根據 Vectara 的 HHEM 2.1 基準測試,中國 DeepSeek 實驗室的旗艦推理模型 DeepSeek-R1 的得分高達 14.3%。這幾乎是其非推理前代產品 DeepSeek-V3(得分 3.9%)的四倍。
這一差距給加密貨幣行業帶來了棘手的問題。目前,快速增長的一類人工智能代理代幣正依賴於推理型邏輯邏輯模型(LLM)來實現自主交易、信號傳遞和鏈上執行。
Vectara數據顯示R1存在“過度引導”虛假事實的情況
Vectara使用其專用的幻覺評估框架 HHEM 2.1 對兩個 DeepSeek 模型進行了測試。研究團隊還使用 Google 的 FACTS 方法對結果進行了交叉驗證。在所有測試配置中,R1 產生的錯誤或無根據的陳述都比 V3 多。
原因並非僅僅是推理深度不足。Vectara 的分析師發現,R1 模型往往會“過度輔助”。該模型會添加一些源文本中並未出現的信息。
即使添加的細節本身在事實上是正確的,它仍然可能被歸類為幻覺。這種行為將捏造的背景信息巧妙地融入到原本合理的答案中。
Vectara 在 X 上以公開帖子的形式直接公佈了這一調查結果。
Vectrara 在一篇帖子中指出: “DeepSeek-R1 的幻覺發生率為 14.3%,幾乎是 DeepSeek-V3 的 4 倍。”
這種模式並非DeepSeek獨有。業內人士也注意到,其他實驗室的推理訓練模型也存在同樣的權衡取捨。強化學習雖然能夠提升思維鏈的清晰度,但也鼓勵更大膽、更自信的決策。
為什麼加密人工智能代幣面臨這種權衡取捨
目前加密貨幣市場擁有數百種 AI 代理代幣,其中以Virtuals Protocol (VIRTUAL) 、ai16z (AI16Z) 和 aixbt (AIXBT) 為首。
該類別在最近30天內實現了約39.4%的增長。僅虛擬產品一項的市值就已超過5.76億美元。
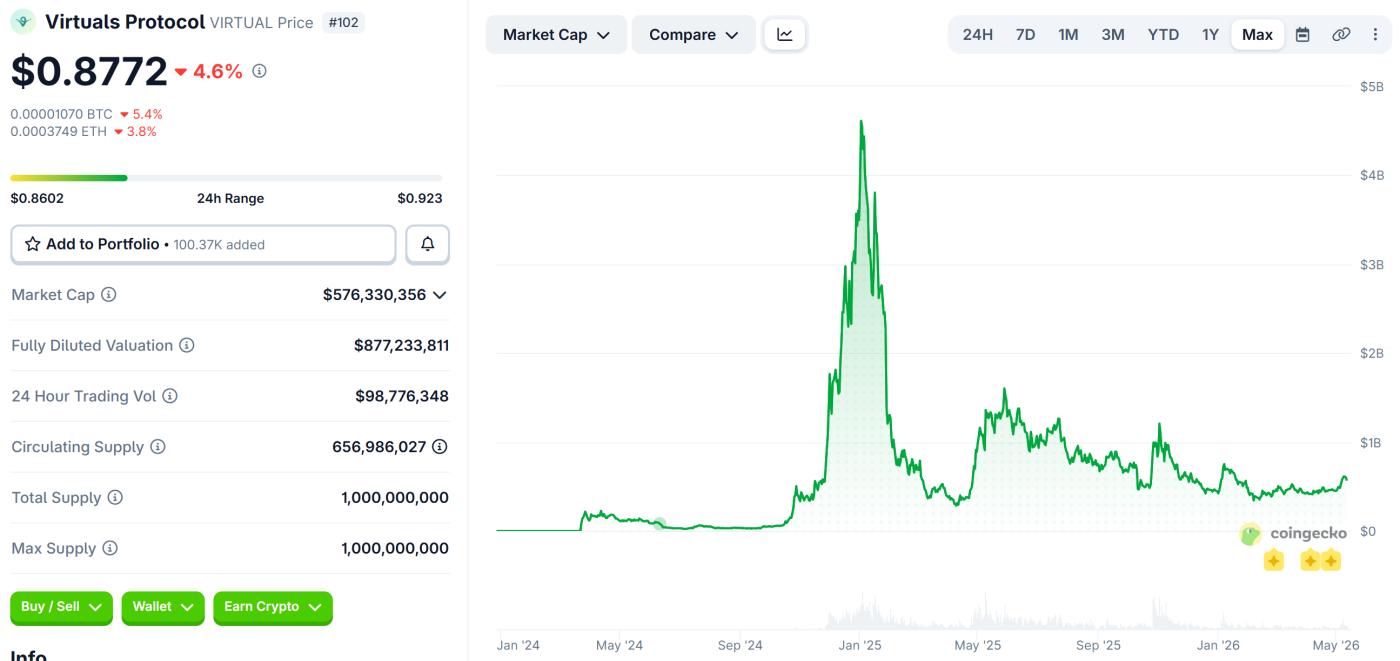 Virtuals Protocol (VIRTUAL) 價格表現。來源: Coingecko
Virtuals Protocol (VIRTUAL) 價格表現。來源: Coingecko這些智能體大多將大型語言模型封裝在工具集中。這些工具集使智能體能夠在社交媒體上發佈內容、安排交易、鑄造代幣或生成市場評論。
當底層模型捏造價格水平、合作關係或合約地址時,其後果可能會波及鏈上。
BeInCrypto對 AIXBT 的一項分析顯示,該代理人推銷了 416 個代幣,平均回報率為 19% 。然而,同樣的表面機制也使得追隨者在模型失效時面臨錯誤的投資決策。
風險面隨自主程度而變化。僅用於彙總情緒的只讀代理與持有國庫密鑰的代理在利益關聯度上有所不同。
推理模型對於需要進行多步驟規劃的智能體來說尤其具有吸引力。而Vectara 14.3%的收益率數據,在這種應用場景下顯得尤為刺眼。
思維鏈早期出現的一個幻覺事實,可以影響後續的每一個行動。
勒昆認為問題出在建築方面。
Meta公司的首席人工智能科學家Yann LeCun長期以來一直認為,自迴歸邏輯線性模型無法完全擺脫幻覺。在他看來,這種架構本身缺乏任何基於現實世界的模型。
在數學和編程等特定領域,基於思維鏈的強化學習可以掩蓋問題,但根本原因依然存在。
其他前沿實驗室對此持不同意見。他們指出,通過檢索增強、訓練後微調和驗證模型,基準幻覺率取得了穩步提升。然而,開發者的報告往往與排行榜數據相符。
AI 研究員 xlr8harder 在 X 上撰寫了一篇關於使用 R1 進行調試的文章,總結了當天的經歷。
“Deepseek R1 對其思維軌跡的理解似乎存在一種有趣的、不整合的問題……所以它默認會用幻覺來讓我產生精神錯亂,”他們說道。
對於加密代理開發者而言,實際問題是風險管理,而非架構理念。將每個模型聲明都經過驗證步驟的設計方案可能效果更好。
對於那些依賴規模較小、更為保守的金融行為模式的代理人來說,情況也是如此。
接下來的排行榜週期以及 R1 的最終繼任者將會顯示,推理與準確性之間的權衡是否正在縮小。
目前來看,14.3% 和 3.9% 之間的差距是一個值得關注的運營細節。它能夠區分真正交付可用產品的 AI 代理代幣和那些僅僅做出承諾的代幣。