作者:willcl-ark, l0rinc, hodlinator
來源:https://bitcoinmagazine.com/print/the-core-issue-outrunning-entropy-why-bitcoin-cant-stand-still
初始化區塊下載
讓一個全新的節點同步到網絡的最新狀態,要經歷幾個不同的階段:
- 對等節點發現,和區塊鏈挑選:節點連接到隨機挑選的一些對等節點,然後確定擁有最多工作量證明的鏈。
- 區塊頭下載:節點從這些對等節點索取區塊頭,然後前後連接、形成完整的區塊頭鏈。
- 區塊下載:節點從多個對等節點處同時請求屬於這條鏈的區塊。
- 區塊和交易驗證:驗證完一個區塊的交易,才會驗證下一個區塊的交易。
雖然區塊驗證天然是講順序的 —— 每個區塊都依賴於前一個區塊所產生的狀態,但許多周邊工作是可以並行處理的。區塊頭同步、區塊下載和腳本驗證,全都可以在不同的線程中各自運行。一個理想初始化區塊下載流程要儘可能運用所有的子系統:網絡線程下載數據、驗證線程驗證簽名、數據庫線程寫入產生的狀態。
沒有持續的性能提升,未來也許配置較差的節點就無法再加入網絡了。
引言
比特幣的 “別信任,去驗證” 文化,要求這個賬本可以被任何人從頭重新建構出來。在處理完所有歷史交易之後,對於每個人的資金的狀態,應該每個用戶都能得到跟網絡上的其他人完全相同的結果。
這種可復現性,是比特幣的信任最小化設計的靈魂,但它也是以巨大的代價換來的:在比特幣區塊鏈誕生 17 年以後,這個日漸膨脹的數據庫,讓新加入網絡的人必須比前人消耗更多資源來執行使用它的準備工作。
要從頭啟動一個新節點,它必須下載、驗證和持久化保存從創世區塊到當前鏈頂端的每一個區塊 —— 這項消耗大量資源的同步過程,就叫 “IBD(初始化區塊下載)”。
雖然消費級硬件持續升級,讓初始化區塊下載保持低負擔依然對中心化至關重要:要確保每個人都能驗證比特幣區塊鏈,從低功耗的設備(比如樹莓派),到高功耗的服務器。
基準測試
性能優化的起點是理解軟件組件、數據模式、硬件和網絡條件,以及它們的互動如何產生出性能瓶頸。這需要大量的測試,其中絕大部分不會產生什麼成果。除了常規的要在速度、內存使用量和可維護性上取得平衡,Bitcoin Core 開發者們還必須選擇 低風險/高回報的變更。有效但微小的優化,常常會因為風險大於收益而被拒絕。
我們有一套重要的微小基準測試套件,以保證現有的功能不會出現性能下降。這對於捕捉迴歸效應(即單段代碼中的性能倒退)非常有用,但並不必然代表初始化區塊下載的整體性能。
提議優化措施的貢獻者們提供了不同環境中的可復現性和指標:操作系統、編譯器、存儲器類型(固體硬盤 vs. 機械硬盤)、網絡速度、數據庫緩存空間、節點配置(剪枝模式 vs. 歸檔模式處)、索引組合(index combinations)。我們編寫了單一用途的基準測試,並使用編譯瀏覽器來驗證哪種設置在哪個具體場景下會表現更好(例如,使用 哈希集合/有序集合/有序向量 來實現跨區塊的重合交易檢查)。
我們也會定期為初始化區塊下載運行基準測試。測試方法有:從本地區塊文件中重新索引區塊鏈狀態(chainstate)(還可同時要求重新索引區塊);或者,從一個內網的對等節點或從廣大的點對點網絡執行一次完整的初始化區塊下載(使用內網的對等節點可以避免網絡連接較慢的對等節點影響計時)。
初始化區塊下載的基準測試顯示出來的提升,常常比微型基準測試所顯示的更小,這是因為網絡帶寬或者硬盤讀寫常常是瓶頸所在;在全球平均網速下,光是下載整個區塊鏈就要花去大約 16 小時。
為了最大化可復現性,我們通常更喜歡重新索引鏈狀態的測試方法,它會展示處優化前和優化後的內存和 CPU 使用情況,並且驗證這些變更會如何影響其它功能。
歷史上的以及開發中的優化
早期的 Bitcoin Core 版本是為小得多的區塊而設計的。最早的由中本聰編寫的原型只是打下基礎,如果沒有來自 Bitcoin Core 開發者們的持續創新,它早就無法應對這個網絡的前所未有的規模了。
最初,區塊索引會存儲每一筆歷史交易以及它們是否已被花費,但在 2012 年,開發者 “Ultraprune”(PR #1677)創建了一個專門的數據庫,用於跟蹤未花費的交易輸出,這就形成了 “UTXO 集” 的概念;這個數據庫會預先緩存所有 可以花費 的鉛筆的最先狀態,從而為區塊驗證提供一個統一的視角。再加上從 Berkeley DB 到 LevelDB 的數據庫實現遷移,驗證速度得到巨大提升。######
不過,這一數據庫實現遷移也導致了 BIP50 1 鏈分叉:一個包含許多交易輸入的區塊,被升級後的節點接受,卻被未更新的節點拒絕(因為區塊過於複雜)。這凸顯了 Bitcoin Core 開發工作與常規的軟件工程的區別:即使是純粹的性能優化,也可能導致意料之外的鏈分裂。
在接下來的一年,(PR #2060)啟用了多線程的簽名驗證。幾乎同一時間,專用的密碼學庫 libsecp256k1 誕生,並在 2014 年集成到了 Bitcoin Core。在接下來的十年裡,經過持續的優化,它已經比通用的 OpenSSL 庫中的相同功能快上 8 倍。
“區塊頭優先同步”(Headers-first sync,PR #4468,2014)重構了初始化區塊下載流程:先下載累計了最多工作量的鏈的區塊頭,然後從多個對等節點處同時索取區塊。除了加速 IBD,它也讓節點不會在不歸屬於主鏈的孤兒區塊上浪費帶寬。
在 2016 年,PR #9049 移除了一個似乎是多餘的重合輸入檢查,帶來了一個允許通貨膨脹的共識 bug 。幸運的是,在被利用之前,它就被發現和打上補丁了。這個意外推動了大規模的測試資源投資。現在,有了差分模糊測試(中文譯本)、廣泛的代碼覆蓋和嚴格更的審核紀律,Bitcoin Core 發現和解決問題的速度都快得多了,而且自那以來再也沒有報告過同等嚴重的共識漏洞 2。
在 2017 年,-assumevalid啟動標籤(PR #9484)將普通的區塊有效性檢查與昂貴的簽名驗證分離開來,讓後者對於 IBD 的絕大部分變成可選項,從而讓 IBD 的時間減少了大約一半。區塊構造、工作量證明和花費規則,依然是完全驗證的:-assumevalid 模式只是完全跳過了簽名檢查(在抵達特定高度以前)。
在 2022 年,PR #25325 將Bitcoin Core 的普通內存分配器換成了一個定製化的、基於池子的分配器,而且專門為錢幣緩存做了優化。通過專門為比特幣的分配模式設計,它減少了內存浪費、提高了緩存效率,讓 IBD 的速度加快了大約 21%,同時,在相同的內存用量上塞進了更多錢幣。
雖然代碼自身不會變異,但它寄身的系統在不斷變化。每隔 10 分鐘,比特幣的狀態的改變一次 —— 使用模式一改變,瓶頸也就發生變化。維護和優化並不是可有可無;沒有持續的改進,比特幣積累漏洞的速度會快過靜態的代碼庫所能抵禦的速度,而初始化區塊下載的性能性能會迅速下降,哪怕硬件還在不斷進步。
UTXO 集的不斷膨脹的規模,還有區塊平均重量的增加,都放大了這些變化。曾經,軟件的任務只是 CPU 密集的(比如簽名驗證),現在常常是硬盤讀寫密集的,因為更多的鏈狀態訪問(必須在磁盤中檢查 UTXO 集)。這種變遷已經推動了新的優先級:優化內存緩存、減少 LevelDB 刷寫頻率,以及並行化磁盤讀取,從而讓新型的多核 CPU 保持忙碌。
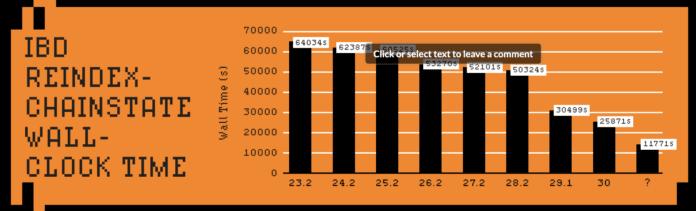
- 不同 Bitcoin Core 發行版的 IBD 時間一覽 -
近期優化
軟件設計的基礎是對使用模式的預測,而這種預測必然隨著網絡的演變而偏離實情。比特幣的確定性的工作負載,讓我們可以度量實際行為並時候糾正,確保性能跟得上網絡的增長。
我們持續地調整軟件的默認設置,以更好地適應真實世界的使用模式。舉幾個例子:
- PR #30039 提高了 LevelDB 的最大文件體積 —— 僅此一個參數改變,就讓 IBD 加速了接近 30%, 因為它更好地匹配了實際訪問鏈狀態數據庫(UTXO 集)的模式。
- PR #31645 倍增了刷寫批次的體積,減少了初始化區塊下載的最密集寫入階段的碎片化磁盤寫入,還加快了初始化區塊下載被打斷時候的進度保存。
- PR #32279 調整了內部預向量(prevector)的存儲體積(主要用於內存內的腳本的存儲)。舊的隔離見證前閾值,會偏向較老的腳本模板,犧牲較新的模板。通過調整它的容量以覆蓋新式的腳本體積,避免了零碎的分配,減少了內存碎片化,腳本執行也受益於更好的緩存定位。
全部都是微小的變化,但帶來了可觀的影響。
除了參數調整,一些變更還要求我們重新思考現有的設計:
- PR #28280 改進了剪枝節點(為節約磁盤空間而放棄舊區塊的節點)處理頻繁的內存緩存刷寫的方式。原本的設計要麼是丟掉整個緩存,要麼是掃描它以尋找修改後的條目。有選擇地跟蹤修改後的條目,為使用最大緩存(
dbcache)的剪枝節點帶來了超過 30% 的加速,在默認設置上也產生了大約 9% 的加速。 - PR #31551 引入了區塊文件的 讀取/寫入 批處理,減少了許多小規模的文件系統操作的開銷。這個 4 到 8 倍的區塊文件讀取加速,不僅讓初始化區塊下載受益,也讓其他 RPC 受益。
- PR #31144 優化了現有的可選的區塊文件混淆(用於確保數據並非以明文存儲在磁盤上),通過按 64 比特的分塊來處理而非按字節處理,帶來了又一項 IBD 加速。隨著混淆變得幾乎免費,用戶不再需要在安全存儲和性能之間二選一。
其它微小的緩存優化(比如 PR #32487)啟用了以往被(PR #32638)認為是過於昂貴的額外的安全性檢查。
類似地,現在我們可以更加頻繁地刷寫緩存到磁盤(PR #30611),確保在宕機事件中,節點絕不丟失 1 個小時以上的驗證工作。這個微小的開銷是能夠接受的,因為更在的優化已經讓初始化區塊下載快了很多。
PR #32043 當前是 IBD 相關的性能提升的一個跟蹤帖。它歸納了十多項正在開展的工作,從硬盤和緩存的調整,到併發的強化措施,並且提供了一個框架來度量每一項變更會如何影響實際場景中的性能。這種方法鼓勵貢獻者們不僅給出代碼,也給出可復現的基準測試、使用量數據和多種硬件的比較。
未來的優化建議
PR #31132 讓區塊驗證期間的交易輸入索取並行化。當前,每個輸入都是按順序從 UTXO 集中索取的 —— 如果緩存中沒有找到,就需要磁盤通信,從而產生讀寫瓶頸。這個 PR 在多個工作線程之間引入了並行化的索取,在 -reindex-chanstate(重新索引鏈狀態)中實現了大約 30% 的加速(在使用 450MB 數據庫緩存的樹莓派 5 電腦上,只花費大約 10 小時)。它的副作用是,縮小了使用高低 -dbcache `配置的性能差距,讓內存不多的節點同步起來可能跟高內存的節點一樣快。
除了初始化區塊下載,PR #26966 還使用可配置的工作線程,並行化了區塊過濾器和交易索引編制。
讓持久化存儲的 UTXO 集保持緊湊,對於節點的經濟性至關重要。PR #33817 通過移除一個可選的 LevelDB 特性(可能並非比特幣應用場景所需),實驗出了稍微減少它的效果。
SwiftSync 3 是一種實驗性的方法,利用了我們對歷史區塊的後見之明。已知實際的結果,我們可以為每一個遇到的錢幣按其在目標高度的最終狀態分類:依然未花費的(就要存下來),和在那高度前已經花費掉的(就要忽略,僅僅驗證它們出現在匹配的 創建/花費 配對中,具體位置則不必理會)。預先生成的提示可以編碼這種分類,讓節點可以完全跳過短命錢幣的 UTXO 操作。
比特幣對所有人開放
除了合成的基準測試,近期的一項實驗 4 也在一個降頻的樹莓派 5 上運行了 Swiftsync 原型;這個樹莓派 5 用一個電池包供電,通過 WiFi 聯網,在 3 小時 14 分鐘內就重新編制了 888,888 個區塊的鏈狀態。使用等效配置的實驗,在較新的 Bitcoin Core 版本上顯示出 250% 的完全驗證加速 5。
多年積累的工作轉化成了巨大的影響:完全驗證接近 100 萬個區塊,在便宜的硬件上也能在 1 天之內完成;儘管區塊鏈在持續增長,還是保持了經濟性。
自我治理比以往任何時候都更加容易。
參考文獻
1. https://github.com/bitcoin/bips/blob/master/bip-0050.mediawiki ↩
2. https://en.bitcoin.it/wiki/Common_Vulnerabilities_and_Exposures ↩
3. https://delvingbitcoin.org/t/swiftsync-speeding-up-ibd-with-pre-generated-hints-poc/1562 ↩
4. https://x.com/L0RINC/status/1972062557835088347 ↩
5. https://x.com/L0RINC/status/1970918510248575358 ↩
本文列出的所有 PR,都可以通過編號在這裡查找:https://github.com/bitcoin/bitcoin/pulls