本文是與Ingonyama團隊合作編寫的。特別感謝@jeremyfelder讓這一切成為可能。
硬件加速的 ZKML
我們最近整合了由Ingonyama團隊構建的的開源Icicle GPU加速庫。這使開發人員能夠通過簡單的環境配置來利用硬件加速。
該集成是對EZKL引擎的戰略性增強,解決了當前ZK證明系統固有的計算瓶頸。它尤其適用於大型電路,比如為機器學習模型生成的電路。
我們觀察到,與基線CPU運行相比,聚合電路的MSM時間減少了98%,總聚合證明時間與基線CPU證明時間相比減少了35%。
這是全面硬件集成的第一步。與Ingonyama團隊一起,我們將繼續致力於對GPU操作的全面支持。此外,我們正在努力與其他硬件供應商集成——理想情況下,為更廣泛的領域展示切實的基準。
我們在下面提供上下文和技術規範。或者你也可以隨時直接進入這裡的庫。
零知識瓶頸
引用硬件評論:GPU, FPGA和零知識證明,零知識應用程序有兩個組成部分:
1. DSL和低級庫:它們對於以ZK友好的方式表達計算是必不可少的。例子包括Circom、Halo2、Noir和像Arkworks這樣的低級庫。這些工具將程序轉換為約束系統(或在這裡閱讀更多),其中像加法和乘法這樣的操作被表示為單個約束。位操作更加棘手,需要更多的約束。
2. 證明系統:它們在生成和驗證證明方面起著至關重要的作用。驗證系統處理電路、證人和參數等輸入。通用系統包括Groth16和PLONK,而像EZKL這樣的專用系統則迎合機器學習模型等特定輸入。
在最廣泛部署的ZK系統中,主要的瓶頸是:
• 多標量乘法(MSM):對向量進行大規模乘法,即使在並行化時也會消耗大量時間和內存。
• 快速傅里葉變換(FFT):需要頻繁變換數據的算法,使其難以加速,特別是在分佈式基礎設施上。
硬件的作用
硬件加速,如GPU和FPGA,通過增強並行性和優化內存訪問,提供了比軟件優化顯著的優勢:
• GPU:提供快速開發和大規模並行性,但耗電量很大。
• FPGA:提供更低的延遲,特別是對於大數據流,並且更節能,但具有複雜的開發週期。
有關最佳硬件設計和性能的更廣泛討論,請參閱此處。該領域正在迅速發展,許多方法仍然具有競爭力。
Halo2的GPU加速
在Halo2驗證系統中,瓶頸可能會因所驗證的具體電路而異。這些瓶頸主要分為兩類:
1. 承諾瓶頸(MSM):這些主要是計算瓶頸,通常是可並行化的。在MSM是瓶頸的電路中,我們觀察到一定程度的通用性。這意味著應用GPU加速的解決方案可以通過對現有代碼庫的最小修改來有效地解決這些瓶頸。
2. 約束評估瓶頸(尤其是在h poly中):這些瓶頸更為複雜,因為它們可能是計算密集型的,也可能是內存密集型的。它們在很大程度上取決於電路的細節。解決這些問題需要對評估算法進行量身定製的重新設計。這裡的重點是優化內存使用和計算之間的權衡,以及決定是存儲中間結果還是重新計算它們。

一個典型的例子是KZG聚合電路。在這種電路中,主要的挑戰在於橢圓曲線群元素的積累。這些情況下的約束是相對統一且程度較低的(例如,根據Halo2文檔,具有4級約束的不完全加法公式)。
因此,大部分複雜性來自於承諾(MSM),這是一個可以通過GPU加速有效解決的計算問題。
對於這個集成的範圍,我們選擇關注承諾瓶頸。這是唾手可得的成果,也是對引擎核心組件(KZG聚合)的優化。這只是第一步,還有很多工作要做。
Icicle:支持 CUDA 的 GPU
Ingonyama的團隊開發了Icicle作為一個開源庫,使用支持CUDA的GPU為ZK加速設計。CUDA,即計算統一設備架構,是由英偉達創建的並行計算平臺和API模型。它允許軟件利用英偉達GPU進行通用處理。Icicle的主要目標是將證明程序代碼的重要部分卸載到GPU並利用並行處理能力。
Icicle在Rust和Golang中託管API,這簡化了集成。該設計也可定製,具有以下特定:
• 高級API:用於提交、求值和插值多項式等常見任務。
• 低級API:針對特定運算,如多標量乘法(MSM)、數論變換(NTT)和逆數論變換(INTT)。
• GPU內核:用於GPU上特定任務的優化執行。
值得注意的是,Icicle支持基本功能,如:
• 矢量化字段/組算術:有效處理字段和組上的數學運算。
• 多項式算法:許多ZK算法的關鍵。
• 哈希函數:對加密應用程序至關重要。
• 複雜結構:如逆橢圓曲線數論變換(I/ECNTT)、批處理MSM和Merkle樹。
與EZKL集成
Icicle庫已經與EZKL引擎無縫集成,為直接訪問NVIDIA GPU或簡單地訪問Colab的用戶提供GPU加速。這種集成通過利用GPU的並行處理能力增強了EZKL引擎的性能。下面是如何啟用和管理此功能:
• 啟用GPU加速:要啟用 GPU 加速,請使用該Icicle功能構建系統並設置環境變量,如下所示:
export ENABLE_ICICLE_GPU=true
• 恢復到CPU:要切換回CPU處理,只需取消ENABLE_ICICLE_GPU環境變量的設置,而不是將其設置為false:
unset ENABLE_ICICLE_GPU
• 定製小型電路的閾值:如果希望修改構成小型電路的閾值,可以將ICICLE_SMALL_K環境變量設置為所需值。這允許更好地控制何時使用GPU加速。
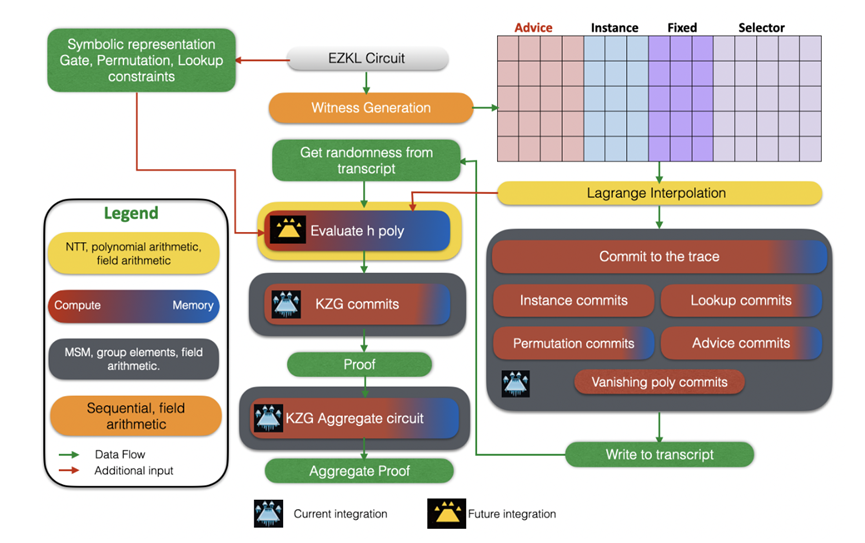
當前ICICLE整合概述。這種集成的目標是由於MSM導致的計算瓶頸,在KZG聚合電路中可以看到顯著的影響。
關鍵功能
這種集成提供了幾種技術支持。
最重要的是,該集成支持使用 Icicle 庫在 GPU 中進行即插即用 MSM 操作。作為目標和測試環境,我們專注於替換EZKL聚合命令中基於CPU的KZG承諾。這是將多個證明合併為一個證明的地方。更具體地說,KZG承諾的commit和commit_lagrange(在CPU上完成)與BN254橢圓曲線的MSM操作(在GPU上)。
我們還啟用了環境變量和crate功能,允許開發人員在相同二進制/構建EZKL的不同電路之間切換CPU和GPU。為了優化GPU切換,默認情況下僅對大 k 電路 (k > 8) 啟用 GPU 加速。
基準測試結果
我們的基準測試結果表明,將Icicle庫集成到EZKL引擎中,性能有了實質性的提高:
• MSM時間的顯著減少:我們觀察到,與聚合電路的基準CPU運行相比,多標量乘法(MSM)時間減少了大約98%。這表明計算任務的高效卸載到GPU。
• MSM操作的速度顯著提高:與基準CPU配置相比,ICICLE執行的MSM操作平均快50倍。這種加速在aggregate命令中的大多數MSM中是一致的。
• 證明時間的總體減少:與基準CPU證明時間相比,生成聚合證明所需的總時間減少了約35%。這反映了證明生成過程中顯著的整體性能增強。
這些結果突出了GPU加速在優化ZK證明系統方面的有效性,特別是在計算方面,如MSM操作。要進行驗證,您可以在這裡查看我們的持續集成測試。
未來的發展方向
展望未來,我們計劃進一步優化和擴展EZKL與Icicle集成的能力:
• 擴展GPU操作:重點關注的一個領域是用GPU取代更多的CPU操作。這包括涉及數論變換(NTT)的操作,它目前是基於CPU的。通過將這些操作卸載到GPU,我們期望實現更高的效率和速度。
• 引入批量操作:另一個重要的發展是添加批量操作。此增強功能特別旨在即使在更小和更寬的電路中也能高效使用 GPU。通過這樣做,我們的目標是將GPU加速的好處擴展到更廣泛的電路類型和尺寸,確保在所有場景下的最佳性能。
更廣泛地說,我們尋求看到與其他硬件系統的集成。這將為更廣泛的領域提供功能基準測試和開發人員靈活性。
通過這些未來的發展,我們的目標是繼續推動ZK證明系統的性能界限,使其更高效,並且適用於更廣泛的應用。
附錄
未來集成注意事項
對於貢獻者和開發人員,我們在具有四個證明的自定義實例上使用聚合命令教程測試了這種集成。關於未來集成的一些注意事項
• 基準測試環境:使用AWS c6a.8xlarge實例與AMD Epyc 7R13的基準CPU運行c測試。
• 聚合命令教程:使用聚合命令教程驗證了集成的性能,包括一個具有4個基線比較證明的測試實例。
• 在單個MSM實例上的初始測試:最初,測試集中在EZKL/halo2板條箱中的單個MSM實例上,以驗證功能。
• 完整證明中GPU上下文的問題:在擴展到完整證明時,發現GPU上下文在單個操作後丟失。解決方案是通過創建靜態引用來維護整個證明命令中的 GPU 上下文來實現的。
• 關注聚合電路/命令:該集成主要針對聚合電路/命令,其特點是K(約束數量)很大,而advice欄數少。
• 對Proof命令的影響:代碼中的修改也會影響Proof命令。有必要確保單個證明的性能隨著這些變化而保持或改進。
• 基於電路尺寸和寬度的性能變化:對於大型和狹窄的電路,GPU增強產生了積極的結果。然而,對於更小(K≤8)和更寬的電路,GPU 增強會導致性能下降。
• 通用優化的未來改進:計劃將增強所有電路類型的GPU集成,特別是關注批處理操作,以實現各種電路尺寸的最佳性能。