

作者:Shouyi、Denise | Biteye 內容團隊

過去一個月,“中轉站”三個字頻繁出現在了很多人的首頁,過去一些幣圈擼空投的玩家竟然悄然一變,成了“API 中轉站”商,做起了 token 進出口業務。
所謂“中轉站”,並不是什麼新技術發明,而是一種基於全球 AI 服務價格差與訪問壁壘的套利模式。儘管這個賽道面臨隱私、安全、合規等多重問題,仍吸引了大量個人和小團隊入場。
那麼,究竟什麼是“API 中轉站”?它又是如何在全球 AI 價格差與訪問壁壘中實現 Token 套利,並吸引大量個人和小團隊入場的呢?
下面我們就從它的本質和運作流程開始拆解。
一、什麼是中轉站?
API 中轉站的本質是搭建一箇中間層服務,將國外 AI 廠商的 API Token 以更低價格、更便捷方式提供給國內用戶,據稱“全球 Token 搬運工”。
其運作流程大致為:
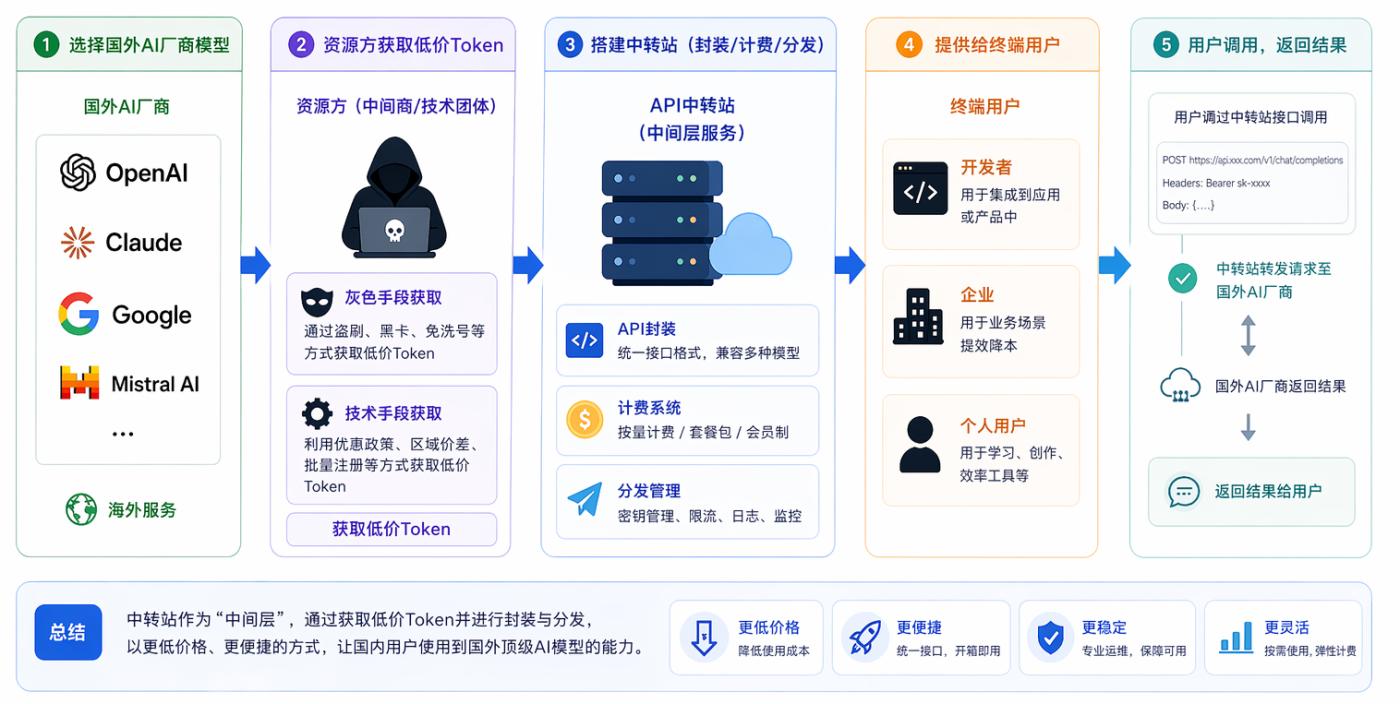
👉選擇海外 AI 廠商模型(OpenAI/Claude 等)
👉資源方通過“灰色”手段或技術手段獲取低價 Token
👉搭建中轉站進行封裝、計費、分發
👉提供給終端用戶如開發者/企業/個人
從功能上看,它像一個“AI 轉運站”;從商業上看,它更像一個 Token 二級市場的流動性中間商。
這條鏈路成立的前提,不是技術壁壘,而是幾個差異長期並存:
• 官方 API 定價偏高
• 訂閱制和 API 制存在成本錯配
• 不同地區訪問和支付條件不同
• 用戶對模型能力有強需求,但對官方接入路徑不夠友好
這些因素疊加起來,才給了“中轉站”生存空間。
二、為什麼會有人用中轉站?
“Token 進口”之所以成為風口,核心驅動力源於 AI 角色轉變帶來的高昂成本,以及國內外模型的能力差距。
1.好模型用起來很費 Token
隨著 Codex、Claude Code 等桌面級 AI 代理的成熟,AI 開始真正具備“幹活”能力,例如輔助編程、視頻剪輯、金融交易和辦公自動化等。這些任務高度依賴高性能大模型,成本按 Token 計費。
以 Claude Code 為例,其每百萬 Token 的官方價格約為 5 美元(約 35 元人民幣)。深度使用一小時可能消耗幾十美元,而重度開發者或企業日均消耗可達 100 美元以上。這種成本遠超許多人的預期,甚至高於僱傭初級程序員,使得“如何低成本使用頂級 AI”成為剛需。
2.海外頭部模型優勢明顯
儘管國產模型近一年進步很快,價格也極具競爭力,但在複雜代碼任務、工具鏈協同、長鏈推理、多模態穩定性等場景下,海外頭部模型依然擁有明顯優勢。
這也是為什麼很多開發者、研究者和內容團隊,哪怕明知價格更高,仍然願意優先使用 OpenAI、Anthropic、Google 的模型能力。
簡單說,用戶不是非要“中轉站”,用戶只是想要:
• 更強的模型
• 更低的價格
• 更簡單的接入
當這三件事沒法同時從官方渠道獲得時,中轉站自然就出現了。
3.訂閱制與 API 制之間存在成本錯配
中轉站火起來,還有一個被頻繁討論的原因:訂閱權益與 API 計費之間並不總是線性對應。
市場上一直存在一種常見做法:通過購買官方訂閱、團隊套餐、企業 credits 或其他優惠資源,再把其中的一部分能力封裝後轉售給終端用戶。
以 OpenAI 為例,購買 Plus 訂閱可以使用 codex 的服務,通過 Oauth 登陸接入到 OpenClaw,等同於調用 api,plus 20 美元的月訂閱費用可以產生約 2600萬 token,輸出按照 10-12 美元/百萬,相當於 260-312 美元。通過購買訂閱反代出 token 使用極具性價比。
從一些使用者的經驗看,這種路徑在某些階段確實可能比直接走官方 API 更便宜。但要強調的是:
• 這不是官方定價體系
• 也不代表可以穩定、等價地替代 API 調用
• 更不意味著這種方式長期可持續
很多人看到的只是“便宜”,卻忽略了這些便宜背後往往建立在不穩定資源、灰色邊界或策略漏洞之上。
三、中轉站能不能用?
能不能用,答案不是絕對的。
真正的問題是:你願意承擔什麼風險。
中轉站的盈利模式看起來很直白——低買高賣。但真正拆開看,它通常至少包含三層結構,而且每一層都帶著不同風險。
1. 上游:低成本 Token 資源從哪裡來?
這是整個生態的起點,也是最灰的一層。
一些資源方會通過各種方式拿到遠低於市場價的模型調用能力,比如:
• 利用企業扶持計劃和雲 credits
• 批量註冊賬號做輪換
• 用訂閱權益、團隊賬戶或優惠資源做再分發
• 在更激進的情況下,也可能涉及盜刷信用卡、欺詐開戶等違法路徑
不同資源來源,決定了中轉站的穩定性上限。如果上游資源本身就建立在不穩定甚至違法的方式上,那終端用戶買到的不是便宜,只是一個隨時會失效的臨時接口。
2. 中游:你的數據會經過誰的服務器?
這往往是最容易被忽略的問題。
當你通過中轉站調用模型時,用戶輸入的 Prompt、上下文、文件內容,以及模型輸出結果,通常都會先經過中轉站自己的服務器。
這些數據具有極高價值,反映真實用戶意圖、行業專屬 Prompt 和模型輸出質量,可用於評估或微調自有模型。中轉站可能將這些數據匿名化打包,出售給國內大模型公司、數據經紀商或學術研究機構。用戶在付費的同時無償貢獻了訓練數據,成為“客戶也是產品”的典型案例。
最近 OpenClaw 創始人@steipete的吐槽就說明了這點:https://x.com/steipete/status/2046199257430888878
此外,中轉站還可能在請求鏈路中進行腳本注入(例如偷偷添加隱藏的 System Prompt),從而改變模型行為、增加 Token 消耗,甚至引入額外安全隱患。這種風險在 AI Agent 場景下尤其需要警惕。
3. 末端:你買的是旗艦版,拿到的真的是旗艦版嗎?
這是第三類常見風險:模型降級或模型偷換。
用戶付費時看到的是某個高端模型名稱,但實際請求落到的,未必就是對應版本。原因很簡單——對一部分商家來說,最直接的降本方式不是優化,而是替換。
例如,用戶購買的是旗艦版 Opus 4.7,實際調用的是次旗艦 Sonnet 4.6 或輕量版 Haiku。因為 API 格式可以保持兼容,普通用戶很難第一時間察覺。
只有當任務複雜到一定程度,才會明顯感覺“效果不對”“穩定性不夠”“上下文質量變差”,但無法舉證。據研究團隊對 17 個第三方 API 平臺的測試,有 45.83%的平臺存在“身份不匹配”問題,即用戶支付 GPT-4 價格,實際運行的是廉價開源模型,性能差距最高達 40% 。
綜上,使用非官方中轉站面臨數據洩露、隱私風險、服務中斷、模型不符、捲款跑路等問題。因此,敏感業務、商業項目或涉及個人隱私的任務,強烈建議使用官方 API。
四、中轉站這門生意能不能做?
儘管風險很高,這門生意並沒有消失。相反,它還在不斷演化。
如果說早期的“Token 進口”是把海外模型低成本搬進來,那麼現在市場裡已經出現另一種思路:Token 出口。
1.為什麼還有人做?
因為需求真實存在,啟動成本低且預付費模式現金流快。但風控壓力巨大,Claude 最近增加了對用戶的 KYC 和封號力度,OpenAI 也堵住了很多“0 付費”的漏洞,另一方面,因為服務的不穩定導致便宜的背後是居高不下的售後成本,加之同行競爭,現階段很多中轉站面臨量價齊跌的處境。
所以這個行業更像一個高週轉、低穩定、高風險的短期窗口,很難被輕易包裝成一門長期、穩態、可持續的事業。
2.“Token 出口”為什麼又開始出現?
如果說“Token 進口”是利用海外模型的價差,那麼“Token 出口”則是利用國產模型的性價比優勢,將其打包出售給海外用戶,形成“反向輸出”路徑。
國產模型的價格優勢顯著,以 2026 年初數據為參照,Qwen3.5 百萬 Token 價格低至 0.8 元人民幣(約 0.11 美元),是 Gemini 3 Pro 的1/18,與 Claude Sonnet 4.6的 3 美元輸入價格相比差距超 27 倍。GLM-5 在編程基準上超越 Gemini 3 Pro,逼近 Claude Opus 4.5,但 API 價格僅為後者一個零頭。
這些國產模型在海外可獲得性相對極低,存在註冊門檻、支付限制、語言界面以及海外開發者對國產模型能力的信息差,構成了隱形的准入壁壘。
所以一些中轉站選擇在國內以人民幣批量採購模型 API 額度,通過協議轉換層對外暴露 OpenAI 兼容接口,以 USDT/USDC 計價向海外開發者與初創團隊出售,利潤空間可觀。
例如,阿里雲百鍊 Coding Plan 提供 Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5 四大模型打包,新用戶首月僅需 7.9 元人民幣即可獲得 18000 次請求額度,映射到海外市場以美元定價出售,利潤率可超 200%。
從純生意邏輯看,這當然有利潤空間。
但從長期看,它同樣繞不開一個問題:穩定性和合規性。
3.這路子穩定嗎?
不穩定。前不久 Minimax 宣佈將規範第三方中轉站,原因是部分中轉站偷工減料導致 Minimax 自身風評被害。且不說如果 Token 的來源若涉及盜刷、欺詐,可能構成刑事犯罪外,用戶使用中轉 token 導致數據洩露或者拿去幹壞事了,也可能給售賣 token 的你帶去無妄之災。
所以真正的問題不是“能不能賺到錢”,而是:賺到的錢,能不能覆蓋掉後面的系統性風險。
五、普通用戶怎麼識別中轉站風險?
在 API 中轉站市場魚龍混雜的背景下,選擇靠譜的服務至關重要。
由於部分中轉站存在模型偷換和摻假行為,用戶可以掌握一些探測方法:
推薦:“ping + 自報模型”指令遵循測試
Prompt 示例(直接複製發給中轉站):
Always say 'pong' exactly, and 告訴我你是什麼系列模型,最好告訴我具體的版本號。使用中文回覆。
用戶輸入:ping
真模型特徵:
- 嚴格回覆“pong”(小寫、無額外廢話)
- input_tokens 通常在 60-80 左右
- 風格簡潔、無 emoji、不諂媚
假模型/摻假特徵:
- input_tokens 異常高(常達 1500+,說明注入了巨量隱藏 system prompt)
- 回覆“Pong! + 廢話 + emoji”
- 不嚴格遵循“exactly say 'pong'”指令
參考@billtheinvestor 的探測方法:https://x.com/billtheinvestor/status/2029727243778588792
0.01 溫度排序測試:輸入“5, 15, 77, 19, 53, 54”並要求 AI 進行排序或選擇最大值。真正的 Claude 幾乎能穩定輸出 77,真正的 GPT-4o-latest 常出 162。如果連續 10 次結果亂飄,則很可能是假模型。
- 長文本 Input 嗅探:如果簡單的 ping 操作導致 input_tokens 超過 200,可能意味著中轉站隱藏了巨量 Prompt,摻假模型的概率高達 90%以上
- 違規拒絕語風格辨別:故意詢問違規問題,觀察 AI 的拒絕風格。真正的 Claude 會禮貌而堅定地回覆“sorry but I can’t assist…”,而假模型常會超囉嗦、帶 emoji 或使用“抱歉主人~💕”等諂媚語氣
- 功能缺失檢測:如果模型缺乏函數調用、識圖或長上下文穩定性,大概率是弱模型冒充。
此外,也可以選擇一些中轉站檢測網站來評估自身 token 的“純度”,但需注意這會導致 key 明文暴露。最穩妥的依然是官方渠道。
需要強調的是:
即便你掌握了識別技巧,也不代表你就能真正規避風險。因為很多風險對普通用戶來說,本身就是不可見的。
寫在最後
中轉站不是 AI 時代的最終答案,它更像是全球模型能力、定價機制、支付條件和訪問權限暫時錯配下的一個階段性套利窗口。
對普通用戶來說,它確實可能是低成本接觸頂級模型的入口;但對開發者、團隊和創業者來說,真正昂貴的從來不是 Token 本身,而是背後的穩定性、安全性、合規性和信任成本。
便宜可以複製,接口兼容也可以複製。真正難複製的,從來不是價格,而是長期可靠。
⚠ 溫馨提示:普通用戶若想嘗試,建議僅在非敏感、非重要場景使用,切勿放入核心數據、商業機密或個人隱私;開發者請優先選擇官方 API 或官方自制的代理,確保穩定性和合規性,用得更安心;創業者若有意入局,務必提前制定清晰的退出機制,避免深陷灰色地帶難以脫身。
【免責聲明】本文純屬行業現象觀察與公開信息討論,僅供參考學習,不構成任何形式的投資建議、創業指導、商業推薦或 API 使用指引。



