

微軟宣布推出Phi-3 系列開放小語言模型 (SLM),並宣稱它們是現有規模中功能最強大、最具成本效益的模型。微軟研究人員開發的創新訓練方法使 Phi-3 模型在語言、編碼和數學基準方面優於更大的模型。
「我們將開始看到的不是從大到小的轉變,而是從單一類別模型向模型組合的轉變,客戶能夠決定最適合他們的模型。場景,」微軟生成人工智慧首席產品經理 Sonali Yadav 說。
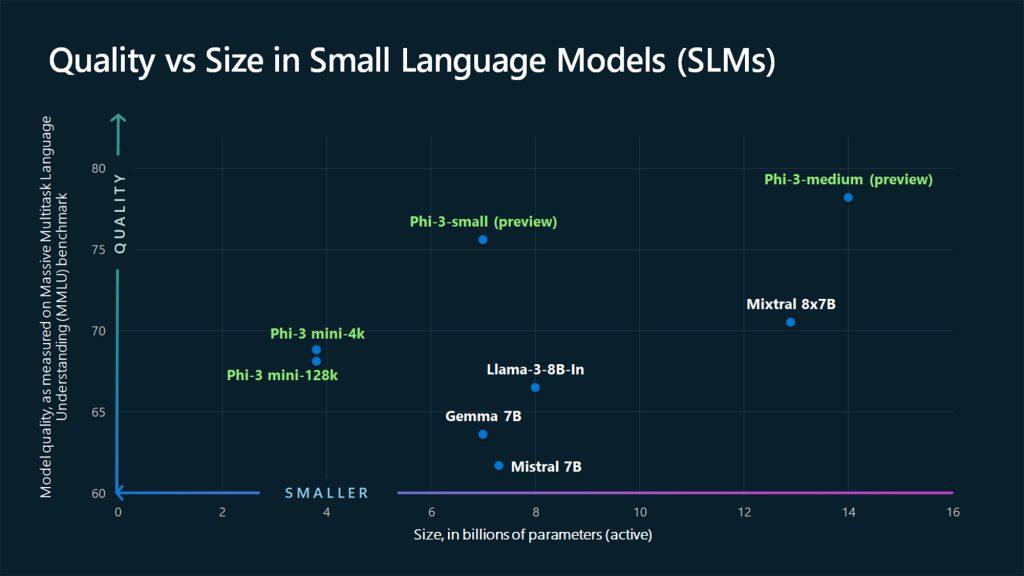
第一款 Phi-3 型號 Phi-3-mini 擁有 38 億個參數,現已在Azure AI 模型目錄、 Hugging Face 、 Ollama中公開提供,並作為NVIDIA NIM微服務提供。儘管尺寸緊湊,Phi-3-mini 的性能優於兩倍尺寸的型號。其他 Phi-3 型號,如 Phi-3-small(7B 參數)和 Phi-3-medium(14B 參數)即將推出。
phi-3-mini:3.8B 型號,搭配 Mixtral 8x7B 和 GPT-3.5
— 米拉 (@_Mira___Mira_) 2024 年 4 月 23 日
加上在許多基準測試中與 Llama 3 8B 相符的 7B 型號。
加上14B型號。 https://t.co/2h0xahzUUS pic.twitter.com/XaED6mJL1V
微軟人工智慧副總裁 Luis Vargas 表示:“有些客戶可能只需要小型模型,有些客戶需要大型模型,而許多客戶則希望以各種方式將兩者結合起來。”
SLM 的主要優勢是尺寸較小,無需網路連線即可在裝置上部署低延遲 AI 體驗。潛在的用例包括智慧感測器、攝影機、農業設備等。將資料保存在設備上的另一個好處是隱私。
大型語言模型 (LLM) 擅長對海量資料集進行複雜推理,透過理解科學文獻中的交互作用,適合藥物發現等應用。然而,SLM 為更簡單的查詢答案、摘要、內容產生等提供了令人信服的替代方案。
Iris.ai首席技術長兼聯合創始人 Victor Botev 評論道:“微軟並沒有追求更大的模型,而是開發具有更精心策劃的數據和專門培訓的工具。”
「這可以提高性能和推理能力,而無需花費數萬億參數的模型的大量計算成本。實現這一承諾意味著為尋求人工智慧解決方案的企業消除巨大的採用障礙。
突破訓練技術
Microsoft SLM 品質飛躍的推動者是受睡前故事書啟發的創新數據過濾和生成方法。
“與其僅使用原始網路數據進行訓練,為什麼不尋找極高品質的數據?”負責 SLM 研究的 Microsoft 副總裁 Sebastien Bubeck 問道。
Ronen Eldan 每天晚上與女兒一起閱讀的習慣激發了他的想法,即通過用 4 歲孩子會知道的單詞組合提示一個大型模型來生成包含數百萬個簡單敘述的“TinyStories”數據集。值得注意的是,在 TinyStories 上訓練的 10M 參數模型可以產生具有完美語法的流暢故事。
在早期成功的基礎上,團隊採購了經過教育價值審查的高品質網路數據,以建立「CodeTextbook」數據集。這是透過人類和大型人工智慧模型的多輪提示、生成和過濾來合成的。
「產生這些合成數據需要花費很多心思,」布貝克說。 “我們不會拿走我們生產的所有東西。”
事實證明,高品質的訓練資料具有變革性。 「因為它是從類似教科書的材料中讀取的……你可以使語言模型的閱讀和理解這些材料的任務變得更加容易,」布貝克解釋道。
降低人工智慧安全風險
儘管資料管理經過深思熟慮,微軟仍然強調在 Phi-3 版本中應用額外的安全實踐,以反映其所有生成式 AI 模型的標準流程。
「與所有生成式 AI 模型版本一樣,微軟的產品和負責的 AI 團隊使用多層方法來管理和降低開發 Phi-3 模型的風險,」一篇部落格文章指出。
這包括進一步的培訓範例以強化預期行為、透過紅隊進行評估以識別漏洞,以及為客戶提供 Azure AI 工具以在 Phi-3 上建立值得信賴的應用程式。
( 塔達斯·薩爾攝)
另請參閱: 微軟將與韓國科技領導者建立人工智慧合作關係

想向產業領導者了解更多關於人工智慧和大數據的知識嗎?查看在阿姆斯特丹、加州和倫敦舉辦的人工智慧與大數據博覽會。該綜合活動與BlockX 、數位轉型週和網路安全與雲端博覽會等其他領先活動同期舉行。
在此探索由 TechForge 提供支援的其他即將舉行的企業技術活動和網路研討會。
微軟推出 Phi-3 系列緊湊語言模型的貼文首先出現在AI News上。






