如果我們只保留 1 年的活躍狀態呢?
特別感謝 Gary Rong、Gabriel Rocheleau 和 Guillaume Ballet 對本文的審閱。
我們已經多次討論過狀態過期作為解決以太坊狀態增長問題的長期方案,但很少有數據表明它會對日常節點運行產生怎樣的影響。
為了使討論更加具體,我們使用真實的主網工作負載進行了一個簡單的實驗:在(1)具有完整狀態的節點和(2)僅保留1 年活動狀態的節點上執行約 1 年的區塊(基於區塊執行期間實際觸及的內容)。
免責聲明:這並非狀態過期機制的完整協議實現(沒有復活見證,也沒有網絡檢索)。這是一個“假設”性能實驗:如果數據庫僅包含在特定時間段內實際訪問的狀態,執行性能會發生什麼變化?
太長不看
- 州規模下降了約78% 。
- 與主網區塊過去一年左右的時間相比,區塊重新執行時間縮短了約 15% 。
- 讀取性能提升幅度最大,尤其是存儲讀取( P50 -46% , P99 -36% )。
- 尾部延遲有所改善,這對於在高負載下保持靠近頭部位置至關重要( P99 塊插入 -21% )。
基準測試設置
在這個實驗中,我們將具有完整狀態的節點與僅存儲1 年活躍狀態的節點進行比較。
- 客戶端: go-ethereum v1.16.5
- 機器:符合EIP-7870規範
- 工作負載:執行19,999,256到22,627,956個數據塊(約 1 年)
- 運行次數: 3 次,報告平均值
一年期活躍狀態數據庫的構建方式:
- 將區塊 19,999,256 → 22,627,956 中的節點同步(“跟蹤”節點)。
- 每次在區塊處理期間訪問狀態的一部分(帳戶、存儲槽、trie 節點)時,將其標記為已訪問。
- 從第 19,999,256 個區塊的數據庫開始,然後使用跟蹤節點的標記刪除未標記的狀態。這就得到了精簡後的數據庫。
- 刪除狀態後,修剪後的數據庫不會手動壓縮。
注意:失敗的交易仍然會觸發標記(因為它們在執行嘗試期間仍然會改變狀態)。在實際的過期機制實現中,失敗的交易可能不會被標記,這會增加非活動狀態的集合。
結果
1. 州面積
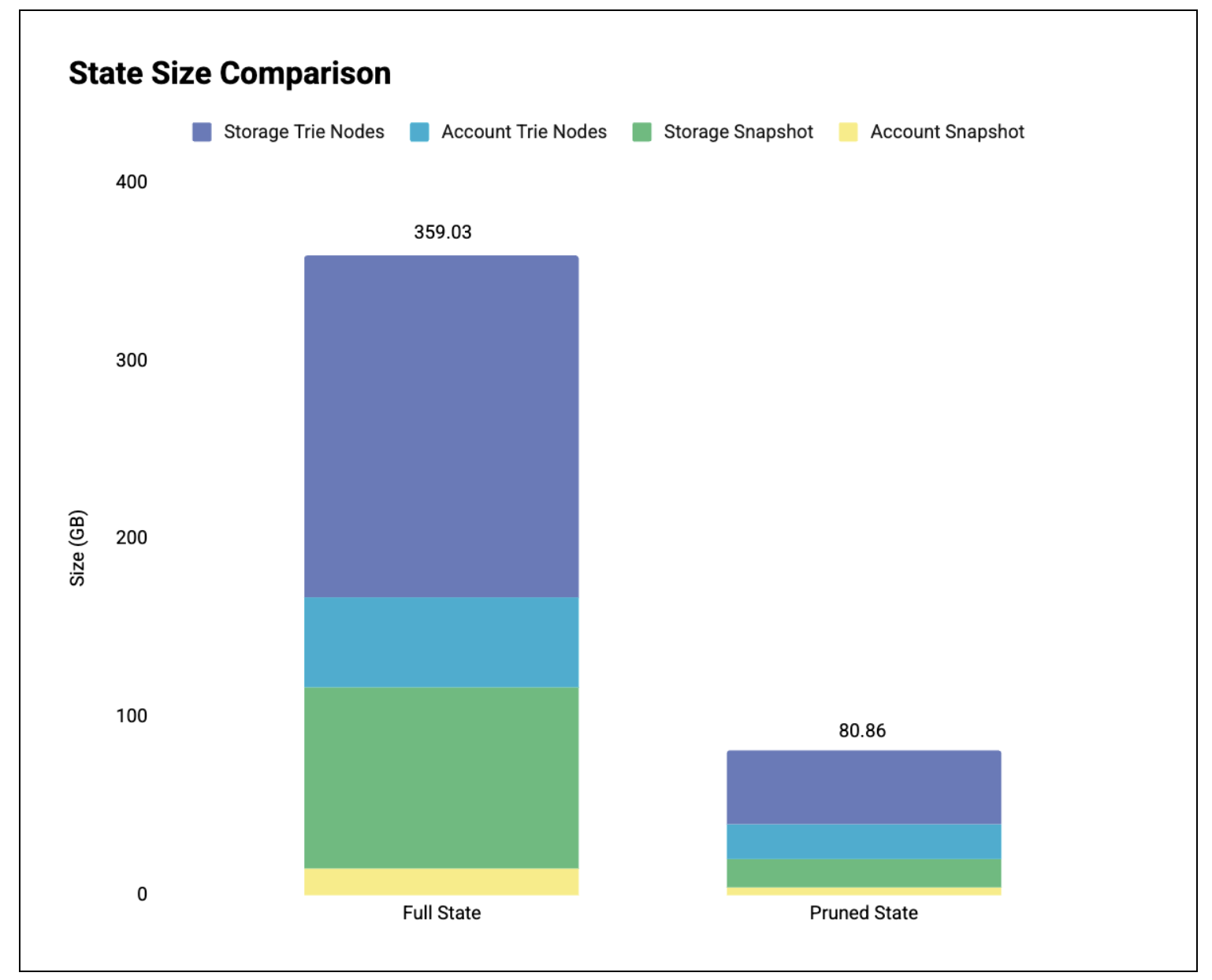
圖 1:數據庫中的狀態大小比較。
表格明細(單位:GB):
| 完整狀態 | 修剪狀態 | 減少 | |
|---|---|---|---|
| 賬戶快照 | 14.65 | 3.60 | 75.43% |
| 賬戶樹節點 | 50.34 | 19.89 | 60.49% |
| 存儲快照 | 101.87 | 15.95 | 84.34% |
| 存儲樹節點 | 192.17 | 41.42 | 78.45% |
| 全部的 | 359.03 | 80.86 | 77.48% |
結果:大幅減少磁盤佔用空間。
- 完整狀態: 359.03 GB
- 精簡後狀態: 80.86 GB ( -77.5% )
大部分資源佔用減少都來自存儲樹節點。這反映了存儲樹本身就比賬戶樹大得多,因此需要修剪的節點也更多。賬戶樹規模較小,訪問密度更高:每次賬戶訪問都會使樹中更大比例的節點保持存活。這些結果也與我們之前的狀態分析相符。
geth 中的“快照”是什麼?
在 geth 中,快照是 trie 樹葉子節點(賬戶和存儲)的扁平化表示,旨在加速讀取操作,而無需遍歷 trie 樹路徑。它們主要是一種讀取優化結構。
2. 端到端執行時間
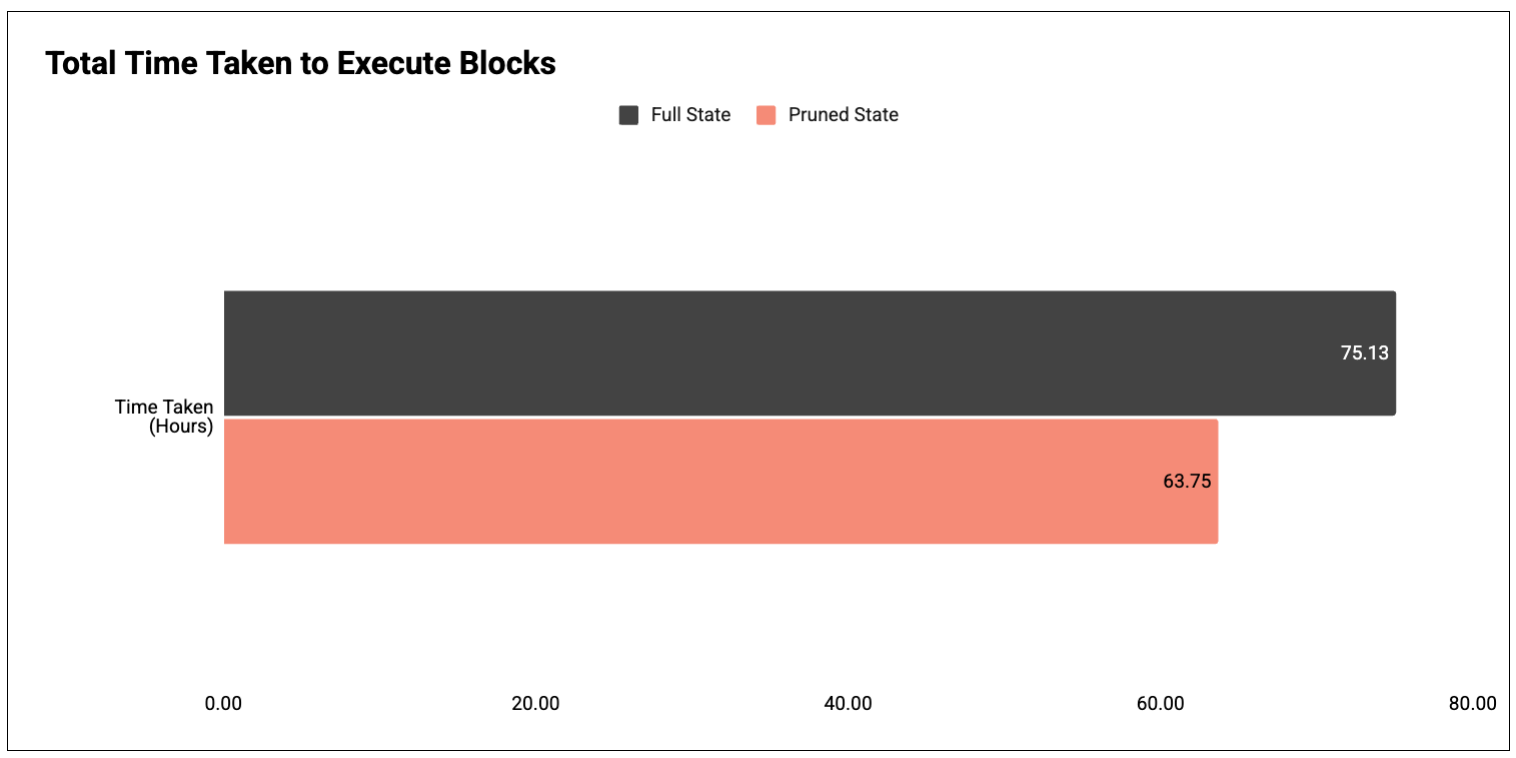
圖 2:執行第 19,999,256 至 22,627,956 個塊所花費的總時間。
結果:修剪後的節點比未修剪的節點運行速度快約 15% 。
- 完整狀態: 75.13 小時
- 修剪後狀態: 63.75 小時( -15% )
3. 塊插入和預取
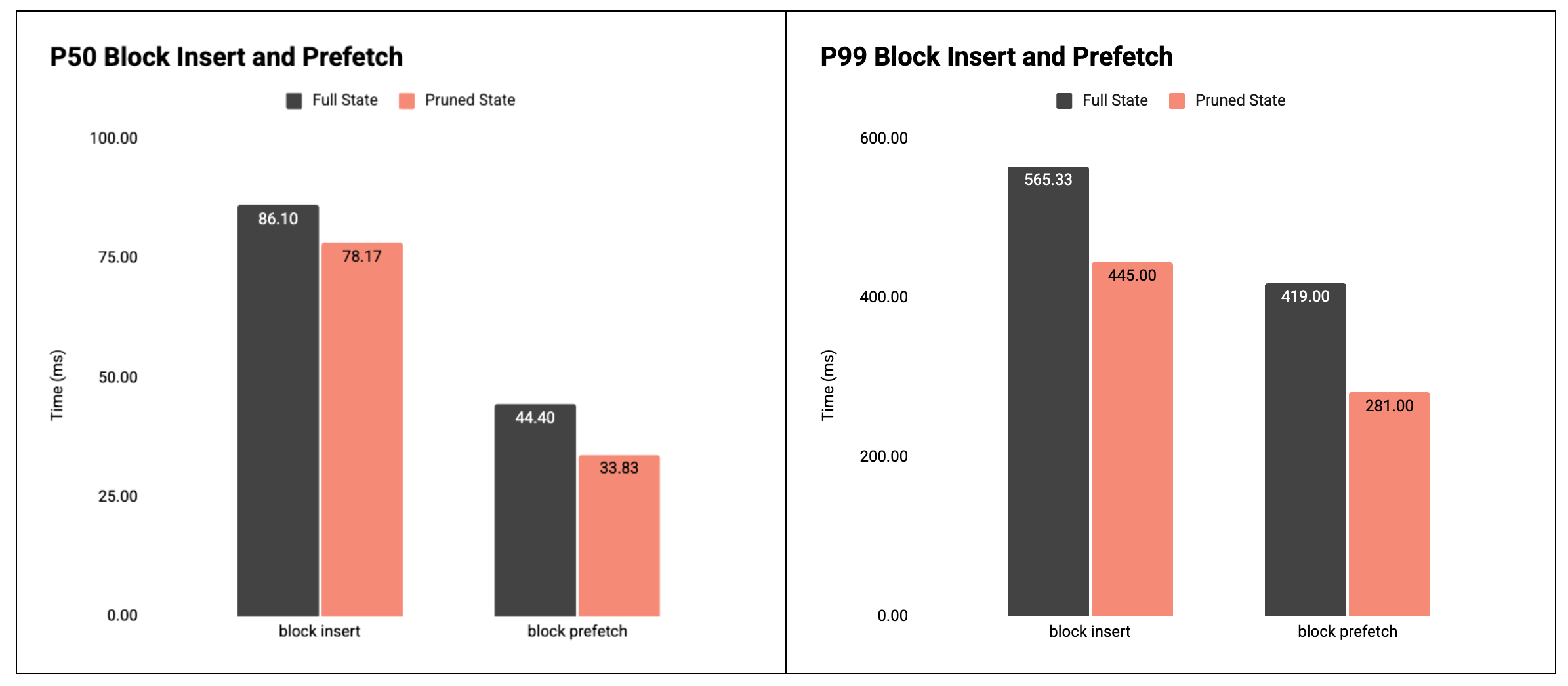
圖 3:塊插入和塊預取的 P50 和 P99 時間。
結果:精簡後的數據庫在塊插入和預取方面速度更快,尤其是在 P99 時。
- 塊插入(執行路徑):
- P50:86.10毫秒 → 78.17毫秒( -9% )
- P99:565.33毫秒 → 445.00毫秒( -21% )
- 塊預取:
- P50:44.40毫秒 → 33.83毫秒( -24% )
- P99:419.00毫秒 → 281.00毫秒( -33% )
geth 中的“prefetch”是什麼?
Geth 運行一個並行預取器,該預取器執行事務來了解需要哪些狀態,將這些對象拉入內存,然後丟棄更改。其目標是預熱緩存,以便實際執行(包括狀態根計算)更頻繁地訪問內存,從而減少磁盤 I/O。
在實際應用中,預取性能在 geth 中尤為重要。預取器會併發執行事務,並且頻繁地需要從底層數據庫解析狀態,這類似於我們預期從塊級訪問列表 (BAL) 中獲得的訪問模式。相比之下,在塊執行期間,大多數狀態訪問都會命中緩存,因此即使性能提升幅度很小,也難以察覺。
總體而言,預取功能的改進凸顯了從數據庫中移除非活動狀態的好處。
4. 狀態讀取和更新
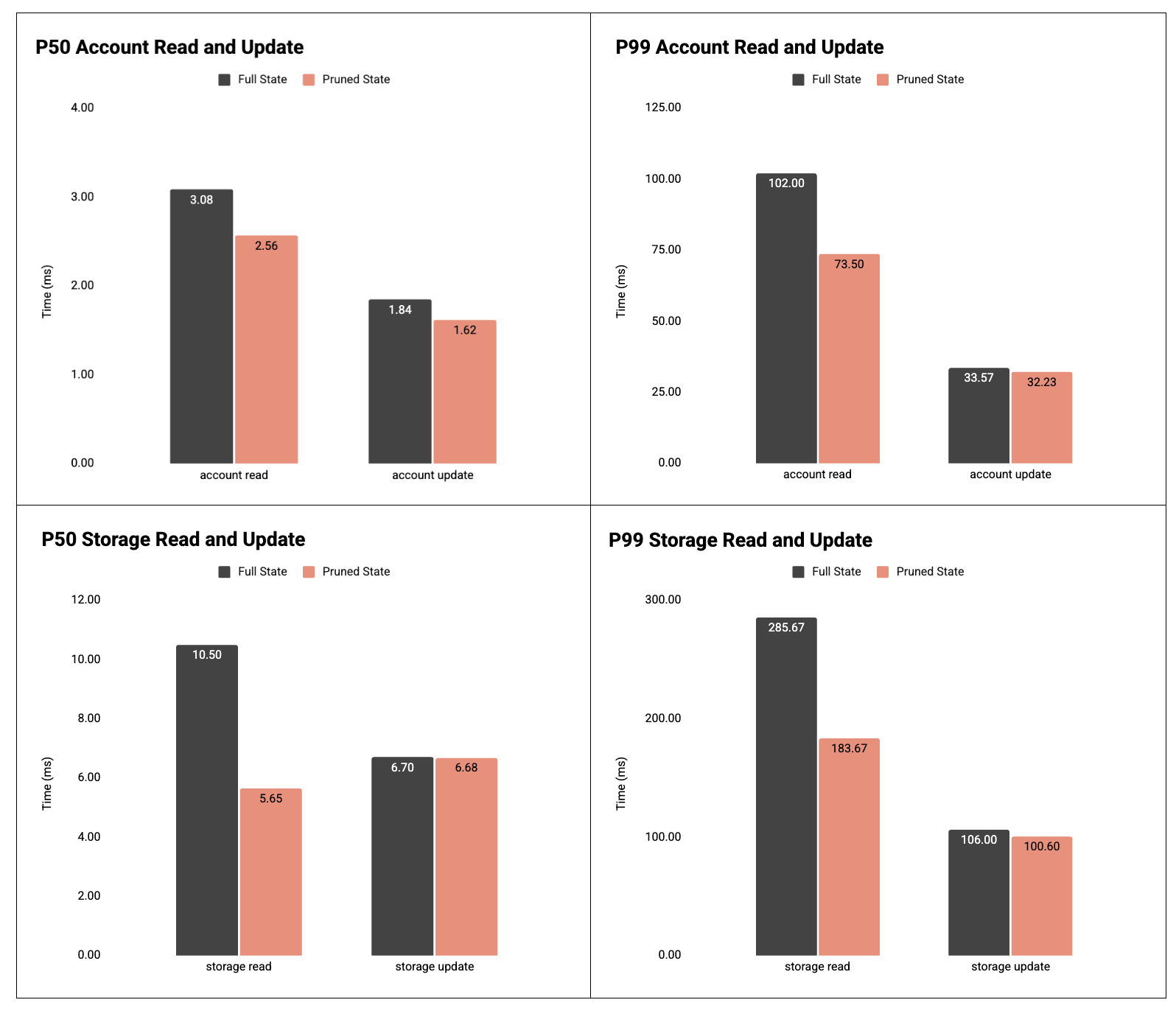
圖 4:P50 和 P99 讀取/更新帳戶和存儲槽的時間。
結果:賬戶和存儲讀取性能顯著提升。
- 賬戶已讀:
- P50:3.08毫秒 → 2.56毫秒( -17% )
- P99:102.00毫秒 → 73.50毫秒( -28% )
- 賬戶更新:
- P50:1.84毫秒 → 1.62毫秒( -12% )
- P99: 33.57ms → 32.23ms ( -4% )
- 存儲讀取:
- P50:10.50毫秒 → 5.65毫秒( -46% )
- P99: 285.67ms → 183.67ms ( -36% )
- 存儲更新:
- P50:6.70毫秒 → 6.68毫秒(基本持平)
- P99:106.00毫秒 → 100.60毫秒( -5% )
這與The Block插入/預取的結果一致。更新操作的改進有限,因為 geth 已經在交易執行期間預取了所需的 trie 節點,並在預取完成之前一直阻塞。因此,trie 更新完全在內存中執行,只是簡單地將狀態更改放入 trie 的相應位置。
主要發現和啟示
- 州規模大幅縮減
精簡後的狀態大小縮小了約 4.4 倍,從 359 GB 縮減到 81 GB。這種縮減顯著降低了節點運營商的存儲和 I/O 負擔,並將“合理的硬件要求”推向了更容易實現的方向。
此次資源縮減主要集中在存儲 trie 節點和存儲快照上,這表明以太坊的大部分狀態都存儲在冷合約中。如果大部分節省來自存儲,那麼狀態過期機制的一個潛在路徑是優先考慮合約過期存儲的解決方案。這條路徑不會影響賬戶,從而避免了一些顯而易見的用戶體驗風險(例如,賬戶意外需要恢復),同時又能獲得大部分過期收益。缺點是,我們可能會引導用戶將賬戶用作合約存儲,以避免過期,最終我們可能需要同時實現賬戶級和槽位級的過期機制。
- 減少狀態大小 = 加快執行速度。
縮小狀態規模主要通過降低從磁盤檢索狀態的成本來提升區塊處理效率。在主網區塊的同一年內,端到端執行時間縮短了約 15%。微觀指標也印證了這一點:最大的提升體現在讀取操作上,尤其是存儲讀取操作。
這與基於局部集模型(LSM)的數據庫的預期相符:較小的數據集往往能提高局部性。實際上,這在兩個方面都創造了提升空間。我們可以提高 gas 限制,並且如果狀態大小得到控制,我們還可以降低狀態操作的成本。
- 改善尾部延遲
除了平均速度提升之外,更重要的運營成果是尾部行為的改善。精簡後的數據庫大幅降低了區塊插入和預取的 P99 延遲,這意味著驗證過程中長時間的停頓次數減少。這些停頓通常是導致節點在突發性工作負載下間歇性落後於鏈首的原因。
這對州的發展意味著什麼?
我們的實驗表明,如果以太坊能夠安全地將本地存儲的狀態限制在最近訪問數據的滾動窗口中,客戶端將受益於:
- 降低硬件要求。
- 需要更大的空間來實現更高的吞吐量,因為目前狀態操作是一個主要瓶頸。
- 由於尾延遲降低,負載下的彈性更好。
然而,缺失的部分在於狀態過期機制的實際實現。無論是在協議內還是協議外,由於需要標記、刪除和恢復過期狀態,都會產生額外的延遲。我們使用主網工作負載進行的實驗顯示出了積極的結果,但對於任何具體的過期方案,都需要對這些權衡進行端到端的評估。
未來工作
- 衡量在最壞情況下,修剪非活動狀態如何有所幫助(或失敗)。
- 對其他EL客戶重複基準測試,並比較結果。
- 探索不同的到期規則(例如 6 個月到期期、僅修剪合約存儲、僅修剪帳戶),並查看基準測試結果有何不同。