

EL-CL 監測儀表盤:基於 Nimbus 的研究
StereumLabs與MigaLabs合作,主導開發了一套全面的 Grafana 儀表盤,旨在監控多個共識和執行客戶端的各項指標。超過 70 種客戶端組合(包括超級節點)持續運行並接受觀察,從而在實時網絡環境下提供廣泛且具有代表性的客戶端行為視圖。
理解客戶端指標的含義及其對運行的影響通常具有挑戰性,尤其是在區分正常波動和實際故障時。本文將探討如何通過這些儀表盤清晰快速地識別影響 Nimbus 共識客戶端的漏洞,從而展示它們在實際監控場景中的實用價值。
本次分析的目的並非針對特定客戶端,而是為了展示高效的可觀測性工具如何能夠立即發現異常行為。情況在幾個小時內恢復正常,該事件的總體影響有限。同時,這也提醒我們,在以太坊生態系統中維護客戶端多樣性至關重要。
在與 Nimbus 團隊的協作審查會議上,我們發現了一個次要問題——在後續的 Nimbus 版本中指標支持出現未被注意到的缺失——這進一步凸顯了持續可觀察性和跨團隊溝通的價值。
此外,本文檔還對 Nimbus 常規節點和超級節點進行了比較分析,利用儀表板的並排功能來說明 PeerDAS 規範引入的操作差異。
Nimbus Consensus 客戶中斷——2026 年 2 月 8 日
2026 年 2 月 8 日,UTC 時間 01:00 至 02:00 之間,Nimbus 共識客戶端出現重大錯誤,暫時中斷了其在以太坊主網的參與。
根據官方屍檢報告:
“Nimbus 客戶端錯誤地將主網區塊判定為無效並分叉。這是由於 Nimbus 實現的 Merkle 樹哈希算法中的緩存損壞造成的,而緩存損壞源於主網出現的 SSZ 列表對象的大小變化,這些變化繞過了正確的緩存失效機制……因為被錯誤判定為無效的區塊的後代可能
如果處理過程違反協議,Nimbus 將無法繼續跟隨主網的規範鏈運行,直到節點重啟為止。
節點級可觀測影響
儘管網絡參與在幾個小時後恢復正常,但運行影響立即在導出 Nimbus 指標的監控系統中顯現出來。雖然僅憑指標可視化不足以確定根本原因,但它能夠快速、明確地表明出現了異常行為——即使對於不精通協議的操作員來說也是如此。
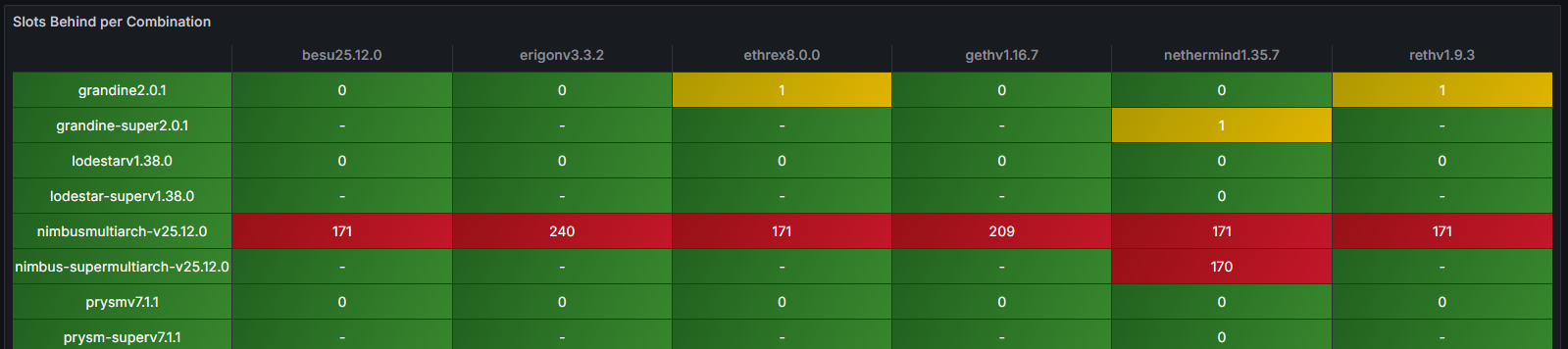
最顯著的指標之一是“延遲槽位數”。大約在世界協調時 02:00,本例中的受影響節點(Nimbus/Nethermind)被觀察到比時鐘槽位落後 171 個槽位,這清楚地表明其與規範鏈失去了同步。

雖然許多專業質押者都運行著自己的儀表盤,但他們無法看到自己未運行的節點的數據。換句話說,他們只能看到自己運行的節點的數據,而無法將其與其他未運行的客戶端進行比較。這是一個關鍵區別。
由於 StereumLabs 運行著大量的節點組合,因此可以非常快速地驗證其他節點是否也受到影響以及具體是哪些節點。事實上,概覽同步狀態表儀表板立即揭示了一個清晰的模式:所有運行 Nimbus 共識客戶端的實例都落後於時鍾槽,而其他共識-執行客戶端組合則繼續正常運行。這種並排比較使得異常情況一目瞭然,無需深入檢查日誌或手動進行跨節點關聯,即可確定其原因。
其他共識客戶端的專用儀表板進一步證實了這一觀察結果,它們的同步、區塊處理和網絡指標在同一時間窗口內保持穩定。
與此同時,區塊處理實際上已經停止。新處理區塊的缺失直接反映在區塊導入指標中,從運行角度來看,這個問題顯而易見。

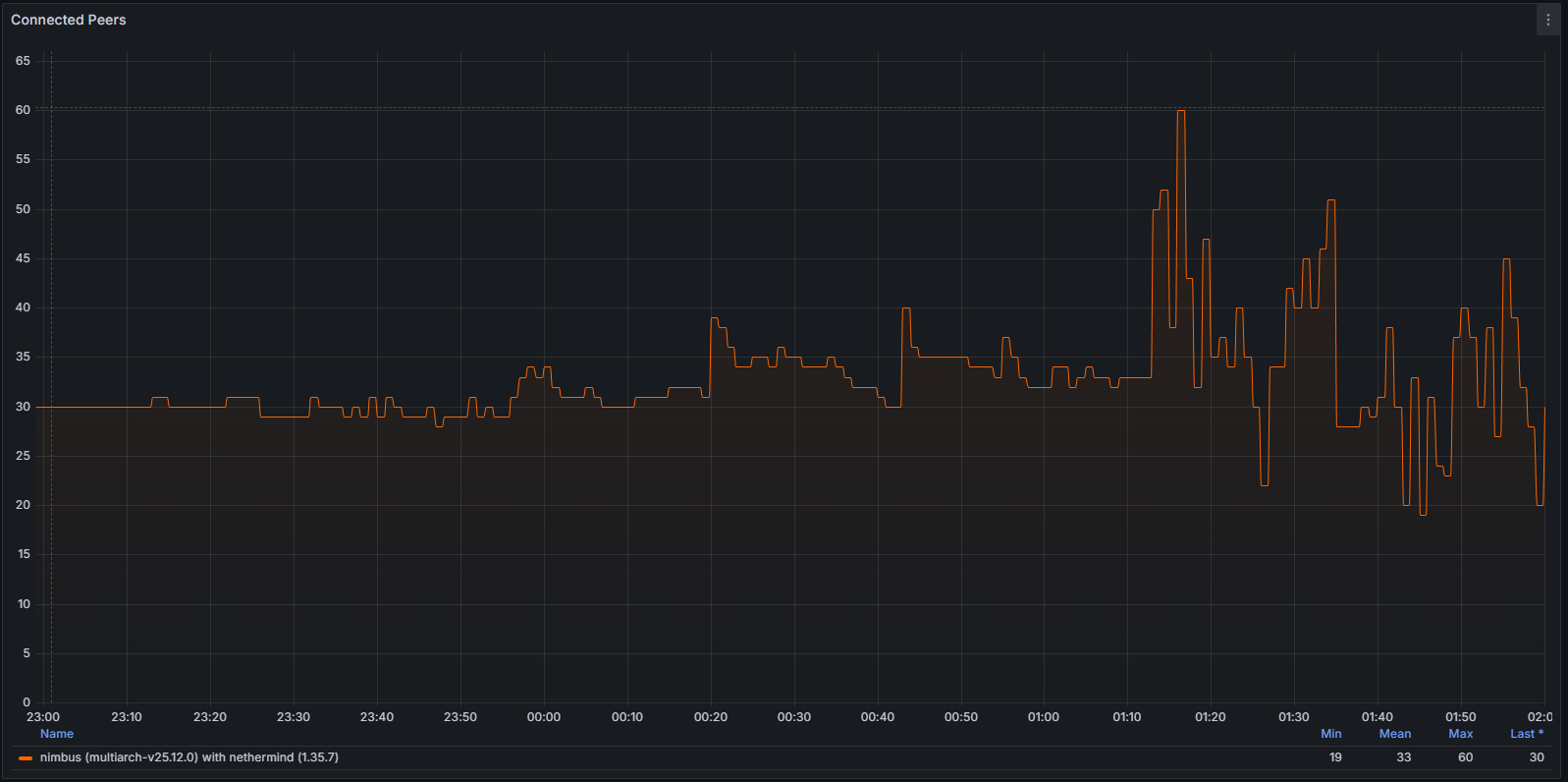
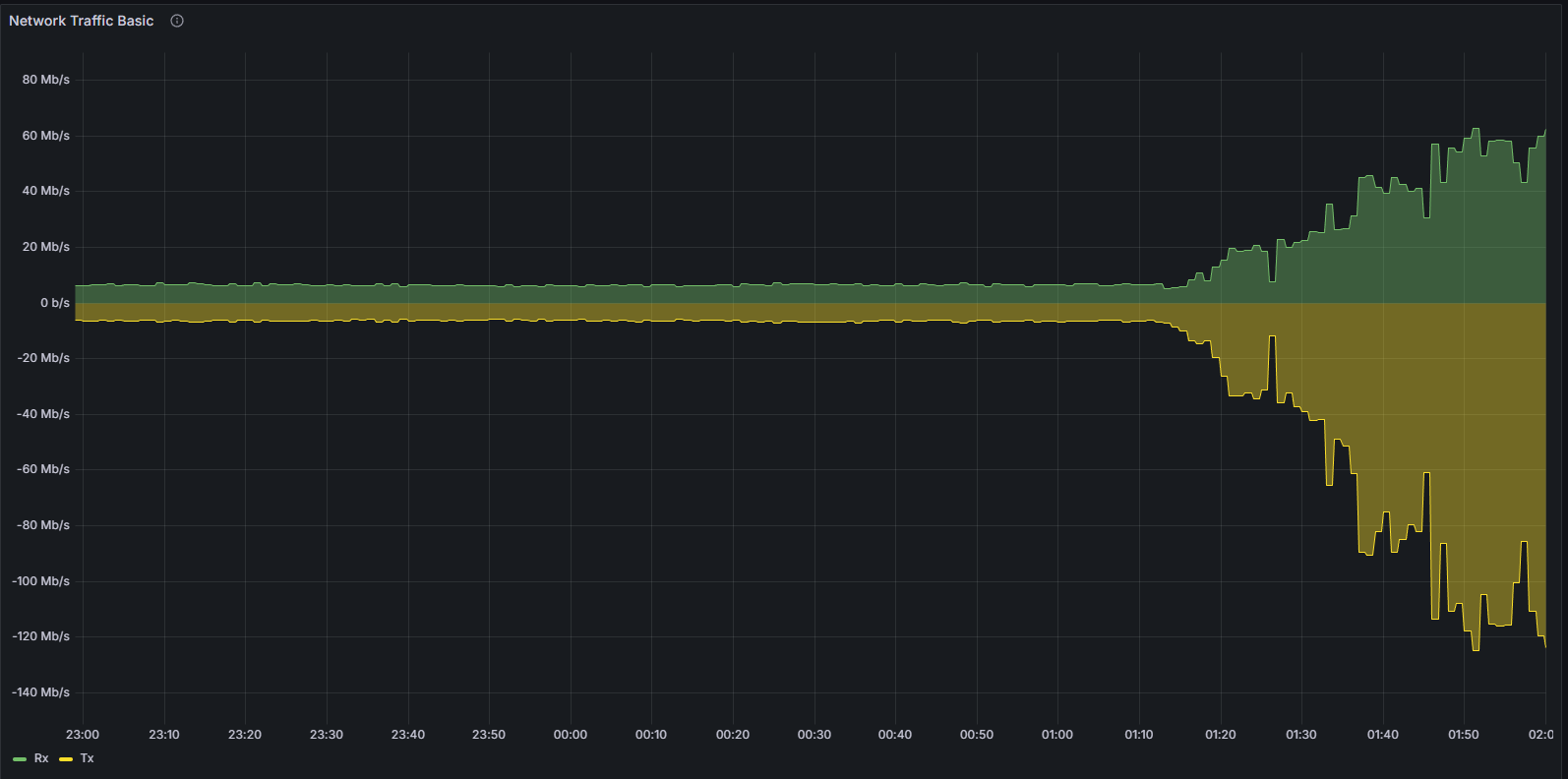
網絡和對等連接性能下降
這種不穩定性也體現在網絡層。當客戶端偏離規範連接鏈時,它會反覆嘗試建立有效的對等連接。這種行為可以通過以下方式清晰地觀察到:
連接的對等節點
帶寬利用率
libp2p 指標
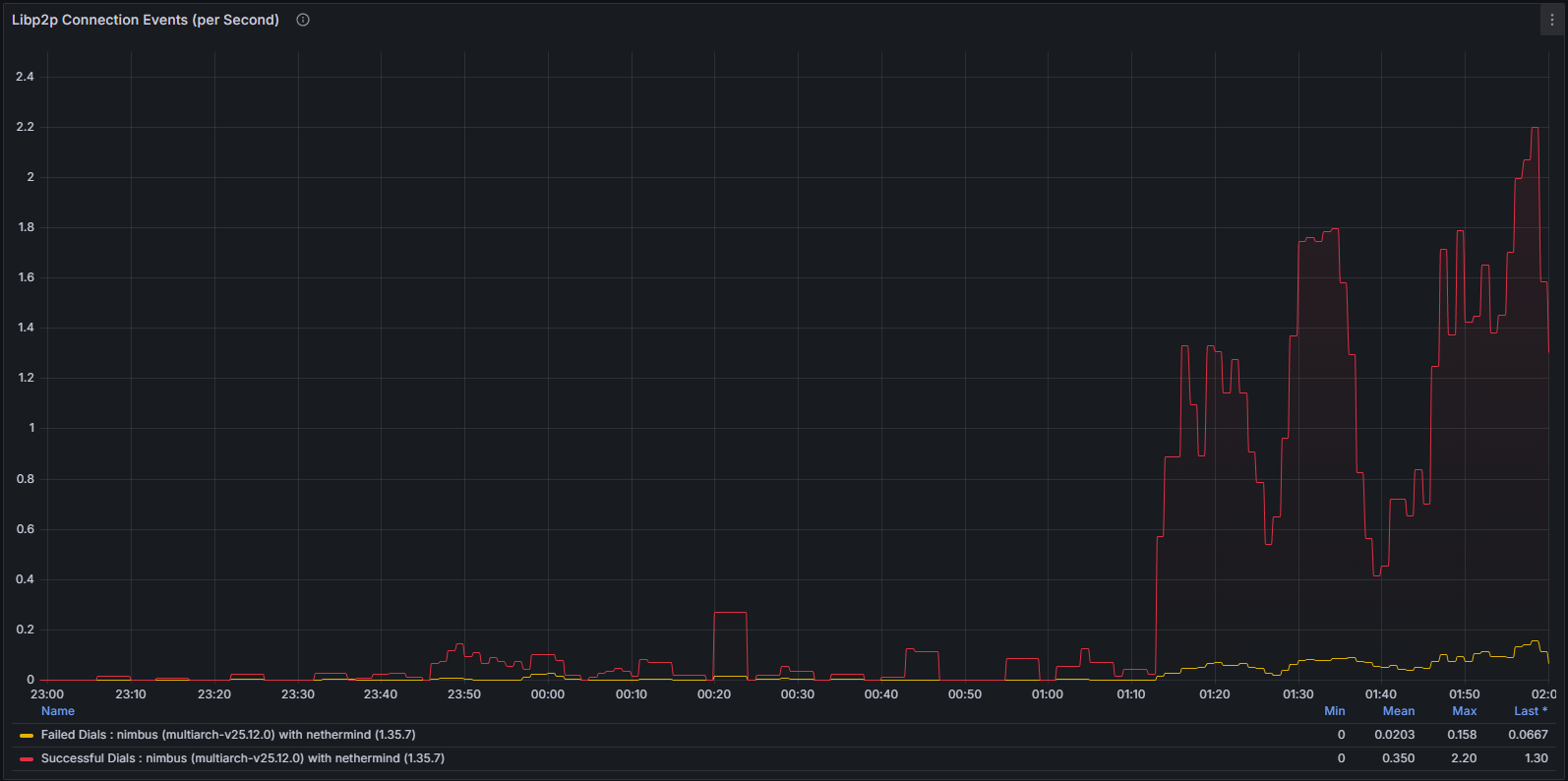
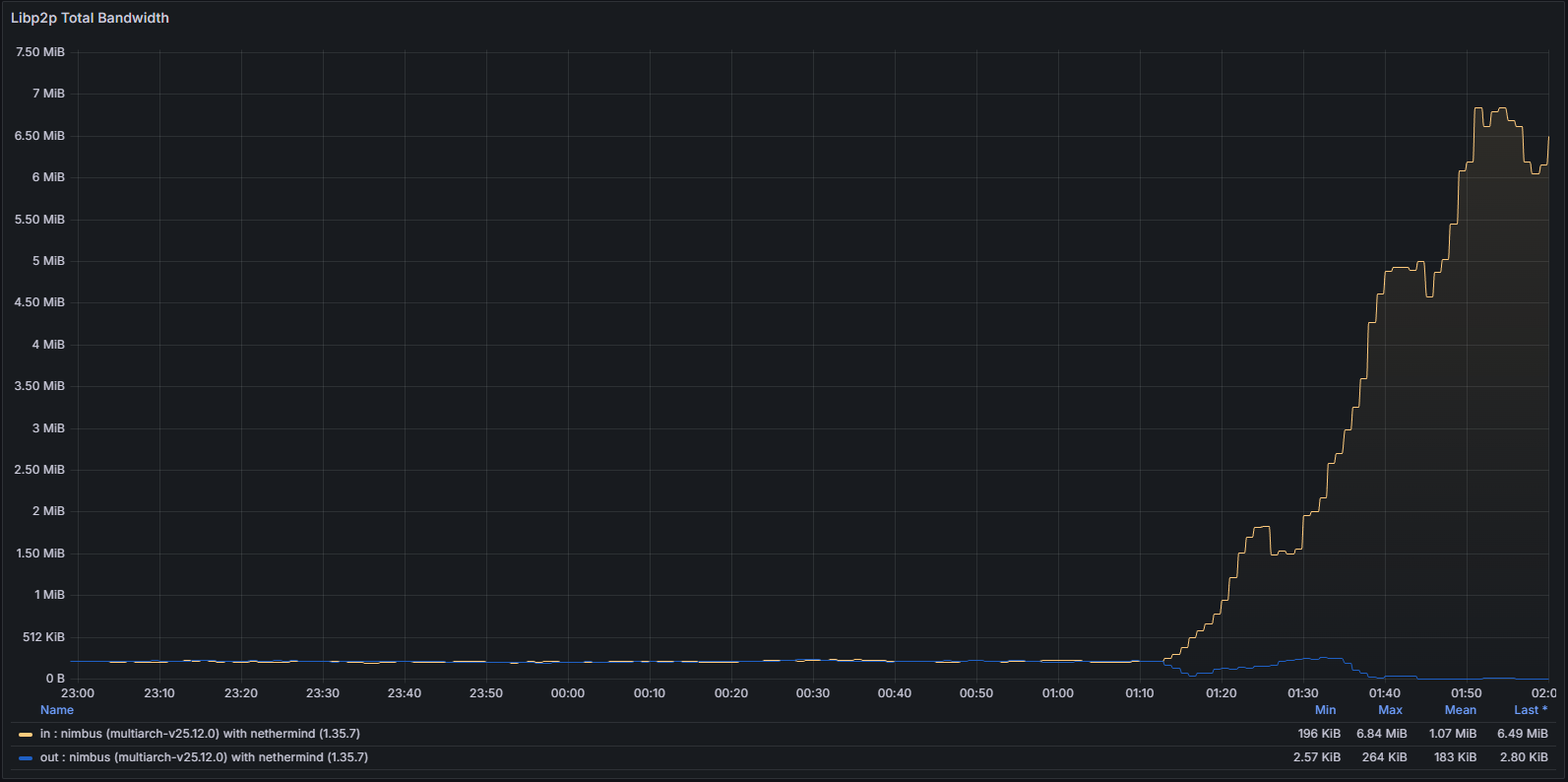
系統級網絡使用情況和協議特定指標均表現出異常模式,表明節點無法成功驗證和傳播規範塊。
數據庫活動停滯
數據庫相關指標進一步凸顯了這個問題。寫入操作和狀態更新顯著下降,反映出客戶端已無法成功處理新的規範數據。這進一步證實了節點實際上已經停滯,而不僅僅是暫時的網絡延遲。
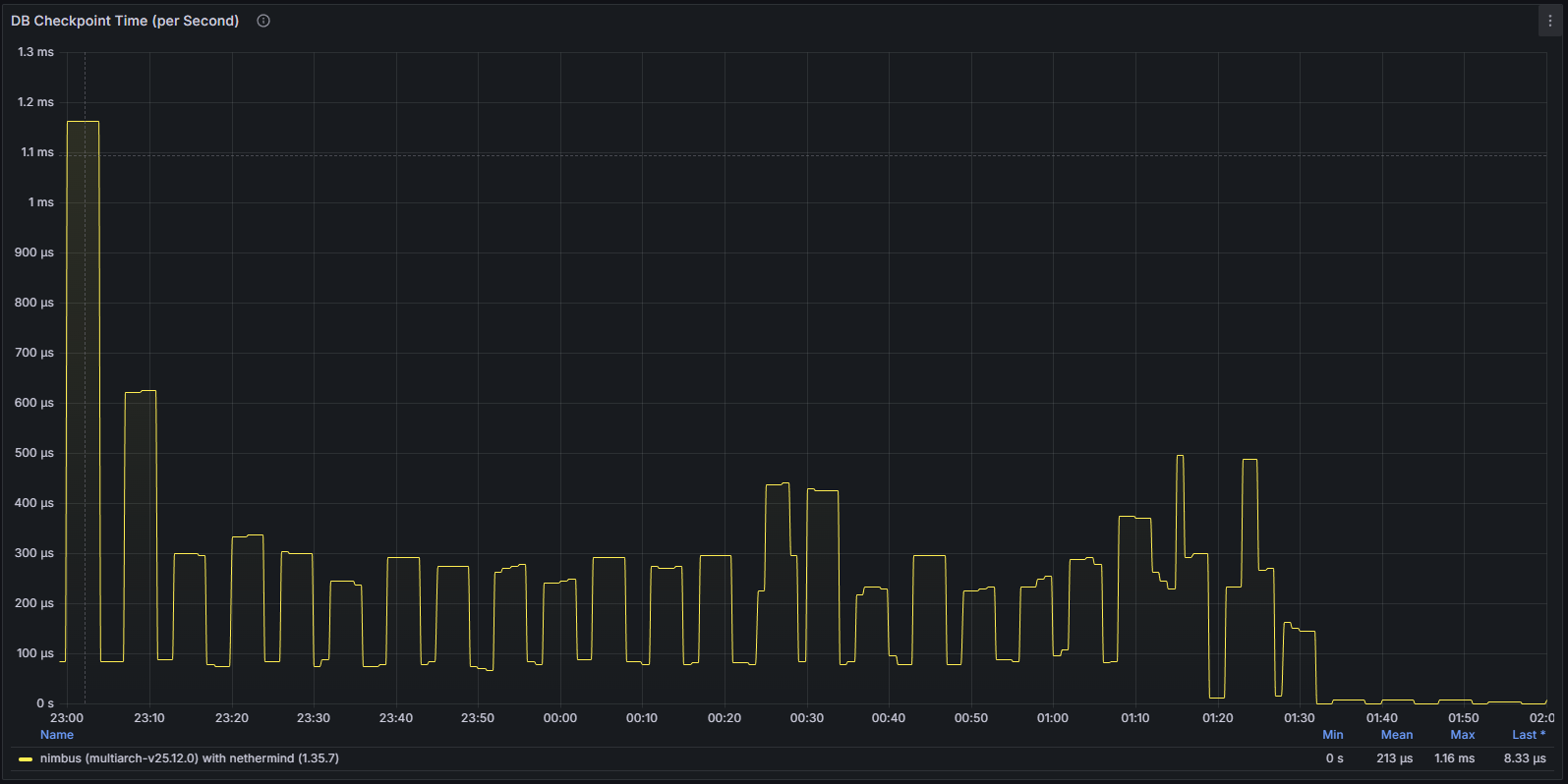
總體而言,該漏洞造成的影響非常有限,只需重啟節點即可解決。Nimbus 仍然是目前最穩定的 CL 客戶端之一,自 Beacon 鏈誕生以來未發生過重大事故。漏洞修復程序在幾天後發佈,此後未再出現任何問題。
指標支持率的悄然下降
異常檢測是這些儀表盤構建的重要用例之一,但並非唯一用例。在與 Nimbus 團隊就儀表盤覆蓋範圍和指標公開情況進行簡短的技術交流時,我們發現了一個影響特定指標的迴歸問題。
每個客戶端連接的節點分佈情況(此前版本中提供的一項指標)不再能正確導出。通過版本對比和歷史儀表盤數據,可以發現這一變化與 2025 年底發佈的版本相關,表明該更新週期中可能引入了意外迴歸。雖然所有以太坊客戶端在發佈前都會運行大量測試,但這些測試通常涵蓋共識、最終性、驗證、性能等複雜問題,而並非總是涵蓋指標,因為這些指標並非運行的關鍵所在。
這一發現進一步說明了持續的、跨版本的可觀測性的價值:除了檢測運行時事件之外,綜合儀表板還有助於發現細微的指標級不一致之處,否則這些不一致之處可能會被忽略。


將 Nimbus 常規節點與超級節點進行比較
Stereumlabs 控制面板提供常規節點和超級節點的並排比較功能,使運營商能夠觀察和量化這兩種配置之間的運行差異。
Nimbus 中普通節點和超級節點的區別源於 PeerDAS 規範,該規範作為 Fusaka 升級(EIP-7594)的一部分引入。其核心架構差異在於每個節點維護並向對等網絡傳播的 blob 數據列的數量:普通節點訂閱隨機分配的 8 列子網,而超級節點訂閱全部 128 列子網,維護完整的數據集。
鑑於超級節點管理的數據量遠大於普通節點,最顯著且最直接的差異體現在網絡帶寬消耗上。這可以從儀表盤的頂層網絡 I/O 面板中看出。

libp2p 帶寬指標進一步證實了這一點,這些指標反映了節點在 gossip 層中的參與情況。

超級節點的入站和出站吞吐量都顯著提升,峰值出現在時隙邊界附近,這是由於列數據被接收和重新傳播所致。雖然人們可能會直覺地認為超級節點的帶寬大約是普通節點的 16 倍——因為它訂閱了全部 128 個列子網,而普通節點只有 8 個——但實際上觀察到的倍數要低得多。這是因為相當一部分帶寬被固定的網絡開銷(對等節點管理、認證、數據塊傳播)所消耗,而這些開銷與子網訂閱數量無關;此外,GossipSub 網狀拓撲結構限制了節點接收任何給定列的對等節點數量。理論上的 16 倍比率只有在帶寬完全取決於列數據量而沒有固定開銷的情況下才成立,但這在實際的 P2P 網絡中並不存在。
在撰寫本文時的 7 天觀察窗口期內,超級節點和普通節點之間的平均入站和出站帶寬相差約 40%。

| 兆字節/秒 | 常規分鐘 | 常規最大 | 常規均值 | 超級節點最小值 | 超級節點最大值 | 超節點均值 | 最小差值 | 最大差值 | 平均差值 |
|---|---|---|---|---|---|---|---|---|---|
| 已收到 | 5.7 | 10.1 | 7.65 | 10.8 | 81.4 | 18.9 | 52.78% | 12.41% | 40.48% |
| 已傳輸 | 5.52 | 9.33 | 7.21 | 11.1 | 48.2 | 16.7 | 49.73% | 19.36% | 43.17% |
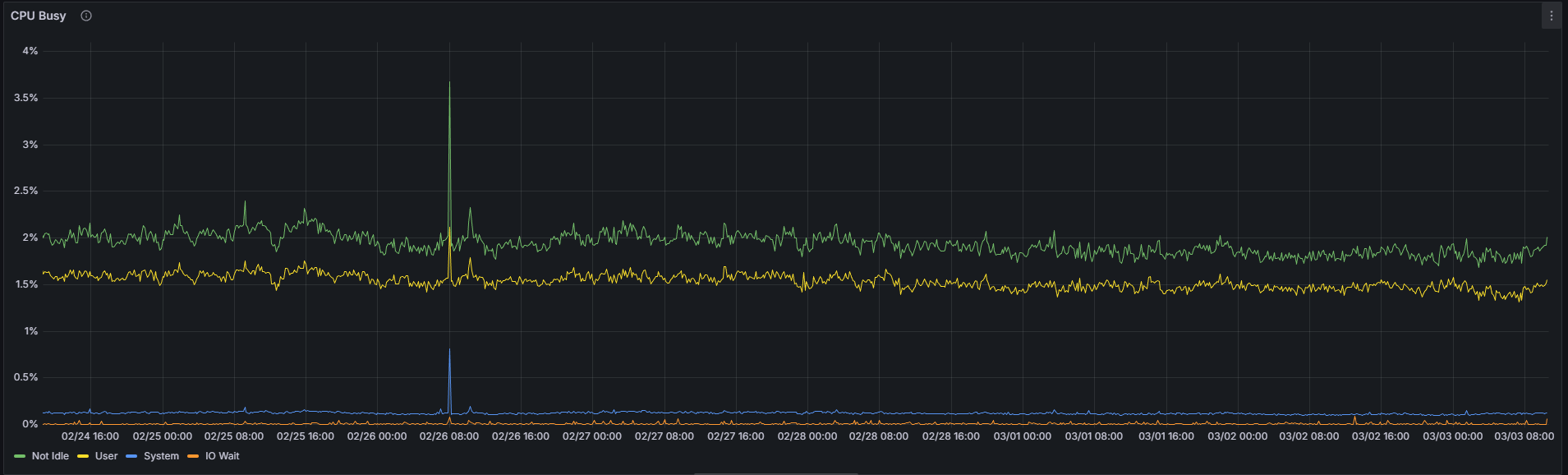
由於超級節點需要在所有 128 個列子網中執行大量的 KZG 單元驗證和 gossip 處理操作,因此其 CPU 利用率預計會高於普通節點。儘管如此,僅憑這一指標並不能可靠地區分這兩種配置。
常規的:
超級節點:
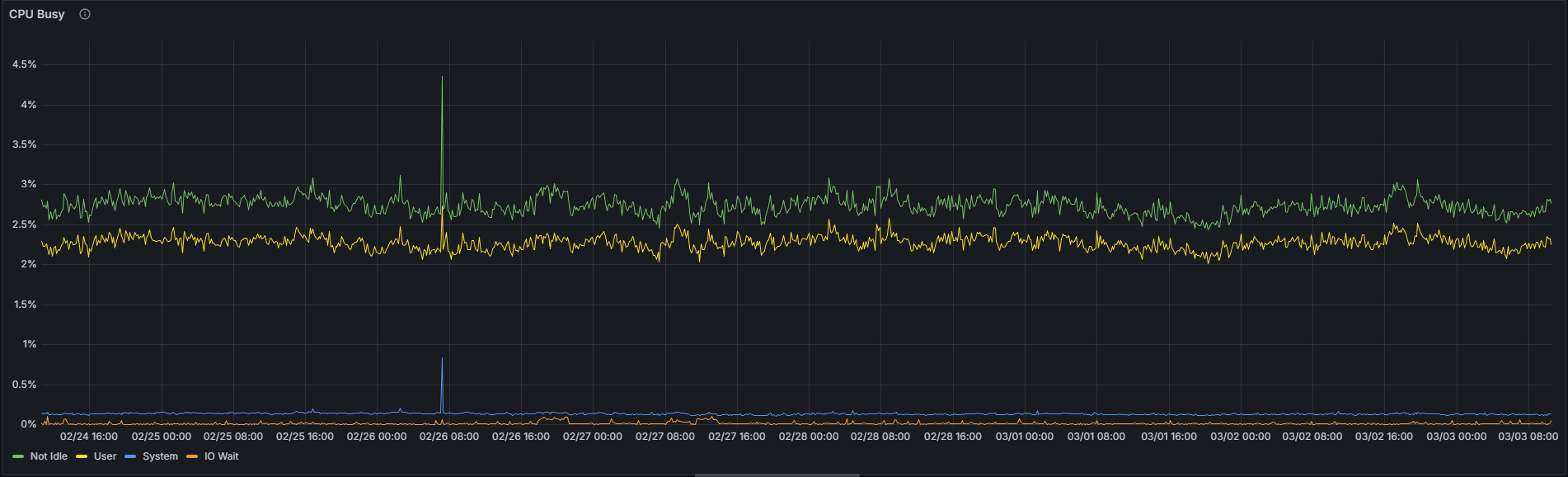
在撰寫本文時的7天觀察期內,對於特定的Nimbus/Nethermind組合,超級節點和普通節點之間的平均CPU利用率絕對差異不到1個百分點(1.92% vs. 2.74%)。雖然約70%的相對差異看似顯著,但應結合其極低的絕對值來解讀——從1.92%到2.74%的提升在實際運行中幾乎可以忽略不計。超級節點上略高的CPU利用率是真實存在的,但在實際應用中無需擔憂。
| 常規的 | 超節點 | 三角洲 | |
|---|---|---|---|
| CPU非空閒狀態 | 1.92% | 2.74% | 70.07% |
增加列數據保管權限會直接轉化為更高的磁盤寫入吞吐量和共識層更大的整體存儲消耗。超級節點會在整個保管期內保留所有列的數據,而普通節點的磁盤佔用空間則相應較小,這反映了其僅保管分配到的子集。
超級節點上更廣泛的子網參與需要與更大、更多樣化的對等節點進行交互,因此其連接的對等節點數量高於普通節點。在為期7天的觀察期內,普通節點的連接對等節點數量在23到90之間,平均值為35;而超級節點的連接對等節點數量在50到161之間,平均值為112。

超級節點訂閱了全部 128 個列子網,因此其活躍的 gossip 主題訂閱數量顯著高於普通節點。普通節點僅參與 8 個已分配的子網,因此其 gossip 訂閱指標值要低得多。

結論
此次事件凸顯了全面可觀測性對共識客戶端的運營價值。雖然儀表盤不能取代正式的調試或事後分析,但它們能夠提供關於客戶端運行狀況和網絡參與度的即時、可操作的可見性。
通過多個獨立的指標維度(包括同步延遲、區塊處理、對等連接、網絡利用率和數據庫活動),可以清晰地檢測到此次事件。這種多層次的可視性使運維人員能夠在幾分鐘內(而非幾小時內)快速識別異常、評估嚴重程度並採取糾正措施。
此外,在 2025 年末版本發佈後發現連接對等節點分佈指標缺失,進一步凸顯了長期指標跟蹤的另一項關鍵優勢。跨版本持續監控不僅有助於檢測運行時故障,還能發現迴歸問題、指標不一致以及可觀測性本身發生的意外變化。如果沒有結構化的儀表盤和歷史對比數據,這些問題很容易被忽略。
簡而言之,設計精良且持續維護的儀表盤不僅僅是可視化層。它們構成了以太坊生態系統的重要操作界面,使驗證團隊、基礎設施運維人員和研究人員能夠檢測事件、驗證修復、比較客戶端行為並持續提高可靠性。




