

我的初步研究表明,除了合同去重和存儲時壓縮代碼之外,合同代碼的存儲空間還可以再減少 30%。
Solidity 編譯器和其他所有編譯器都必然會生成包含操作碼模式的字節碼。在壓縮單個合約時,理想的壓縮算法會在這些模式在合約中出現一次後學習它們,然後在合約的其餘部分以簡化的方式引用它們。
然而,這意味著壓縮算法總是會對單個合約中首次出現的某種模式感到驚訝,因為該算法不知道這種模式在許多智能合約中都很常見,因此只能從它正在處理的單個合約中學習。
大多數壓縮算法庫都內置瞭解決方案——你可以提供一個預訓練的小型“字典”,其中編碼了歷史數據中已出現的常見模式。這樣,當這些常見模式首次出現在新數據中時,就可以立即對其進行壓縮。
其次,使用預訓練字典還能記住大量垃圾郵件/垃圾郵件合同中的常見模式。對於那些已被髮送數萬次且僅有細微差別的垃圾郵件合同,字典可以將這些合同的數量減少到原來的個位數百分比。
以下是結果:
圖片尺寸:986×428,11 KB
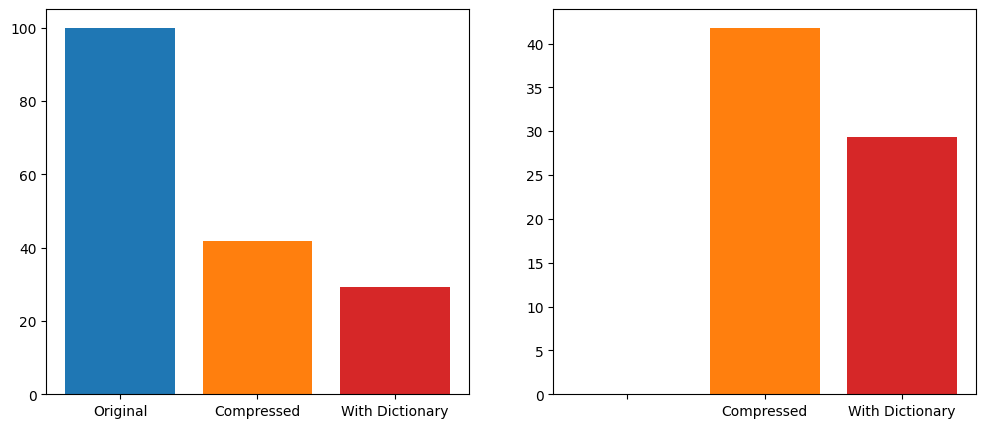
使用 zelliac 數據集,該數據集包含了截至 2025 年初部署的所有合約字節碼,共有1,539,858去重後的已部署字節碼集。
使用 Zstandard 壓縮庫,並採用其默認的快速壓縮級別 3,對每個單獨的字節碼集進行壓縮,總大小從原始大小的100%減少到41.8% 。添加一個 100KB 的字典,並在默認壓縮級別下進行訓練,最終字節碼大小為原始大小的29.3% ,比壓縮後的大小減少了30% 。
增加壓縮字典的大小或提高壓縮級別可以進一步減小最終文件的大小。我為了追求速度而進行了優化。此外,進一步調整字典訓練參數也很有可能獲得更小的文件大小。
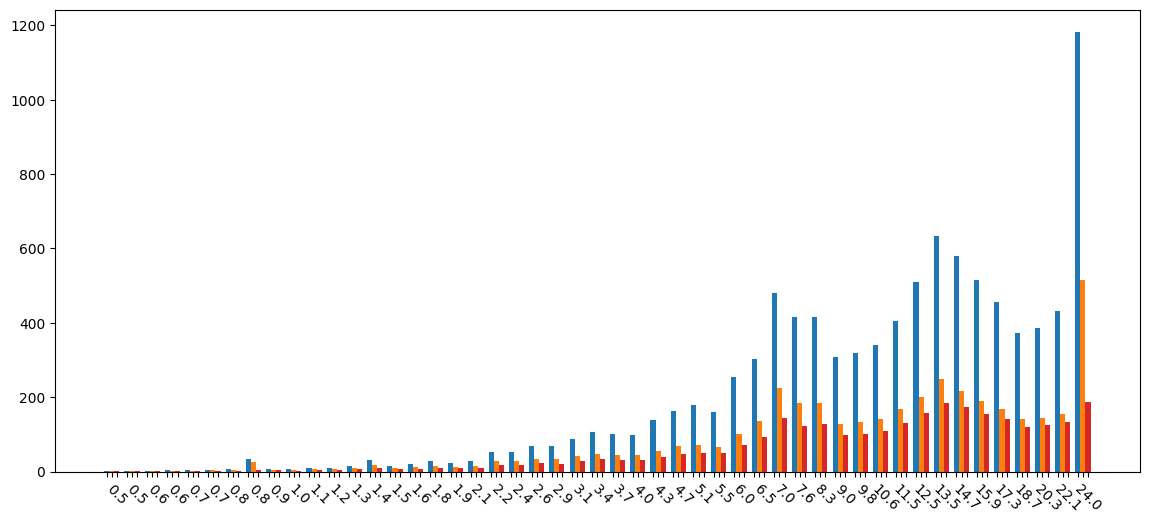
不同大小的合約字節碼所需的總存儲空間:
圖片尺寸:1149×523,大小:17.7 KB
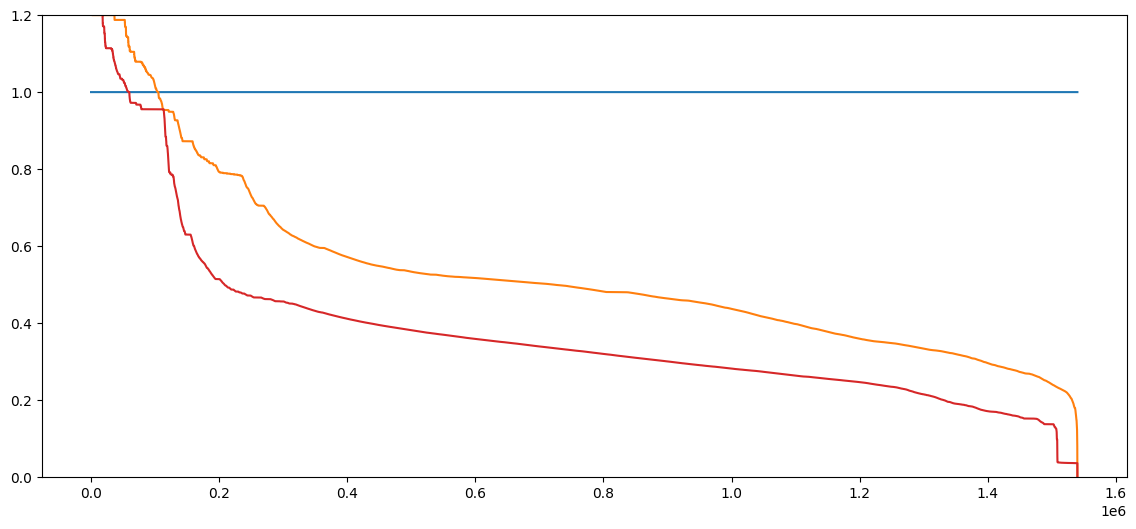
所有合同中的表現從最差到最佳。
圖片尺寸:1136×529,大小:26.4 KB
最後幾點說明:
- 如果在客戶端使用此功能,我建議存儲一個字節來指示合約是否被壓縮,如果被壓縮,則指示使用了哪個字典/ALGO。這樣可以方便將來平滑升級到更好的字典,同時也能避免壓縮那些壓縮後質量反而更差的文件。
- 我之所以選擇 zstandard 作為壓縮庫,僅僅是因為我過去使用它的體驗很好。目前我還沒有比較過不同的壓縮庫或算法。





