文章的核心觀點是:金融AI的競爭焦點不在於誰能打造一個更會聊天的“金融版ChatGPT”,而在於誰能深度融入金融從業者的日常工作工具(如Excel、PPT、Word)和核心業務流程(如盡調、審批),並直接輸出可被審閱、歸檔的正式“交付物”。
文章作者:Resonant Ones
文章來源:遂初.AI
金融 AI 的競爭不在"誰會聊天",而在"誰能進入 Excel、PPT 和審批流"。
很多人以為,金融 AI 的競爭,是訓練一個更懂金融的大模型。
但 Claude for Financial Services 暴露了真正答案:金融 AI 的核心不是模型,而是工作流。
它不是讓 AI 陪用戶聊股票,而是讓 AI 進入 Excel、PPT、Word、投研、投行、盡調、合規、對賬和審批流。
這件事對國內創業者很關鍵。因為如果你還在做"金融版 ChatGPT",大概率會被大廠、數據終端和辦公套件吃掉;但如果你能接管金融機構每天重複生產的 Excel、PPT、Word 和審批包,機會才剛剛開始。
一個真實場景
上個月我和一個做 PE 的朋友聊。他們團隊對一家消費公司做盡調,收到的 Data Room 有 17 個文件夾、400 多份文件——合同、審計報告、銀行流水、訂單明細、訪談紀要、管理層材料。
以前一個 VP 帶著兩個分析師幹兩週,才能出一份像樣的 IC Memo 初稿。
現在呢?如果有一個人(或者一個 Agent)能在 24 小時內跑完資料梳理、風險標記、缺失項識別和初稿生成——你覺得客戶會不會買單?
這不是科幻。Claude for Financial Services 已經在做這件事了。而它開源的不是一個 App,是一套「Agent + Skill + Connector + 交付物 + 人工籤核」的產品範式。
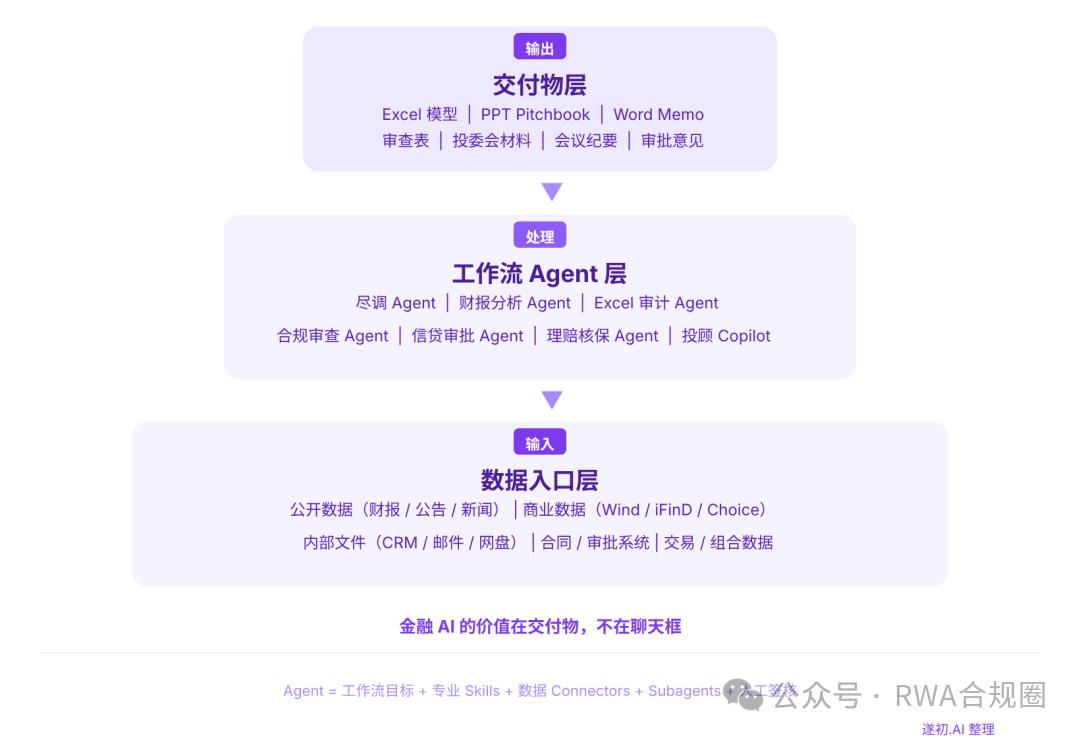
先說第一個發現。Claude for Financial Services 的產品結構其實很簡單:Agent 負責端到端任務,Skill 沉澱金融專業流程,Connector 接入金融數據和企業內部系統,Excel、PowerPoint、Word 承接最終交付物,再加上權限、引用、審計、人工複核保證金融機構能用。
過去金融 AI 的形態是你問一個問題,AI 給一個答案。但金融機構真正需要的是:你給我一堆資料,我要一份能被審閱、能被引用、能被歸檔、能進入業務系統的交付物。這兩者差別巨大。金融 AI 的價值在交付物,不在聊天框。
另一個值得關注的變化是,國內金融機構已經不是觀望狀態了。
2025 到 2026 年,我看到的落地情況大致分三個梯隊。銀行走得最快,建設銀行完成 DeepSeek 私有化部署,覆蓋了數百個場景。中信建投基金用 DeepSeek 做 REITs 盡調,5 名員工 70 天的工作量壓縮到 1 人 10 天——效率提升了 30 倍。
券商人保財險也跟上了,中信建投證券基於多智能體做投顧服務,人保財險接入 DeepSeek 建專業知識庫,平安大模型半年調用 8.18 億次。
但真正有意思的是第三梯隊——PE、資管和財富管理。它們數據多、預算足、交付壓力大,但目前大多還在 POC 階段。這不叫落後,這叫創業公司的窗口期。
說到創業公司切入,很多人第一反應是做金融版 ChatGPT。但這件事風險很大,因為會同時遇到三類強敵。
模型廠商會把通用能力越做越便宜。金融數據終端像 Wind、Choice、iFinD、同花順,本來就有數據和用戶入口,AI 一嵌進去,泛金融問答很難獨立收費。大型金融機構更傾向於自建內部 AI 中臺,把通用能力放進自己的權限體系裡。
創業公司正面打,三線受敵。
但如果你換個角度,不看入口,看操作層,情況就不一樣了。什麼叫垂直操作層?就是圍繞一個具體崗位、一個具體流程、一個具體交付物,把 AI 做深。比如 PE/投行盡調資料結構化、Excel 財務模型審計、信貸審批材料初審、合規審查表自動生成、保險理賠和核保材料輔助審核、客戶經理會議紀要自動整理。
這些方向看起來不如"金融大模型"宏大,但更接近客戶預算。
什麼樣的產品值得做
我總結下來,必須同時滿足四個條件。
接得住數據
真正高價值的場景,往往要接客戶內部文件、CRM、網盤、郵件、合同、審批系統。只處理公開網頁,價值很有限。
跑得通流程
金融用戶不會為了 AI 改變工作習慣。產品要進入他們已經在用的 Excel、PPT、飛書、企業微信、釘釘、WPS、CRM。
交得出文件
金融機構買單的不是回答,而是材料。能輸出審查表、memo、deck、Excel,才有付費意願。
留得下責任邊界
AI 必須支持引用、留痕、權限、審計、人工複核。不做投資建議、不自動交易、不替代最終審批。
這四條缺一條,產品就很難進入真實生產環境。
如果把視角拉遠,看未來 24 個月,我覺得最值得關注的細分方向有七個。
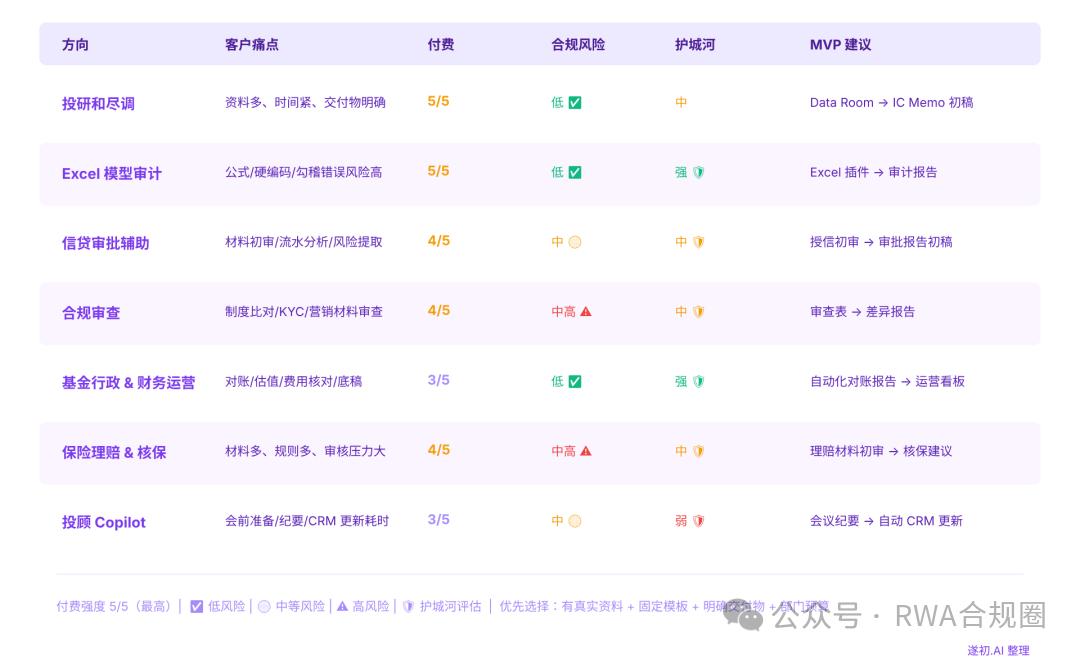
投研和盡調排第一。資料多、時間緊、交付物明確,是最接近 Hebbia 和 Rogo 的方向。
其次是 Excel 模型審計——投行、PE、信貸、資管都有大量 Excel,公式錯誤、硬編碼、假設不一致,AI 輔助空間極大。
信貸審批輔助排第三,銀行和非銀都需要材料初審、流水分析、風險提取和授信報告生成。合規審查排第四,制度比對、營銷材料審查、KYC 檢查,都適合做可引用、可留痕的 AI 助手。
基金行政和財務運營對賬、估值、費用核對、審計底稿非常流程化且錯誤成本高。
保險理賠和核保材料多、規則多、審核壓力大但必須保留人工確認。
最後是客戶經理和投顧 Copilot,不是 AI 直接給投資建議,而是幫顧問做會前準備、產品解釋、會議紀要、CRM 更新。
這七個方向有一個共同的前提:產品必須可審計、可引用、可私有化。
金融機構不會接受"AI 大概是這麼說的"。數字從哪來?引用在哪裡?誰複核過?數據是否出域?這是採購決策的前提條件。所以從一開始就要設計引用溯源、人工籤核、數據隔離和操作留痕。這不是合規成本,是產品壁壘。
還有一個更大的趨勢。模型能力商品化之後,機會轉向 workflow、connector 和治理層。就像當年雲計算讓 IT 基礎設施變成 API,新一代創業者會在上面做 SaaS。今天的大模型也一樣——誰能在上面封裝行業工作流,誰就有壁壘。
金融行業知識工作信息密度高、格式要求高、責任約束強,這些特性決定了它不是通用 AI 能快速覆蓋的。這恰恰是創業公司的安全區。
創業公司怎麼切入
不要一開始做平臺。
找一個窄場景:有真實資料、有固定模板、有明確交付物、有人工複核、有部門預算、能在 60-90 天內驗證 ROI。
不要這樣說:
我要做金融機構 AI 平臺。
要這樣說:
我先幫 PE/FA 團隊把 Data Room 資料自動結構化,輸出盡調 Q&A、風險清單和 IC Memo 初稿。
越具體,越容易成交。
最大風險被大廠替代?
通用入口會被替代。泛金融問答、普通研報摘要、簡單數據查詢,很容易被大模型和數據終端覆蓋。
但垂直深流程不會。
因為大廠不願意為每個細分崗位做髒活。真正難的是:接入客戶內部系統、理解崗位流程、適配客戶模板、陪客戶從 POC 跑到生產。
這些不是一個模型 API 能自動解決的。