

撰文:Haseeb Qureshi
編譯:深潮TechFlow
你想要運行一個像 Llama2–70B 這樣的大型語言模型。如此龐大的模型需要超過 140GB 的內存,這意味著您無法在家用計算機上運行原始模型。那麼你有哪些選擇?你可能會轉向雲服務提供商,但你可能不太願意信任一個單一的中心化公司來為你處理這個工作負載並收集你所有的使用數據。那麼你需要的是去中心化推斷,它可以讓你運行機器學習模型而不依賴於任何單一的提供商。
信任問題
在去中心化網絡中,僅僅運行模型並信任輸出是不夠的。假設我讓網絡使用 Llama2–70B 分析一個治理困境,我怎麼知道它實際上沒有使用 Llama2-13B,給我提供了更糟糕的分析,並將差額收入囊中?
在中心化的世界中,你可能會相信像 OpenAI 這樣的公司是誠實的,因為它們的聲譽受到了威脅(而且在某種程度上,LLM 的質量是不言而喻的)。但在去中心化的世界中,誠實並不是默認的,它需要經過驗證。
這就是可驗證推斷髮揮作用的地方。除了對查詢提供響應之外,你還要證明它在你請求的模型上正確運行了。但是怎麼做呢?
最簡單的方法是將模型作為智能合約在鏈上運行。這肯定可以保證輸出經過驗證,但這是極其不切實際的。GPT-3 用一個維度為 12,288 的嵌入來表示單詞。如果你在鏈上進行這個大小的單次矩陣乘法運算,根據當前的Gas價格,它將花費約100億美元,這個計算將填滿每一個區塊大約一個月的時間。
所以,我們需要採取不同的方法。
觀察了這個領域之後,我清楚地看到了三種主要的方法,用於解決可驗證推斷:零知識證明、樂觀型欺詐證明和加密經濟學。每種方法都有其自身的安全和成本影響。
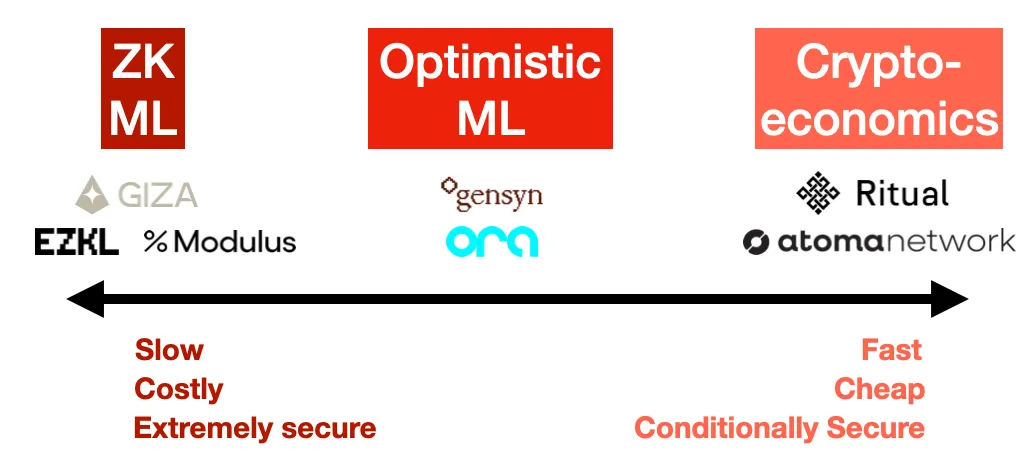
1.零知識證明(ZK ML)
想象一下能夠證明你運行了一個大型模型,但證明的大小實際上是固定的,不管模型有多大。這就是 ZK ML(機器學習) 所承諾的,通過 ZK-SNARK實現。
雖然原則上聽起來很優雅,但將一個深度神經網絡編譯成零知識電路,然後證明它,是極其困難的。而且成本極高 ,至少,你可能會看到推斷成本增加了1000倍,延遲增加了1000倍(生成證明的時間),更不用說在任何事情發生之前,將模型本身編譯成電路。最終,這個成本必須轉嫁給用戶,因此對終端用戶來說,這將變得非常昂貴。
另一方面,這是唯一一種在密碼學上保證正確性的方法。使用 ZK,無論模型提供者多麼努力,都無法作弊。但是這樣做的成本很高,使得這對於可預見的未來的大型模型來說是不切實際的。
示例:EZKL, Modulus Labs, Giza
2.樂觀型欺詐證明(Optimistic ML)
樂觀的方法是相信,但要驗證。我們假設推斷是正確的,除非證明相反。如果一個節點試圖作弊,“觀察者”可以在網絡中指出作弊者,並使用欺詐證明對其進行挑戰。這些觀察者必須隨時觀察鏈,並重新運行他們自己的模型以確保輸出正確。
這些欺詐證明是 Truebit 風格的交互式挑戰:響應遊戲,在遊戲中,你要反覆在鏈上對模型執行軌跡進行分割,直到找到錯誤為止。
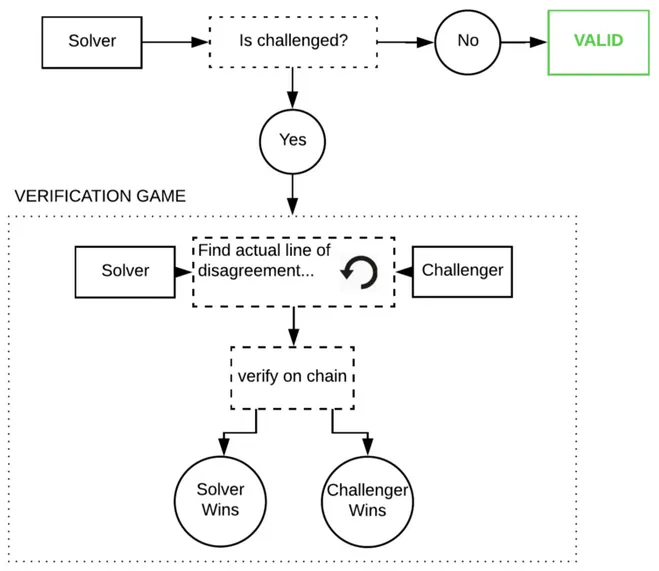
如果這確實發生了,那將是極其昂貴的,因為這些程序龐大且具有巨大的內部狀態,一個單獨的 GPT-3 推斷成本約為 1 petaflop(10⁵ 浮點運算)。但是博弈論表明,這幾乎不可能發生(欺詐證明在編碼時也非常難以正確編寫,因為在實際生產中幾乎不會執行到這段代碼)。
樂觀的好處是,只要有一個誠實的觀察者在關注,ML 就是安全的。成本比 ZK ML 便宜,但請記住,網絡中的每個觀察者都在重新運行每個查詢。在平衡狀態下,這意味著如果有10個觀察者,那麼安全成本必須轉嫁給用戶,所以他們將不得不支付超過10倍推斷成本的費用(或者有多少觀察者就支付多少)。
缺點是,與樂觀型聚合技術一樣,你必須等待挑戰期結束,以確保響應已被驗證。但是,根據網絡參數的設置方式,你可能只需要等待幾分鐘而不是幾天。
3.加密經濟學(Cryptoeconomic ML)
在這裡,我們放棄所有花哨的技術,做簡單的事情:權益加權投票。用戶決定有多少節點應該運行他們的查詢,它們各自透露他們的響應,如果響應之間有差異,那麼奇怪的節點就會被砍掉。標準的預言機機制,這是一個更直接的方法,讓用戶設定他們想要的安全級別,平衡成本和信任。如果 Chainlink 在做 ML,這就是他們會採取的方式。
這裡的延遲很快,你只需要每個節點的提交和揭示。如果這被寫入到區塊鏈中,那麼從技術上講,這可以在兩個區塊中發生。
然而,安全性是最弱的。如果大多數節點都願意合作,那麼它們可以理性地選擇合謀。作為用戶,你必須思考這些節點投入了多少,並且作弊會給他們帶來多大的成本。也就是說,使用類似 Eigenlayer 的重新質押和可歸因的安全性,網絡可以在安全失敗的情況下提供有效的保險。
但這個系統的好處是用戶可以指定他們想要多少安全性。他們可以選擇在他們的法定數量中有3個節點或5個節點,或者是網絡中的每個節點。或者,如果他們想要冒險,他們甚至可以選擇 n=1。這裡的成本函數很簡單:用戶為他們的 quorum 中想要的法定數量支付費用。如果你選擇了3個,你就要支付3倍的推斷成本。
這裡的棘手問題是:你能讓 n=1 安全嗎?在一個簡單的實現中,一個孤立的節點應該每次都會作弊,如果沒有人監督的話。但我懷疑,如果你加密查詢並通過意向進行支付,你可能能夠對節點隱瞞他們實際上是唯一回應這個任務的節點。在這種情況下,你可能可以向普通用戶收取少於2倍推斷成本的費用。
最終,加密經濟學方法是最簡單、最容易的,也可能是最便宜的,但從原則上講,它是最不引人注目和最不安全的。但是一如既往,細節決定成敗。
示例:Ritual 、Atoma Network
為什麼可驗證的 ML 很難
你可能會想,為什麼我們還沒有所有這些東西呢?畢竟,歸根結底,ML模型只是非常大的計算機程序。證明程序正確執行一直是區塊鏈的核心。
這就是為什麼這三種驗證方法反映了區塊鏈如何保護其區塊空間的方式,ZK rollup使用 ZK 證明,樂觀型rollup使用欺詐證明,大多數 L1 區塊鏈使用加密經濟學。毫無疑問,我們最終會得出基本相同的解決方案。那麼當應用於 ML 時,是什麼使這變得困難?
ML 是獨特的,因為 ML 計算通常被表示為密集的計算圖,旨在在 GPU 上高效運行。它們不是為了被證明而設計的。因此,如果你想在 ZK 或樂觀環境中證明 ML 計算,它們必須重新編譯成可行的格式,這是非常複雜和昂貴的。
機器學習的第二個基本困難是非確定性。程序驗證假設程序的輸出是確定性的。但是,如果你在不同的 GPU 架構或 CUDA 版本上運行相同的模型,你會得到不同的輸出。即使你強制每個節點使用相同的架構,你仍然會遇到算法中使用的隨機性問題(擴散模型中的噪聲,或者LLM中的代幣抽樣)。你可以通過控制隨機數種子來修復這種隨機性。但即使如此,你仍然會面臨最後一個令人不安的問題:浮點運算中固有的非確定性。
幾乎所有的 GPU 操作都是在浮點數上進行的。浮點數很難處理,因為它們不是可結合的——也就是說,對於浮點數來說,(a + b) + c 總是與 a + (b + c) 相同這種說法並不正確。由於 GPU 高度並行化,每次執行時加法或乘法的順序可能會不同,這可能會導致輸出中的小差異。這不太可能影響LLM的輸出,因為單詞的離散性質,但對於圖像模型來說,可能會導致像素值微妙地不同,從而使兩個圖像不能完全匹配。
這意味著你要麼需要避免使用浮點數,這會對性能造成巨大的打擊,要麼你需要在比較輸出時允許一些靈活性。無論哪種方式,細節都很煩瑣,你無法完全抽象出來。(這就是為什麼以太坊虛擬機不支持浮點數,儘管一些區塊鏈如NEAR支持浮點數的原因。)
簡而言之,去中心化推理網絡很難,因為所有的細節都很重要,而現實中的細節卻出人意料地多。
總結
目前,區塊鏈和機器學習顯然有很多共同之處。其中一個是創造信任的技術,另一個則是迫切需要信任的技術。雖然去中心化推理的每種方法都有其自身的權衡,但我非常感興趣地想看看企業家們如何利用這些工具來構建最好的網絡。






