雖然這並非嚴格意義上的加密貨幣相關內容,但它與我過去撰寫過的預測市場密切相關,而且我相信這裡的讀者也會對此感興趣。此外,一些讀者明確要求我寫一篇類似的文章,所以就有了這篇文章!
過去幾周,我一直在構建一個預測模型,用來預測 Dota 2(一款電子競技遊戲)比賽的勝負。我完全使用Vibe Code 和 Claude Code完成了這項工作(Yoshi 通過 OpenClaw 提供了一些幫助,但所有操作都可以直接通過 Claude Code 完成)。我沒有機器學習學位,也沒有數據科學背景。
雖然現在下結論還為時過早,但結果看起來非常令人鼓舞。我回測了這個模型,結果確實非常棒。說實話,好得有點不真實,所以請大家對此保持一定的懷疑態度:
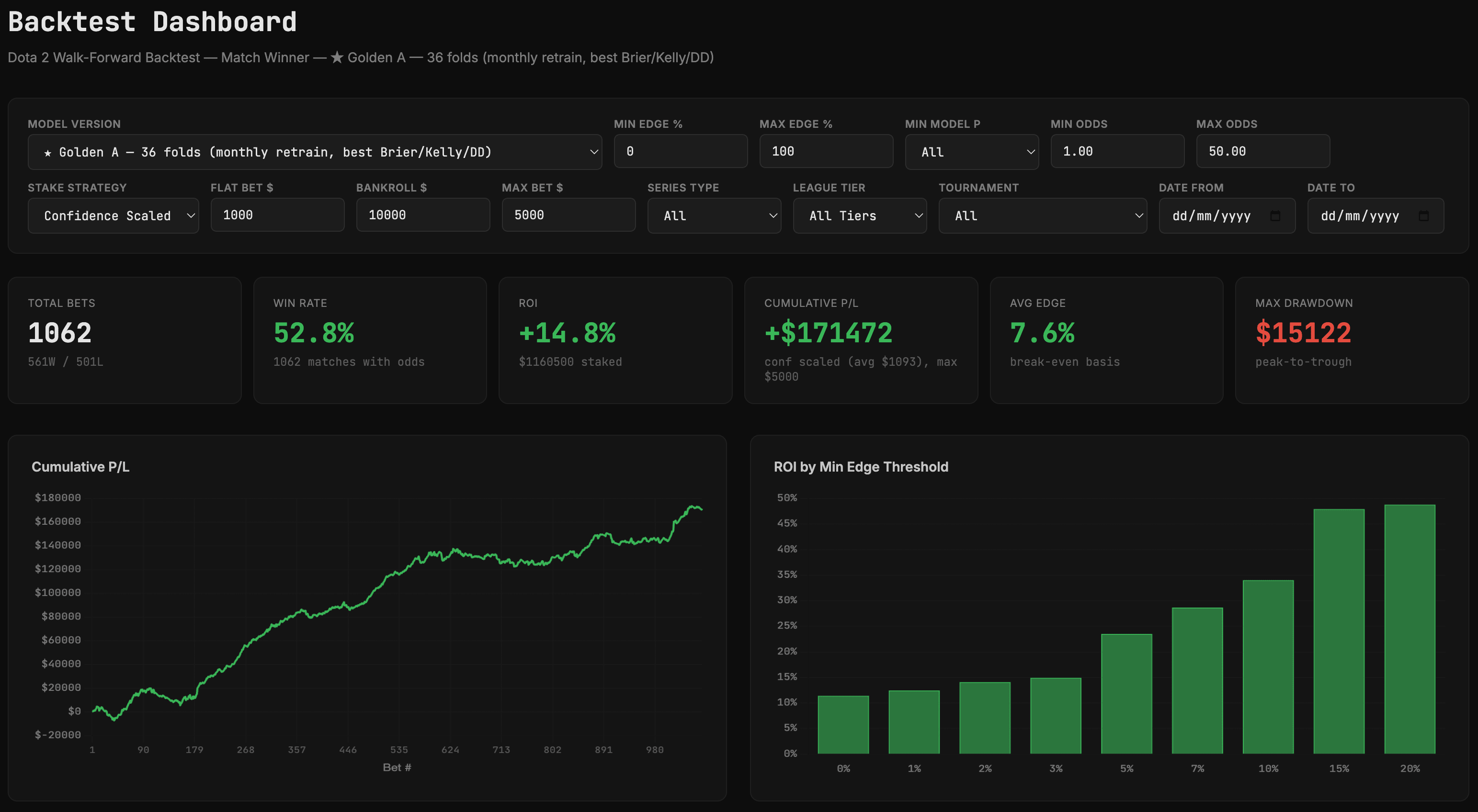
我已經追蹤實際結果幾周了,記錄了大約100筆實際投注,目前模型表現良好(投資回報率約7.5%),所以我對未來發展抱有希望。但我知道現在還處於早期階段。
我每天都在完善我的模型,已經堅持了將近兩個月,平均每天投入五個多小時。這其中有很多艱辛的工作,也伴隨著不少挫折。但我相信,任何人都能像我一樣,構建出一個(希望是)盈利的模型。
今天我將帶你瞭解預測模型的工作原理,我是如何創建我的模型的,以及如何利用 Vibe 編碼的力量創建你自己的模型。
我將詳細分析每個成功的預測模型都需要的核心組成部分,並就如何從實際角度構建和開發這些模型提出一些建議:
附註:我正在籌建一個新的教育社區,面向那些想要學習人工智能的人。我的兩位聯合創始人多年來一直在構建和教授人工智能,除此之外,我們還將每週舉辦 8 場直播視頻研討會。
我們目前還處於起步階段,但我們正在招募新會員。高級訂閱用戶可享受一項特別優惠,我會在本期簡報末尾分享,優惠幅度為最終價格的70% 。
1. 首先提出一個清晰明確的問題
人們一聽到“預測模型”就犯的最大錯誤是,他們開始思考算法、框架和盈利。不要這樣做。相反,你應該思考你試圖回答什麼問題。
誰贏了這場Dota 2比賽?這是個好問題。結果非此即彼,而且可以量化。你知道自己什麼時候猜對了,什麼時候猜錯了。
“本週加密貨幣市場會發生什麼?”這個問題問得不好。它太籠統了,沒有明確的成功或失敗標準。你甚至很難知道應該收集哪些數據。
如果你對這四個問題都有明確的答案,你應該能夠提出一個好問題,並使用預測模型來回答這個問題。
如果你想建立一個可以用來下注賺錢的模型,那麼我認為最好從你已經具備領域知識和專業技能的領域入手。
你可以向任何人工智能描述你感興趣的領域,並請它幫助你構建一個明確的問題。讓它引導你更具體地思考。告訴它你的領域以及你想做出的決策,它會幫助你找到你想回答的問題。
2. 讓人工智能全程協助你
獨自完成所有這些事情毫無榮耀可言。人工智能是世界上最強大的工具,要善用它,並且要充分利用它。
一旦你選定了想要解答的問題,就可以打開你選擇的編程平臺,開始向人工智能尋求幫助了。幾周前我寫過一篇關於 Claude Code 的文章,我的模型就是用它構建的。我建議使用 Claude Code 搭配 Opus 4.6,或者使用 Codex 搭配 GPT 5.4,因為它們是目前編程領域最前沿的兩款模型。
當然,你可以先用低端型號試試水,做些實驗(這也是個很好的學習方法),但如果你想賺錢,我真的覺得你應該選擇頂級型號。
在 Claude Code/Codex 中,創建一個新項目,然後根據你提出的問題,開始描述你的需求。例如:
我想構建一個 Dota 2 預測模型,用來預測哪支隊伍會贏得比賽。我需要你的幫助。首先,你需要深入研究構建預測模型的方方面面,特別是 Dota 2 和電競模型。查閱相關的研究論文,以及其他成功模型的案例,從中汲取經驗。把這些資料和案例分享給我。然後,根據這些信息,制定一個循序漸進的計劃,並告訴我我們需要哪些材料才能開始。
人工智能接下來肯定能制定出相當不錯的計劃,但我發現真正有幫助且非常重要的一點是,你自己也要閱讀相關資料和研究論文(至少讀幾篇)。我知道我們都在努力適應依賴人工智能的摘要和要點,但你真的需要對底層運作原理有所瞭解;這對你接下來的工作大有裨益。
希望這封信的其餘部分能為您提供一些背景信息,並幫助您理解這些事情。
3. 你需要可靠、乾淨的數據
你的模型通過數據學習。如果數據錯誤、不完整或不一致,模型就會學習到錯誤的信息。
我的 Dota 2 模型的大部分數據都來自官方 API。我始終建議大家儘量尋找優質的 API 來獲取數據,而不是從網絡上抓取數據。就 Dota 而言,我使用的 API 擁有長達數年的全面比賽數據,包括隊伍陣容、選手數據、比賽結果、版本更新信息等等。這些數據結構清晰、文檔齊全,並且定期更新。
遺憾的是(或許也算幸運,因為這可能帶來機會),並非每個領域都提供完善的 API。有時,你不得不抓取網站數據、解析 PDF 文件,或者處理雜亂的電子表格。
通常情況下,你還是需要兩者兼顧(我會抓取一些內容,儘管 95% 的內容來自 API)。
歸根結底,格式遠不如可靠性重要。你需要確信數據能夠準確反映實際發生的情況。API 更便捷,但並非實現這一目標的唯一途徑。
除了可靠的數據之外,乾淨的數據也至關重要。這意味著:沒有重複記錄、格式一致、關鍵字段沒有缺失值,並且每個字段的含義都有清晰的文檔說明。
人工智能如何提供幫助
讓它編寫數據質量檢查腳本。例如:“編寫一個腳本,加載我的比賽數據,檢查重複項,標記缺少球隊 ID 的比賽,並顯示每月比賽的分佈情況。” 你甚至可以更基礎一些,比如:“我想確保我們的數據乾淨可靠,我們該怎麼做?” 它會給出一些建議和方案,然後你可以根據這些建議進行操作。
4. 你的特點至關重要
構建預測模型時,理解特徵至關重要。簡而言之,特徵是模型用於進行預測的輸入。原始數據本身很少有用。你需要原始數據,因為它是創建特徵的基礎,但真正用於預測的是特徵。
對於 Dota 2 來說,像“A 隊已經打了 200 場比賽”這樣的原始數據幾乎無法告訴你下一場比賽誰會贏。但是“A 隊在當前版本最近 20 場比賽中贏了 65% 的比賽”這樣的數據卻能提供一些關於當前版本環境下隊伍近期狀態的有用信息。
這時,你的專業知識就派上用場了。你瞭解你的領域,知道哪些因素會影響結果。如果你是一位狂熱的高爾夫球迷,你就知道天氣會影響比賽結果,草種類型會影響比賽結果,球員早上開球還是下午開球會影響他們取得好成績的可能性,你也知道遠距離擊球手在某些球場上表現更好,等等。
你的模型一開始並不知道這些。它只知道你通過特徵告訴它的信息。
好的特徵能夠捕捉預測之前可獲得的信息,與結果相關,並且與其他特徵不冗餘。
人工智能如何提供幫助
先讓它推薦一些功能作為起點,這樣你就能瞭解可以使用的功能類型。然後描述你的領域專業知識以及你認為重要的因素,集思廣益,列出你認為可能影響結果的其他功能。
然後,讓它從你的原始數據中提取這些特徵。它會編寫轉換代碼。你評估這些特徵是否合理。這種來回交互正是“直覺式編碼”的優勢所在。你貢獻思考(至少一部分)和你的領域知識。剩下的所有工作都由人工智能完成。
5. 選擇合適的型號
你有了問題、數據和特徵。現在你需要一個工具,能夠利用這些特徵做出預測。這個工具就是模型。
把模型想象成一個函數。你給它輸入數據(你的特徵),它會給你一個輸出(預測結果)。不同類型的模型學習這個函數的方式各不相同。有些很簡單,有些則很複雜。正確的選擇取決於你的問題,但對於大多數結構化數據的預測任務來說,答案比你想象的要簡單。