

這項研究由MigaLabs完成。
執行摘要
本報告對以太坊在Fusaka硬分叉及後續僅包含Blob參數(BPO)更新後的blob吞吐量和網絡穩定性進行了實證分析。該研究考察了長達數月的觀察期內的blob分佈模式、丟失槽相關性以及整體網絡健康狀況。
主要調查結果引發了重大擔憂:
- 容量利用率不足:網絡未達到目標數據塊數量(14)。自 BPO1 以來,中位數實際上有所下降,而高數據塊數量(16+)仍然極其罕見。
- 高斑點計數時的漏檢率升高:16 個以上斑點時的漏檢率在 0.77% 到 1.79% 之間,是 0-14 個斑點時的基線漏檢率(~0.50%)的兩倍多。
- 建議:在高數據塊計數下的丟失率恢復正常,並且當前容量有明顯需求之前,不應考慮進一步的 BPO 更新。
事件時間線
| 事件 | 日期 | 描述 |
|---|---|---|
| 數據收集開始 | 2025年10月1日 | 基線測量期開始 |
| 福薩卡硬叉 | 2025年12月3日 | Fusaka 發生硬分叉,沒有 blob 參數變化 |
| BPO 最新動態#1 | 2025年12月9日 | 目標斑點數量從 6 個增加到 12 個,最大值從 9 個增加到 15 個。 |
| BPO 最新動態#2 | 2026年1月7日 | 目標斑點數量從 12 個增加到 14 個,最大值從 15 個增加到 21 個。 |
分析
每個插槽的斑點分佈
在整個觀測期間,我們記錄了每個觀測時段內斑點數量的隨時間變化情況,以及相應的缺失觀測時段數據。圖 1 以箱線圖的形式展示了每個觀測時段內斑點數量的每日分佈情況,並在次座標軸(90 天)上疊加了缺失觀測時段的斑點數量。
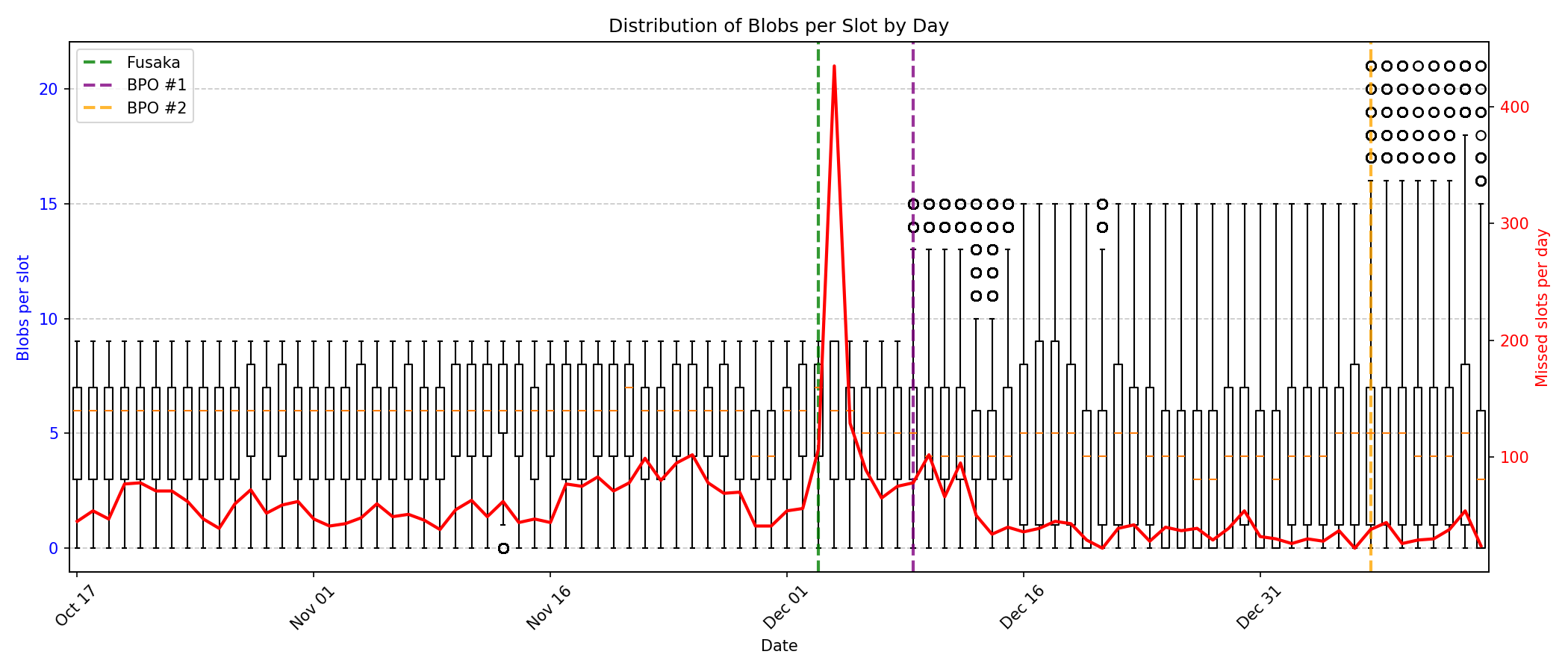
圖 1:箱線圖顯示了每個時隙的每日數據塊分佈(左軸)和每日丟失時隙數(右軸)。垂直虛線表示協議升級事件。
數據顯示了一些值得注意的現象:
目標容量未達標:儘管提高了數據塊限制,但網絡容量仍未達到新的目標容量。自 BPO1 以來,數據塊數量的中位數實際上有所下降,從每個時隙 6 個數據塊降至每個時隙 4 個數據塊。高數據塊數量(16 個以上)極其罕見,在觀察到的超過 75 萬個時隙中,每次僅出現 165 至 259 次。
產能擴張與需求脫節:業務流程外包(BPO)的不斷升級雖然提升了理論產能,但實際利用率並未相應提高。這引發了人們對進一步擴充產能必要性的質疑,因為目前的產能極限遠未達到。
錯過時段相關性分析
為了探究區塊數量與後續缺失區塊之間的潛在相關性,我們分析了自Fusaka硬分叉(40天)以來,不同區塊數量區塊之後缺失區塊的頻率。由於Fusaka硬分叉後的頭兩天缺失區塊數量異常,因此我們排除了這兩天的數據。
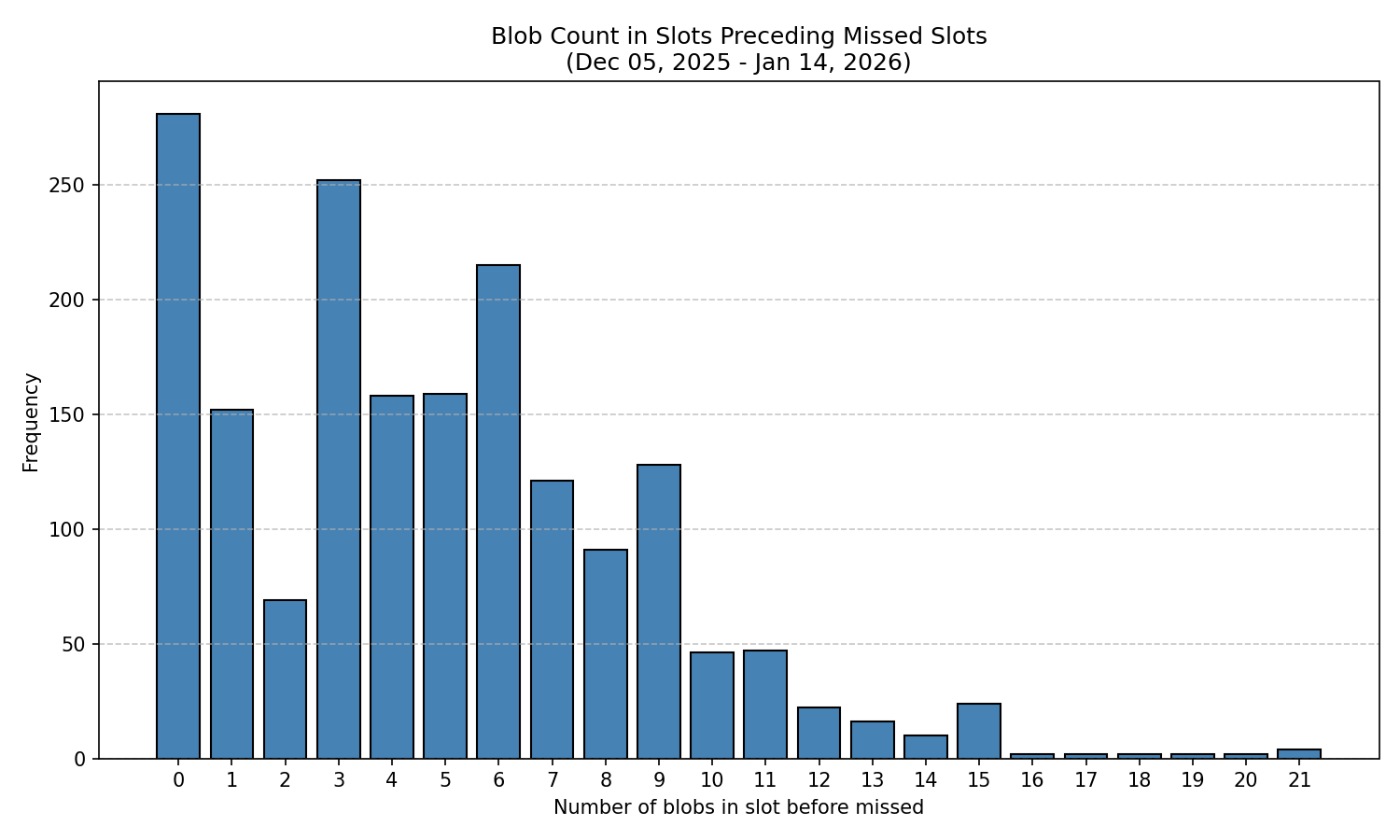
圖 2:按前一個槽位中的 blob 數量分類的丟失塊的絕對計數。
圖 2 中的原始數據顯示,在數據塊數量為零或極少的時隙之後,丟塊的發生率較高。然而,由於網絡中數據塊數量的分佈並不均勻,因此需要對這一觀察結果進行歸一化處理。
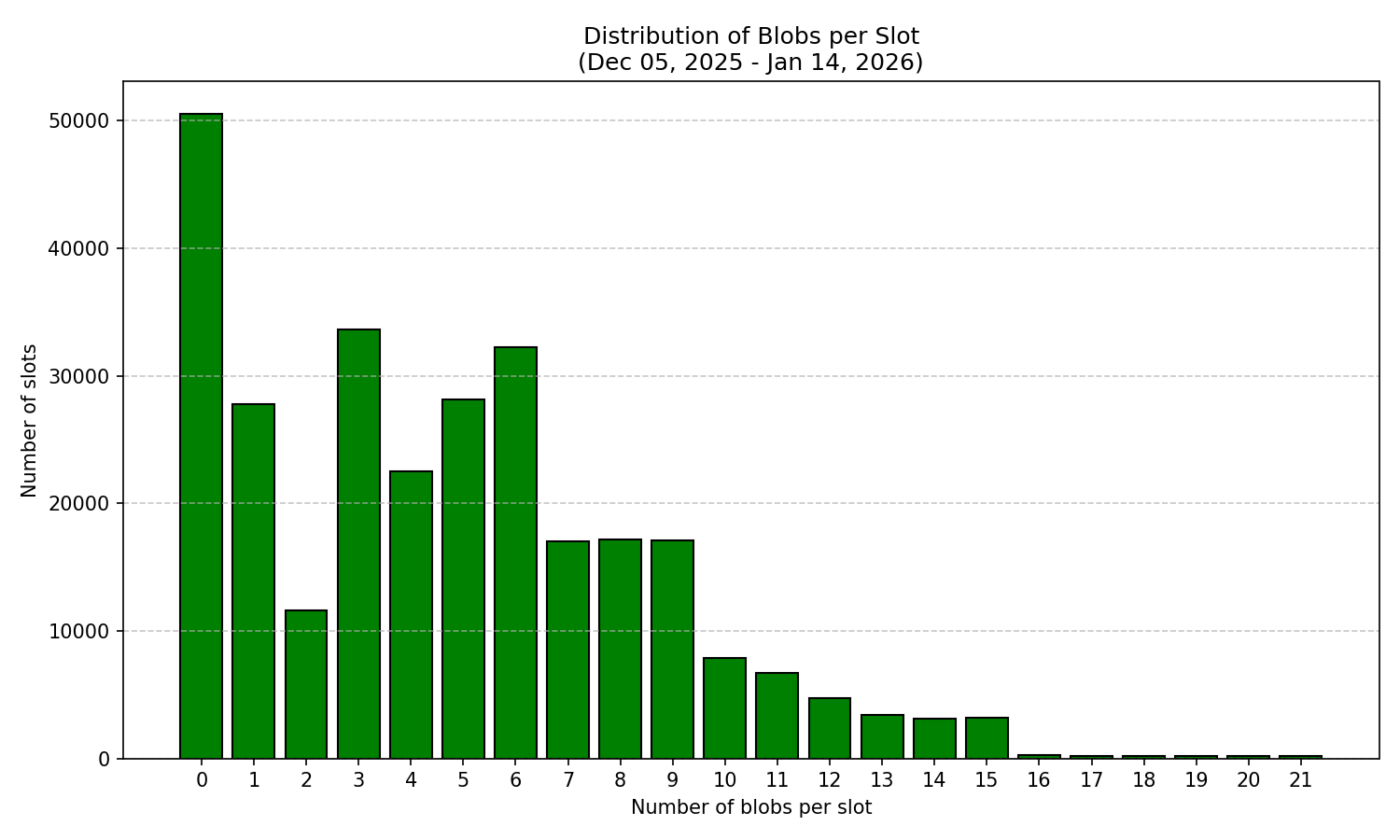
圖 3:所有觀察到的槽位中斑點計數的分佈,表明不同斑點計數的頻率不均勻。
為了準確評估漏檢概率,我們使用以下公式計算了歸一化漏檢率:
Missed blocks after slots with X blobsMiss Rate ( X ) = ——————————————————————————————————————————— × 100 Total slots with X blobs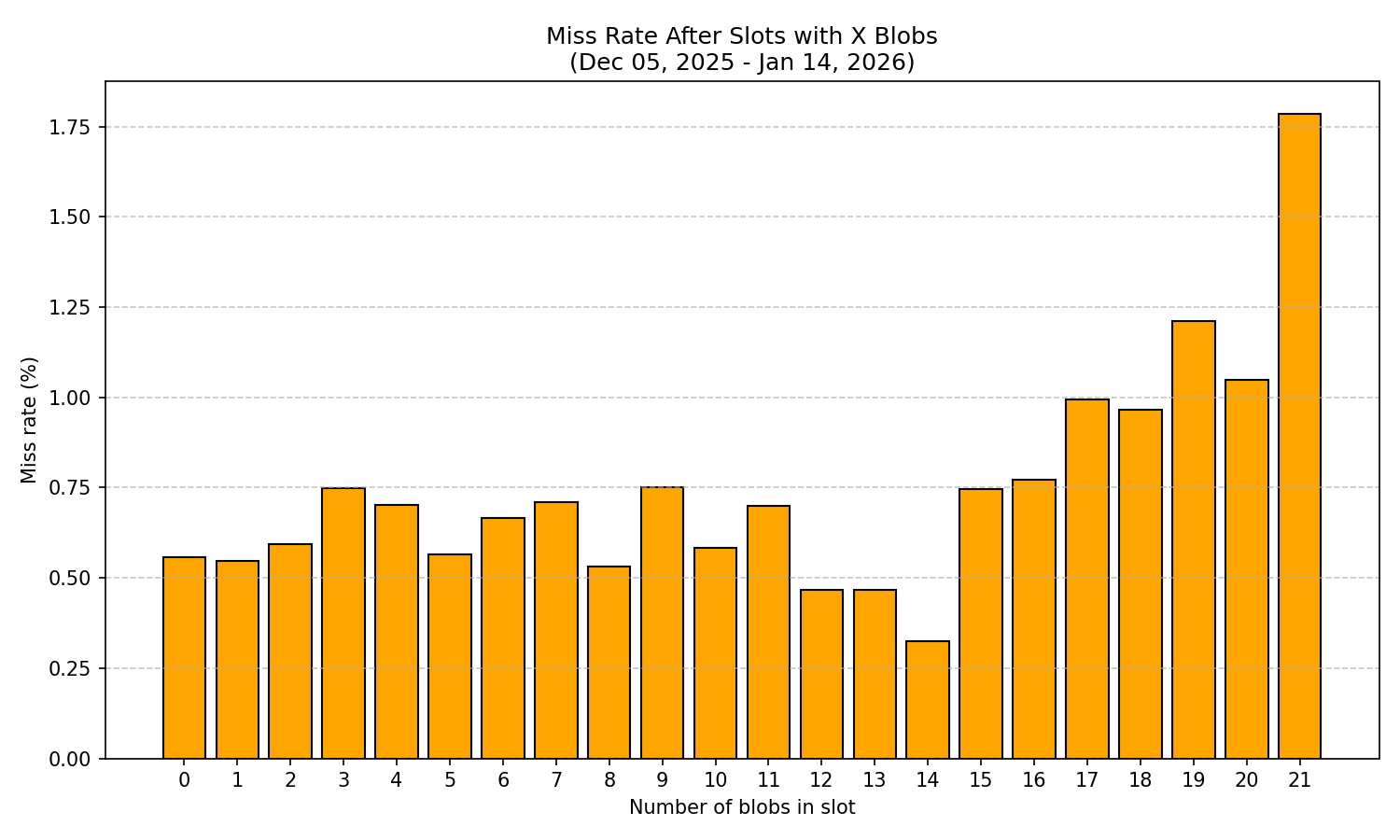
圖 4:給定數量的塊之後,丟失塊的概率。
標準化分析揭示了一些令人擔憂的模式:
- 基線漏檢率(0-15 個斑點) :在不同斑點數量下,漏檢率在 0.32% 到 1.03% 之間,平均值約為 0.5%。
- 當數據塊數量超過 16 個時,丟包率顯著升高:丟包率急劇上升,範圍從 0.77% 到 1.79%。當數據塊數量達到 21 個時,丟包率高達 1.79%,是數據塊數量較少時平均丟包率(約 0.5%)的三倍多。這表明,在處理大量數據塊時,網絡可靠性出現了令人擔憂的下降。
按斑點數量劃分的連續錯過槽位(10 個以上斑點)
| 斑點計數 | 總槽位數 | 錯過的比賽 | 漏診率(%) |
|---|---|---|---|
| 10 | 7880 | 46 | 0.58 |
| 11 | 6723 | 47 | 0.70 |
| 12 | 4717 | 22 | 0.47 |
| 13 | 3431 | 16 | 0.47 |
| 14 | 3088 | 10 | 0.32 |
| 15 | 3213 | 24 | 0.75 |
| 16 | 259 | 2 | 0.77 |
| 17 | 201 | 2 | 1.00 |
| 18 | 207 | 2 | 0.97 |
| 19 | 165 | 2 | 1.21 |
| 20 | 191 | 2 | 1.05 |
| 21 | 224 | 4 | 1.79 |
統計學考量
高 blob 數量(16+)的數據集仍然有限,每個 blob 數量的樣本量僅為 165 至 259 個槽位,而低 blob 數量的樣本量則高達數萬個槽位。然而,所有高 blob 數量(16-21)的缺失率均持續偏高,這一現象令人擔憂。即使樣本量有限,趨勢依然清晰:更高的 blob 數量與更高的缺失率相關。如果隨著需求的增加,這些偏高的缺失率持續存在或進一步惡化,網絡穩定性可能會受到嚴重威脅。
結論
容量未得到充分利用:網絡尚未達到新的目標容量。自 BPO1 以來,中位數據塊數量有所下降,高數據塊數量(16+)仍然極其罕見。沒有證據表明存在足以證明進一步增加容量的需求壓力。
高數據塊數量下的丟失率令人擔憂:包含 16 個或更多數據塊的槽位丟失率高達 0.77% 至 1.79%,相比 12 至 14 個數據塊時觀察到的 0.32% 至 0.47% 的基線水平,顯著升高。這種現象表明網絡基礎設施難以可靠地處理高數據塊數量。
網絡不穩定風險:如果需求增加,高數據塊數量變得更加普遍,當前較高的丟包率可能會加劇並威脅網絡穩定性。數據顯示,該網絡尚未做好在高數據塊數量下持續運行的準備。
在系統穩定之前,不再進行任何 BPO 更新:在以下情況發生之前,不應考慮進一步增加 blob 容量:
- 當斑點數量較高(16個以上)時,漏檢率會恢復到基線水平(約0.5%或以下)。
- 已有證據表明,市場需求能夠充分利用現有產能。
需要持續監控:在進行任何更改之前,應觀察網絡在當前容量限制下的運行情況。過早提升容量會增加網絡崩潰的風險,因為如果底層基礎設施無法可靠地支持,L2 協議可能會開始使用擴展後的容量。
方法論
本研究由 MigaLabs 使用此代碼進行。


