

我認為這是我近期寫過的最實用的文章之一。雖然它並非嚴格意義上的加密貨幣文章,但與我最近發表的關於人工智能代理和克勞德代碼的文章非常契合,而這些文章也確實很受歡迎。
每當我在本期簡報中談到人工智能時,通常指的是像 Claude、ChatGPT、 GeminiETC大型雲端人工智能工具。這些模型的工作原理是:你輸入一個提示,它會被髮送到某個服務器進行處理,然後返回結果。就這麼簡單。無論你是使用網頁界面,還是使用 Claude Max 訂閱在 Claude Code 中進行深度編碼,原理都是一樣的。
但還有完全運行在你自己電腦上的開源人工智能世界。這些是本地LLM(邏輯邏輯模型),到2026年,它們已經非常出色了。
不出所料,這個領域發展迅猛。僅在過去兩週, GLM-5.1 就成為首個在主流編碼基準測試中超越 Claude Opus 4.6 的開源模型。今天早些時候,Kimi K2.6 發佈,從GLM手中奪得桂冠。工具和模型不斷改進,雲端和本地之間的差距也在不斷縮小。
過去一週,我一直在學習和嘗試使用Mac版Studio上的本地模型,它們的強大功能讓我驚喜不已。當然,對於極其複雜的操作,它們肯定比不上Claude Opus 4.7和其他一些前沿模型,但對於我日常的大部分工作來說,本地模型確實非常實用。而且,它們免費、私密,並且隨時可用。
即使你保留了雲訂閱(我就是這麼做的),擁有一個本地模型作為備份或用於特定任務也是你能做的最佳舉措之一。
這本身就非常引人入勝,而且在這個時代,學習如何擁有和運行自己的模型是一項非常實用的技能。
今天這篇文章我們將介紹以下內容:
為什麼要運行本地模型?
硬件:你需要哪些硬件?
軟件工具
哪種模型適用於哪種任務?
入門
將本地模型與人工智能代理連接起來
結語
如果您有興趣進一步提升您的 AI 學習之旅,那麼請查看我與幾位朋友共同創辦的新公司: AI 的 Stoa 。
我們製作視頻課程,並每週舉辦直播研討會和電話會議,向您展示將人工智能融入日常工作流程的實用方法。
我們目前處於早期體驗階段,提供折扣價格,點擊這裡瞭解詳情: https://www.skool.com/thestoaofai
為什麼要運行本地模型?
五個主要原因。
隱私保護。您的提示、文件和對話都保留在您的本地計算機上,不會上傳到任何第三方服務器。對於任何處理敏感數據、專有代碼或機密文檔的人來說,這至關重要。更不用說那些僅僅關心個人隱私,不希望大型人工智能監視自己(或者更糟,不希望數據洩露給不法分子)的人了。
成本方面,一旦擁有了硬件,推理就是免費的。如果大量使用人工智能,本地模型通常會在足夠長的時間內收回成本。你還可以重新利用家中的舊設備來運行本地模型。
沒有速率限制。Frontier模型會迅速消耗積分。擁有本地備用方案簡直是天賜之物,讓模型運行永遠不會達到速率限制的任務(並且不計入您現有的速率限制)也同樣重要。大多數人採用“一刀切”的 AI 方法,對於一些完全過剩的簡單任務,使用像 Opus 和 Sonnet 這樣的模型,而更簡單的本地模型就能勝任。
離線訪問。這功能很棒。一旦將模型下載到本地,即使沒有網絡也能使用。您可以在飛行途中、偏遠地區與模型互動,或者只是擁有一個備用方案,在自己的電腦上訪問人類的全部知識。
完全掌控。您可以選擇模型,並隨心所欲地調整其配置。您無需擔心服務條款的變更,也不會因為違反條款(或因對方錯誤)而被無故封禁。運行本地模型時,您可以完全掌控整個 AI 堆棧。
幾周前,Anthropic 阻止 OpenClaw 和其他第三方代理框架使用 Claude Pro/Max 訂閱,這件事讓我感觸頗深。 依賴這種設置的人突然被迫切換到另一個提供商,或者支付每天可能高達 50 美元的 API 費用。
本地模型不存在這個問題。

正如我開頭所說,本地模型在處理最複雜的多步驟推理時無法與前沿模型相媲美。但對於簡單的日常編碼、摘要生成、草稿撰寫、網頁抓取、研究和問答等任務,它們可以處理我交給它們的 70-80% 的任務。
硬件:你需要哪些硬件?
在深入探討硬件本身之前,我們先快速瞭解一下量化。你會在本地LLM世界中到處看到這個術語,它會影響你做出的每一個硬件決策,因此值得提前理解。
對於大多數任務而言,4 位量化產生的輸出與全精度輸出幾乎沒有區別。如果您遇到類似 Q4_K_M 或 Q3_K_M 這樣的模型名稱,請注意,它們指的是同一模型,只是量化位數分別為 4 位和 3 位。
經驗法則:Q4 量化模型每十億個參數大約需要 0.6-0.7 GB 內存(我在上週的帖子中解釋了參數) 。
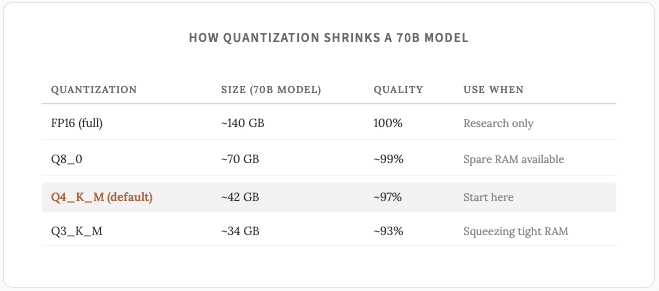
我建議您堅持使用Q4_K_M型號,除非您有特殊原因不這樣做。
好了,我們還是回到硬件話題上來。在硬件上運行LLM時,最重要的參數就是可用內存。這在PC上指的是顯存(VRAM),在Mac上指的是統一內存(UM)。其他所有硬件相關的參數都是次要的。
這裡有一個方便的圖表,可以根據不同的硬件規格查看您可以運行的模型類型:
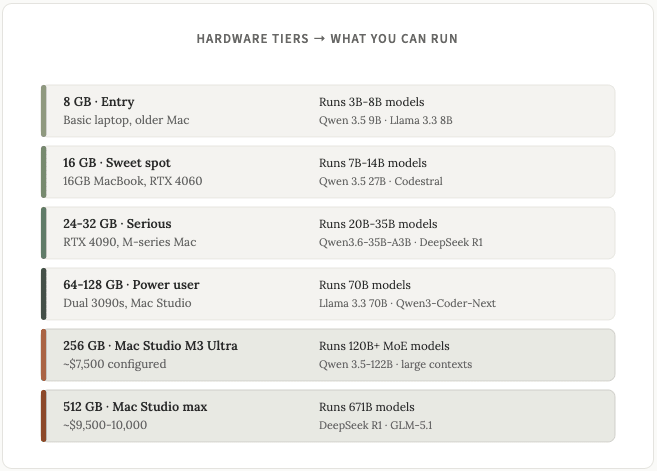
我個人在自己的 Mac Studio(Q3 版本,需要約 308GB 內存)上運行 GLM5.1,參數數量為 7440 億。
Mac 和 PC:你應該買哪一款?
這是一個常見問題,答案和大多數事情一樣,“視情況而定”。兩者沒有絕對的優劣之分,它們各有優勢,具體取決於您的情況/需求。
如果你預算有限,而且已經有了電腦:那就買一塊二手的 RTX 3090 顯卡吧。2026 年性價比最高的顯卡,每 GB 顯存。
如果您想要一臺價格低於 1500 美元的完整機器,並且主要運行 7B-14B 型號的 Mac Mini:配備 24GB 內存的 Mac Mini M4 Pro(1399 美元)。安靜、高效,無需組裝。
如果您想要中小型機型擁有最快的響應速度:組裝一臺配備 RTX 4090 或 5090 顯卡的電腦。總價大約在 2500-3500 美元之間。
這些設備不會很花哨,但對於簡單/基本的任務來說仍然非常實用,更重要的是,你至少可以在花額外的錢之前瞭解一下本地型號是如何運作的。
軟件工具
硬件是第一步,但有了硬件之後,您還需要一些工具來管理和運行您自己的設備上的模型。以下是主要選項。

它具有實時內存監控功能,可在您下載之前告知您的機器是否可以運行某個模型,並根據您的硬件推薦最適合您下載的模型。
它還公開了一個與 OpenAI 兼容的 API,因此您可以根據需要將其連接到腳本和代理(即,您可以在本地模型上運行 Openclaw 或 Hermes 代理)。
如果你想使用本地模型構建項目, Ollama總體來說是更好的選擇,但它要求你熟悉終端/命令行界面 (CLI)。Ollama 相對於 LM Studio 的一些優勢如下:
它是完全開源的(MIT 許可證)。LM Studio 是閉源軟件,其免費套餐不包含商業用途。如果您正在開發產品或希望瞭解計算機上運行的程序,Ollama 是更安全的選擇。
內存佔用更小。Ollama非常精簡。LM Studio 是一個 Electron 應用,即使不加載模型,僅 GUI 層就需要 300MB 到 1GB 的內存。
Ollama 與 LM Studio 具有相同的 API 兼容性。
llama.cpp和MLX是底層引擎。Ollama 和 LM Studio 都使用其中一個進行推理。大多數用戶無需考慮它們的具體作用。
哪種模型適用於哪種任務?
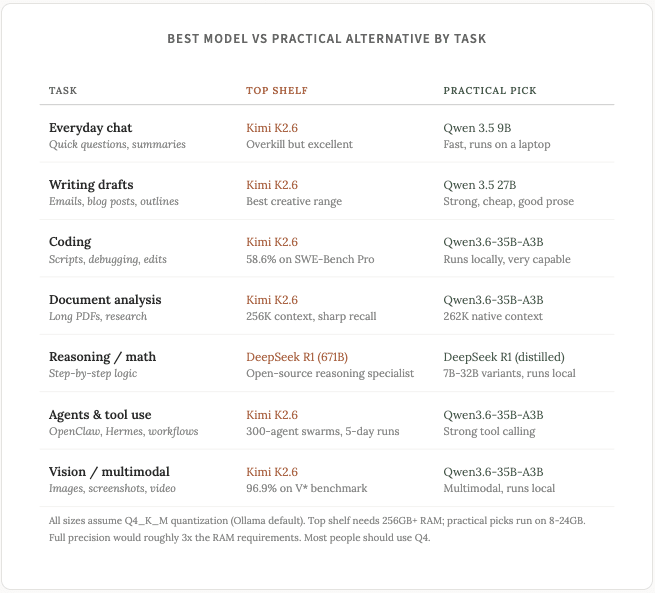
目前,在編程領域的頂尖產品中,有兩款開放重量級模型脫穎而出。

對於配置較低的硬件, Qwen 3.5 9B是一個實用的選擇,在 8GB 內存的 MacBook 上運行良好。它無法處理複雜的多文件運算,但對於一些日常任務(例如重寫電子郵件、文章摘要、快速問答),它的表現非常出色。
入門
如果您想嘗試運行自己的本地模型,以下是 LM Studioo 和 Ollama 的一些入門說明。
LM工作室:
從lmstudio.ai下載LM Studio。
安裝它。
打開應用。
點擊“發現”並搜索型號。實時內存監控器會告訴您該型號是否能在您的計算機上運行。
點擊下載。
完成後點擊“加載模型”,就可以開始使用了。你可以直接在LM Studio中與模型聊天,或者將其連接到像OpenClaw/Hermes這樣的代理(我將在下一節中解釋如何操作)。
奧拉瑪:
從ollama.com安裝 Ollama(適用於 Mac 和 Linux 的一鍵安裝程序)。
然後前往ollama.com/library或huggingface.co瀏覽模特。
每個模型列表都應該提供運行該模型的確切命令。HuggingFace 提供更多選擇,並顯示文件大小,方便您在下載前檢查內存是否足夠。
找到模型後,在終端中運行它,它應該看起來像這樣:
ollama run qwen3.5:9b第一次運行此類命令時,它會下載模型;之後,它會從硬盤加載模型。下載/加載完成後,您就可以立即通過終端與模型進行交互。
使用本地模型非常簡單,上手也很容易。從頭到尾的整個設置過程並不長,通常耗時最長的部分是下載模型本身(根據模型的不同,大小從幾GB到幾十甚至幾百GB不等)。
這就是在您自己的設備上運行本地 LLM 的全部步驟,我建議所有擁有相應硬件的人至少用一些最小的型號嘗試一下。
將本地模型與人工智能代理連接起來
事情變得有趣起來了。運行本地聊天機器人固然有用也很酷,但將本地模型連接到代理框架(Openclaw 或 Hermes)才是真正的突破。
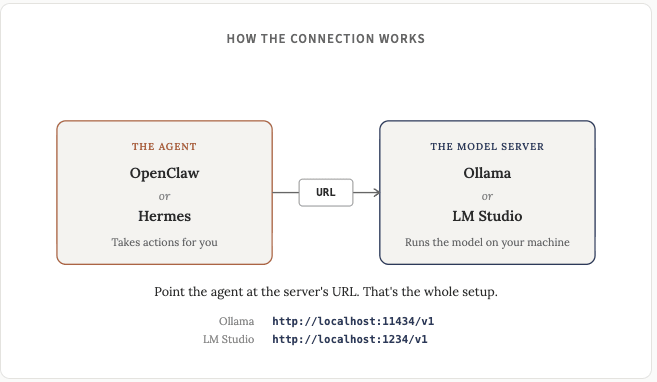
Ollama 和 LM Studio 都提供了兼容 OpenAI 的 API,OpenClaw 和 Hermes 也都支持這種格式,所以最終一切都很簡單。一旦你掌握了方法,就會發現嘗試新模型非常容易。
結語
本地模型無法取代 Claude Opus 4.7 處理複雜的多步驟推理。它無法像前沿的雲模型那樣高效地編寫內容。它也無法像雲模型那樣可靠地調試複雜的多文件代碼庫。
它將為您提供一個私密、免費、隨時可用的 AI 助手,它可以處理您交給它的大部分基本任務,而且,顯然,它有時還能更好地創建鵜鶘騎自行車的圖像?
我建議大家採用的最佳方案是:將最複雜的任務放在雲端,其他所有任務(或必須保密的內容)放在本地。不必非此即彼。
到2026年4月,本地LLM生態系統已經成熟。過去幾個月,LLM的質量取得了令人矚目的飛躍,如果這種趨勢持續下去,我們這些普通人在家就能掌握的AI能力將會非常驚人。
說實話,這些模型可能已經比你想象的還要好。擁有一個運行在你自己電腦上的人工智能,能夠以(幾乎)零運行成本和零數據洩露回答你的問題,這又讓我想起了科幻小說史上最偉大的作家之一的精彩論述:

免責聲明:本簡訊內容不構成投資建議。本人並非財務顧問,以上僅代表個人觀點和想法。在交易或投資任何加密貨幣相關產品之前,您務必諮詢專業/持牌財務顧問。文中部分鏈接可能為推薦鏈接。





