

PANDAS: A Practical Approach for Next-Generation Data Availability Sampling in Ethereum
Authors: Onur Ascigil1, Michał Król2, Matthieu Pigaglio3, Sergi Reñé4, Etienne Rivière3, Ramin Sadre3
TL;DR
- PANDAS is a network layer protocol that supports Danksharding with 32 MB blobs and beyond.
- PANDAS aims to achieve a 4-second deadline for random sampling (under the tight fork choice model).
- Following the Proposer-Builder Separation (PBS), resourceful builders perform the initial distribution (i.e., seeding) of samples to the nodes.
- PANDAS proceeds in two phases during each slot: 1) Seeding Phase, where the chosen builder of a slot distributes subsets of rows and columns of a 2-D encoded blob to the validator nodes, and 2) Row/Column Consolidation and Sampling phase, where nodes sample random cells and at the same time retrieve and reconstruct assigned rows/columns to boost the data availability of cells.
- PANDAS uses a direct communication approach, which means 1-hop, i.e., point-to-point communications, for both seeding and sampling phases rather than a gossip-based, multi-hop approach or a DHT.
We make the following assumptions when designing PANDAS:
Assumption 1) Resourceful Builders: Following the Proposer-Builder Separation (PBS) scheme, in PANDAS, a set of resourceful builders — e.g., cloud instances with sufficiently high upload bandwidth such as 500 Mbps or more — undertake the distribution of seed samples to the network. [1]
Assumption 2) Builder Incentives: The builders have an incentive for the blob data to be available since the block will be accepted only if DAS succeeds. However, different builders can have different amounts of resources. The interest of rational builders is to guarantee that data will be considered available while spending a minimal amount of resources.
Assumption 3) Validator Nodes (VNs) are the primary entities of DAS protocol: A single Validator Node (VN) performs only a single sampling operation (as one entity), independent of the number of validators it hosts.
Assumption 4) Dishonest Majority: A majority (or even supermajority) of VNs and builders can be malicious and, therefore, may not follow the protocol correctly.
Assumption 5) Sybil-resistance VNs: An honest VN can use a Proof-of-Validator scheme to prove that it hosts at least one validator. If multiple nodes attempt to re-use the same proof, they can be blocklisted by other honest nodes and builders.
Below are the objectives of PANDAS:
Objective 1) Tight fork choice: Honest validator nodes (VNs) complete random sampling before voting for a block, even when the majority of VNs are malicious*.* Therefore, we target the tight fork choice model, which means that honest VNs in a slot’s committee must complete random sampling before voting within four seconds into that slot.
Objective 2) Flexible builder seeding strategies: Given that different builders can have different resources, our design allows the block builder the flexibility to implement different blob distribution strategies, each with a different trade-off between security and resource usage. For higher security, the builder can send more copies of the blob’s cells to validator nodes, ensuring higher availability. Conversely, to minimise resource usage, the builder can distribute a single copy of each cell at most, reducing bandwidth usage at the expense of lower security. This flexible approach allows the builder to navigate the trade-off between ensuring data availability and optimising bandwidth while under the incentive for the block to be deemed available by validator nodes to be accepted.
Objective 3) Allowing Inconsistent Node Views: Our objective is to ensure that the VNs and the builders are not required to reach a consensus on the list of VNs. While we aim for the VNs and builders to generally agree on the set of VNs in the system, it is not necessary for the VNs to maintain strictly consistent views or for the builders’ and VNs’ views to be fully synchronised.
PANDAS Design
Continuous Peer Discovery: To achieve Objective 3, the nodes in the system perform continuous peer discovery in parallel to the protocol phases below to maintain an up-to-date “view” containing other peers. The builder and the VNs aim to discover all the VNs with a valid Proof-of-Validator. We expect both the builder and VNs to have a close but not perfect view of all the VNs in the system.
A membership service running the peer discovery protocol inserts new (verified) VNs to the view and eventually converges to a complete set of VNs. Peer discovery messages are piggybacked to sample request messages to reduce discovery overhead.
PANDAS protocol has two (uncoordinated) phases, which repeat during each slot:
Phase 1) Seeding,
Phase 2) Row/Column Consolidation and Sampling
In the seeding phase, the builder pushes subsets of row/columns directly to the VNs where row/column assignment is based on a deterministic function. Once a VN receives its samples from the builder, it consolidates the entire row/column it is assigned to (by requesting missing cells from other VNs assigned to the corresponding row/column) and simultaneously performs random sampling.
VNs do not coordinate to start consolidating and sampling. Therefore, a node finishing phase 1 can begin phase 2 immediately without coordinating with other nodes. The VNs who are the committee members of a slot must complete seeding and random sampling within 4 seconds into the slot.
Below, we explain the two phases of our protocol in detail.
Phase 1- Seeding: The builder assigns VNs to individual rows/columns using a deterministic function that uses a hashspace as we explain below. This mapping of VNs to individual rows/columns is dynamic and changes in each slot. The mapping allows nodes to locally and deterministically map nodes to rows/columns without requiring the number or full list of nodes to be known.
The Builder prepares and distributes seed samples to the VNs as follows:
1.a) Mapping Rows/Columns to static regions in the hashspace: The individual rows and columns are assigned static regions in the hashspace as shown in the upper portion of Figure 1.
1.b) Mapping VNs to a hashspace : The builder uses a sortition function FNODE(NodeID, epoch, slot, R) to assign each VN to a key in the hashspace. The function takes parameters such as NodeID, which is the identifier of the node (i.e., peer ID), epoch and slot numbers, and a random value R derived from the header of the block header from the previous slot.
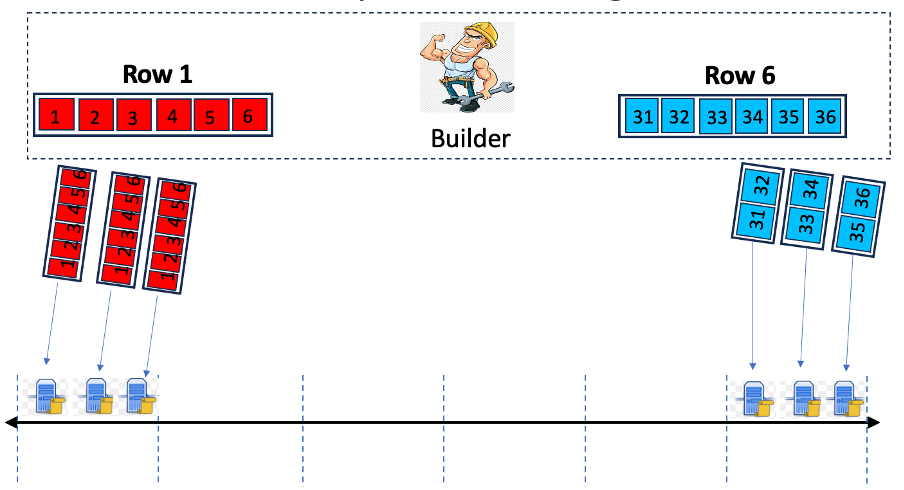
Figure 1: Assignment of Row samples to VNs. The Column samples are mapped similarly.
A VN assigned to a row’s region will receive a subset of the cells belonging to that row from the builder. As the VNs are re-mapped to the hashspace during each slot using FNODE, their row/column assignments can also change.
NOTE: A dynamic, per-slot assignment of rows and columns to VNs is impossible in a gossip-based seeding approach where per-row and per-column gossip channels must remain relatively stable over time.
1.c) Row/Column Sample Distribution: For each row and column, the builder applies a best-effort distribution strategy to push subsets of each row/column to the VNs mapped to the corresponding row/column’s region. The builder uses a direct communication approach, particularly a UDP-based protocol, to distribute the cells for each row/column directly to the VNs.
Rationale for direct communication*:* We aim to complete the seeding phase as quickly as possible to give time for committee members to complete random sampling before voting (Objective 1).
Row/Column Distribution Strategies: We allow the builders to choose distribution strategies based on resource availability in line with Objective 2. A trade-off between resource usage and data availability exists for different distribution strategies. Consider the example in Figure 2 for distributing two rows. In one extreme case (on the left), the builder distributes the entire row 1 to each VN in the row’s region for improved data availability at the expense of higher resource usage. In another extreme case, the builder sends non-overlapping row pieces of row 6 to each VN in that row’s region, which requires fewer resources but results in less availability of individual cells.
We are currently evaluating different distribution strategies, including ones that can deterministically map individual cells of rows/columns to individual VNs in the row/column’s region.
NOTE: The builder is only involved in the Seeding phase.
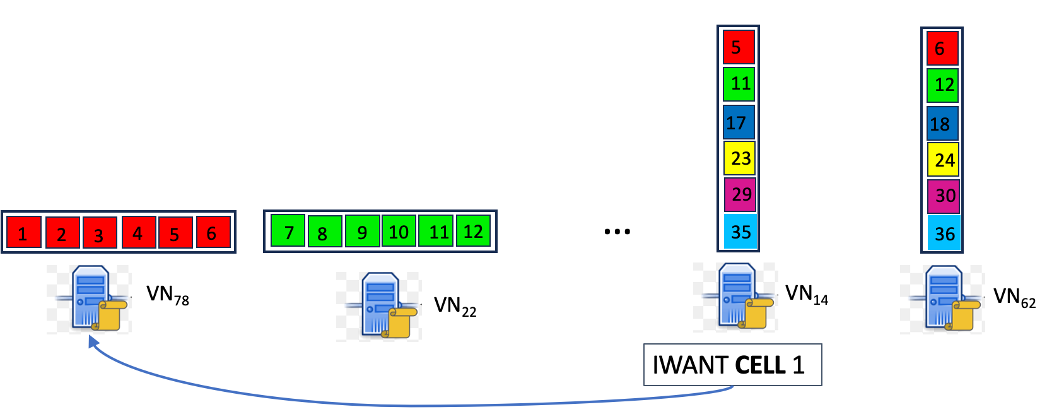
Figure 2: Two (extreme) strategies to distribute row samples to the VNs in the corresponding row’s region.
Phase 2- Row/Column Consolidation and Sampling: VNs that are part of the current slot’s committee aim to complete random sampling within the slot’s first four seconds (i.e., voting deadline). To boost the availability of cells, particularly for the committee members of the slot who must perform (random) sampling within four seconds, the VNs also consolidate, i.e., retrieve the full row and column they are assigned to based on the FNODE mapping as part of row/column sampling.
2.a) VN Random Sampling: The VNs in the current slot’s committee attempt to retrieve 73 randomly chosen cells as soon as they receive their seed samples from the builder.
Using the deterministic assignment FNODE, VNs can locally determine the nodes expected to eventually custody a given row or column.
Sampling Algorithm: Some of these nodes may be offline or otherwise unresponsive. Sequentially sending requests for cells risks missing the 4-second deadline for the committee members.
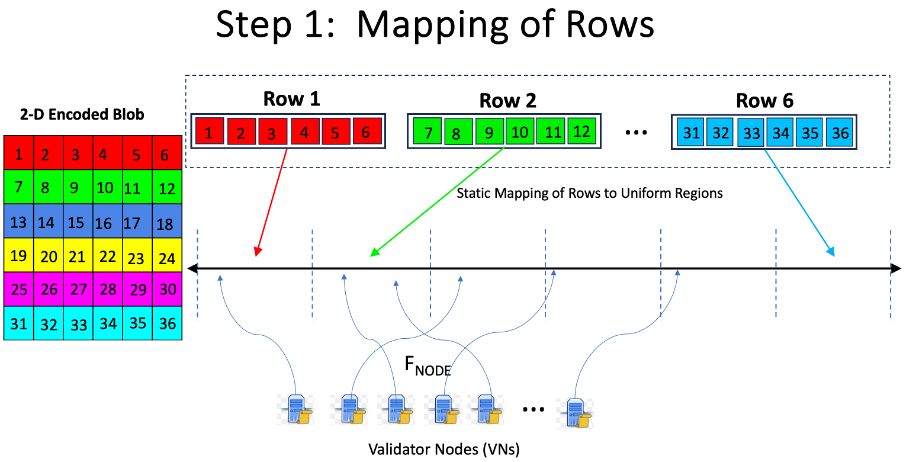
Figure 3: Sample Fetching Example: The rows and columns assigned to each VN are shown on the top of the corresponding VN. VN14 knows to send a request to VN78 to retrieve cell one based on the knowledge of the mapping FNODE.
At the same time, sending requests to all peers holding copies will lead to an explosion of messages in the network and bear the risk of congestion. Fetching must, therefore, seek a tradeoff between the use of parallel and redundant requests on the one hand and latency constraints on the other hand. Our approach employs an adaptive cell-fetching strategy using direct communication between nodes through a UDP-based (connectionless) protocol. The fetching algorithm can tolerate losses and offline nodes.
2.b) VN Row/Column Consolidation: If a VN receives less than half of the cells of its assigned row or column from the builder (as a consequence of the builder’s chosen distribution strategy), it requests the missing cells from other VNs. A VN requests cells from only the VNs assigned to the same row/column’s region during row/column consolidation. When a VN has half of the cells of a row or column, it can locally reconstruct the entire row or column.
The Rationale for Consolidating Row/Column:
- Reconstructing missing cells: while performing row/column sampling, VNs reconstruct missing cells.
- To boost the availability of cells: Given the deterministic mapping (FNODE), the builder can choose any distribution strategy to send subsets of rows and columns to the VNs. Row/Column consolidation aims to improve the availability of samples so that random sampling can be completed on time.
Ideally, the builder should select a seed sample distribution strategy that enables VNs to consolidate rows and columns efficiently. To facilitate this, the builder can push each VN a map (together with the seed samples) that details how individual cells of a row/column are assigned to VNs within that row/column’s region as part of the builder’s distribution strategy. With this map, VNs can quickly identify and retrieve missing cells to reconstruct a complete row, thereby improving the availability of the data.
NOTE: In some DAS approaches, the term ‘row/column sampling’ refers to nodes retrieving multiple rows and columns before voting on the availability of the blob. In our approach, nodes retrieve rows and columns to enhance data availability, supporting validators who must perform random sampling before they vote.
We refer to this as ‘row/column consolidation’ instead of ‘row/column sampling’ because in PANDAS, committee members vote based on random sampling, and they do not directly sample entire rows or columns.
What about Regular Nodes (RNs)?
Unlike VNs, RNs do not obtain seed row/column samples from the builder. The builder sends initial seed samples to a Sybil-resistant group of VNs that use the Proof-of-Validator scheme. There is currently no mechanism for RNs to prove that they are not Sybils; therefore, the initial distribution of samples from the builder only uses VNs.
Using the public deterministic function FNODE, RNs can be similarly mapped to individual row/column regions. Once mapped to a region, RNs can (optionally) perform row/column consolidation to retrieve entire rows and columns and respond to queries for cells within their assigned region.
Like other nodes, RNs must perform peer discovery. In general, RNs aim to discover all the VNs and can also seek to discover other RNs. Given the knowledge of other peers through peer discovery, RNs can perform random sampling through direct communication. Unlike VNs, RNs are not under strict time constraints to complete sampling — they can start sampling after the VNs, for instance, after receiving the block header for the current slot.
Discussion & On-going Work
We assume rational builders to have an incentive to cut costs (and under provision) but, at the same time, aim to make blocks available (to be rewarded). This implies that the builders will aim for the row/column consolidation to be as efficient as possible, i.e., with efficient consolidation, which boosts the availability of cells, the builder can send less copies of each cell during the seeding phase to cut costs.
We are currently experimenting with different distribution strategies with malicious VNs withholding samples and attempting to disrupt peer discovery. Our DAS simulation code is available on DataHop GitHub repository.
[1] Lancaster University, UK
2 City, University London, UK
3 Université catholique de Louvain (UCLouvain)
4 DataHop Labs





