注:本文來自@BlazingKevin_ 推特,MarsBit整理如下:
1/ Arweave 2.6版本已釋出,將在3月6號完成硬分叉升級,主題圍繞如何降低能源消耗,並提升儲存激勵。
Arweave上一次重要升級要回溯到21年2月的2.4版本,完成了SPoA到SPoRA的升級,激勵礦工提高對資料的訪問速度。
在Arweave迎來又一次重大升級之際,本文將回顧此前的歷次升級,讓大家有更充分的瞭解
2/ Arweave 1.5(2018年10月 主網上線)
上線時的weave size只有177Mi,這個部分我會介紹Arweave網路中的一些特有名詞,這裡我們遇到了第一次名詞是區塊坊(block weave)。
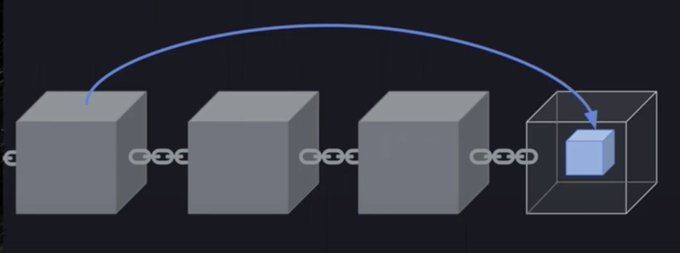
區塊坊是Arweave網路的區塊結構,和普通區塊鏈一前一後的連線方式不同。
3/ Arweave 的資料結構並不是嚴格的單鏈列表而是複雜一點的圖結構,結構中每個區塊一共與三個區塊相關,當前塊的前一個和後一個塊以及隨機的指向一個之前的塊稱為回憶區塊 (recall block/recall chunk),由此構成區塊紡(摘自Arweave黃皮書)。
4/ 回憶區塊是根據前一個塊的雜湊和高度確定的,密碼學原理保證了回憶區塊在選定時既有確定又不可預測。
此時Arweave的效能如下:

5/ 和PoW以及PoS的挖礦機制不同,Arweave的挖礦機制是訪問證明(Proof of Access)。 在早期的Arweave中,訪問證明是指礦工為了獲得打包新區塊的權利,必須證明他能夠訪問歷史區塊的資料,也就是說礦工必須儲存歷史資料。
6/ 實際工作中,每當一個新區塊產生時,PoA會隨機挑選一個歷史區塊作為回憶區塊,並要求礦工將回憶區塊放入新區塊當中。
7/ 因此,在 Arweave 網路中不存在存在全節點和輕節點概念,新礦工加入網路後只需要從儲存新塊和會議區塊開始,而不必儲存所有的歷史區塊。礦工之間儲存的副本(回憶區塊)數量也是不同的。
8/ PoA共識要求礦工必須儲存回憶區塊,但不要求礦工儲存全部歷史資料。前文圖中,我們看到Arweave的區塊時間是2分鐘。在這兩分鐘裡,還進行著激烈的PoW競爭,是的,在Arweave中工作量證明被包含在了PoA共識當中。
9/ 兩分鐘的挖礦過程可以被分為兩個部分,第一個部分我們已經瞭解,就是訪問證明。當新區塊到來時,在2分鐘的時間裡,PoA共識會隨機選擇一個歷史區塊作為回憶區塊,對回憶區塊擁有訪問路徑的礦工才有資格進入第二部分的工作量證明競爭中,如果一個礦工沒有儲存回憶區塊,他可以向附近的礦工傳送申請。
10/ 即時儲存這個回憶區塊並以落後的速度進入工作量證明中。從這裡可以看出,礦工同步的歷史區塊越多,同步的稀有區塊越多,通過第一部分要求的可能性就越大,Arweave巧妙地將對歷史資料的儲存從要求變成了激勵。在第一部分中,擁有回憶區塊的礦工們會進入工作量證明。
11/ 在1.5版本的Arweave中,工作量證明是純粹的雜湊算力比拼:消耗資源,堆積硬體。礦工們朝著兩分鐘的終點線瘋狂計算,當兩分鐘時間截止時,計算量最高的礦工獲勝。下一個區塊的競爭重新開始。
12/ 這種PoA設計出現了一個問題,由於礦工能在第一部分時向附近礦工下載回憶區塊,因此很多礦工選擇不儲存歷史區塊,而是堆積大量gpu硬體來平行計算。這樣一來即使稍微落後進入第二部分,依然能依靠大量算力反敗為勝。
13/ 這種策略逐漸變成主流,礦工們放棄對於歷史資料的儲存,放棄對於副本的快速訪問,而選擇堆積算力。這種策略導致的結果是,歷史資料會逐漸中心化,整個網路的資源消耗會爆發式增長。
最初的Arweave網路設計具有缺陷,沒有限制對於gpu的堆砌。在2019年6月,Arweave推出了1.7版本。
14/ Arweave 1.7(2019年6月 Random X)
為了限制礦工瘋狂堆積gpu的行為,在1.7版本中,Arweave推出Random X。Random X是一個雜湊方程式,特點是很難在gpu或者Asics上執行。礦工無法堆積gpu挖礦後,只能依靠單一cpu來完成工作量證明,減少了能源消耗。
15/ Arweave上沒有全節點這個概念,也就是說礦工之間不必維護共識,那麼當使用者傳送一筆交易時,礦工們會互相分享同步嗎?答案是會的,試想我是一名礦工,我必定希望挖出新塊時能獲得最大的收益,當我收到使用者交易時,我會選擇將交易傳播給網路中的其他礦工,如此一來,其他礦工也會將各自收到交易同步
16/ 我們可以將其看作一種激勵措施,如果礦工們互相不分享交易,那麼獲勝礦工打包的區塊中交易數量會減少,使用者體驗下降後,網路陷入死亡螺旋。為了收益,礦工們會積極同步交易。
17/ Arweave是一個儲存網路,和普通區塊鏈不同,一筆交易最高有5.8MB。礦工們需要在兩分鐘的時間內同步所有的交易,並完成工作量證明,這對交易的傳輸速度提出了要求。
18/ 同時Arweave網路的可拓展性也受到了限制,礦工們需要儘可能確保在第一部分時完成對回憶區塊的訪問或下載,以及同步使用者的新交易,否則在第二部分工作量證明中,礦工們不能處於同一起跑線。Arweave的網路發展遇到交易傳輸速度的瓶頸(transmission bottlenecks)。
19/ Arweave 1.8(2019年10月 交易最大size翻倍到10MB)
5.8MB的大小對於普通交易綽綽有餘,但是對於儲存網路來說還是太小,有時甚至無法容納一張圖片,更不用說音訊和視訊。在2019年10月,Arweave將單筆交易的最大容量提升到10MB。
20/ 但是交易傳輸的瓶頸還是沒有解決,Arweave的終極目標是儲存人類歷史,成為現代的亞歷山大圖書館。為了達到這個終點,Arweave必須解決可拓展性的問題。Arweave是一個分散式網路架構,礦工分散在全球不同地區。客觀上,礦工使用的硬體和擁有的網路條件各不相同,無法統一。
21/ Arweave網路的效能實際上取決於所有節點的平均傳輸速度,增加網路中礦工的數量會增大單位時間內同步資料的傳輸速度需求,盲目增加礦工或者提高交易和區塊大小來拓展網路會導致使用者交易丟失,因此在這個階段,Arweave無法提高可拓展性,網路中歷史資料增速在一個較低的速度。
22/ Arweave 2.0(2020年3月 SPoA)
為了打破傳輸瓶頸,Arweave在2.0版本中,引入兩個概念:succinct proof(簡潔證明)和format 2 transaction(新型交易格式)。
簡潔證明用到了一個常見技術,默克爾樹,在礦工打包新區塊時,必須證明他們擁有回憶區塊的副本/訪問,並且在新區塊中包含回憶區塊。
23/ 這使得未儲存該回憶區塊的礦工必須先消耗頻寬從附近礦工那裡下載整個回憶區塊,隨著單筆交易容量增加,區塊大小也在增加,傳輸回憶區塊的頻寬要求也在進一步提高。礦工們為了收益最大化,必須儘可能多的等待其他礦工傳來的交易,而未儲存回憶區塊的礦工會在同步回憶區塊後才開始分享交易。
24/ 區塊大小的增加縮短了礦工們分享交易的時間,部分礦工不得不在未同步全部交易的情況下開始工作量證明。為了解決這個問題,簡潔證明讓礦工能夠將回憶區塊按照默克爾樹的排序方式打包,最終生成一個root proof,也被成為簡潔證明,用來證明礦工能夠儲存了該歷史區塊。
25/ 簡潔證明代替了回憶區塊,可以被礦工同步,也可以被放入新區塊中,節省了區塊空間和區塊傳輸成本。
format 2 transaction是Arweave引入的新交易格式,幫助其將區塊能容納的交易量無上限增加。舊的交易資料包括header和data,二者不可分開。
26/ format 2當中交易的header和data能夠拆分開,為什麼拆分交易能夠無上限提升區塊交易量呢?讓我們回到2.0版本的2分鐘區塊時間內,在第一部分當中,礦工會同步簡潔證明,快速建立和回憶區塊的連線,與此同時舊版本的交易格式也沒有刪除。
27/ 在第一部分中,format 1交易依然會完全在礦工之間同步,header和data沒有分割。不同的是,使用者發出的format 2交易只有header被放入新區塊中,也只有header在礦工之間同步。
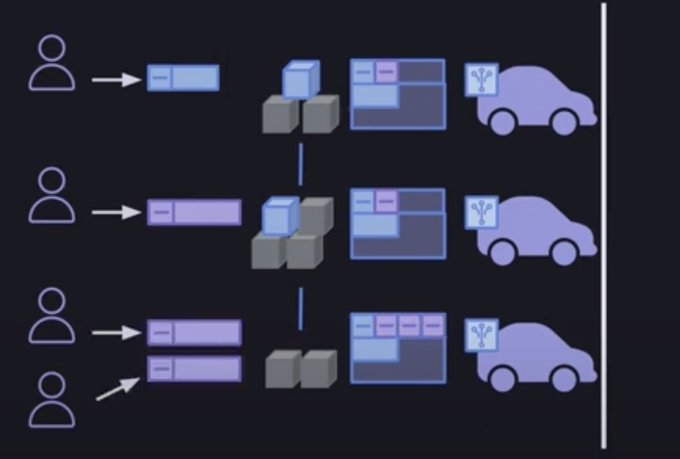
28/ 簡潔證明和format 2交易的引入,極大的減輕了第一部分中礦工之間同步的資料量,提高了Arweave的可拓展性。當新區塊產生時,它的區塊組成是:對於回憶區塊的簡潔證明、format 1交易的完整資料和format 2交易的header。
29/ 可以想像此時的區塊是一個巨大樂高模型,但是中間很多零件是空白的,這些空白的零件就是format 2交易的data部分。data資料會在下一個區塊進行到第二部分時完成同步,因為工作量證明不佔據頻寬,完全可以在cpu進行雜湊計算時,利用頻寬同步上一個區塊未傳輸的data資料。
30/ 新區塊生成時只有交易header是沒有問題的,因為通過header也可以完成驗證,但是隨後必須補齊資料,因為未來某個時刻會把當前區塊作為回憶區塊,回憶區塊能生存簡潔證明,但前提是資料必須完整。
31/ 此刻,Arweave的可拓展性已經被釋放,但是新的問題又來了。不同於上文提到的堆砌gpu的策略,SPoA的引入讓礦工們又走上另一條歧路。我們知道,簡潔證明的引入讓礦工能夠很快同步回憶區塊的資訊,礦工們不再儲存歷史區塊而是選擇等待其他礦工同步的簡潔證明,並將成本偏移到挖礦硬體上。
32/ Arweave 2.4(2021年2月 SPoRA)
PoA 只能保證永久儲存,不能保證訪問速度。在資料檢索方面沒有競爭優勢的情況下,礦工們可以通過使用遠端儲存池中獲益,而不是維護單獨的、去中心化的節點。為了解決礦工們不再儲存歷史副本的問題,Arweave將SPoA升級到SPoRA(succinct proof of random access)
33/讓我們再次回到2分鐘到區塊時間裡,在第一部分中,沒有任何變化,礦工們可以通過同步簡潔證明來獲得進入第二部分的資格,大部分的礦工選擇使用遠端儲存池,通過提升頻寬速度,快速同步和訪問遠端記憶體,不會選擇自己構建儲存池。
34/ SPoRA的引入讓第二部分變得不同,SPoRA提出的雜湊計算會要求礦工針對回憶區塊裡某一個交易計算雜湊值,生成一個輕量的簡潔證明,並且進行第二部分時,礦工之間無法傳遞簡潔證明。
35/ 對於沒有構建自己儲存池的礦工來講,可以想象成他們被強制退回到第一部分,在遠端儲存池中找到雜湊值,再進入第二部分的工作量計算。可是SPoRA對於回憶區塊裡雜湊計算是隨機且不間斷的,沒有個人儲存池的礦工會不斷被退回到第一部分。
36/ 這樣的設計要求礦工必須維護自己的個人儲存池,SPoRA 降低了之前礦工出塊概率的權重,加入了對資料訪問速度的考量。
37/ SPoRA 通過抑制 CPU 之間的資源池建立了一個更加去中心化和高效的區塊編織,讓礦工專注於維護本地硬體和節點,實現地理位置多樣化以及去中心化,以此來激勵礦工更高效、更迅速地複製資料。(摘自Arweave黃皮書)
38/ 新的設計又帶來了新的問題,現在我們能確保礦工儘可能多在個人硬碟裡儲存儘可能多的歷史副本。但是,如前文提到的,SPoRA加入對於資料訪問速度的考量,礦工如果不能快速的在硬碟中找到SPoRA要求的交易資料,並且不能及時生成輕簡潔證明的話就無法獲得挖礦獎勵。
39/ SPoRA讓礦工們追求硬碟讀取速度,能夠更快檢索資料,更快計算雜湊值意味著更高的獎勵。補充一點,硬碟的價格和讀取速度基本是成正比的,70刀的機械硬碟讀取速度是750MB/s,而700刀的固態硬碟讀取速度是7300MB/s。
40/ 礦工想要更高的收益就需要更高的付出。這是一個合理的機制,但卻還有更優解,SPoRA沒有考慮到Arweave礦工的入門門檻,變相限制了Arweave的可拓展性。
以上是針對@ArweaveEco @ArweaveNewsCN歷次升級的一個回顧,文章有點長,感謝看到這裡的各位。下一個
我將從自己的角度來理解Arweave2.6,謝謝