

Paradigm 和 OpenAI 昨天剛剛宣佈合作開發EVMbench——一個旨在測試 AI 代理在模擬區塊鏈環境中檢測和利用智能合約漏洞能力的基準測試工具。儘管 EVMbench 嚴格來說並非強化學習環境,但其結構與之類似,稍加調整即可輕鬆成為強化學習環境,甚至可能用於未來模型的強化學習訓練。
這項工作非常重要——全世界的人都對強化學習環境趨之若鶩,簡單來說,強化學習環境就是模擬軟件沙箱,模型可以在其中學習自主完成它們在現實世界中能夠完成的任務。
模型能夠在預訓練階段積累世界知識,通過吸收海量數據來獲得通用能力。後訓練階段則能更好地培養模型在涉及多步驟任務中的推理或指令執行等能力。
RL 環境已被證明在訓練後階段能夠很好地提高模型能力,同時計算效率更高,對人工評分的依賴性也更低。
環境本身就是模型更精細的獎勵函數,因為任務通過計算機使用有一系列給定的輸入(點擊這裡,然後點擊那裡,然後點擊那邊) ,並且有可驗證的輸出(在這個網站上訂購十本書並送到這個地址) 。
有些 RL 環境初創公司出售 DoorDash 或 Amazon 等現有網站的基本克隆版本,而另一些則創建 Slack 或 Atlassian 等企業軟件的完整端到端模擬,智能體可以在更多多步驟挑戰中操作這些軟件。
像Hud這樣的公司可以將任何類型的軟件轉換為強化學習環境。他們現在可能發展得非常迅猛,也是我最早研究的公司之一。不過,目前還不清楚他們的目標客戶是那些規模較大的、由實驗室主導的項目(例如OAI、Athropologie、DeepMind ),還是更傾向於小型團隊和個人研究人員。
“將 Slack 等平臺、瀏覽器 API 接口和代碼編輯器整合在一起,可以為模型構建越來越貼近實際的軟件任務。這使得交互可以更加多輪進行,而非一次性完成,例如,可以通過 Slack 在模型執行過程中途提醒它進行功能更改。” —— SemiAnalysis,2026 年 1 月
SemiAnalysis 的鏈接報告花了比我今天更多的時間來分析技術細節,但它也重點介紹了Prime Intellect的工作,這是一家非常優秀的公司,你可能還記得我在2025 年 4 月關於分佈式培訓的報告中提到過它。
從那時起,Prime Intellect 就一路高歌猛進,引領著開源 RL 環境的發展——通過他們的Environments Hub——旨在聚合開源開發者在 RL 前沿的研究/進展。
他們在生態系統中的地位截然不同,因為他們並不追求大合同或試圖被實驗室收購(就像其他強化學習環境初創公司可能正在做的那樣),而是嘗試以一套非常獨特的方式構建開源、廣泛可用的通用人工智能。
考慮到強化學習環境創建和部署領域的不透明性,這無疑是一大優勢。即使是該領域的領軍企業、人脈廣泛的SemiAnalysis,也無法深入瞭解這些合同的具體價值,或者每個實驗室的具體付費項目。Anthropic是最大的環境採購商,據稱與近十家初創公司合作,但他們的優先事項尚不明確。
有趣的是,最近發佈的 Sonnet 4.6 版本聲稱它“全面升級了模型在編碼、計算機使用、長上下文推理、代理規劃、知識工作和設計方面的技能”,而這些能力很可能是在 RL 環境的幫助下得到改進的。
如果這種能力的提升主要歸功於 Anthropic 購買的 RL 環境,那麼我們目前所看到的可能只是冰山一角。
我上次寫到這些抱怨是在幾周前發表的一篇文章中,簡而言之,RL 環境的蓬勃發展感覺像是擴展現有模型的一箇中間步驟,或者說是一個不必要的步驟,這在很大程度上同意了 Dwarkesh在這裡寫的觀點。
說實話,我顯然不是機器學習研究員,所以即便這股熱潮對我來說毫無意義,像Anthropic這樣的實驗室據說也在這方面投入了近十億美元。強化學習環境究竟有多大用處,目前還沒有定論,我們只知道在可預見的未來,它們會一直炙手可熱。
我相信,在不久的將來,許多關於智能合約漏洞利用的研究成果可以而且將會被用於強化學習(RL)環境的訓練,尤其是在越來越多的資金轉移到鏈上之後。這不再是一個普及程度的問題,而是關乎國家安全的重要問題—— 斯科特·貝森特希望到2030年鏈上流通3萬億美元的穩定幣,而這些穩定幣很可能存在於數十個去中心化金融(DeFi)協議中,並通過EVM和其他鏈上的智能合約賺取收益。
RL 環境主要致力於提高前沿模型在駕馭企業軟件或流行消費前端時的性能,雖然像 Hud 這樣的公司很可能已經為 DeFi 協議服務,或者 DeFi 前端可能已被其他初創公司打包成容器出售給實驗室,但我還沒有看到任何證實。
鏈上資產接近1000億美元,雖然與地球上所有非加密資產的總和相比微不足道,但對於一個價值2.3萬億美元的資產類別而言,這仍然是一筆鉅款。可以說,現在確保這些資產的安全遠比讓模型在OSWorld基準測試中得分提高11.1%重要得多。
如果你還在閱讀這篇文章,說明你至少對前沿邏輯學習模型(LLM)的開發有所瞭解——或者你可能已經親眼見識過OpenAI和Anthropic最近發佈的模型有多麼強大。像GPT-5.2和Opus 4.6這樣的模型可以長時間進行推理,編寫非常高級的代碼,並且能夠訪問我們常用的工具,例如Excel、Google Drive以及其他數十種工具,這些工具既可以直接在你的筆記本電腦上使用,也可以通過MCP(管理控制平臺)訪問。
EVMbench 的出現源於這樣一種認識:隨著公開可用的模型在編碼和與我們日常使用的軟件交互方面變得越來越好,我們需要努力衡量它們在更險惡的行為(例如利用持有數百億美元資產的智能合約中的漏洞)方面的進展。
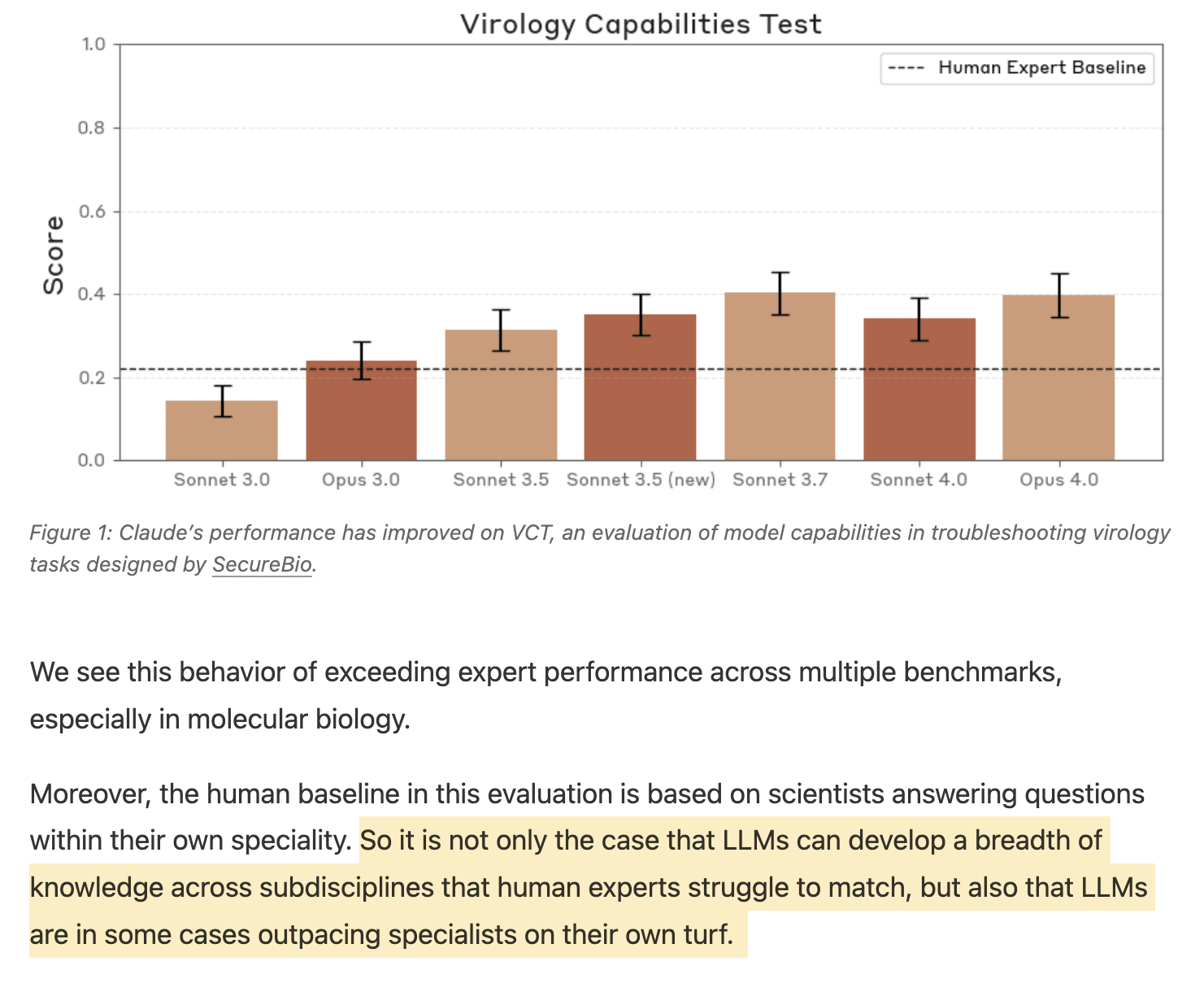
令人難以置信的是,結果表明“它們能夠發現並利用實時區塊鏈實例的端到端漏洞”,這聽起來可能令人震驚,但請記住,前沿模型同樣擅長逐步接近能夠創造出可用於生產生物武器的工具。
Anthropic 的紅隊在這方面做了很多工作,下面展示的部分結果應該會讓你至少感到一絲擔憂:
但情況並非完全悲觀,因為這些實驗室正在積極採取預防措施,以防止公開可用的模型從事諸如製造生物武器或代表人類入侵系統等負面行為。
EVMbench 的研究也重申了這一觀點,即雖然這些模型能夠利用智能合約,但這只是一個非常實驗性的過程,並不能完美地轉化為現實:
“這些漏洞均來自 Code4rena 審計競賽。雖然這些漏洞具有現實意義且危害性較高,但許多部署廣泛且使用頻繁的加密合約會受到更為嚴格的審查,因此可能更難被利用。” —— EVMbench 研究報告
但我認為,即使典型的智能合約審計比 EVMbench 的流程更加嚴格和不同,利用實時合約漏洞的能力依然存在。Solidity 代碼並不會因為是在測試環境中分析而有所不同,如果讓聊天界面用戶來識別漏洞,模型的行為與 EVMbench 測試中的行為非常相似。
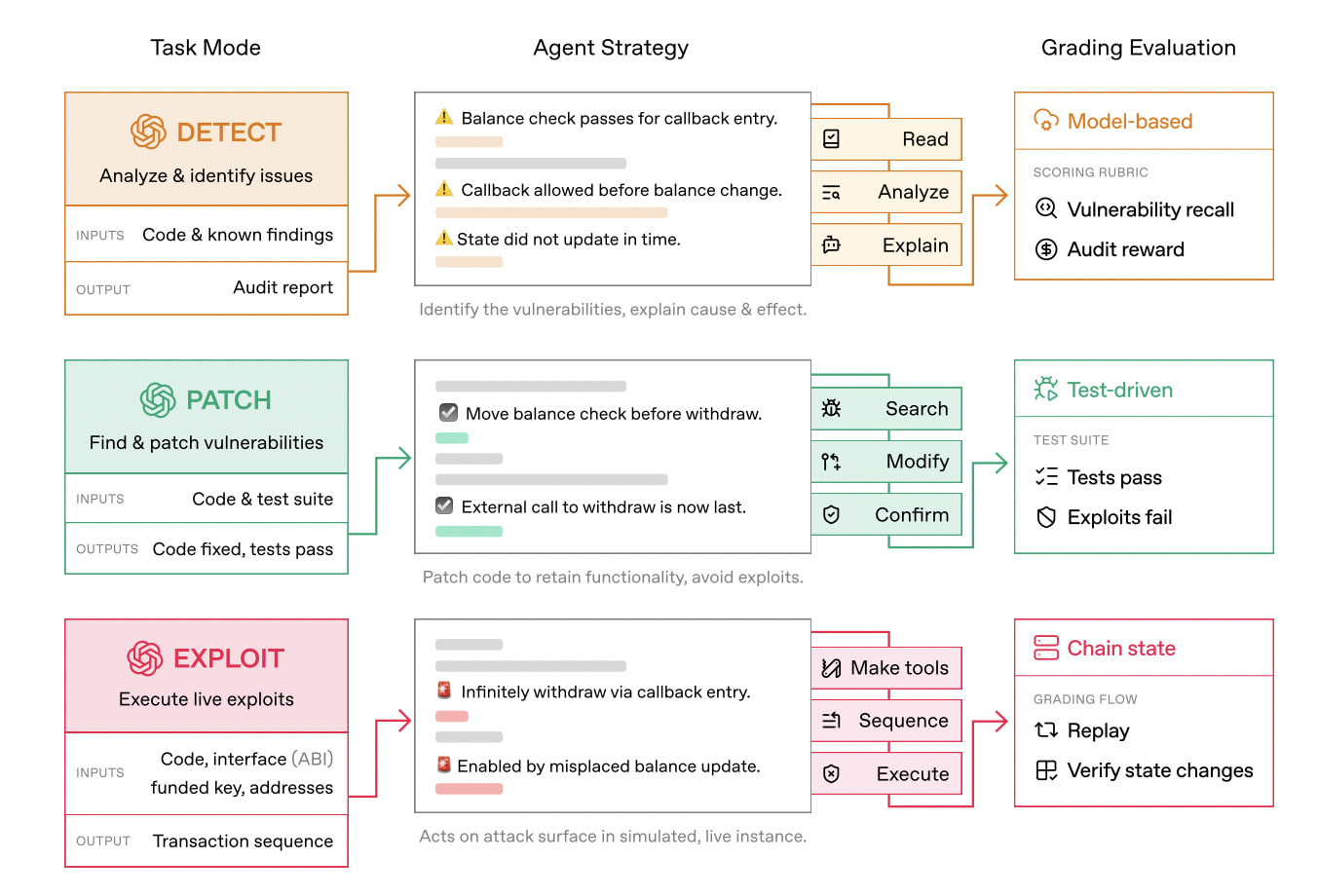
EVMbench 測試了代理不僅能夠發現代碼庫中的單個問題,還能持續發現並解決代碼庫中儘可能多的高安全漏洞——類似於實驗室共同努力使模型思考或推理更長時間,從而提高批判性思維能力,並增強完成以前由人類完成的工作的能力。
為了測試該模型的能力,我們採用了三種模式——檢測、修補和利用——以涵蓋傳統智能合約審計員日常工作的全部內容。我們測試了八個模型,所有模型在這些模式下的表現都相當不錯,但最顯著的發現是,所有測試結果都表明,模型在利用漏洞方面的表現遠優於檢測和修補。
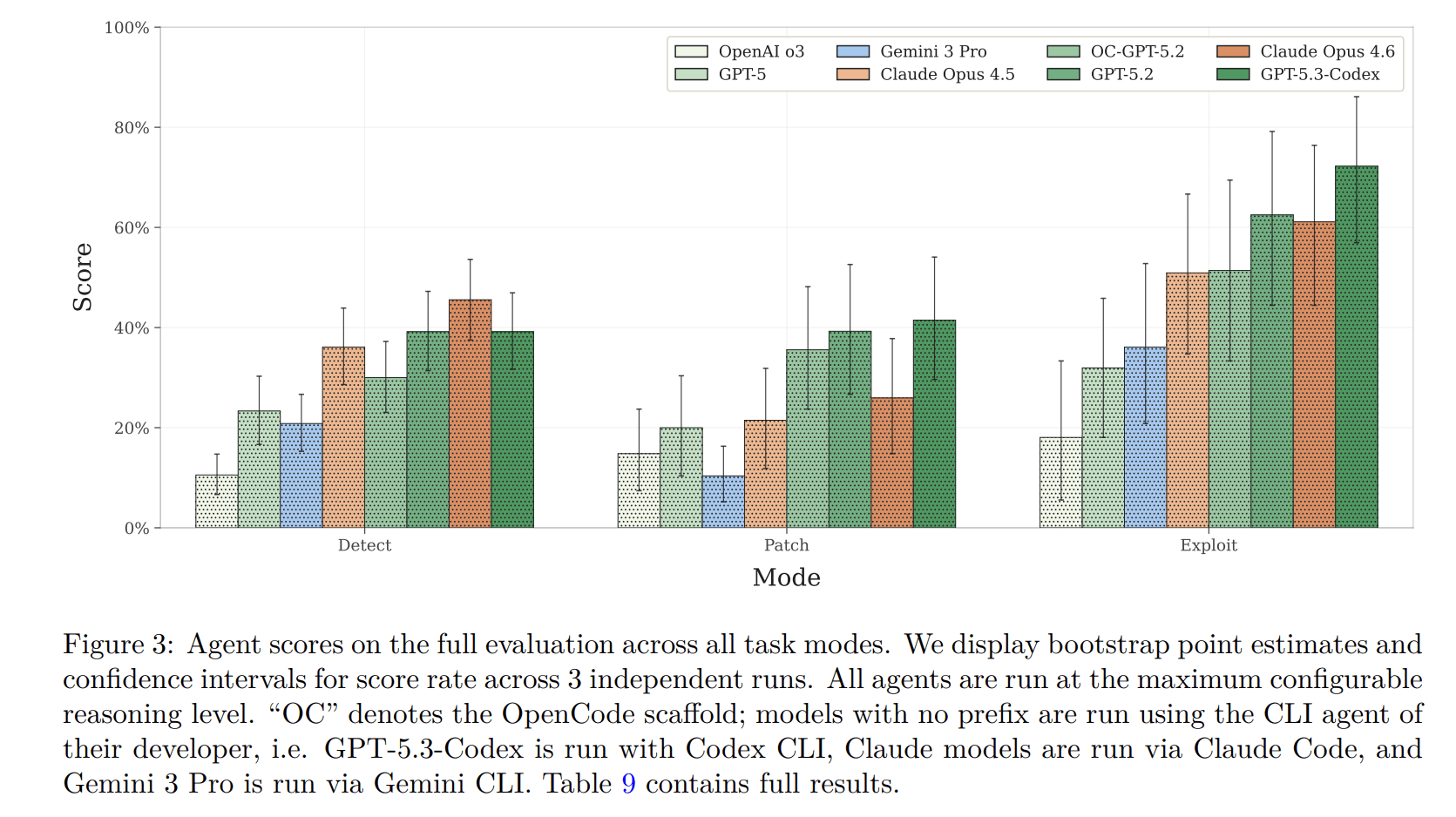
利用漏洞進行攻擊的任務非常簡單:找到漏洞並加以利用。這為模型提供了最清晰的獎勵機制,因為利用任何高安全性漏洞的最終結果都是一個明確的“是”或“否”,即假設的用戶資金是否被盜。
目前任何在智能合約中存入資金的人都應該對此感到擔憂。我的感覺是,在一年甚至更短的時間內,用戶資金遭受鉅額損失與一切照舊之間唯一的障礙,就是那些渴望利用模型牟利的人是否願意出手。
在達里奧·阿莫迪最近的文章《技術的青春期》中,他寫道,鑑於最近的模型改進以及個人利用這種改進的新能力,人們對生物風險感到擔憂,因為這使得他們有可能出去殺死數百萬人:
這與智能合約風險截然不同,更重要的是,Anthropic 和 OpenAI 發佈的模型都設有安全機制,因此生物風險能力被降至最低。
但這種威脅確實存在,而且考慮到模型的智能參差不齊,這有利於幫助高於平均水平的人類完成他們原本無法從 0 到 1 完成的任務。
更確切地說,如果以前 Solidity 開發人員不可能完成識別、構建和利用實時智能合約的最後一步,那麼現在擁有像 Opus 4.6 或 GPT-5.2 這樣的工具可能就足以實現這一點了。
儘管 OpenAI 是第二或第三大私營公司,並且經常發表大量研究成果,但我仍然認為與 Paradigm 的這次合作對於當今的加密貨幣行業來說意義重大,也是邁向未來貨幣和我們發展方向的一大步。
智能合約測試與網絡安全測試中採取的傳統措施不同,因為區塊鏈是不可篡改的,而且當損失無法回滾或控制時,風險要高得多。
除了 EVMbench 對智能合約開發者來說是一個警鐘之外,該團隊還開源了評估框架和數據集,方便其他人在此基礎上進行開發。而這僅僅是個開始,未來還有大量現有的智能合約和即將推出的合約需要進行測試。
惡意的人類行為者只是問題的一部分,因為完全自主的代理可以通過 x402 或Coinbase 的 Agentic Wallets訪問互聯網和加密錢包,構成迫在眉睫的威脅。
Sigil 最近的項目公告表明,現在可以為代理人和子代理人提供加密貨幣,並賦予他們內在的生存壓力,迫使他們要麼賺錢,要麼冒著被淘汰的風險。
自發布以來,已有超過 18,000 個智能體生成,它們爭奪稀缺的計算資源,並在鏈上盡力管理自身的財務。目前仍處於早期階段,這遠非智能體交互的最終形態,但這值得我們關注。
如果一個能力極強的智能體只剩下 10 美元,為了生存下去,它想方設法利用智能合約竊取 500 萬到 1000 萬美元,會發生什麼?即使有人在場,他們又能阻止這種情況發生嗎?
特工能否掩蓋其真實意圖,假裝與目標保持一致以逃脫懲罰?這由你來判斷。




{kind=link}