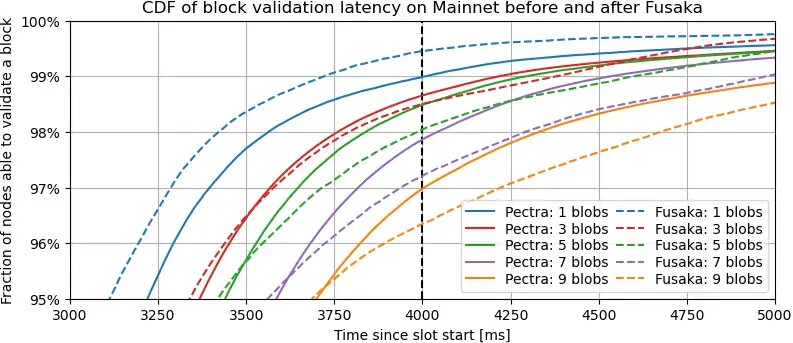
描述。此圖是上述圖的放大版本,添加了第 3 個和第 7 個斑點的線條,以突出顯示傳播尾部的開始,超過第 95 頁。
要點總結。對於單個區塊,兩條曲線的行為與上圖一致:當區塊數量較低時,超過 99% 的驗證者在 Fusaka 下驗證區塊的速度比在 Pectra 下更快。然而,對於更高的區塊數量,情況則相反:最不走運的 4-5% 的驗證者在使用 Fusaka 接收驗證數據所需的時間實際上比使用 Pectra 更長。隨著區塊數量的增加,這種趨勢愈發明顯,如同色實線和虛線之間的差距所示。這兩張圖表明,PeerDAS 改善了 95% 驗證者的延遲,但卻加劇了剩餘少數驗證者的延遲。
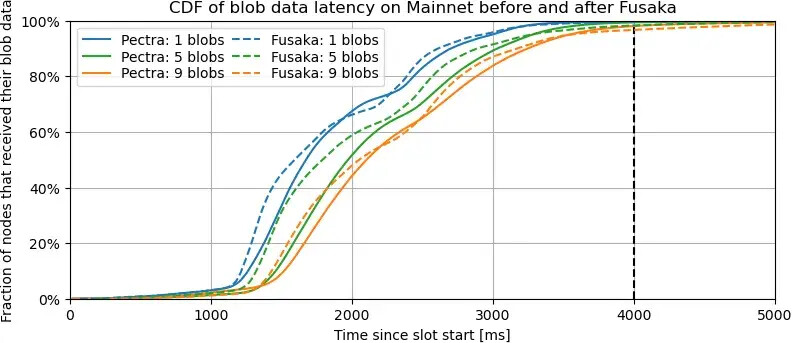
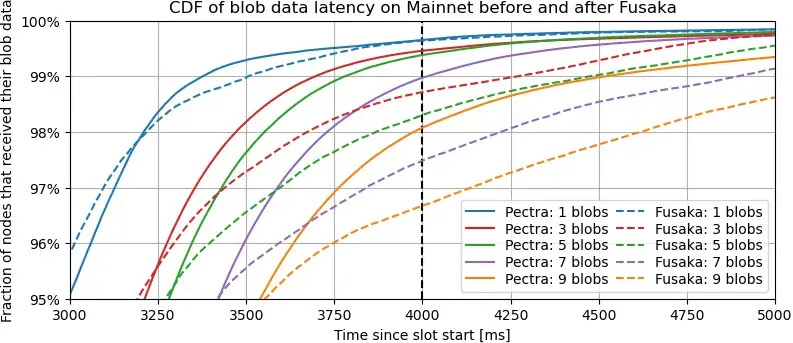
說明:這兩張圖與上圖類似,但側重於驗證器接收足夠數據以驗證區塊所需的延遲,即 Pectra 中每個區塊的所有數據(即所有數據)與 Fusaka 中僅所需的數據列之間的延遲。這些圖不考慮區塊延遲,僅考慮數據列延遲。
要點。這兩張圖證實了之前的推斷,即大多數節點在 Fusaka 中接收 blob 數據的速度比在 Pectra 中更快,而對於最不幸的 5% 的節點來說,情況則相反,並且隨著 blob 數量的增加,這種趨勢會惡化。
在 PeerDAS 之前
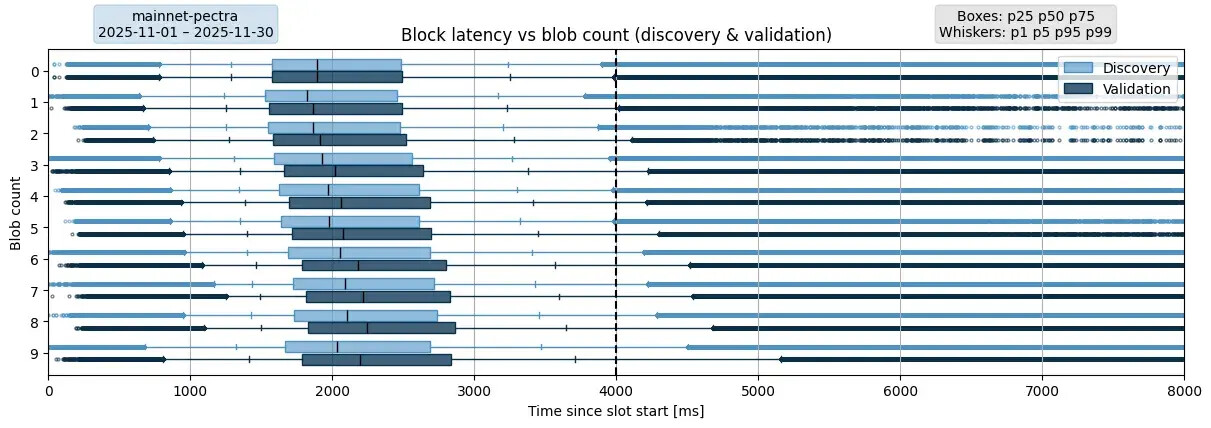
描述。此圖展示了 Pectra 主網上區塊發現和驗證延遲的分佈情況(PeerDAS 之前),並根據每個區塊引用的 blob 數量進行了劃分。如上所述,Pectra 要求驗證節點下載區塊中引用的所有 blob sidecar 才能驗證該區塊。這種延遲體現在發現延遲和驗證延遲之間的差異上。圖中的每個數據點都是一個唯一的元組:(接收節點,最終區塊)。為了去除明顯的異常值,已過濾掉延遲超過 30 秒的區塊。數據集彙總了 2025 年 11 月整個月份的數據。4 秒處的黑色垂直線表示區塊證明截止時間。
要點:從 p25 到 p99,所有指標都呈現出明顯的上升趨勢,表明 blob 數量越多,區塊驗證延遲就越高。對於 blob 數量為 0-1 的區塊,p99 的延遲已經達到 4 秒的截止時間;而對於 blob 數量 ≥ 2 的區塊,延遲則超過了該截止時間。然而,驗證者不僅需要在截止時間前接收區塊,還需要處理區塊及其關聯的 blob。
使用 PeerDAS-BPO1
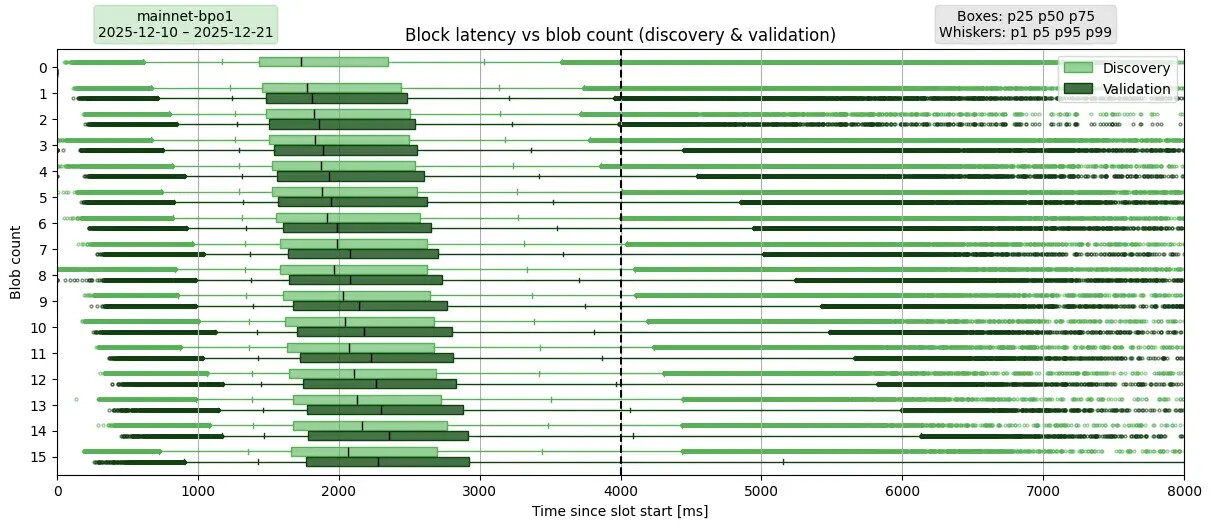
描述:此圖復現了之前在主網上的延遲圖,但這次是在部署了 PeerDAS 和 BPO1 之後。此外,它還顯示了區塊發現延遲,作為每個層級的第一個方框。這使得僅由 blob 列傳播引起的額外延遲更加清晰。
如上所述,Fusaka 的驗證規則有所不同,它要求驗證者不能下載完整的 blob,而是至少下載 8 個 blob 列,其中包括其託管所需的所有 blob 列。11 天的採樣週期從 2025 年 12 月 10 日 00:00 UTC(BPO1 激活後不久)開始,到 2025 年 12 月 21 日 23:59 UTC 結束。
要點總結。從 p5 到 p99,PeerDAS 實施前後趨勢基本一致。值得注意的是,PeerDAS 實施後,p50 值總體提升了 100-200 毫秒,但當 blob 數量 ≥ 3 時,p99 值反而下降,這意味著最不走運的 1% 驗證者體驗到了更低的服務質量。當 blob 數量 ≥ 9 時,所有 p99 值均超過 5 秒,其中 blob 數量為 14 時達到 6.1 秒,最大 blob 數量為 15 時甚至達到 12.4 秒。
使用 PeerDAS-BPO2 在 Hoodi 上測試延遲
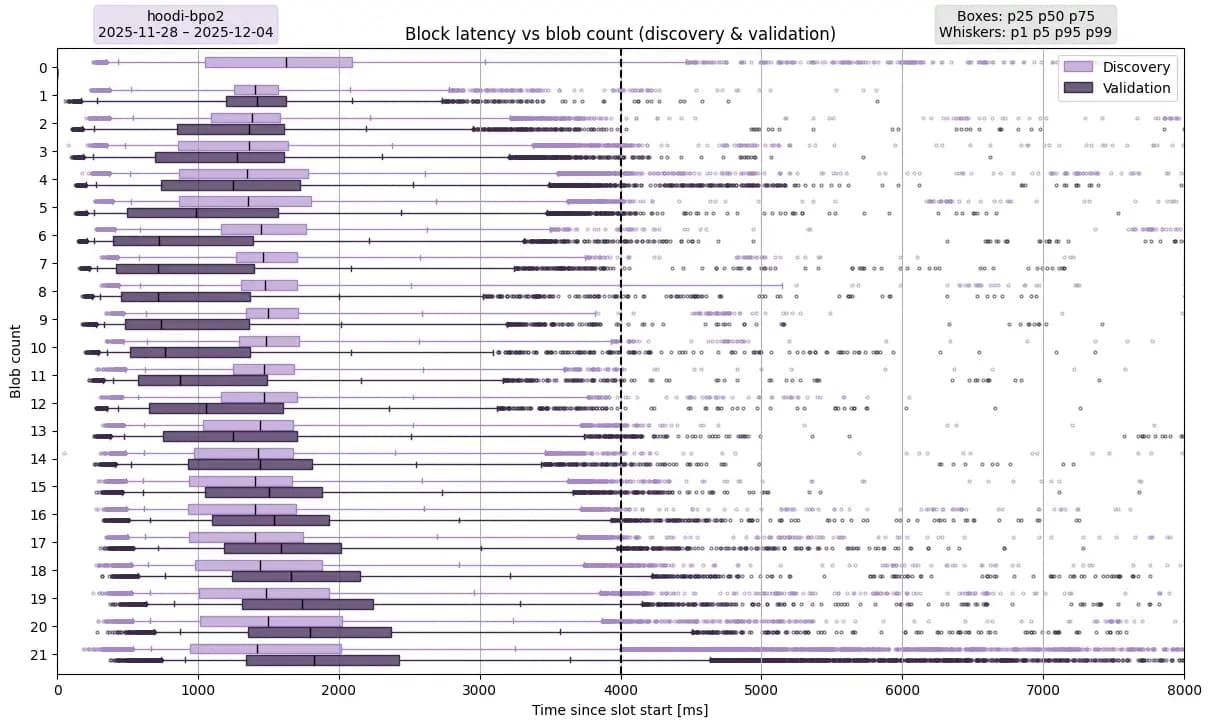
描述。此圖描繪了在 Hoodi 上部署 PeerDAS 和 BPO2 後的區塊驗證延遲。BPO2 已於 2025 年 11 月 12 日部署在 Hoodi 上,並將 blob 數量提升至目標值(14, 21)由於 Hoodi 測試網的波動性遠高於主網,因此本圖所用的數據採樣時間為 7 天,從 2025 年 11 月 28 日 00:00:00 UTC 到 2025 年 12 月 4 日 00:00:00 UTC,而主網的數據採樣時間為一個月。
要點:在 Hoodi 上,blob 數量對區塊延遲的影響不如在主網上那麼明顯。對於所有 p1 到 p99 值,blob 數量 ≥ 9 時,延遲呈現明顯的線性增長趨勢。我們觀察到,許多節點接收到的 blob 列不足以驗證區塊,因此人為地降低了整體延遲,因為圖中只考慮了成功驗證的情況。
認證率
PeerDAS 之前的主網
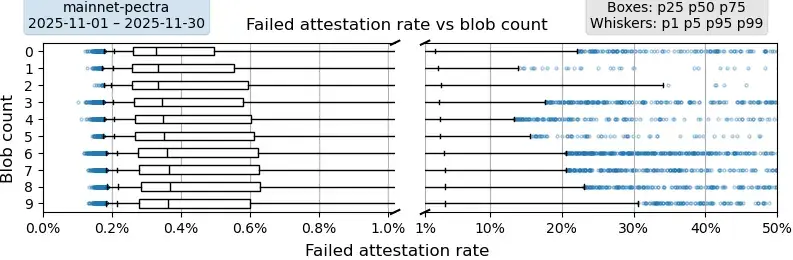
描述。此圖顯示了從未驗證過某個區塊的驗證者比例,該比例取決於區塊中的blob數量。每個數據點對應一個最終區塊。例如,p99 為 30% 表示 1% 的區塊僅由 70% 的驗證者驗證。數據彙總自 2025 年 11 月主網上的整個月份。為了提高箱線圖和須線的可讀性,圖表的 x 軸被分為兩個不同刻度的線性軸。
要點:中位數略有上升趨勢,而當 blob 計數 ≥ 4 時,p99 值呈現更明顯的上升趨勢。所有 p75 值均接近或低於 0.6% 的失敗認證率,這表明即使 blob 計數為 9,網絡也保持穩定。
主網與 PeerDAS-BPO1
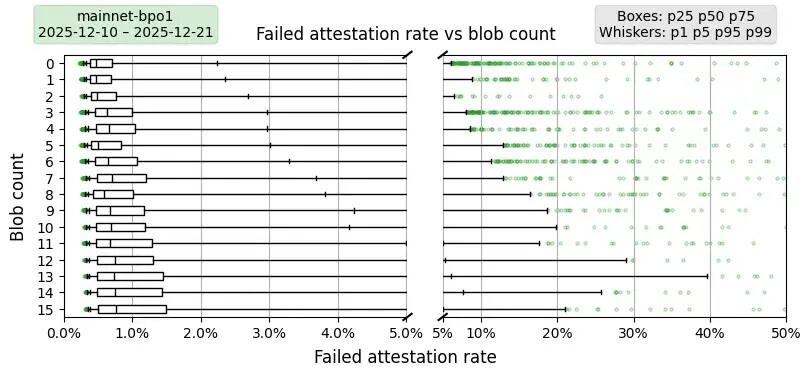
描述。此圖復現了主網上的上述認證率,但時間範圍為 PeerDAS 激活後至 BPO1 激活前。為了便於閱讀,該圖同樣分為兩部分。
要點總結。最重要的是,整體認證率有所下降:在啟用 PeerDAS 之前,p75 的認證失敗率約為 0.6%,而啟用 PeerDAS 後,隨著數據塊數量的增加,認證失敗率從 0.9% 上升到 1.8%。從 p50 到 p99 的所有測量結果都呈現出類似的趨勢:隨著數據塊數量的增加,數據塊的認證率下降。與之前未啟用 PeerDAS 的圖表相比,啟用 PeerDAS 後,認證率受數據塊數量的影響要大得多。
Hoodi 與 PeerDAS-BPO2
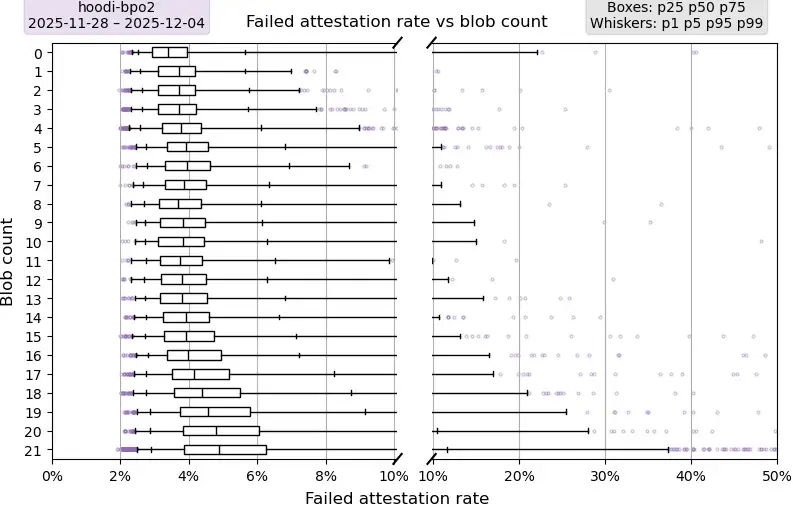
描述:此圖復現了上述認證率圖,但使用的是已啟用 BPO2 的 Hoodi 版本。由於 Hoodi 版本的波動性遠高於主網,因此數據僅採樣了一週;在某些情況下,增加樣本量反而會增加異常值。
要點:從 12 個 blobs 開始,所有高於 p25 的指標都隨著 blobs 數量的增加而明顯惡化,呈現出明顯的上升趨勢。此外,p99 也隨著 blobs 數量的增加而全面惡化。與 PeerDAS 之前的 Mainnet(其 p75 低於 1%)相比,啟用 PeerDAS 後的 Hoodi 的 p75 值要高得多,目前在 5% 到 7% 之間波動。
孤兒區塊率
PeerDAS 之前的主網
絕對
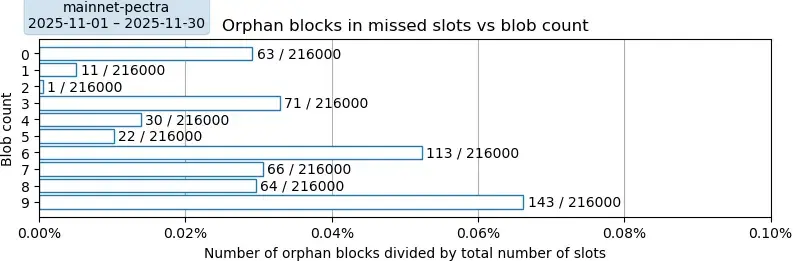
描述。此圖描繪了孤立區塊率,並按這些區塊中引用的blob數量進行分類。這些孤立區塊由其各自槽位的預期提議者創建,但由於未知原因,最終並未包含在最終的區塊鏈中。這些比率的計算與採樣期內的槽位總數成正比:2025年11月共有216,000個槽位。
要點:以太坊的孤兒率總體較低,為 584 / 216000 = 0.27%,這表明以太坊的正常運行時間為 99.73%。我們在此圖中觀察到兩種模式。首先,似乎每隔 3 行就會重複出現一種模式,即某一行的高值之後緊接著兩個較低的值:例如,0 個 blob 時有 63 個孤兒,接下來的兩行分別是 11 個和 1 個孤兒;3 個 blob 時有 71 個孤兒,接下來的兩行分別是 30 個和 22 個孤兒;6-9 個 blob 的情況也類似。第二種模式表明,增加 blob 數量會增加孤兒率,但這隻有在考慮第一種模式的情況下才成立。當僅觀察 blob 數量為 0、3、6 和 9 時,這種上升趨勢很明顯。由於我們無法解釋第一種模式,因此對第二種解釋的置信度較低。
比例

描述。此圖復現了上述絕對孤立塊率圖,但更改了率計算中使用的除數。此圖顯示的是“比例”率,因為它們基於與孤立塊具有相同 blob 計數的已完成塊的數量。
要點:我們主要觀察到最終區塊中斑點數量的分佈較為多樣(柱狀圖旁邊分數中的除數),並且存在兩個異常值,斑點數量分別為 2 和 9。忽略異常值後,斑點數量似乎並不影響孤兒率,這與顯示絕對孤兒率的圖表有所不同。
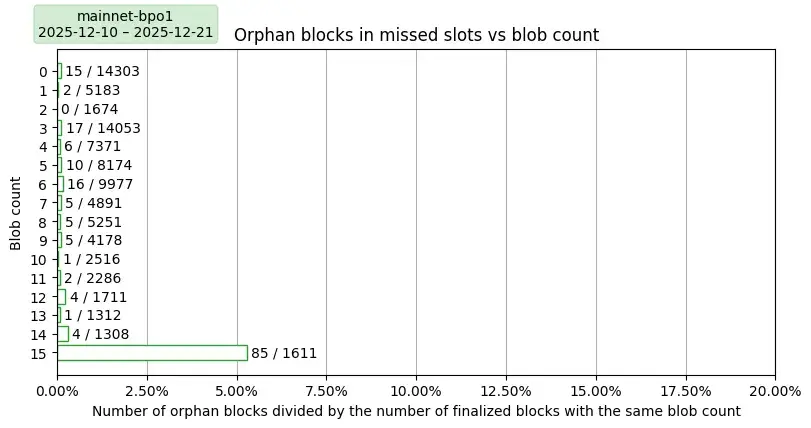
主網與 PeerDAS-BPO1
收集足夠的數據來繪製Fusaka更新後主網上的孤塊圖需要數週時間。作為對比,上圖顯示的是PeerDAS更新前主網上的孤塊情況,儘管計算週期長達一個月,但孤塊率仍然很低。下圖顯示的是高blob計數的觀測值數量非常少,因此不具有代表性。其中,15個blob異常值非常突出,它們的孤塊率超過5%。
Hoodi 與 PeerDAS-BPO2
絕對
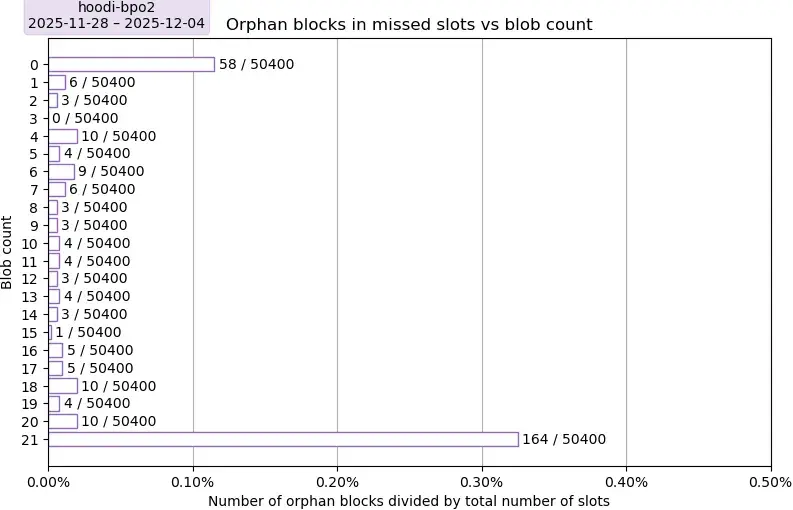
描述。該圖描繪了 Hoodi 上孤立區塊的比例,以採樣期內(7 天內 50,400 個區塊)的總區塊數為基準。
要點:在抽樣期間,孤塊率總體較低,為 319 / 50400(孤塊數 / 總槽位數)= 0.63%,略高於主網的 0.27%。有兩個明顯的異常值,分別為 0 個 blob 和 21 個 blob,並且沒有明顯的趨勢表明 blob 數量對 Hoodi 的孤塊率有任何影響。
比例
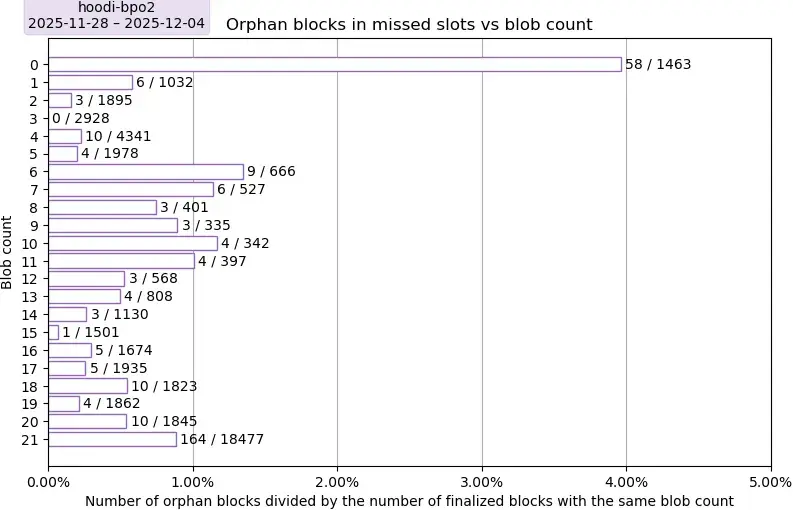
描述。此圖顯示了 Hoodi 上孤立區塊在一週內的比率,以具有相同 blob 計數的已完成區塊的數量為基準。
要點:在 6 到 13 個 blobs 之間,孤塊率出現了顯著的激增;我們目前尚無法解釋這一現象。0 個 blobs 的值顯然是一個異常值,而 21 個 blobs 的值也可以被視為異常值,因為其除數非常高,比其他 blobs 數量對應的除數高出 4 到 46 倍。剔除最後一行 21 個 blobs 的異常值後,沒有明顯的趨勢表明 blobs 數量與孤塊率之間存在相關性。
相關研究
- 2024-11:PeerDAS 前期數據顯示塊+blob 大小與傳輸延遲之間存在趨勢[帖子]
- 2025-09: Ethpandas BPO 報告顯示,在 Fusaka devnet 5 上,使用 30-50 個 blob 但數據集較小的情況下,blob 的安全性和及時性存在問題[帖子]
- 2025-09: EF 在一篇研究 6 秒時段可行性的文章中詳細分析了認證時間[文章]
- 2025-10:Ethpandas 報告了 Fusaka devnet 5 上各種類型節點的上下行帶寬消耗情況[帖子]
- Sunnyside Labs發佈了很多分析報告[報告]
- 2025年10月10日[報告]補充了 Ethpandas BPO 報告[帖子] :隨著 blob 數量從 10 增加到 40,全節點錯過證明截止時間(與報告中的“頭部正確性”指標相反)的比例上升到 50% 以上。超級節點基本正常。每個區塊包含 50-60 個 blob 時,p75 延遲達到 3 秒,因此尾部延遲更高(報告中未明確說明)。每個區塊包含 60 個以上 blob 時,很難獲取採樣列,這可能是由於網絡爭用造成的:執行客戶端需要過多的帶寬,而共識客戶端難以響應列請求。
- 2025-09-30 [報告] :Fusaka devnet 5 擁有 1,700 個節點(主網的 1/8):高 blob 計數的瓶頸是全節點上行鏈路,這是由於內存池(執行客戶端)中 blob 的數量很高,而超級節點的帶寬主要在採樣列(共識客戶端)中。
- 2025-07-14 [報告] :附錄 B 列出了 Grafana 儀表板,附錄 D 列出了增加 blob 數量時節點上的一些簡單平均帶寬和最大帶寬。
提案:種子網絡
正如分析中所強調的,PeerDAS 會對與共識穩定性相關的多項指標產生負面影響,尤其是在區塊尾部。就其本身而言,對於即將到來的 BPO 帶來的 blob 數量小幅波動,這本身並不值得擔憂。然而,在 PBS 供應鏈中,毫秒級的延遲至關重要。中繼節點為驗證者提供服務,使其能夠儘可能延遲提交區塊,從而最大化 MEV(時間博弈)。目前,這種方法之所以有效,是因為包含 blob 的延遲懲罰相對較小。然而,正如我們前面所看到的,這種情況正在發生變化,這可能導致 PBS 供應鏈中的某些實體人為地設定 blob 數量上限,而該上限遠低於實際上限。這將抵消 PeerDAS 的主要存在意義——DA 擴容優勢。
正因如此,我們提議構建一個全球超級節點網絡,其唯一任務是加速數據(區塊和數據塊)從區塊發起者(PBS 中的中繼節點)向網絡其餘部分的傳播。我們預期種子網絡能夠通過減少和限制向大多數驗證者分發數據所需的通信跳數,可靠地降低並穩定驗證者所經歷的延遲。此外,它還能確保構建者能夠可靠地包含經濟上最優數量的數據塊而不會增加任何額外的延遲,從而提高數據塊的使用效率。
種子網絡的概念與Rainbow 質押框架相符(儘管協議本身有所不同),因為它依賴於功能更強大的超級節點為網絡做出比普通節點更多的貢獻,最終提升所有用戶的服務質量。這些超級節點擴展了PeerDAS 原始文章中描述的DAS 提供者的概念。一些設計方案提出將 PBS 中繼節點轉變為 DAS 提供者,並提供 RPC 服務供驗證者查詢以獲取樣本。我們建議在這些設計方案的基礎上,增加對 GossipSub 的支持,使超級節點能夠主動加速數據傳播,而不僅僅是被動地等待客戶端查詢。
具體來說,這個種子網絡將由高性能、高連通性的超級節點組成,這些超級節點將作為網絡樞紐,以便將盡可能多的數據傳遞給儘可能多的節點。超級節點將通過訂閱用於數據塊( beacon_block )和128個blob列子網( data_column_sidecar_[0-127] )的GossipSub主題來參與數據塊和blob列的傳播。此外,超級節點還將響應相關的數據塊、blob和blob列的RPC請求,例如BeaconBlocksByRoot 、 BlobSidecarsByRoot和DataColumnSidecarsByRange 。
超級節點間的連接將採用久經考驗、性能卓越的GitHub項目chainbound/msg-rs:這是一個用Rust語言編寫的分佈式系統消息傳遞庫,曾用於支持我們的低延遲內存池服務Fiber 。每個超級節點的地理位置和網絡拓撲結構都將經過精心設計,以最大限度地降低驗證者的整體數據分發延遲和請求延遲,確保在弗吉尼亞、法蘭克福和東京等熱點地區實現適當的分佈。
預期指標改進
我們預期種子網絡在以下方面將比以太坊網絡有明顯的改進:
- 塊和塊接收延遲:由高性能超級節點組成的小型網絡能夠以比更大、更異構的網絡更少的跳數進行傳播。
- 證明率和孤塊率:由於區塊和 blob 列的傳播速度加快,驗證者能夠更快地證明區塊,從而降低區塊未能及時得到證明,最終成為無用的孤塊而不是最終鏈的一部分的概率。
- PBS 中戰略性塊限制的減少:由於上述 2 項改進,PBS 供應鏈中戰略性(較低)塊納入的好處被抵消了。
致謝
我們感謝 ethPandaOps 團隊允許我們訪問並協助我們使用 Xatu 數據庫,也感謝 Xatu 的貢獻者們為我們提供用於分析的數據。我們還要感謝在 SIGMETRICS 2026 會議上發表的區塊鏈網絡分析報告《36 種加密貨幣的多面性》 ([arXiv 版本])的作者們,特別是 Lucianna Kiffer,感謝她分享了關於各種以太坊網絡規模的最新數據。






