

by: Davide Rezzoli (@DavideRezzoli) and Barnabé Monnot (@barnabe)
Many thanks to Yoav Weiss (@yoavw) for introducing us to the problem, Dror Tirosh (@drortirosh) for helpful comments on the draft, and the 4337 team for their support. Reviews ≠ endorsements; all errors are the authors’ own.
This work was done for ROP-7.
Introduction
In our previous post, we introduced the ERC-4337 model. This model outlines the fee market structure for bundlers and details the cost function related to the on-chain publishing cost and the off-chain (aggregation costs) of a bundle.
We also introduced the concept of the “Bundler Game”. This game will be the primary focus of the second part. Given a set of transactions, a bundler can choose which transactions to include in their bundle. This creates an asymmetry of information between the bundlers and the user, as the user doesn’t know how many transactions will be included in the bundle. This leads to a zero-sum game where the user is at a clear disadvantage.
This research aims to explore methods to improve the UX by ensuring that users do not need to overpay for inclusion in the next bundle. Instead, users should be able to pay a fee based on the actual market demand for inclusion.
Current state of ERC-4337
In today’s market, the P2P mempool is not live on mainnet and it’s being tested on the Sepolia testnet. Companies building on ERC-4337 are currently operating in a private mode, the users connect via an RPC to a private bundler which will than work with a buidler to publish onchain your useroperation. Bundle Bear app, developed by Kofi, provides some intriguing statistics on the current state of ERC-4337.
In the Weekly % Multi-UserOp Bundles metric, we observe the percentage of bundlers creating bundles that include multiple userops. From the beginning of 2024 to June 2024, this percentage has not exceeded 6.6%. This data becomes even more interesting when considering that many bundlers run their own paymasters, entities that sponsor transactions on behalf of users. Notably, the two largest bundlers who also operate as a paymaster, in terms of user operations published, sponsored 97% of the user operations using their services. The paymaster pays for some parts of the useroperation and the rest is paid by the dapps or other entity.
The question that arises is why paymasters, dApps, etc., are paying for the user operations. Will the user pay them back in the future? We can’t be sure what will happen, but my personal guess is that currently, dApps are covering the fees to increase usage and adoption of their apps. Once adoption is high, users will likely have to pay for the transactions themselves. It’s worth mentioning that for the user to pay for a user operation with the current model is not the best option, since a basic ERC-4337 operation costs ~42,000 gas, while a normal transaction costs ~21,000 gas.
Variations on ERC-4337
Overview of ERC-4337
The mempool is still in a testing phase on Sepolia and is not live on the mainnet. Without the mempool, users have limited options for using account abstraction. Users interact with an RPC, which may be offered by a bundler that bundles UserOps, or with an RPC service that doesn’t bundle, similar to services like Alchemy or Infura, which receive and propagate transactions to other bundlers.
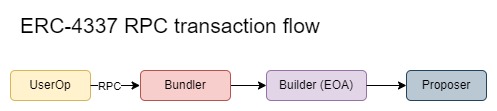
Once the mempool is live, the transaction flow will resemble the diagram below, which is similar to the current transaction flow. A mempool enhances censorship resistance for users because, unlike the RPC model, it reduces the chances of a transaction being excluded. However, even with a mempool, there is still a risk that an RPC provider might not forward the transaction, but the mempool model is particularly beneficial for users who prefer to run their own nodes, as it mitigates this risk.
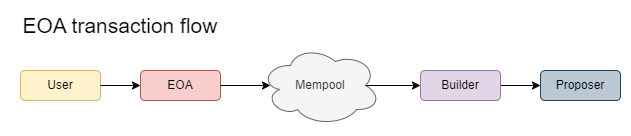
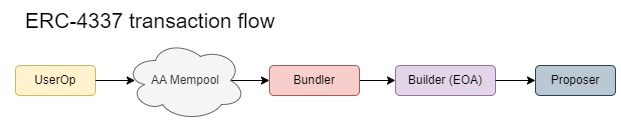
While bundlers have the potential to act as builders, we prefer to keep the roles separate due to the competitive landscape. Bundlers would face significant competition from existing, sophisticated builders, making building less attractive and potentially less profitable. As a result, bundlers are more incentivized to collaborate with established builders rather than building independently and risking losses.
Combining the roles of bundler and builder into a single entity implies significant changes to the current system. Bundlers would need to compete with existing sophisticated builders, or alternatively, current builders will need to horizontally integrate and assume the bundler role as well. The latter scenario, while more plausible, raises concerns about market concentration and the potential negative impact on censorship resistance.
Bundlers and builders as two different entities
With the users connecting directly to an RPC, everything runs in a more private environment, which doesn’t help with market competition. In the near future the mempool will be on the mainnet increasing competition.
Using a mempool, in which userops are public to different bundlers increases competition, in the case of non native account abstraction having a separation between bundler and builder is needed, in the case of native account abstraction the separation might not be needed since the builder can interpret the userops as normal transactions.
For our model we believe that having a separation between the bundler and the builder also offers some advantages, especially in terms of competition and censorship resistance. Imagine a scenario where all the bundlers are offering a cost \textbf{v}v for getting included in their bundle. There will be a bundler who wants to attract more users to achieve higher profits, so they will offer a cost \textbf{v’}v’ where \textbf{v’} < \textbf{v}v’<v with enough competition among bundlers, \textbf{v'}v' will get close to \omegaω, the aggregation cost for the bundle. In this case, the bundlers who can search more efficiently and have better hardware to include more transactions in a bundle will earn higher fees and in return makes the useroperation for the user cheaper.
This could lead to the following outcome: In a competitive environment, bundlers will lower their prices to be selected by users, who will, in turn, seek the lowest price for the inclusion of their user operation in a bundle. This competition will create a system where the bundler who offers the best price will be selected more often than the bundler who is only trying to maximize their profit by creating smaller bundles. Separating the roles of the bundler and builder can also enhance censorship resistance. A bundler can create a bundle of aggregated user operations and send it to different builders. If the bundle includes operations that could be censored, a non-censoring builder can accept it and proceed with construction. However, it’s worth noting that from a user’s perspective, this setup could increase costs, as the introduction of a bundler adds an additional party, leading to higher expenses.
RIP-7560
Native account abstraction isn’t a novel concept; it’s been under research for years. While ERC-4337 is gaining traction, its implementation outside the protocol offers distinct advantages alongside trade-offs. Notably, existing EOAs can’t seamlessly transition to SCWs, and various types of censorship-resistant lists are harder to utilize. As previously mentioned, the gas overhead of a userOp cost escalates significantly compared to a normal transaction. RIP-7560 won’t inherently resolve the ongoing issue concerning off-chain costs, but it substantially reduce transaction expenses. From the initial ~42000 gas, it’s possible to reduce the cost by ~20000 gas.
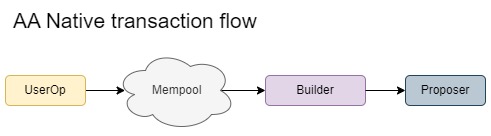
Layer2s Account Abstraction
Account abstraction can be utilized in Layer 2 (L2) solutions. Some L2s already implement it natively, while others follow the L1 approach and are waiting for a new proposal similar to RIP-7560. In L2, the L1 is used for data availability to inherit security, while most of the computation occurs off-chain on the L2, providing cheaper transactions and scalability.
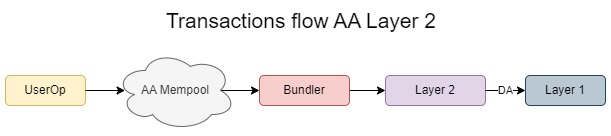
In scenarios where computation on L2 is significantly cheaper than the cost of calldata for data availability (DA) on the mainchain, the use of signature aggregation proves highly beneficial. For instance, pairing for BLS on the mainnet is facilitated by the 0x08 precompile from the EVM, which costs approximately ~45000k gas. Consequently, using BLS on L1 is more expensive than traditional transactions.
Compression techniques on L2s are already being used, such as 0-byte compression, which reduces the cost from ~188 bytes to ~154 bytes for an ERC20 transfer. With signature aggregation, the compression efficiency can be further enhanced by using a single signature, reducing the size to ~128 bytes.
In Layer 2s, signature aggregation is a crucial innovation that enhances both transaction efficiency and cost-effectiveness. By combining multiple signatures into a single one, the overall data payload is significantly reduced, which lowers the costs associated with data availability on Layer 1. This advancement not only improves scalability but also reduces transaction costs for users, making the system more economical and efficient.
Signature Aggregation economics in Layer2s
When using an L2 service, the user incurs several costs, including a fee for the L2 operator, a cost based on network congestion, and the cost of data availability on L1.
From a previous research on ”Understanding rollup economics from first principles”, we can outline the costs a user faces when using L2 services as follows:
When a user interatcs with a layer 2 he has some costs that we can define as follow:
- User fee = L1 data publication fee + L2 operator fee + L2 congestion fee
- Operator cost = L2 operator cost + L1 data publication cost
- Operator revenue = User fees + MEV
- Operator profit = Operator revenue - Operator cost = L2 congestion fee + MEV
In the case of non-native account abstraction, an additional entity, the bundler, may introduce a fee for creating bundles of userops.
Considering the bundler, the costs and profits are extended as follows:
- User fee = L1 data publication fee + L2 operator fee + L2 congestion fee + Bundler Fee
- Bundler Cost = Quoted(L1 data publication fee + L2 operator fee + L2 congestion fee)
- Bundler Revenue = User fee
- Bundler profit = Bundler Revenue - Bundler cost = Difference between L1 and L2 costs and quoted prices from the bundler + Bundler fee
- Operator Cost = L1 data publication fee + L2 operator fee
- Operator profit = Operator revenue - Operator cost = L2 congestion fee + MEV
The bundler earns its fee from the user for their services, while the remainder of the user’s payment covers the L2 operator’s costs. If the user is unaware of the bundle size, estimating the actual cost of sending userops becomes challenging, potentially leading to the bundler charging higher fees than the one necessary to cover the operator cost.
Incentive Alignment in L2
The interaction between the bundler and L2 helps address this issue, as L2s are incentivized to keep user costs low due to competition. Overcharging users can drive them to switch to other L2s offering fairer prices.
Let’s redefine our model by introducing the operator. The user bids to the bundler for inclusion in the next L2 block by bidding a value VV. The user aims to minimize the data publication fee, while the bundler seeks to maximize their fee or gain a surplus from L2 interaction costs and user fees.
The costs associated with creating a bundle and publishing it on-chain can be divided into two parts:
On-chain cost function: A bundler issuing bundle \mathbf{B}B when the base fee is rr expends a cost:
Aggregated cost function: The bundler has a cost function for aggregating nn transactions in a single bundle \mathbf{B}B with base fee of rr:
with S' < SS′<S the reduced size of a transaction and the pre-verification gas use F' > FF′>F, which contains the publication and verification of the single on-chain aggregated signature.
If the user can obtain a reliable estimate for nn, they can calculate their cost using the estimateGas function, available in most L2 solutions. Having a good estimation can make the user bid accordingly without having to overestimate their bid for inclusion. This function determines the necessary cost to ensure inclusion. Having a good estimate for nn and the estimateGas function can avoid the user to pay for a higher preVerificationGas. In the next section, we will explore various mechanisms to ensure a reliable estimation of nn.
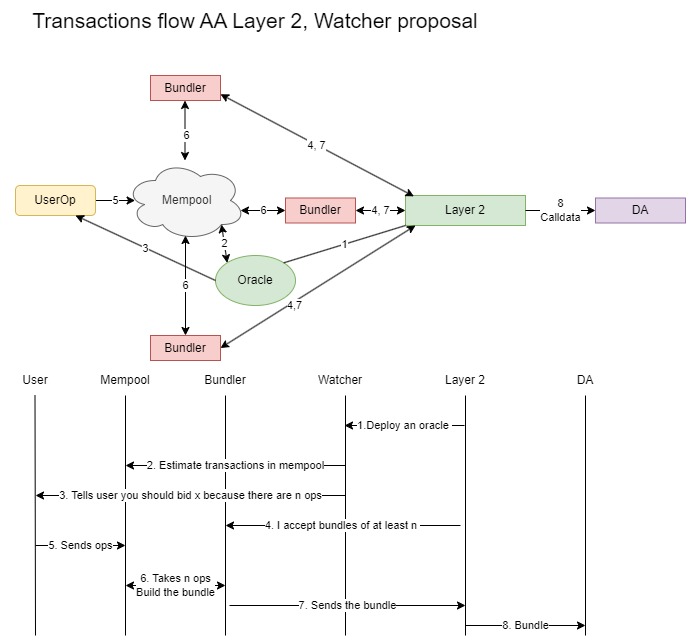
Layer2s operate an oracle
The oracle’s role is to monitor the mempool and estimate the number of transactions present. The process works as follows: the Layer 2 deploys an oracle to check the mempool and then informs the user about the number of transactions in the mempool. This enables the user to estimate their bid for inclusion in a bundle. The Layer 2 can request the bundler to include at least a specified number of transactions (nn) in a bundle, or else the bundle will be rejected. Once the bundler gathers enough transactions to form a bundle, it sends the bundle to the Layer 2, which then forwards it to the mainnet as calldata for data availability.
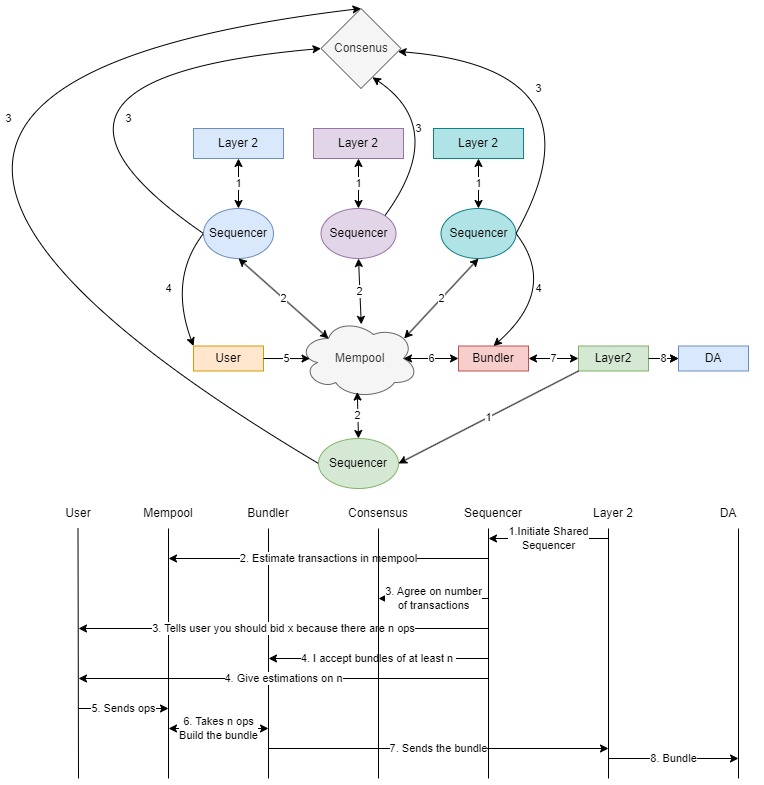
Layer2s with shared sequencer
An interesting approach is to have multiple Layer 2 (L2) networks running a shared sequencer. This setup can provide a more accurate estimate of the mempool, as the sequencer reaches an agreement through consensus facilitated by the shared sequencer.
In this configuration, different L2 networks operate independently but share a common sequencer. At regular intervals, these networks check the number of user operations (userops) in the shared mempool. The shared sequencer helps synchronize and aggregate data from these networks. Once they reach an agreement, the information is communicated to the user, allowing them to bid based on the number of userops present.
This approach offers several advantages. Firstly, it provides a decentralized method to determine the number of userops in the mempool, enhancing resistance to collusion. Secondly, it eliminates the single point of failure that could occur if only one system were managing the communication between the user and the mempool. Thirdly, the shared sequencer ensures consistency and reduces discrepancies between the different L2 solutions.
By leveraging the shared sequencer, this method ensures a robust and reliable system for estimating and communicating the state of the mempool to users, thus improving the overall efficiency and security of the process.
In the two explained approaches by using an oracle, there is a potential attack vector where an adversary could generate multiple user operations in the mempool, knowing that they will revert if aggregated together. As a result, the oracle sees that there are nn transactions and requires a large bundle, but the bundler cannot create the bundle. This issue could stall the network for many blocks.
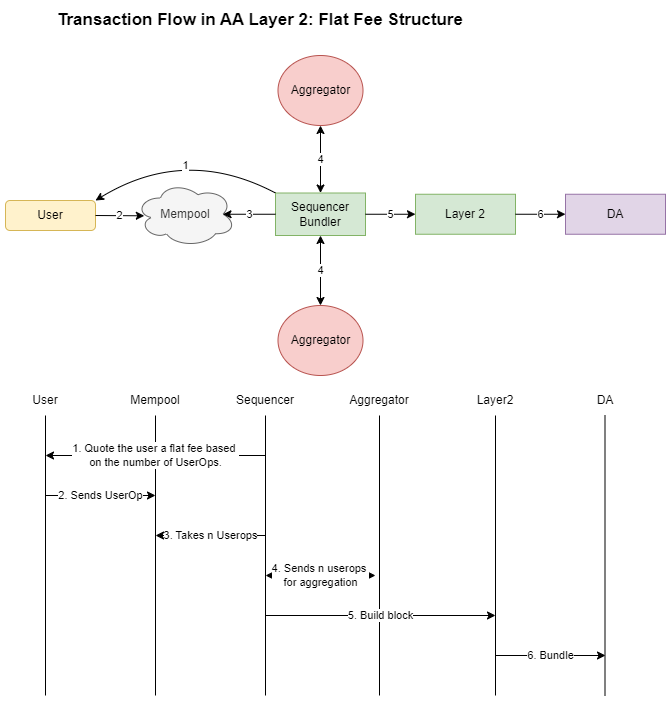
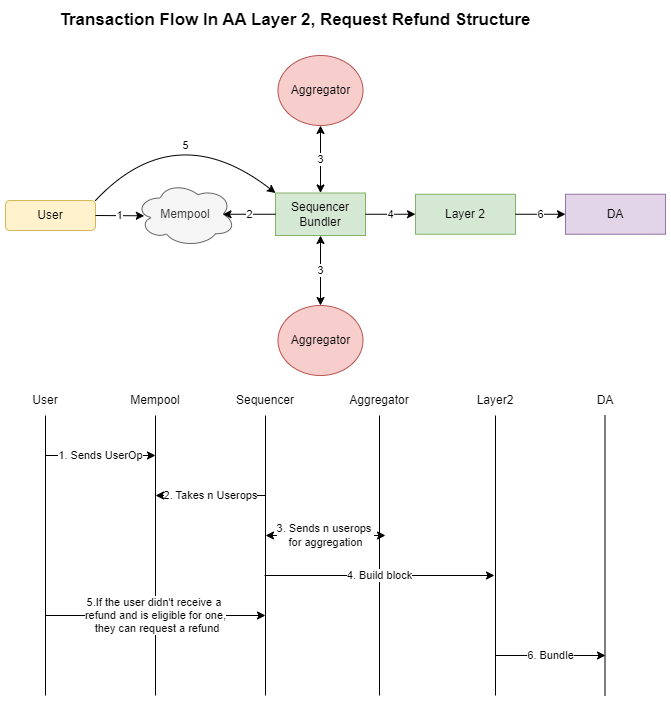
Layer2s operate their own bundler
In this proposal, the Layer 2 itself assumes the role of the bundler, while another entity handles the aggregation of signatures (this could be current bundler services). The process works as follows: the Layer 2 operates its own bundler, and users send their operations (userops) to the mempool. The Layer 2 selects some of these userops from the mempool and sends them “raw” to the aggregator, compensating the aggregator for aggregating the signatures. Once the aggregator produces the bundle, it sends it to the bundler, which then forwards it to the mainnet as calldata for data availability.
The main idea is that the Layer 2 handles the collection of userops and then outsources the aggregation to another entity. The Layer 2 pays for the aggregation and charges the user a fee for the service.
There are two different options:
Flat Fee Model: The bundler (Sequencer) selects some transactions and charges the user a flat fee. This flat fee is calculated similarly to current Layer 2 transactions, predicting the future cost of L1 data publication. Alternatively, the Layer 2 could charge the user a flat fee based on the cost of bundling nn aggregated userops, the layer 2 still have to predict how many transactions will be present in the bundle he will contruct to correctly quote the user, this can be made in the same way is now where the . As it is now where the l2 charge the best comeptitive price to the user that it is in the Layer 2’s best interest to keep the prices as competitive as possible for the user.
Requesting Refunds: If the Layer 2 wants to enhance its credibility, it could enable automatic refunds. This would involve a mechanism that checks how many userops are published in a single block and whether the transactions could have been aggregated. If a userop that could have been aggregated wasn’t, and no automatic refund was issued, the user can request a refund. In this scenario, the Layer 2 could stake some assets, and if the refund isn’t provided, the user could enforce the refund, ensuring fairness and accountability.
Conclusion
In these two different posts, we outline the difficulties users experience when bidding to be included in the next bundle. In the first part, we presented the ERC-4337 model, explaining the costs a bundler incurs when posting a bundle on-chain and the associated off-chain costs. We also outlined the fee markets for bundlers and began discussing the issue of formatting the bundler. Users experience difficulties with bidding due to a lack of knowledge about the number of transactions present in the mempool at the time of bundling.
In the second part, we explained ERC-4337 and RIP-7560. We then discussed why signature aggregation is more likely to occur on Layer 2 solutions rather than directly on Layer 1. We demonstrated how Layer 2 solutions could address the asymmetric knowledge that users experience in different ways. The first one is to use oracles to signal to the user how many transactions are present in the mempool, with this approach the users knows how much they should bid and can force the bundler to make larger bundles. The third approach which is the simplest is that the L2 acts as a bundler and outsources the aggregation to a third party and lets the users pay a fee for it.





