

原文作者:Jtsong.eth (Ø,G)(X:@Jtsong2)
近期加密投研智庫 @MessariCrypto 出臺了一篇關於0G的綜合深度研究報告,本文是中文精華總結版:
【核心摘要】
隨著 2026 年去中心化人工智能(DeAI)賽道的爆發,0G (Zero Gravity) 以其顛覆性的技術架構,徹底終結了 Web3 無法承載大規模 AI 模型的歷史難題。其核心殺手鐧可歸納為:
極速性能引擎(50 Gbps 吞吐量):通過邏輯解耦與多級並行分片,0G 實現了相較於傳統 DA 層(如以太坊、Celestia)逾 60 萬倍 的性能跨越,成為全球唯一能支持 DeepSeek V3 等超大規模模型實時分發的協議。
dAIOS 模塊化架構:首創“結算、存儲、數據可用性(DA)、計算”四層協同的操作系統範式,打破了傳統區塊鏈的“存儲赤字”與“計算滯後”,實現了 AI 數據流與執行流的高效閉環。
AI 原生可信環境(TEE + PoRA):通過可信執行環境(TEE)與隨機訪問證明(PoRA)的深度集成,0G 不僅解決了海量數據的“熱存儲”需求,更構建了一個無需信任、隱私受保護的 AI 推理與訓練環境,實現了從“賬本”向“數字生命底座”的飛躍。
第一章 宏觀背景:AI 與 Web3 的“解耦與重構”
在人工智能進入大模型時代的背景下,數據、算法與算力成為了核心生產要素。然而,現有的傳統區塊鏈基礎設施(如以太坊、Solana)在承載 AI 應用時正面臨嚴峻的“性能錯位”。
1. 傳統區塊鏈的侷限性:吞吐量與存儲的瓶頸
傳統的 Layer 1 區塊鏈設計初衷是處理金融賬本交易,而非承載 TB 級別的 AI 訓練數據集或高頻的模型推理任務。
存儲赤字:以太坊等鏈的數據存儲成本極高,且缺乏對非結構化大數據(如模型權重文件、視頻數據集)的原生支持。
吞吐量瓶頸:以太坊的 DA(數據可用性)帶寬僅為約 80KB/s,即便經過 EIP-4844 升級,也遠無法滿足大型語言模型(LLM)實時推理所需的 GB 級吞吐需求。
計算滯後:AI 推理要求極低的延遲(毫秒級),而區塊鏈的共識機制往往以秒為單位,導致“鏈上 AI”在現有架構下幾乎不可行。
2. 0G 的核心使命:打破“數據牆”
AI 行業目前被中心化巨頭壟斷,形成了事實上的“數據牆(Data Wall)”,導致數據隱私受限、模型輸出不可驗證且租用成本昂貴。0G (Zero Gravity) 的出現,標誌著 AI 與 Web3 的深度重構。它不再僅僅將區塊鏈視為一個存儲哈希值的賬本,而是通過模塊化架構將 AI 所需的“數據流、存儲流、計算流”進行解耦。0G 的核心使命是打破中心化黑盒,通過去中心化技術讓 AI 資產(數據和模型)成為主權可擁有的公共商品。
在理解了這種宏觀錯位後,我們需要深入剖析 0G 如何通過一套嚴密的四層架構,將這些碎片化的痛點逐一擊破。
第二章 核心架構:模塊化 0G Stack 的四層協同
0G 並非簡單的單一區塊鏈,而是被定義為 dAIOS (去中心化 AI 操作系統)。這一概念的核心在於,它為 AI 開發者提供了一個類似操作系統的完整協議棧,通過四層架構的深度協同,實現了性能的指數級躍升。
1. dAIOS 的四層架構解析
0G Stack 通過解耦執行、共識、存儲與計算,確保了每一層都能獨立擴展:

2. 0G Chain:基於 CometBFT 的性能底座
作為 dAIOS 的神經中樞,0G Chain 採用了高度優化的 CometBFT 共識機制。其創新之處在於將執行層與共識層分離,並通過流水線並行處理(Pipelining)和 ABCI 模塊化設計,大幅縮減了區塊生產的等待時間。 性能指標:根據最新基準測試,0G Chain 在單分片下可實現 11,000+ TPS 的吞吐量,並具備亞秒級(Sub-second)的最終確認性。這種極高性能確保了在大規模 AI 代理(AI Agents)高頻交互時,鏈上結算不會成為瓶頸。
3. 0G Storage 與 0G DA 的解耦協同
0G 的技術護城河在於其“雙通道”設計,將數據發佈與持久化存儲分離:
0G DA:專注於 Blob 數據的快速廣播與採樣驗證。它支持單 Blob 最高約 32.5 MB,通過糾刪碼(Erasure Coding)技術,即便部分節點離線,也能確保數據可用。
0G Storage:通過“日誌層(Log Layer)”處理不可變數據,通過“鍵值層(KV Layer)”處理動態狀態。
這種四層協同架構為高性能 DA 層提供了生長的土壤,接下來我們將深入探討 0G 核心引擎中最具震撼力的部分——高性能 DA 技術。
第三章 高性能 DA 層(0G DA)的技術深潛
在 2026 年的去中心化 AI 生態中,數據可用性(DA)不僅僅是“發佈證明”,而必須承載 PB 級 AI 權重文件與訓練集的實時管道。
3.1 邏輯解耦與物理協同:“雙通道”架構的代際演進
0G DA 的核心優越性源於其獨特的“雙通道”架構:將數據發佈(Data Publishing)與數據存儲(Data Storage)在邏輯上徹底解耦,但在物理節點層面實現高效協同。
邏輯解耦:不同於傳統 DA 層將數據發佈與長期存儲混為一談,0G DA 僅負責驗證數據塊在短時間內的可訪問性,而將海量數據的持久化交由 0G Storage。
物理協同:存儲節點利用隨機訪問證明(PoRA)確保數據真實存在,而 DA 節點則通過基於分片的共識網絡確保透明度,實現了“即發即驗、存驗一體”。
3.2 性能標杆:量級領先的數據對壘
0G DA 在吞吐量上的突破,直接定義了去中心化 AI 操作系統的性能邊界。下表展示了 0G 與主流 DA 方案的技術參數對比:
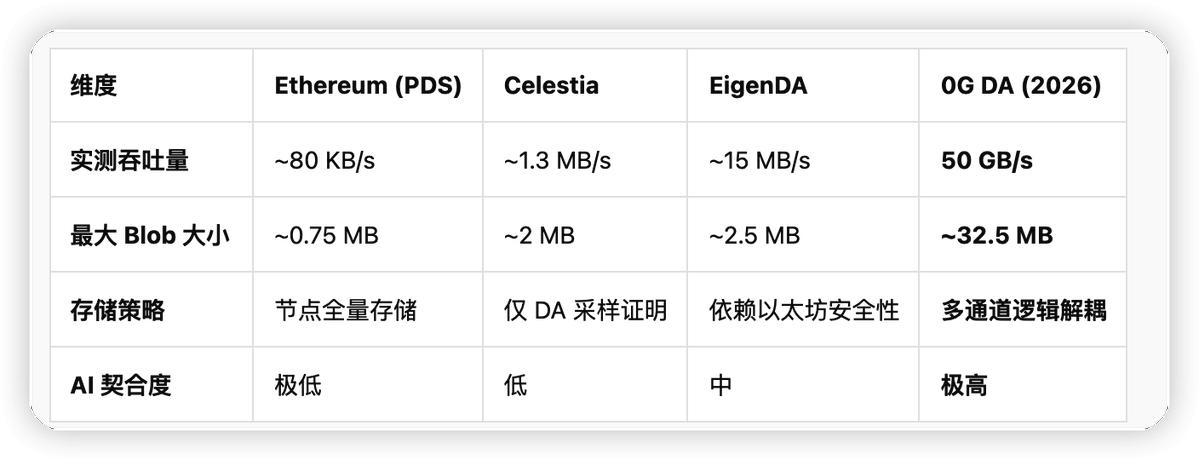
3.3 實時可用性的技術底座:糾刪碼與多共識分片
為了支撐海量 AI 數據,0G 引入了糾刪碼(Erasure Coding)與多共識分片(Multi-sharding):
糾刪碼優化:通過增加冗餘證明,即使網絡中大量節點離線,仍能通過採樣極小的數據片段恢復完整信息。
多共識分片:0G 摒棄了單條鏈處理所有 DA 的線性邏輯。通過橫向擴展共識網絡,使總吞吐量隨節點數量增加而線性增長。在 2026 年的實測中,支撐了每秒數萬次的 Blob 驗證請求,確保了 AI 訓練流的連續性。
僅僅有高速的數據通道是不夠的,AI 還需要一個低延遲的“大腦存儲”和安全隱私的“執行空間”,這便引出了 AI 專用優化層。
第四章 AI 專用優化與安全算力增強
4.1 解決 AI 代理(AI Agents)的延遲焦慮
對於實時執行策略的 AI Agents 而言,數據讀取延遲是決定其生存的生死線。
冷熱數據分離架構:0G Storage 內部劃分為不可變日誌層(Log Layer)與可變狀態層(KV Layer)。熱數據存儲於高性能 KV 層,支持亞秒級隨機訪問。
高性能索引協議:利用分佈式哈希表(DHT)與專用元數據索引節點,AI 代理能在毫秒級定位所需的模型參數。
4.2 TEE 增強:構建 Trustless AI 的最後一塊拼圖
0G 在 2026 年全面引入了 TEE(可信執行環境) 安全升級。
計算隱私化:模型權重與用戶輸入在 TEE 內部的“隔離區”處理。即便節點運營商也無法窺視計算過程。
結果可驗證性:TEE 生成的遠程靜默證明(Remote Attestation)會連同計算結果一同提交至 0G Chain,確保結果由特定的未篡改模型生成。
4.3 願景實現:從存儲到操作系統的躍遷
AI 代理不再是孤立的腳本,而是擁有主權身份(iNFT 標準)、受保護記憶(0G Storage)與可驗證邏輯(TEE Compute)的數字生命實體。這種閉環消除了中心化雲廠商對 AI 的壟斷,標誌著去中心化 AI 進入了大規模商用時代。
然而,要承載這些“數字生命”,底層的分佈式存儲必須經歷一場從“冷”到“熱”的性能革命。
第五章 分佈式存儲層的創新——從“冷存檔”到“熱性能”的範式革命
0G Storage 的核心創新在於打破了傳統分佈式存儲在性能上的桎梏。
1. 雙層架構:Log Layer 與 KV Layer 的解耦
Log Layer(流式數據處理):專為非結構化數據(如訓練日誌、數據集)設計。通過追加寫(Append-only)模式,確保海量數據在分佈式節點間實現毫秒級的同步。
KV Layer(索引與狀態管理):針對結構化數據,提供高性能索引支持。在調取模型參數權重(Weights)時,將響應延遲壓低至毫秒級。
2. PoRA (Proof of Random Access):抗 Sybil 攻擊與驗證體系
為了確保存儲的真實性,0G 引入了 PoRA (隨機訪問證明)。
抗女巫攻擊:PoRA 將挖礦難度與實際佔用的物理存儲空間直接掛鉤。
可驗證性:允許網絡對節點進行隨機“抽查”,確保數據不僅被存儲,而且處於“隨時可用”的熱激活狀態。
3. 性能跨越:秒級檢索的工程實現
0G 通過糾刪碼與高帶寬 DA 通道的結合,實現了從“分鐘級”到“秒級”的檢索跨越。這種“熱存儲”能力,性能足以媲美中心化雲服務。
這種存儲性能的飛躍,為支撐百億級參數的模型提供了堅實的去中心化底座。
第六章 AI 原生支持——百億級參數模型的去中心化底座
1. AI Alignment Nodes:AI 工作流的守護者
AI Alignment Nodes(AI 對齊節點) 負責監控存儲節點與服務節點間的協作。通過對訓練任務真實性驗證,確保 AI 模型運行不偏離預設邏輯。
2. 支撐大規模並行 I/O
處理百億、千億級參數模型(如 Llama 3 或 DeepSeek-V3),需要極高的並行 I/O。0G 通過數據切片與多共識分片技術,允許數千個節點同時處理大規模數據集讀取。
3. 檢查點(Checkpoints)與高帶寬 DA 的協同
故障恢復:0G 能夠將百 GB 級別的檢查點文件迅速持久化。
無感恢復:得益於 50 Gbps 吞吐上限,新節點可以瞬間從 DA 層同步最新的檢查點快照,解決了去中心化大模型訓練難以長期維持的痛點。
在技術細節之外,我們必須將視野放大到整個行業,看 0G 是如何橫掃現有市場的。
第七章 競爭格局——0G 的維度碾壓與差異化優勢
7.1 主流 DA 方案的橫向測評
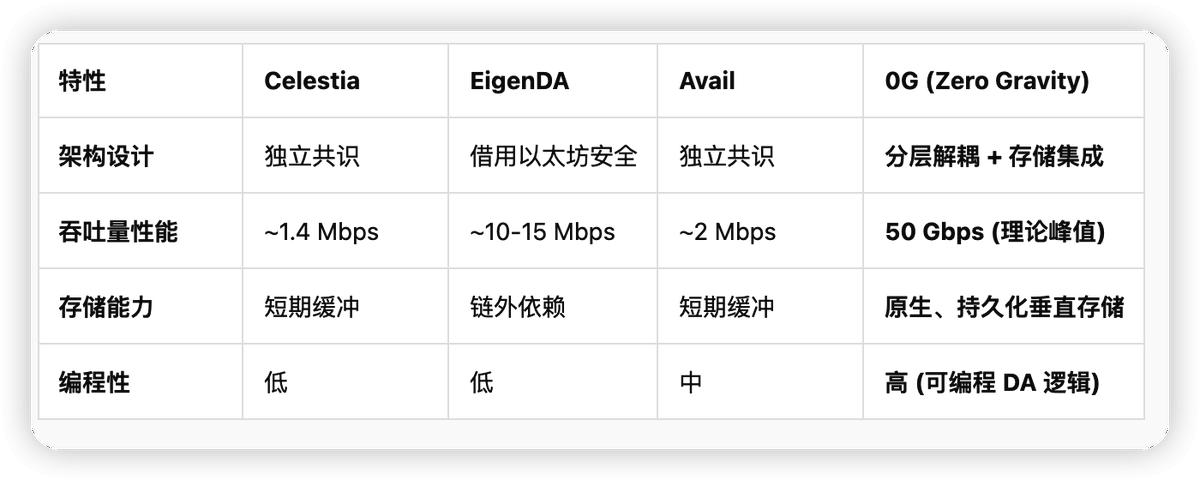
7.2 核心競爭力:可編程 DA 與垂直集成存儲
消除傳輸瓶頸:原生融合存儲層,使 AI 節點直接從 DA 層檢索歷史數據。
50Gbps 的吞吐量飛躍:比競品快了幾個數量級,支撐實時推理。
可編程性(Programmable DA):允許開發者自定義數據分配策略,動態調整數據冗餘度。
這種維度的碾壓預示著一個龐大經濟體的崛起,而代幣經濟學則是驅動這一體系的燃料。
第八章 2026 生態展望與代幣經濟學
隨著 2025 年主網的平穩運行,2026 年將成為 0G 生態爆發的關鍵節點。
8.1 $0G 代幣:多維價值捕獲路徑
資源支付(Work Token):訪問高性能 DA 和存儲空間的唯一媒介。
安全抵押(Staking):驗證者和存儲提供者必須質押 $0G,提供網絡收益分紅。
優先級分配:在繁忙期,代幣持有量決定計算任務的優先級。
8.2 2026 生態激勵與挑戰
0G 計劃啟動 "Gravity Foundation 2026" 專項基金,重點扶持 DeAI 推理框架與數據眾籌平臺。儘管技術領先,但 0G 仍面臨節點硬件門檻高、生態冷啟動及合規性等挑戰。





