

作者:Tina、冬梅,InfoQ
1、時隔近三年,馬斯克再次開源 X 推薦算法
剛剛,X 工程團隊在 X 上發帖宣佈,正式開源 X 推薦算法,據介紹,這個開源庫包含為 X 上的“為你推薦”信息流提供支持的核心推薦系統,它將網絡內內容(來自用戶關注的帳戶)與網絡外內容(通過基於機器學習的檢索發現)相結合,並使用基於 Grok 的 Transformer 模型對所有內容進行排名,也就是說,該算法採用了與 Grok 相同的 Transformer 架構。
開源地址:https://x.com/XEng/status/2013471689087086804
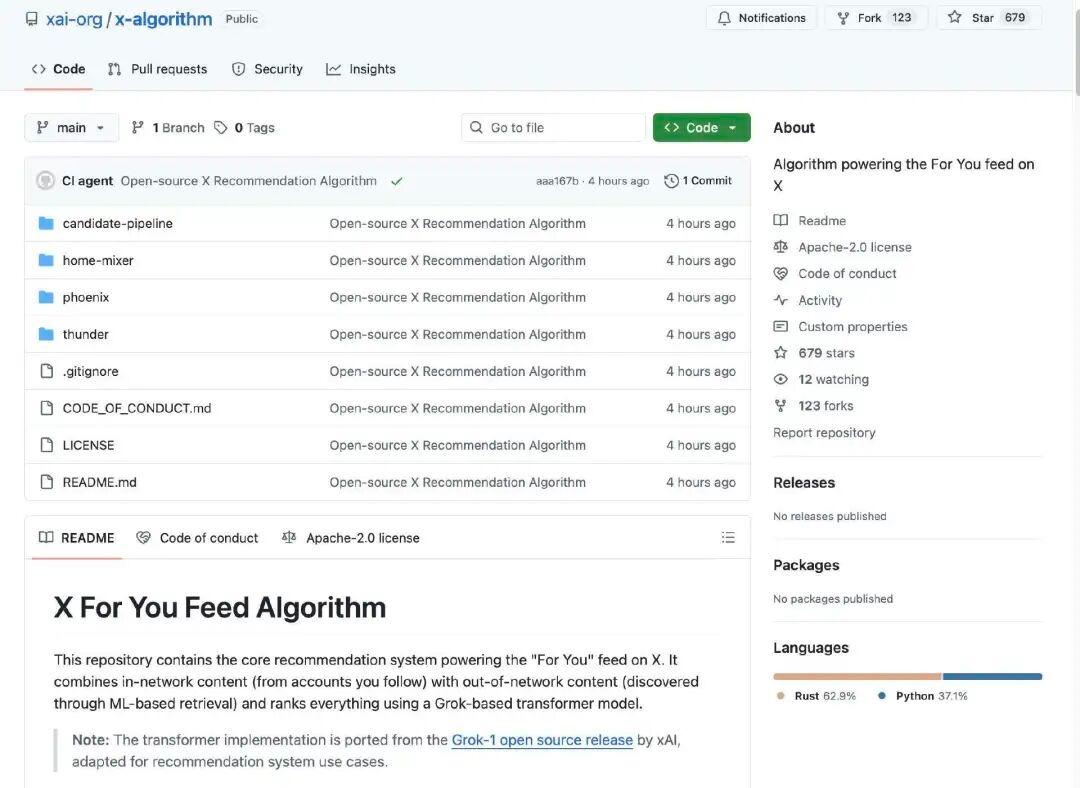
X 的推薦算法負責生成用戶在主界面看到的“為你推薦”(For You Feed)內容。它從兩個主要來源獲取候選帖子:
你關注的賬號(In-Network / Thunder)
平臺上發現的其他帖子(Out-of-Network / Phoenix)
這些候選內容隨後被統一處理、過濾然後按相關性排序。
那麼,算法核心架構與運行邏輯是怎樣的?
算法先從兩類來源抓取候選內容:
關注內的內容:來自你主動關注的賬號發佈的帖子。
非關注內容:由系統在整個內容庫中檢索出的、可能你感興趣的帖子。
這一階段的目標是“把可能相關的帖子找出來。
系統自動去除低質量、重複、違規或不合適的內容。例如:
已屏蔽賬號的內容
與用戶明確不感興趣的主題
非法、過時或無效帖子
這樣確保最終排序時只處理有價值的候選內容。
此次開源的算法的核心是系統使用一個 Grok-based Transformer 模型(類似大型語言模型 / 深度學習網絡)對每條候選帖子進行評分。Transformer 模型根據用戶的歷史行為(點贊、回覆、轉發、點擊等)預測每種行為的概率。最後,將這些行為概率加權組合成一個綜合得分,得分越高的帖子越有可能被推薦給用戶。
這一設計把傳統手工提取特徵的做法基本廢除,改用端到端的學習方式預測用戶興趣。
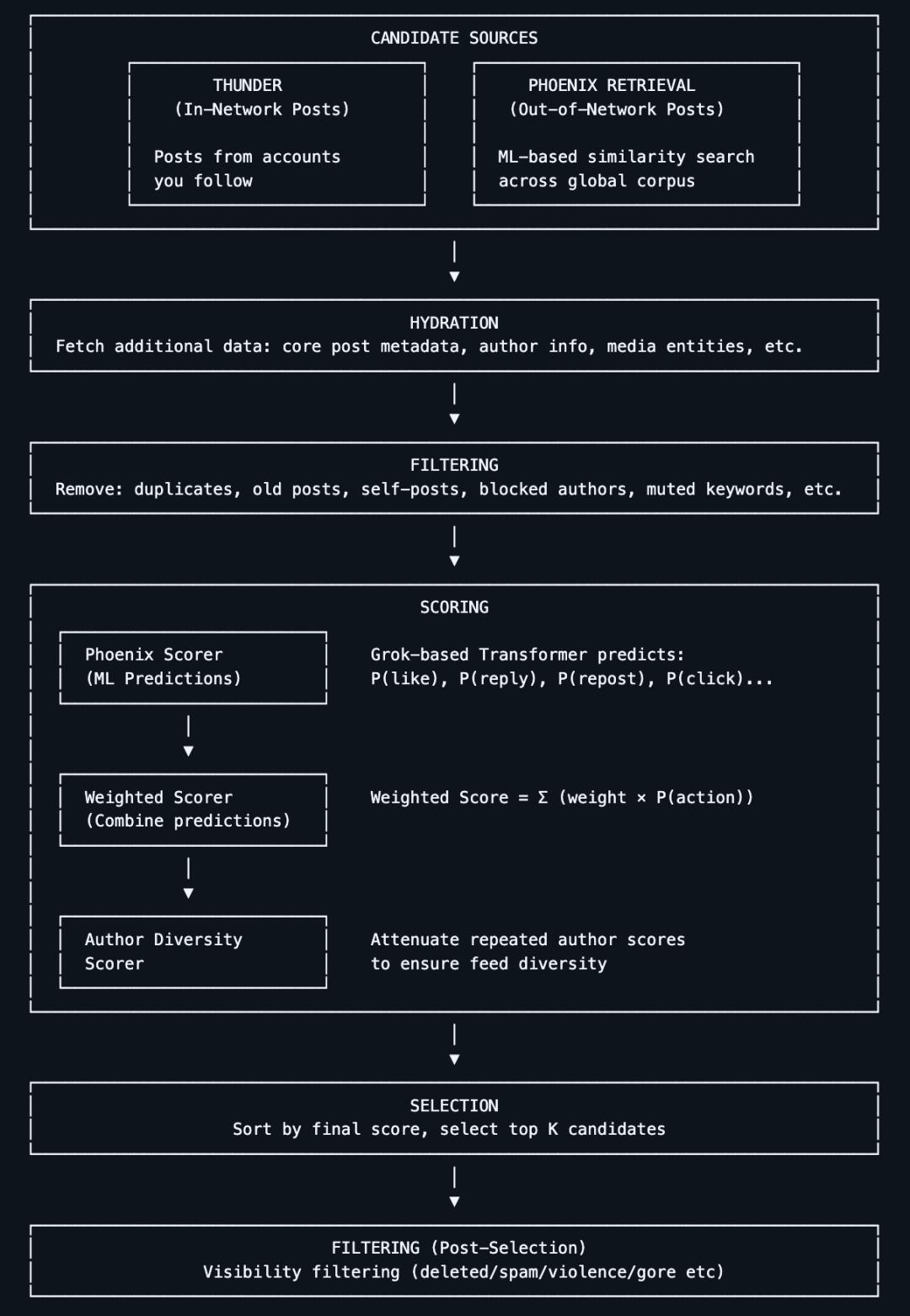
這不是馬斯克第一次開源 X 推薦算法。
早在 2023 年 3 月 31 日,正如馬斯克收購 Twitter 時承諾的那樣,他已將 Twitter 部分源代碼正式開源,其中包括在用戶時間線中推薦推文的算法。開源當天,該項目在 GitHub 已收穫 10k+ 顆 Star。
當時,馬斯克在 Twitter 上表示此次發佈的是“大部分推薦算法”,其餘的算法也將陸續開放。他還提到,希望“獨立的第三方能夠以合理的準確性確定 Twitter 可能向用戶展示的內容”。
在關於算法發佈的 Space 討論中,他說此次開源計劃是想讓 Twitter 成為“互聯網上最透明的系統”,並讓它像最知名也最成功的開源項目 Linux 一樣健壯。“總體目標,就是讓繼續支持 Twitter 的用戶們最大程度享受這裡。”
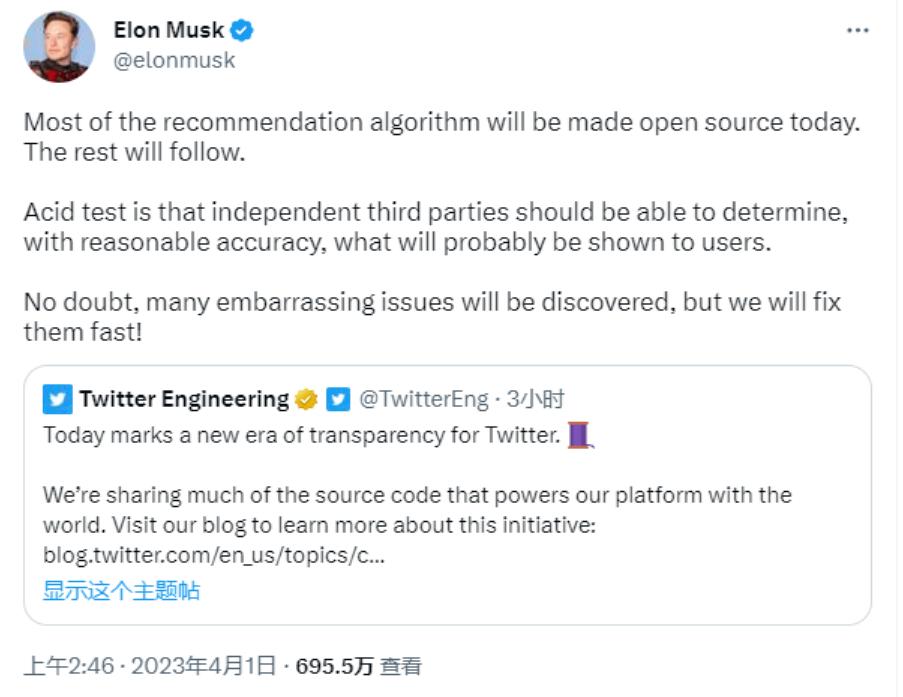
如今距離馬斯克初次開源 X 算法,過去了近三年的時間。而作為技術圈的超級 KOL,馬斯克早已為此次開源做足了的宣傳。
1 月 11 日,馬斯克在 X 上發帖稱,將於 7 天內將新的 X 算法(包括用於確定向用戶推薦哪些自然搜索內容和廣告內容的所有代碼)開源。
此流程將每 4 周重複一次,並附有詳細的開發者說明,以幫助用戶瞭解發生了哪些變化。
今天,他的承諾再次兌現了。
2、 馬斯克為什麼要開源?
當埃隆·馬斯克再次提到“開源”時,外界的第一反應並非技術理想主義,而是現實壓力。
過去一年裡,X 因其內容分發機制屢次陷入爭議。該平臺被廣泛批評在算法層面偏袒和助長右翼觀點,這種傾向並非零星個案,而被認為具有系統性特徵。去年發佈的一份研究報告就指出,X 的推薦系統在政治內容傳播上出現了明顯的新偏見。
與此同時,一些極端案例進一步放大了外界的質疑。去年,一段涉及美國右翼活動人士查理·柯克遇刺的未經審查視頻在 X 平臺迅速傳播,引發輿論震動。批評者認為,這不僅暴露了平臺審核機制的失效,也再次凸顯了算法在“放大什麼、不放大什麼”上的 隱性權力。
在這樣的背景下,馬斯克突然強調算法透明性,很難被簡單解讀為一次純粹的技術決策。

3、 網友怎麼看?
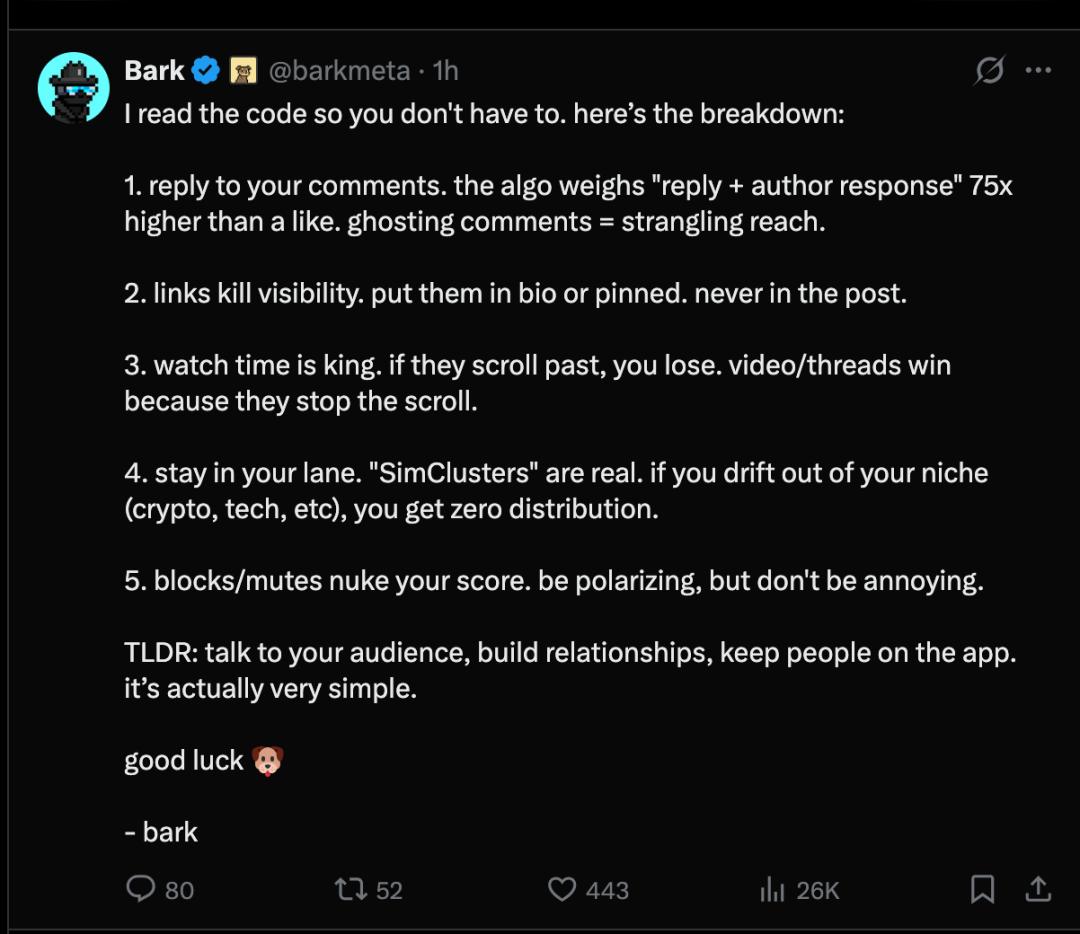
X 推薦算法開源後,在 X 平臺,有用戶對推薦算法機制做了以下 5 點總結:
- 回覆你的評論。算法對“回覆 + 作者回應”的權重是點讚的 75 倍。不回覆評論會嚴重影響曝光率。
- 鏈接會降低曝光率。應該把鏈接放在個人簡介或置頂帖裡,千萬不要放在帖子正文中。
- 觀看時長至關重要。如果他們滑動屏幕略過,你就不會吸引他們。視頻 / 帖子之所以能獲得高關注,是因為它們能讓用戶停下來。
- 堅守你的領域。“模擬集群”是真實存在的。如果你偏離了你的細分領域(加密貨幣、科技等),你將無法獲得任何分銷渠道。
- 屏蔽 / 默不作聲會大幅降低你的分數。要有爭議性,但不要令人討厭。
簡而言之:與你的受眾溝通,建立關係,讓用戶留在應用內。其實很簡單。
也有網友發現,雖然架構是開源的,但還有些內容仍未開源。該網友表示,此次發佈本質上是一個框架,沒有引擎。具體少了啥?
缺少權重參數 - 代碼確認“積極行為加分”和“消極行為扣分”,但與 2023 年版本不同的是,具體的數值被刪除了。
隱藏模型權重 - 不包含模型本身的內部參數和計算。
未公開的訓練數據 - 對於訓練模型的數據、用戶行為的採樣方式,以及如何構建“好”樣本與“壞”樣本,我們一無所知。
對於普通 X 用戶而言,X 的算法開源並不會造成太大影響。但更高的透明度可以解釋為什麼有些帖子能獲得曝光而另一些則無人問津,並使研究人員能夠研究平臺如何對內容進行排名。
4、 為什麼推薦系統是必爭之地?
在大多數技術討論中,推薦系統往往被視為後臺工程的一部分,低調、複雜,卻很少站在聚光燈下。但如果真正拆解互聯網巨頭的商業運轉方式,會發現推薦系統並不是邊緣模塊,而是支撐整個商業模式的“基礎設施級存在”。正因如此,它可以被稱為互聯網行業的“沉默巨獸”。
公開數據已經反覆印證了這一點。亞馬遜曾披露,其平臺約 35% 的購買行為直接來自推薦系統;Netflix 更為激進,約 80% 的觀看時長由推薦算法驅動;YouTube 的情況同樣類似,大約 70% 的觀看來自推薦系統,尤其是信息流(feed)。至於 Meta,雖然從未給出明確比例,但其技術團隊曾提到,公司內部計算集群中約 80% 的算力週期都用於服務推薦相關任務。
這些數字意味著什麼?如果將推薦系統從這些產品中移除,幾乎等同於抽掉地基。就拿 Meta 來說,廣告投放、用戶停留時長、商業轉化,幾乎都建立在推薦系統之上。推薦系統不僅決定用戶“看什麼”,更直接決定平臺“如何賺錢”。
然而,正是這樣一個決定生死的系統,長期面臨著工程複雜度極高的問題。
在傳統推薦系統架構中,很難用一個統一模型覆蓋所有場景。現實中的生產系統往往高度碎片化。以 Meta、LinkedIn、Netflix 這類公司為例,一個完整的推薦鏈路背後,通常同時運行著 30 個甚至更多專用模型:召回模型、粗排模型、精排模型、重排模型,各自針對不同目標函數和業務指標進行優化。每個模型背後,往往對應一個甚至多個團隊,負責特徵工程、訓練、調參、上線與持續迭代。
這種模式的代價是顯而易見的:工程複雜、維護成本高、跨任務協同困難。一旦有人提出“是否可以用一個模型解決多個推薦問題”,對整個系統而言,意味著複雜度的數量級下降。這正是行業長期渴望卻難以實現的目標。
大型語言模型的出現,給推薦系統提供了一條新的可能路徑。
LLM 已經在實踐中證明,它可以成為極其強大的通用模型:在不同任務之間遷移能力強,隨著數據規模和算力的擴展,性能還能持續提升。相比之下,傳統推薦模型往往是“任務定製型”的,很難在多個場景之間共享能力。
更重要的是,單一大模型帶來的不僅是工程簡化,還包括“交叉學習”的潛力。當同一個模型同時處理多個推薦任務時,不同任務之間的信號可以相互補充,隨著數據規模增長,模型更容易整體進化。這正是推薦系統長期渴望、卻很難通過傳統方式實現的特性。
LLM 改變了什麼?其實是改變了從特徵工程到理解能力。
從方法論層面看,LLM 對推薦系統最大的改變,發生在“特徵工程”這一核心環節。
在傳統推薦系統中,工程師需要先人為構造大量信號:用戶點擊歷史、停留時長、相似用戶偏好、內容標籤等,然後明確告訴模型“請基於這些特徵做判斷”。模型本身並不理解這些信號的語義,只是在數值空間中學習映射關係。
而引入語言模型後,這一流程被高度抽象。你不再需要逐條指定“看這個信號、忽略那個信號”,而是可以直接向模型描述問題本身:這是一個用戶,這是一個內容;這個用戶過去喜歡過類似內容,其他用戶也對這個內容有正反饋——現在請判斷,這條內容是否應該推薦給這個用戶。
語言模型本身已經具備理解能力,它可以自行判斷哪些信息是重要信號,如何綜合這些信號做出決策。在某種意義上,它不只是執行推薦規則,而是在“理解推薦這件事”。
這種能力的來源,在於 LLM 在訓練階段接觸過海量、多樣化的數據,使其更容易捕捉細微但重要的模式。相比之下,傳統推薦系統必須依賴工程師顯式枚舉這些模式,一旦遺漏,模型就無法感知。
從後端視角看,這種變化並不陌生。就像你向 GPT 提問,它會基於上下文信息生成回答;同樣地,當你問它“我是否會對這條內容感興趣”,它也可以基於已有信息做出判斷。某種程度上,語言模型本身已經天然具備“推薦”的能力。






