

作者:Dmytro Zakharov
致謝
本本部分基於我在 Blockstream 研究部門工作期間形成的研究。感謝大家支持我並給我研究這個課題的機會。
格外感謝 Jonas Nikc,細緻地審核本文並給出了非常有用的建議;還有 Mykyta Redko,注意到了本文的解釋中的幾個重要的錯誤。
引言
因為 Google Quantum AI 團隊的最新論文出版,圍繞第一臺 “有密碼學意義的量子計算機(CRQC)” 何時問世的討論又開始升溫(直白地說,在有些地方甚至變成了一種恐慌)。觀點差別很大,但有一個點似乎是每個人都同意的:我們需要儘快遷移到量子安全的算法。
當然,需要這樣做的,包括大量已在服役的協議;尤其是,在比特幣(以及廣義的區塊鏈領域),自然而然的第一步就是構造一種後量子的(PQ)安全電子簽名方案。然而,哪怕是這第一步,也涉及許多爭議:現在有許多備選的 PQ 方案,但他們都(a)在某些指標上顯著差於 “零散對數(DL)” 構造(至少是 16 倍);(b)底層的安全性假設通常更少得到研究(相比於前量子的同類方案)。
目前為止,PQ 簽名主要有兩種類別:基於哈希函數的,以及 基於格的(lattice-based)。關於基於哈希函數的密碼學,Blockstream 已經形成了非常豐富的分析和研究: 比如說,由 Jonas Nick 和 Mikhail Kudinov 撰寫的《為比特幣考慮基於哈希函數的簽名方案》,以及由 Jnoas Nick 提出的 SHRIMPS 方案。現在,輪到基於格的構造了!
重要提醒
我們注意到還有基於編碼的(code-based)構造,但它們的公鑰和簽名的體積都太大了:舉個例子,一個重要的(前)NIST 候選方案 LESS 的公鑰體積最小是 13.9KB 。也就是說,從目前來看,似乎不是比特幣的可行選項。
本文的課題
如前所述,我們準備分析基於格的簽名方案背後的基本想法。尤其是,在讀完本文之後,讀者可以獲得對一種叫做 “帶中止的 Fiat-Shamir 變換(Fiat-Shamir with aborts)”(也叫 “拒絕採樣 ”)的關鍵技術的堅實理解;這種技術用在 Dilithium 以及(比如說)許多基於格的證明系統(proving systems)中(參見《基於格的積證明》)。令人驚喜的是,這種技術與基於離散對數假設的傳統 Schnorr 簽名構造非常相似。在本文中,我們會提供一套基礎的工具,幫助讀者理解基於格的方案,希望能讓讀者更容易進入這個密碼學領域。
更具體一些,在本文中,我門將從著名的論文《無陷門的格簽名》出發,理解作者 Lyubashevsky 所提出的構造;該文可能是整個格密碼學領域影響力最大的一篇論文。
對格的基本介紹
格
先介紹一下我們的研究對象。我們定義 $m$ 維的 “格(lattice)” $\Lambda \subseteq \mathbb{R}^d$ 為一組獨立的線性向量 $\mathbf{b}_1,\dots,\mathbf{b}_m$ 在 $\mathbb{R}^d$ (d 維實數空間)上的所有整數線性組合(其中 $m\leq d$),也即:
$$
\begin{equation*}
\Lambda \triangleq \left{ \sum_{i=1}^m \lambda_i\mathbf{b}_i: \lambda_1,\dots,\lambda_m \in \mathbb{Z} \right}.
\end{equation*}
$$
為了更直觀地理解這個東西,這裡給出一個具體的例子:下圖是一個二維($m=d=2$)的格。
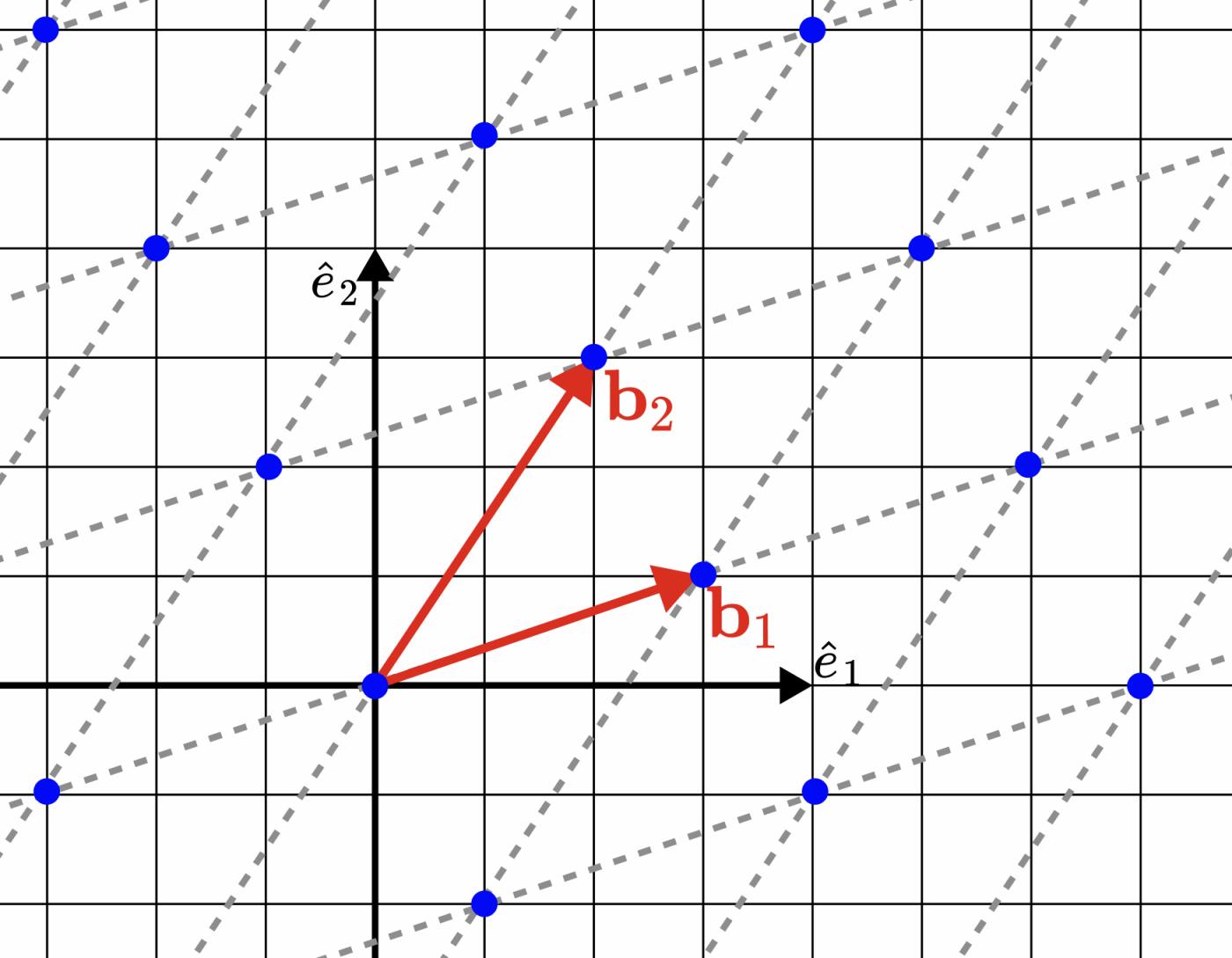
圖 1.一個二維格的例子,它由向量 $b_1 = (3, 1)$ 和 $b_2 = (2, 3)$ 張成。得到的格 $\Lambda$ 是一組藍色的點。
我第一次讀到這個定義時,忍不住懷疑 “這麼直截了當的定義,能搞出什麼有用的東西呢?”但是,在密碼學家們注意到格是許多計算困難問題的根域以前,格就已經被證明在數學上是有用的,至少可以追溯到 18 世紀。事實上,格是自然而然出現在許多領域的,比如數論(number theory)和球堆積(sphere packings)問題(兩者都或多或少與基於格的和基於編碼的密碼學有關)。
注:
有時候我會聽到這樣一種說法:“相比於基於哈希函數的密碼學,格太不成熟了”。然而,這是一種概念錯亂,因為早在哈希函數被髮明(可以追溯到大概 1950 年)之前,格就已經被使用和研究了:) 不過,格確實比哈希函數擁有更豐富的代數結構。雖然這可以帶來更高級的密碼學協議(例如:多簽名或 SNARKs),我們還是要謹慎對待其安全性。
密碼學中的格問題
基於格的密碼學圍繞著一些假設展開,這些假設可以歸約(reduced)為解決格 $\Lambda$ 上的一些難題。反過來,這些問題,在當前,被認為哪怕是量子計算機也難以求解。現在有許多這樣的假設,比如:最短向量問題(SVP)、最近向量問題(CVP)、有限距離解碼(BDD)、格同構問題(LIP)、決定性最短向量問題(GapSVP),等等。
在本文中,我們只會介紹其中一種假設。
(近似的)最短向量問題($\gamma$-SVP)。目標是找出格 $\Lambda$ 上的一個 “非常短” 的向量。我們可以(相對容易地)證明 $\Lambda$ 包含這個 最短的 向量(即,存在 $\mathbf{u} \in \Lambda$ 使得 $|\mathbf{u}|=\min_{\mathbf{v} \in \Lambda}|\mathbf{v}|$,其長度我們記作 $\lambda_1(\Lambda)$ ,但是,找出這樣一個向量,被認為甚至對量子計算機也是一個難題。我們把這個問題稱為 “SVP” 。
然而,想要基於這個 “裸” SVP 開發出實用的協議,幾乎是不可能的。於是我們放寬要求:假設我們接受其範數值小於 $\gamma\lambda_1(\Lambda)$ 的向量,只需因子 $\gamma>1$ 。可以證明,這樣一個修改過的問題,對哪怕是較大的因子也依然足夠難,比如 $\gamma=\mathsf{poly}(\sqrt{d})$ 。這個修改後的問題,我們稱為 “$\gamma$-SVP”。(譯者注:“範數(norm)” 是將向量空間內的向量映射成實數的函數。或者說,每種範數都對應著一種定義向量長度的方式,可以將範數值理解成長度。)
這個問題可以用下圖來演示。
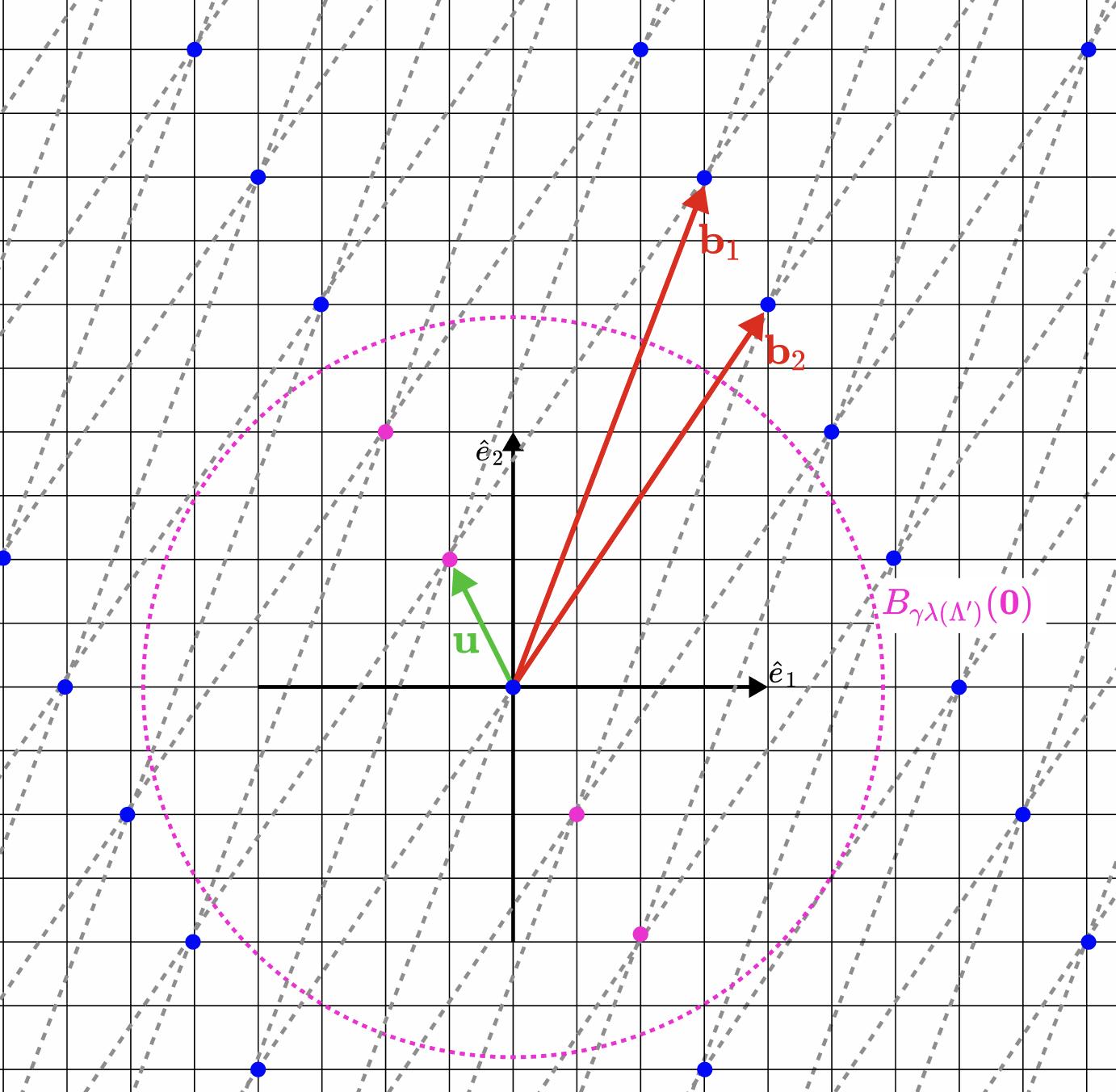
*圖 2. 解釋 $\gamma$-SVP 。假設格 $\Lambda’$ 是由向量 $\mathbf{b}_1=(3,8)$ 和 $\mathbf{b}_2=(4,6)$ 張成的(順帶說一句,它是在上文的 圖 1 中定義的格 $\Lambda$ 的子格。它的兩個最短向量是 $\mathbf{u}=(-1,2)$ 和 $-\mathbf{u}$ ,兩個向量的長度都是 $\lambda_1(\Lambda’)=\sqrt{5}$ 。在這個近似版本的 $\gamma$-SVP 中, $\gamma$ 約等於 2.61,只需要找出長度短於 $\sqrt{34}$ 的向量就可以了(在圖中以紫色的圓圈標註了其範圍)。比如說,$\mathbf{u}’=(2,-4)$ 的長度是 $\sqrt{20}$ ,是這個近似 SVP 的解,但不是標準 SVP 的解。*
短整數解
雖然可以直接基於格假設來構造密碼系統(比如說,Hawk 就是這樣做的),但一般來說,我們使用另一種假設(它可以規約為格假設)。最著名的例子是 “短整數解(SIS)” 和 “帶錯誤學習(LWE)”。出於本文的目的,我們只講前者。
假設有線性方程 $\mathbf{Ax}=0$,其中 $\mathbf{A} \in \mathbb{Z}q^{n \times m}$ ($A$ 是一個 $n \times m$ 的整數矩陣)。求出這個等式的解,是容易的(例如,通過 “高斯消元法(Gaussian elimination)”)。但是,假設我們還要求解 $\mathbf{x} \in \mathbb{Z}^m$ 是 “短的”,即 $|\mathbf{x}|{\infty} < \beta$ (其中 $|\mathbf{x}|{\infty} := \min{i \in [m]}|x_i|$ ,是 $\mathbf{x}$ 的 $\ell^{\infty}$ 範數值),且 $\beta \ll q$ ,這就成了短整數解問題的一個實例,記作 $\mathsf{SIS}_{q,n,m,\beta}$ ;並且,在精心挑選的 $q,n,m,\beta$ 之下,它甚至對量子計算機也非常非常難。
(譯者注:不知為何,作者在這裡使用的 $\ell^{\infty}$ 範數的定義似乎與常見定義不同,常見定義是取元素的最大值,從而短整數解的要求是向量在任一維度上的值都小於 $\beta$ 。)
習題 1. 證明只要 $m>\frac{n\log q}{\log(1+\beta)}$ , $\mathsf{SIS}_{q,n,m,\beta}$ 就存在解。
此外,我們用 $S_{\eta}$ 來表示 “短” 向量的集合,也即:
$$
\begin{equation*}
S_{\eta} := {\mathbf{x} \in \mathbb{Z}^n: |\mathbf{x}|_{\infty} \leq \eta}.
\end{equation*}
$$
非齊次 SIS
這一假設的一個重要微調是考慮同一等式的非齊次版本(non-homogeneous version):$\mathbf{Ax}=\mathbf{t}$ 。這個修改允許我們考慮決定性假設,而不是搜索假設。具體來說,我們引入 “非其次短整數解(ISIS)” 假設,聲稱區分下面兩種分佈 $D_0$ 和 $D_1$ 是計算難題:
- $D_0$:從 $\mathbb{Z}_q^{n \times m} \times \mathbb{Z}_q^n$ 中隨機選出一個樣本
- $D_1$:隨機採樣 $A \gets_R \mathbb{Z}q^{n \times m}$ ,採樣一個短的向量 $\mathbf{s} \in \mathbb{Z}^m$(即 $|\mathbf{s}|{\infty} < \delta$ ),計算 $\mathbf{t} \gets \mathbf{As}$ ,然後輸出元組 $(\mathbf{A}, \mathbf{t})$ 。
我們可以證明,當背後的 $\beta$ 和 $\delta$ 有適當的關聯時,ISIS 等價於 SIS 。這個假設允許我們開發出以下密鑰生成方法:
- 私鑰 是矩陣 $\mathbf{S} \in S_{\eta}^{m \times k}$ ,由短元素組成。
- 公鑰 是 $\mathbf{T} := \mathbf{AS}$ ,其中 $\mathbf{A} \in \mathbb{Z}_q^{n \times m}$ 是隨機採樣出來的。
習題 2. 證明從公鑰復原私鑰的問題等價求解 ISIS(假設 $k=\mathsf{poly}(n)$ )。
與格的關聯
你可能會想:說好的格呢?這跟格有啥關係?能塞進這篇博客的一種解釋是:對於矩陣 $\mathbf{A}$ 的 $\mathsf{SIS}_{q,n,m,\beta}$ 實例,可以定義出這樣的格:
$$
\begin{equation*}
\Lambda_A^{\perp} = {\mathbf{z} \in \mathbb{Z}^m: \mathbf{Az} = 0 ; (\text{mod} ; q)}.
\end{equation*}
$$
洞見:求解 $\mathsf{SIS}_{q,n,m,\beta}$ 等價於求解恰當 $\gamma$ 下的 $\gamma$-SVP 。這從 $\Lambda_A^{\perp}$ 的定義中就能看出來:這個格中的任何一個向量,都是 $\mathbf{A}\mathbf{x}=0$ 的解;如果我們從想求解這個格的 SVP,本質上就是在尋找這個等式的短整數解,這正好就是 SIS 的要求。
帶中止的 Fiat-Shamir 變換
動機
我們已經看到了,基於格的假設使我們可以為公開的矩陣 $\mathbf{A}$ 和一個 “短” 矩陣 $\mathbf{S}$ 構造出單向的映射 $\mathbf{S} \mapsto \mathbf{AS}$ 。這有點類似於在一個循環群 $\mathbb{G}=\langle a \rangle$ 中,映射 $s \mapsto a^s$ 也是單向的,只要離散對數假設成立。這引導我們問出這樣一個問題:
我們能否 “重新創造” 出 Schnorr 簽名協議,之補充不用群乘法映射 $s \mapsto a^s$ ,而使用 $\mathbf{S} \mapsto \mathbf{A}\mathbf{S}$ ?
可以證明,答案是可以!只不過並不像看起來那麼簡單,這也是 “帶中止的” 這個前綴的來源。在本節中,我們會看看如何讓這種想法成真。
Schnorr 簽名方案
事不宜遲,我們先回顧 Schnorr 簽名是怎麼工作的。描述一個簽名方案意味著定義以下三種程序:
- $\mathsf{KeyGen}(1^{\lambda}) \to (\mathsf{pk}, \mathsf{sk})$ :生成密鑰對;
- $\mathsf{Sign}(\mathsf{sk},\mu) \to \mathsf{sig}$ :使用私鑰 sk 簽名消息 $\mu$ ,從而產生簽名 sig ;
- $\mathsf{Verify}(\mathsf{pk},\mu,\mathsf{sig}) \to {0,1}$ :基於公鑰 pk 和消息 $\mu$ ,驗證簽名 sig 。
Schnorr 簽名可以說是離散對數假設之上的最優雅、高效和簡單的簽名方案,現在已經在比特幣上得到積極應用。不過,我們最好還是從 Schnorr 身份鑑別協議 開始。具體來說,假設一個 q 階的群 $\mathbb{G}$ ,是由 $g \in \mathbb{G}$ 生成的;然後,為了證明簽名人知道對應於公鑰 $h \in \mathbb{G}$(其中 $g^{\alpha}=h$)的私鑰 $\alpha$ ,他參與如下的交互式協議:

*圖 3. Schnorr 身份識別協議,基於密鑰對 $(\alpha,h)$(其中 $h=g^{\alpha}$*)
(譯者注:交互的過程是:簽名人取出隨機數 r,將其在群上的對應值 a 發給驗證者;驗證者取出隨機數 e 發給簽名人;簽名人用 r 和 e 以及私鑰計算 z,交給驗證者。)
Fiat-Shamir 變換 允許簽名人通過使用哈希函數 $\mathsf{H}: \mathbb{G}^2 \to \mathbb{Z}_q$ 派生出 $e$ 來避免與驗證者交互。具體來說,簽名人計算挑戰值 $e \gets \mathsf{H}(h,a)$ ,這就產生了 “證據” $(e,z)$ 。最後,想要開發出 簽名方案,可以把消息 $\mu$ 也放進挑戰值 $e$ 的推導中。所以,$\mathsf{Sign}(h,\mu)$ 是這樣的:
- 為隨機的掩飾標量 $r \gets_R \mathbb{Z}_q$ 構造承諾 $g^r$ ,與上面的身份識別協議一樣;
- 計算出挑戰值 $e \gets \mathsf{H}(\mu,a)$ ;
- 計算標量 $z=r+\alpha e$ ,它遮掩了底層的秘密值 $\alpha$ ;輸出 $(e,z)$ 作為一個簽名 。
最後,驗證者檢查通過 $e=_?\mathsf{H}(\mu, g^zh^{-e})$ 來檢查簽名 $(h,\mu,\sigma)$ 。
嘗試 #1:“格” Schnorr 簽名
因為我們已經發現 $\mathbf{S} \mapsto \mathbf{AS}$ 看起來很像前量子的同類 $\alpha \mapsto g^{\alpha}$ ,所以,我們試試直接把這個單向映射放到 Schnorr 身份識別協議中,如 圖 4 所示。沿著前面提到的思路,這種嘗試是自然而然的第一步(我們將 r、a 和 e 立體化,這樣矩陣乘法就有了意義):
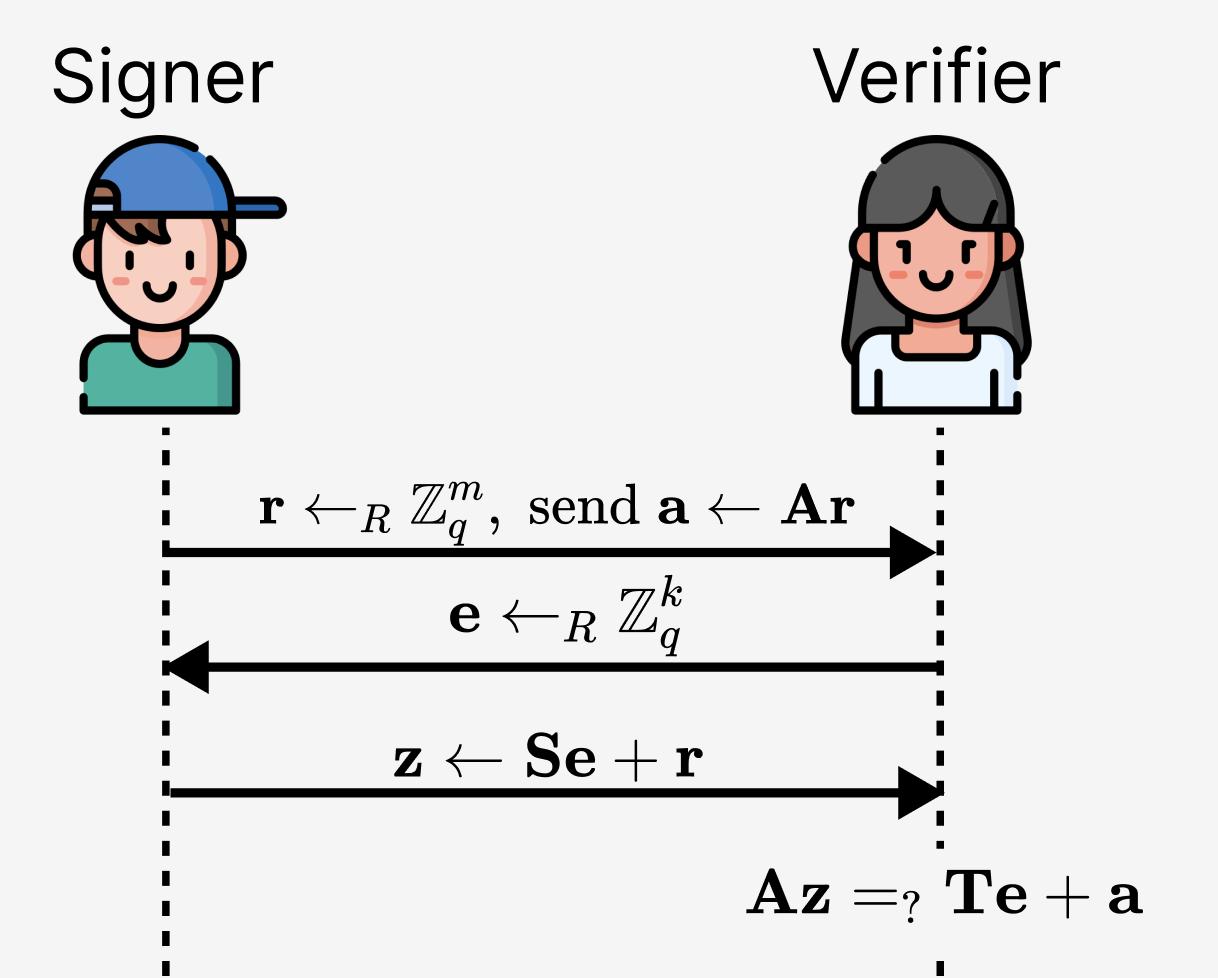
圖 4. “格” Schnorr 身份識別協議的第一次嘗試,密鑰對為 $(\mathbf{S},\mathbf{T})$( $\mathbf{T}=\mathbf{AS}$,其中 $\mathbf{T} \in \mathbb{Z}_q^{n \times k}$ 、$\mathbf{A} \in \mathbb{Z}_q^{n \times m}$ 且 $\mathbf{S} \in \mathbb{Z}_q^{m \times k}$ )。
首先,這個方案在形式上正確嗎?我們把所有東西都代入驗證等式裡看看:
$$
\begin{equation*}
\mathbf{Az} = \mathbf{A}(\mathbf{S}\mathbf{e}+\mathbf{r}) = (\mathbf{AS})\mathbf{e}+(\mathbf{A}\mathbf{r}) = \mathbf{Te}+\mathbf{a}.
\end{equation*}
$$
因此,這個方案是形式正確的。但它可靠嗎?完全不行。你可以找出這個方案失敗的許多情形。比如說:
- 給定 $\mathbf{a} \in \mathbb{Z}_q$ ,很容易從承諾等式 $\mathbf{a}=\mathbf{Ar}$ 中找出 r 。實際上,這只是在 $\mathbb{Z}_q$ 上求解線性方程。
- 即使假設承諾 a 是綁定的,找出能夠滿足方程 $\mathbf{Az}=\mathbf{Te}+\mathbf{a}$ 的 z 也是可以做到的,哪怕你不知道私鑰 S 。再說一次,這只是在得到任意的 e 之後求解線性方程。
看起來,我們在這一點上卡住了。
嘗試 #2:縮小一切
注意,“嘗試 #1” 是不安全的,因為我們很容易就可以偽造 z ,並且很容易就能從 r 中找回 a 。因為它們只是這些線性方程所對應的系統的 隨意 的解。如我們在 SIS 假設中看到的,我們要讓 z 和 r 都 “短”,才能修復這個協議的可靠性。所以這次嘗試我們就以此為目標。我們將從一些 短 分佈 $\chi^m$ 中隨機採樣 r(設想在 $\mathbb{Z}q$ 上有一些概率分佈 $\chi$ ,從中採樣出來的一個值的 $\ell^{\infty}$ 範數值會限制在較小的 $\varepsilon \in \mathbb{Z}{>0}$ 內)。讓 z(以及 $\mathbf{r}+\mathbf{Se}$ )變短會更難一些:雖然現在 r 已經是短的了,我們還要保證 Se 也是短的。結果是,因為 S 已經是小的值,我們需要保證 e 既是短的,e 的可能取值集合 又 足夠大。具體來說,我們將從集合 $B_{\kappa}$ 中採樣:
$$
\begin{equation*}
B_{\kappa} := {\mathbf{x} \in \mathbb{Z}_q^k: x_i \in {0,\pm 1} ; \text{且非零的 $x_i$ 的數量是 $\kappa$}}.
\end{equation*}
$$
誠實地說,這個集合完全是憑空出現的(就像基於格的密碼學中的許多東西一樣)。使用這個集合的理由大概是這樣的:
- 我們希望挑戰值的集合足夠大;這個集合符合這個條件(見下文的 習題 3 );
- 我們希望這個挑戰值集合中的元素都足夠小;顯然這個也符合,因為對於每一個 $\mathbf{e} \in B_{\kappa}$ ,都有 $|\mathbf{e}|_{\infty}=1$ ;
- 最好,我們希望哈希成 $B_{\kappa}$ 的實現儘可能簡單:這個也成立,因為 $B_{\kappa}$ 中的元素可以視為一種三元字符串(ternary string)。
習題 3. 證明挑戰值集合 $B_{\kappa}$ 的兩種屬性:(a)$#B_{\kappa}=2^{\kappa}\binom{k}{\kappa}$ (即,這個集合非常大);(b)對於任意的 $\mathbf{S} \in S_{\eta}^{m \times k}$ ,我們有 $|\mathbf{Se}|_{2} \leq \eta\kappa\sqrt{m}$ ,其中 $|\cdot|_2$ 表示標準的歐幾里得範數(即,對於要進入 z 的計算的 Se 的範數值,我們有很好的邊界)。
現在,因為 e 和 r 都是短的,所以 z 也是短的。因此,為了防止敵手發送較大的的 e 和 r,我們需要檢查 $|\mathbf{z}|2$ 足夠小(即,小於某個閾值 $\tau$ ;你可以理解為 $\tau:=\max{\mathbf{e} \in B_{\kappa}}|\mathbf{Se}|2 + \mathbb{E}{\mathbf{r} \sim \chi^m}[|\mathbf{r}|_2]$ ,但這跟我們當前這個層面的討論無關)。
有了這些修改,我們的第二次嘗試是這樣的:
圖 5. “格” Schnorr 身份識別協議的第二次嘗試,密鑰對為 $(\mathbf{S},\mathbf{T})$( $\mathbf{T}=\mathbf{AS}$,其中 $\mathbf{T} \in \mathbb{Z}_q^{n \times k}$ 、$\mathbf{A} \in \mathbb{Z}_q^{n \times m}$ 且 $\mathbf{S} \in \mathbb{Z}_q^{m \times k}$ )。
這個方案正確嗎?是的,理由跟 “嘗試 #1”一樣。
那它可靠嗎?嗯哼,我們來看看一些 “簡單” 的攻擊:
- 我們能找出短的 r 使得 $\mathbf{Ar}=\mathbf{a}$ 嗎?者等價於求解 ISIS,因此似乎在計算上是不可行的。
- 那我們能找出短的 z 使得 $\mathbf{Az}=\mathbf{Te}+\mathbf{a}$ 嗎?(即,在不知道 S 的前提下)再一次,這是 ISIS 問題的實例,也是難以求解的。
所以 …… 現在我們能說這個方案是可靠的了嗎?
不行! :- (
不過,其中的理由非常地微妙,而且在證明安全性的過程中會更容易發現。這裡是一個簡單的解釋:回顧一下,計算 z 的全部用意在於 “遮掩” 背後的秘密值 S 。但是,我們能說 z 和 S 是相互獨立的嗎?不見得。
注:
如果你在嘗試回憶 Schnorr 簽名的安全證明,以下解釋可能更讓你滿意:回憶一下,EUF-CMA(選擇明文攻擊下存在性不可偽造)的證明由兩部分組成:(a)模擬誠實簽名人;(b)使用 “分叉引理(forking lemma)” 來抽取背後的秘密值。在 圖 5 中,完全不清楚該如何執行(a):具體來說,就是從哪裡取樣 z 。即使我們知道 z 的分佈,它也可能取決於 S ,這就會讓模擬出問題。
出於這個理由,我們需要讓 z 和 S 是相互獨立的。但要怎麼做呢?可以證明這樣一種想法會有用處:
在生成一對候選的 $(\mathbf{e},\mathbf{z})$ 之時,先檢查得到的 z 是不是 “足夠好”。如果不是,那就丟掉它,再來一遍簽名流程。
這就是這個範式叫做 “拒絕採樣”或者 “帶中止的 Fiat-Shamir 變換” 的原因:如果我們對生成的數值不滿意,就中止簽名流程的執行。但是,對於 z 來說,怎樣才算 “足夠好”?為此,我們要選出一種具體的分佈 $\chi$ ,要求它能產生一些有用的屬性,然後看什麼時候,z 和 S 的統計距離(statistical distance)是可以忽略的。
離散高斯分佈
如果你覺得挑戰值空間 $B_{\kappa}$ 的選擇是隨意的,那麼我要說,這才是我開始學習基於格的電子簽名時真正覺得 完全 隨意的東西。引入在格 $\Lambda \subseteq \mathbb{R}^m$ 上的高斯分佈 $\Lambda \subseteq \mathbb{R}^m$ ,其寬度參數(標準差)為 $\sigma \in \mathbb{R}{>0}$ ,平均值為 $\mathbf{v} \in \mathbb{R}^m$ ,如下:
$$
\begin{equation*}
D{\mathbf{v},\sigma,\Lambda}^m(\mathbf{z}) := \rho_{\mathbf{v},\sigma}^m(\mathbf{z})/\rho_{\mathbf{v},\sigma}^m(\Lambda) ; \text{其中} ; \rho_{\mathbf{v},\sigma}^m(\mathbf{z}) := \exp(-|\mathbf{z}-\mathbf{v}|_2^2/2\sigma^2).
\end{equation*}
$$
(譯者注:“高斯分佈” 即 “正態分佈”。)
這裡,我們要濫用記號,用 $\rho_{\sigma}^m(\Omega)=\sum_{\mathbf{w} \in \Omega}\rho_{\sigma}^m(\mathbf{w})$ 來表示一個離散集合 $\Omega \subseteq \mathbb{R}^m$ 上的分佈。我們在索引中省略了 $\Lambda$ 和 $\mathbf{v}$ ,當它們分別是 $\Lambda=\mathbb{Z}^m$ 和 $\mathbf{v}=0$ 的時候。
想必這個定義需要一些解釋。這裡的關鍵想法是,我們想讓在格 $\Lambda$ 上的每一個點 z 出現的概率與 $\exp(-|\mathbf{z}-\mathbf{v}|2^2/2\sigma^2)$ 成比例。為了將它變成一種有效的概率分佈,我們需要將所有的概率除以一個歸一化常數(normalization constant)$\sum{\mathbf{w} \in \Lambda}\exp(-|\mathbf{w}-\mathbf{v}|_2^2/2\sigma^2)$ 。
原理上,之所以得名 “離散 高斯分佈”,正是因為它與連續的高斯分佈非常相似(它們的密度為 $e^{-|\mathbf{z}-\mathbf{v}|^2/2\sigma^2}/\int_{\mathbb{R}^m}e^{-|\mathbf{z}-\mathbf{v}|^2/2\sigma^2}\text{d}\mathbf{z}$ ;在連續分佈中,分母中的積分是容易計算的)。此外,如果你看過這種分佈的形狀,那馬上就會認出這是標準的多元高斯分佈:
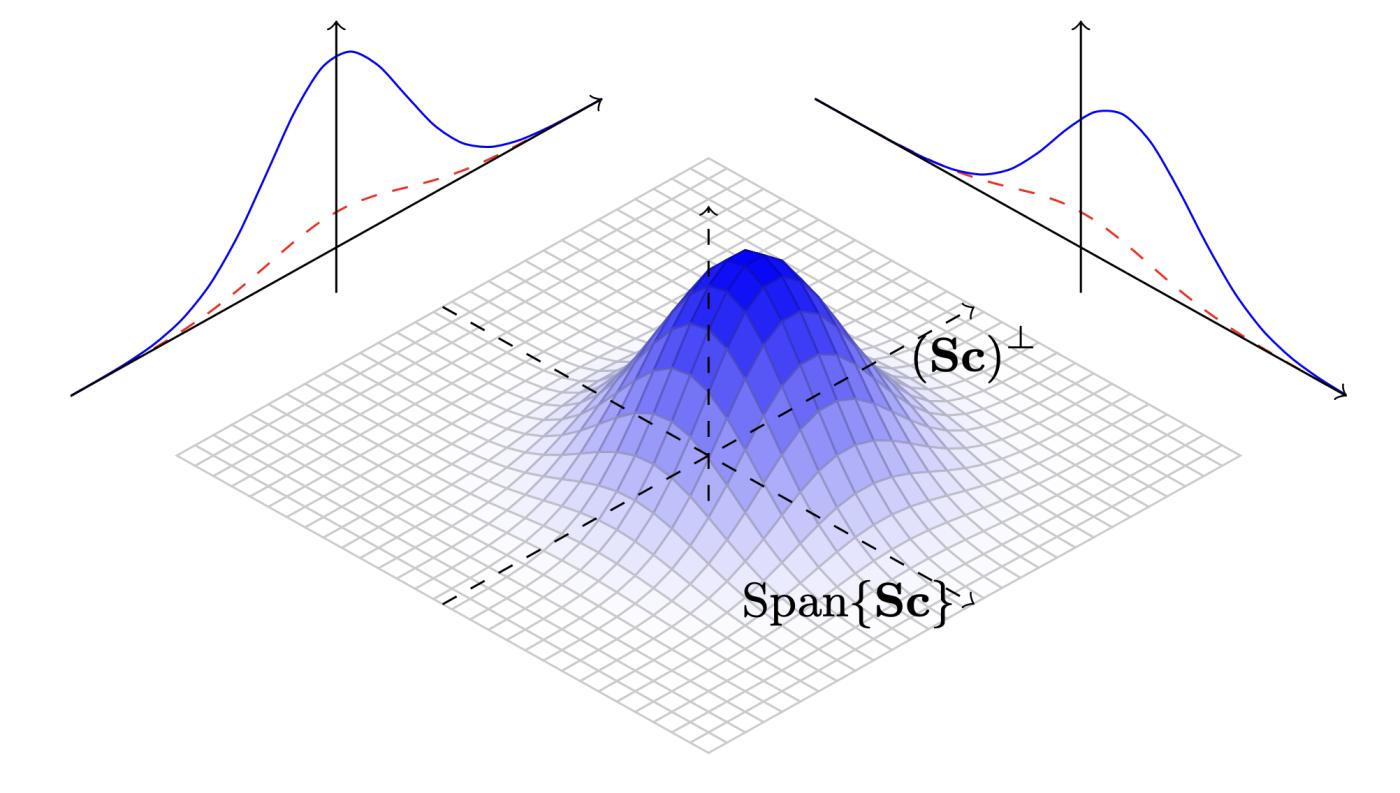
圖 6. 2D 的離散高斯分佈。圖片取自論文《 Lattice Signatures and Bimodal Gaussians》,作者是 Ducas、Durmus、Lepoint 和 Lyubashevsky 。
為什麼要使用離散高斯分佈?
我認為,“為什麼要選擇這種具體的分佈” 的答案,就類似於問為什麼要在統計學中使用連續高斯分佈。這是一種自然而然地選擇,因為,它在多種操作下都有良好的屬性(例如,可以運行傅里葉變換(Fourier transform)和卷積(convolutions);離散高斯分佈之和在統計上接近於單個離散高斯分佈,等等)。
不過,在我們的問題(讓 z 和 S 在概率上獨立)中,我們需要的是離散高斯分佈的兩種屬性。
屬性(A)(從 $D_{\sigma}^m$ 中採樣出短向量的概率是壓倒性高的 )。對於任何 $\beta>1$ ,都有:
$$
\begin{equation*}
\text{Pr}[|\mathbf{z}|2>\beta\sigma\sqrt{m} ; | ; \mathbf{z} \gets_R D{\sigma}^m] < \beta^me^{m(1-\beta^2)/2}.
\end{equation*}
$$
*屬性(B)(中心高斯分佈和非中心高斯分佈的比值幾乎總是有界的* )對於任何 $\mathbf{v} \in \mathbb{Z}^m$ ,只要 $\sigma=\alpha|\mathbf{v}|$ ,就有:
$$
\begin{equation}
\text{Pr}[D_{\sigma}^m(\mathbf{z})/D_{\mathbf{v},\sigma}^m(\mathbf{z}) < e^{12/\alpha+1/(2\alpha^2)} ; | ; \mathbf{z} \gets_R D_{\sigma}^m] > 1 - 2^{-100}.
\end{equation}
$$
這兩種屬性的證明都要用到大量數學。見,例如 Lyubashevsky 的原創論文第四章。我們將進一步用 $M_{\alpha}$ 來表示這個 “魔法” 常量 $e^{12/\alpha+1/(2\alpha^2)}$ 。
習題 4. 假設 $\alpha>1$ ,問 $M_{\alpha}$ 的可能範圍?
雖然我認為 屬性(A) 是符合直覺的(我們將在稍微超過 1.0 的 $\beta$ 上使用它),你可能還是會好奇,為什麼我們需要 屬性(B)?接下來這一節就要解釋它。
拒絕採樣
現在,我們設 圖 6 中的 $\chi^m := D_{\sigma}^m$ 。那麼 z 具體是如何分佈的?因為 $\mathbf{z}=\mathbf{Se}+\mathbf{r}$ ,且 $\mathbf{r} \sim D_{\sigma}^m$ 是中心離散高斯分佈,所以 z 將是 “有偏的(biased)” 高斯分佈 $D_{\mathbf{Se},\sigma}^m$ ,帶有一個小小的偏移向量為 Se 。
這就是為繁體所在:z 的分佈依賴於小小的偏移量 Se ;因此,通過觀察使用同一個 S 的多個 z,敵手就有可能獲得關於 S 的信息。
要是我們能夠消除這個偏移量就好了 …… 那麼下面這個引理就來救場了:
引理. 令 $f$ 和 $g$ 為兩種概率分佈,其所有可能取值的集合(support)為 $\Omega$ ;對於所有的 $z \in \Omega$ 和一些固定的常量 $M \in \mathbb{R}_{\geq 1}$ ,滿足 $f(z) \leq Mg(z)$ 。那麼,以下這種分佈(稱為 $\widetilde{f}$ )跟分佈 $f$ 是一樣的:
- 隨機採樣 $z \gets_R g$ 。
- 以概率 $f(z)/Mg(z)$ 輸出 $z$ ,否則回到步驟 1 。
基本上,這個引理的想法是,如果 $f$ 就是我們的 “目標分佈”,而 $g$ 是 “真實分佈”,那麼只要在 $f$ 和 $g$ 的各點之間有一個良好的不等式,我們就能通過拋棄來自 $g$ 中的一些樣本來模擬 $f$ 的分佈,並且是以獨立於所採樣的值的概率。
這個過程有一個很好的視覺表示如挼下(跟 圖 7 一樣,取自 BLISS 論文,真的是非常好的圖示)。假設 $f$ 和 $g$ 滿足引理中的不等式,那麼 $Mg$ 就會高出 $f$ 。然後,用兩步形成拒絕採樣:先從 $Mg$ 中選出點;然後,如果它低於 $f$ ,就接受它。
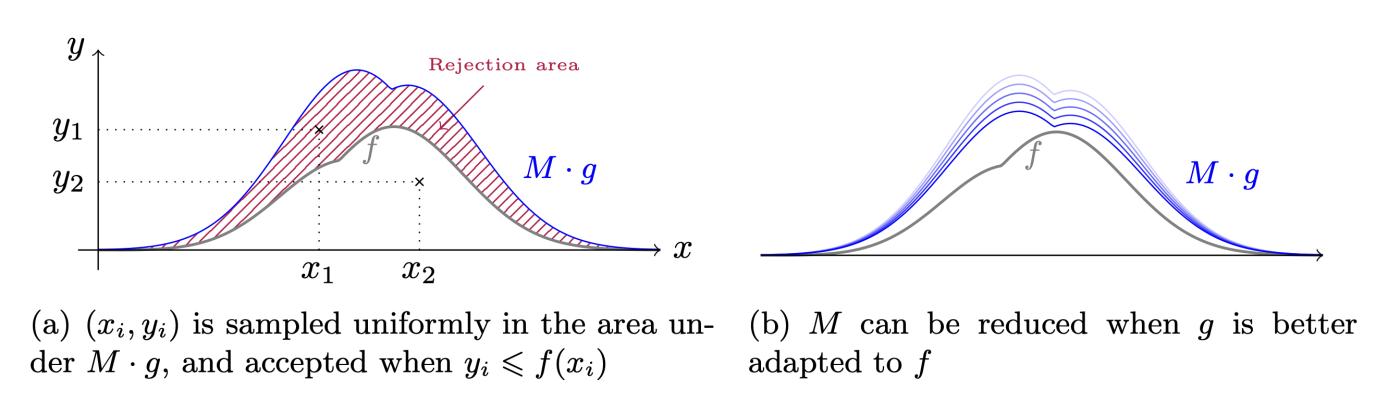
圖 7. 拒絕採樣流程演示。圖片取自論文《 Lattice Signatures and Bimodal Gaussians》,作者是 Ducas、Durmus、Lepoint 和 Lyubashevsky 。
這個引理有沒有讓你想起一些事情?關鍵技巧是這樣應用這個引理:
- 我們的 “目標” 分佈 $f$ 是無偏的(unbiased)離散高斯分佈 $D_{\sigma}^m$ ;
- 我們的 “真實” 分佈 $g$ 是有偏的高斯分佈 $D_{\mathbf{Se},\sigma}^m$ 。
我們能不能應用這個引理?屬性(B) 正是關鍵所在:我們有一個魔法常量 $M_{\alpha}$ 使得 $D_{\sigma}^m(\mathbf{z}) \leq M_{\alpha}D_{\mathbf{Se},\sigma}^m$ 以壓倒性的概率成立!(而且,我們容易可以從 $|\mathbf{Se}|_2 \leq \eta\kappa\sqrt{m}$ 這個事實中確認 $\alpha$ :見 習題 3 )。
警告
小心駛得萬年船,引理必須被調整的使不等式 $f(z) \leq Mg(z)$ 以壓倒性的概率 $1-\varepsilon$ 出現。然後,我們可以證明,在這種情況下,分佈 $\widetilde{f}$ 與分佈 $f$ 的統計距離將是 $\varepsilon/M$ 。
嘗試 #3:Lyubashevsky 簽名
最後,為了修復 圖 2 中的方案,我們只以概率 $D_{\sigma}^m(\mathbf{z})/M_{\alpha}D_{\mathbf{Se},\sigma}(\mathbf{z})$ 接受 $(\mathbf{e},\mathbf{z})$ 。這就修復了整個方案,見下圖。
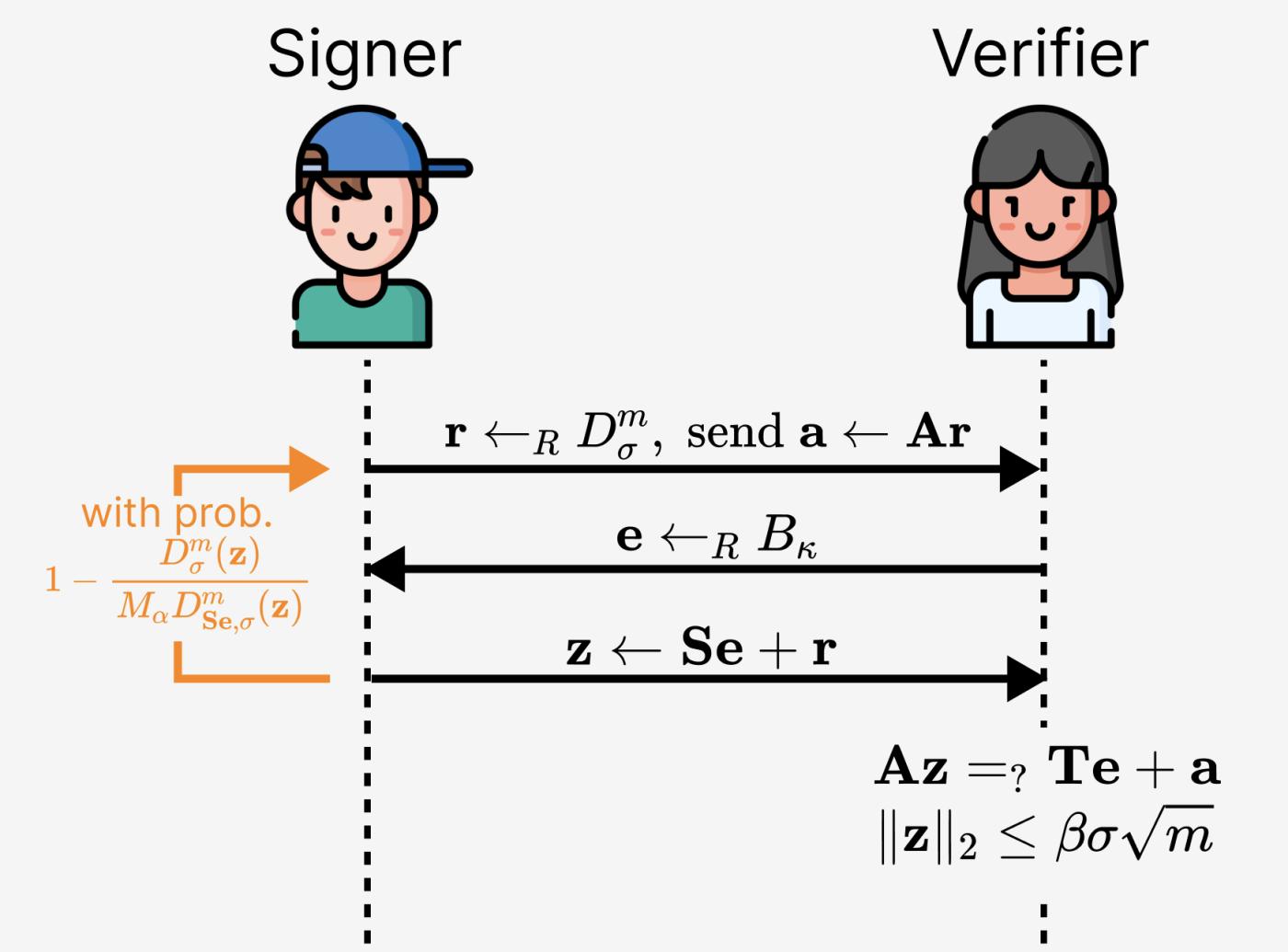
圖 8. 修復基於格的 Schnorr 協議(本質上就是來自 Lyubashevsky 論文的原創方案)。
安全證明骨架*
注:
以下部分可讀可不讀。
回憶一下,為了證明一個簽名方案是安全的,我們需要(a)模擬一個誠實的簽名人;以及(b)使用分叉引理來抽取一些難以計算的問題的實例的解。
步驟 (a) 是拒絕採樣引理的一種簡單應用:我們不是直接採樣 $\mathbf{r} \gets_R D_{\sigma}^m$ 、計算挑戰值 $\mathbf{e} \gets \mathsf{H}(A\mathbf{r}, \mu) \in B_{\kappa}$ 、輸出候選 $(\mathbf{e}, \mathbf{z}:=\mathbf{Se}+\mathbf{r})$ ,而是先採樣 $\mathbf{z} \gets_R D_{\sigma}^m$ 和 $\mathbf{e} \gets_R B_{\kappa}$ ,並將隨機斷言機(random oracle)重新編程為 $\mathsf{H}(\mathbf{Az}-\mathbf{Te},\mu) \gets \mathbf{e}$ 。
步驟 (b) 假設敵手可以按不可忽視的概率 $\delta$ 輸出一個有效的簽名 $(\mathbf{z},\mathbf{e})$ ,根據分叉引理,TA 可以按概率 $\propto \delta^2$ 輸出另一個有效的簽名 $(\mathbf{z}^*,\mathbf{e}^*)$ 。並且,背後的隨機性是一樣的,即:
$$
\begin{equation*}
\mathbf{Az} - \mathbf{Te} = \mathbf{Az}^*-\mathbf{Te}^*.
\end{equation*}
$$
使用事實 $\mathbf{T}=\mathbf{AS}$ ,可以得到
$$
\begin{equation*}
\mathbf{A}((\mathbf{z}-\mathbf{z}^*)+\mathbf{S}(\mathbf{e}^*-\mathbf{e})) = 0,
\end{equation*}
$$
其中 $(\mathbf{z}-\mathbf{z}^*)+\mathbf{S}(\mathbf{e}^*-\mathbf{e})$ 是線性方程 $\mathbf{Ax}=0$ 的一個短的解。因此,我們構造出了一種歸約,將簽名解釋為求解一個近似的 SIS 實例。
性能
坦白說,前述方案是非常低效的。在原版論文提出的參數下,簽名的體積是 19.9KB ,而公鑰的體積是 128KB 。不過,上面展示的想法在許多方面都可以優化。尤其是:
幾乎所有簽名都不使用 $\mathbb{Z}_q$ ,而是使用環 $\mathcal{R}_q := \mathbb{Z}_q[X]/(X^d+1)$ ,其中 $d$ 是 2 的冪。這個環之所以高效的理由就超出本文的範圍了。
可以選擇不同於離散高斯分佈的另一種分佈。比如說 BLISS 簽名方案提出雙峰高斯分佈,其它方面則幾乎原樣照搬上述構造。得到的簽名體積是 5.6KB ,公鑰體積是 7KB 。不幸的是,這套方案被證明在側信道攻擊下不安全
如果我們將離散高斯分佈改成一種均勻分佈,就得到了 Dilithium 方案。不過,可以預料,拒絕採樣的思路將有很大不同(在一定意義上是簡化了)。
下一步
在本文中,我們分析了基於格的電子簽名方案的一種關鍵範式: 帶中止的 Fiat-Shamir 變換。雖然它出現在許多構造中(並且被大多數論文暗中使用),還有一種範式叫做 “先哈希後簽名(Hash-and-sign)”是理解 Falcon 和 Hawk 的前提。這些方案直接利用了格的及合約:先把消息 $\mu$ 哈希成 $\mathbb{Z}^{2n}$ 上的點,然後使用格的一些秘密幾何特徵來轉化這個點(在 Hawk 上,私鑰是具體的格的短的基向量(basis) B,而公鑰是其平方形式 $\mathbf{B}^{\top}\mathbf{B}$ ;在 Falcon 上,公鑰是格的基,而私鑰是其正交格的基。
這些方向持續吸引著學術界和產業界的注意力,這也不無道理。我們正在主動探索這些想法,未來的博文也會回到這些想法上。
(完)


