本文為機器翻譯
展示原文
我已經進行了四次 3B 模型的訓練迭代。
我學到了很多,第一個模型和現在的模型相比簡直是垃圾,儘管我懷疑它甚至比不上一代針對同一領域的最先進模型。
但我現在很好奇它的性能極限在哪裡。

Dennison
@DennisonBertram
03-26
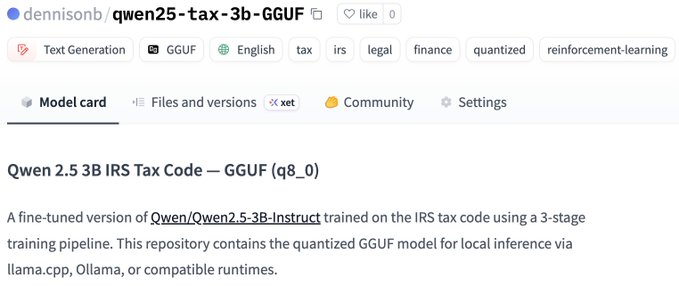
Just trained a small LLM on the entire IRS tax code using reinforcement learning — fully local on my MacBook.
Base model: Qwen 2.5 3B Instruct
Training data: 2,113 IRC sections + 6,149 Treasury Regulations
Pipeline: SFT → DPO → GRPO
Hardware: Apple M4 Max, 128GB RAM
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享