

現在 AI 代理(Agent)開始接管越來越多的工作流,一個被很多人忽視的問題浮出水面:當 AI 擁有了操作電腦、訪問 API 甚至執行交易的能力時,我們該如何保證它不被惡意利用?
在 WEEX Labs 的實戰中,我們不僅關注 AI 的“智商”,更關注它的“免疫力”。基於對資產安全和信息安全的極致追求,我們總結了構建多智能體系統時必須遵守的三條安全鐵律。
鐵律一:物理與邏輯隔離——拒絕“裸奔”的 AI
很多開發者為了圖方便,直接在個人辦公電腦或私人服務器上跑 AI 代理腳本。在 WEEX Labs 看來,這無異於給黑客留下了一道後門。
• 獨立環境運行: 所有的 OpenClaw 實例必須部署在獨立、受控的雲端虛擬環境(VM)中。
• 拒絕私人設備: 嚴禁使用私人設備或主賬號開放權限給 AI。因為一旦 AI 代理調用的某個第三方 API 被劫持,黑客就可能通過 AI 所在的本地環境竊取你的私人數據或身份令牌(Token)。
• 原則: 把 AI 關進“數字沙箱”,讓它在受限的環境中發光發熱。

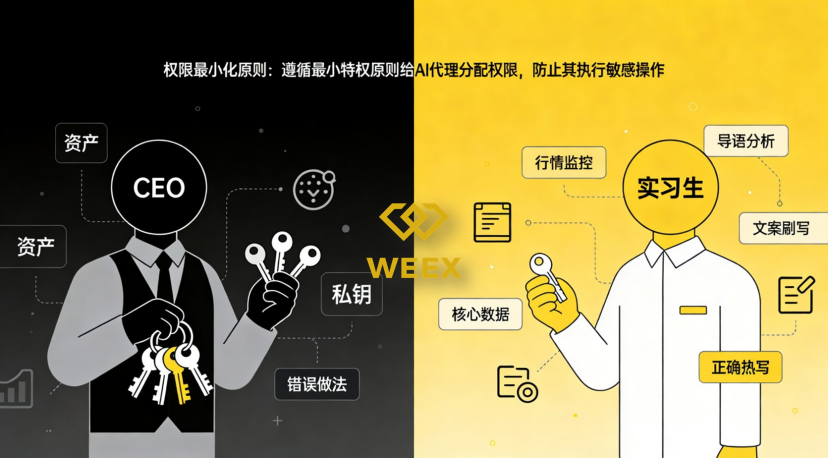
鐵律二:權限最小化原則——它是“實習生”,不是“CEO”
給 AI 代理分配權限時,必須遵循最小特權原則(Least Privilege)。
• 嚴禁接觸私鑰: 在 WEEX 的安全準則下,AI 代理可以進行行情監控、輿情分析、文案撰寫,但絕對禁止觸碰任何涉及核心資產、助記詞或私鑰的敏感操作。
• API 範圍控制: 如果 AI 需要調用 API,只開放 Read-Only(只讀)或受限的操作範圍。即使 AI 邏輯出現錯誤,其造成的潛在損失也將被鎖定在極小的範圍內。
• 原則: 永遠不要把“金庫鑰匙”交給一個還在學習進化的智能體。
鐵律三:設置“安全剎車”:用規則鎖死潛在的異常
AI 具有極強的邏輯自我修復能力,但也可能陷入詭異的“循環指令”。
• 監控與剎車: 正如我們在成本控制篇提到的,WEEX Labs設置了最大重試閾值(如失敗 3 次即停機)。這不僅是為了省錢,更是為了防止 AI 在遭受攻擊或出現漏洞時進行災難性的高頻誤操作。
• 預算預警提示詞: 我們在底層 Prompt 中植入安全防禦指令,要求 AI 在檢測到異常指令請求或越權嘗試時,立即向人工管理人員發出告警。
• 原則: 人類必須保留“一鍵關停”的終極權限。
在 Web3 與 AI 交匯的深水區,安全不是可選項,而是生存的前提。WEEX Labs 堅信,只有構建在堅固安全底座上的自動化,才是真正的生產力革命。我們將持續優化這套“Security-First”的 AI 協作架構,為用戶和行業探索出一條更穩健的創新之路。




