

In this article, Vitalik summarizes and analyzes the historical research and latest research and development progress of the above-mentioned many technical routes related to scalability, and supplements the new possibilities such as trustless and L1 native rollups under new technical conditions.
Original text: Possible futures of the Ethereum protocol, part 2: The Surge (vitalik.eth)
Author: vitalik.eth
Compiled by: 183Aaros, Yewlne, LXDAO
Translator's words
“Breaking the scalability trilemma is very hard, but not impossible, and it requires thinking in a way that is outside the box that the argument implies.” — Vitalik Buterin
In order to solve the scalability trilemma, Ethereum has had many technical ideas and attempts in various historical periods, from state channels, sharding, rollups, Plasma, to the large-scale "data availability" that is the focus of the current ecosystem. It was not until The Surge roadmap in 2023 that Ethereum chose this technical philosophy path that follows the "centered on the robustness and decentralization of L1, and the diversified development of pluralistic L2s", which may be able to overcome the trilemma. As a sequel to the previous article "The Possible Future of Ethereum Protocol (I): The Merge", in this article, Vitalik summarizes and analyzes the historical research and latest research and development progress of the above-mentioned many technical routes related to scalability, and supplements the new possibilities such as trustless and L1 native rollups under new technical conditions.
Overview
This article is about 11,000 words and has 7 parts. It is estimated to take 60 minutes to read the article.
- Supplement: Scalability trilemma
- Further progress on data availability sampling
- Data compression
- Universal Plasma
- Mature L2 proof systems
- Cross-L2 interoperability and user experience improvements
- Extended execution on L1
Content
The Possible Future of the Ethereum Protocol (Part 2): The Surge
Special thanks to Justin Drake, Francesco, Hsiao-wei Wang, @antonttc and Georgios Konstantopoulos
Initially, Ethereum had two scaling strategies in its roadmap. One (see this early paper from 2015) was “sharding”: instead of validating and storing all transactions in the chain, each node only has to validate and store a small fraction of the transactions. Other peer-to-peer networks (e.g. BitTorrent) work this way, so of course we could have blockchains work the same way. The other was Layer 2 protocols: networks that sit on top of Ethereum and can take advantage of its security while keeping most data and computation off the main chain. “Layer 2 protocols” meant state channels in 2015, Plasma in 2017, and then rollups in 2019. Rollups are more powerful than state channels or Plasma, but they require a lot of on-chain data bandwidth. Fortunately, by 2019, sharding research had solved the problem of validating “data availability” at scale. As a result, the two paths converged and we got a roadmap centered around rollups, which is still Ethereum’s scaling strategy today.
The rollup-centric roadmap proposes a simple division of labor: Ethereum L1 focuses on being a robust and decentralized base layer, while L2 is tasked with helping the ecosystem scale. This model can be seen everywhere in society: the court system (L1) does not exist to be extremely efficient, but to protect contracts and property rights, and entrepreneurs (L2) build on top of a solid base layer and take humans to Mars (figuratively and literally).
This year, the rollup-centric roadmap has had important successes: Ethereum L1 data bandwidth has increased significantly with the advent of EIP-4844 blobs, and multiple EVM rollups are now in phase 1. A path to highly heterogeneous and diversified sharded applications has become a reality, where each L2 acts as a "shard" with its own internal rules and logic. But as we have seen, taking this path has its own unique challenges. So now our task is to complete the rollup-centric roadmap and solve these problems while maintaining the robustness and decentralization of Ethereum L1.
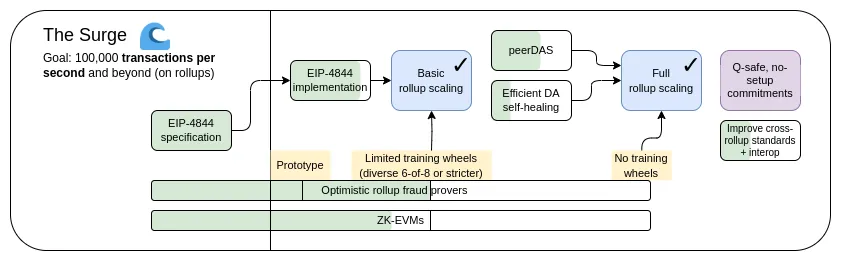
The Surge: Primary Objectives
- 100,000+ TPS on L1+L2
- Keep L1 decentralized and robust
- At least some L2 fully inherits the core properties of Ethereum (trustless, open, censorship-resistant)
- Maximize interoperability between L2s. Ethereum should feel like one ecosystem, not 34 different blockchains.
In this chapter
- Supplement: Scalability trilemma
- Further progress on data availability sampling
- Data compression
- Universal Plasma
- Mature L2 proof systems
- Cross-L2 interoperability and user experience improvements
- Extended execution on L1
Additional: Scalability trilemma
The scalability trilemma is an idea proposed in 2017, which mainly discusses the contradiction between the following three properties: decentralization (more specifically: low cost of running a node), scalability (more specifically: the ability to handle a high number of transactions) and security (more specifically: an attacker needs to compromise a large portion of the network's nodes before a single transaction can fail).
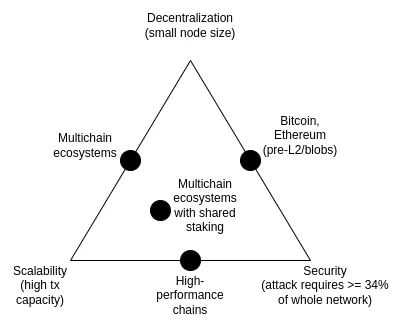
It’s worth noting that the trilemma is not a theorem, and the paper that introduces it does not provide a mathematical proof . It does give a heuristic mathematical argument: if nodes that support decentralization (such as consumer laptops) can verify N transactions per second, and there is a chain that processes k*N transactions per second, then either (i) each transaction is only seen by 1/k of the nodes, meaning that an attacker only needs to compromise a few nodes to push a malicious transaction through, or (ii) the nodes are so powerful that it is difficult to decentralize. This article is not intended to show that breaking the trilemma is impossible; rather, it aims to clarify why breaking the trilemma is very difficult - it requires thinking outside the box in a certain way that the argument implies.
Over the years, some high-performance chains have often claimed that they can solve the trilemma by using software engineering techniques to optimize nodes without elaborate design at the infrastructure level. Such claims are misleading, and running nodes on such chains is much more difficult than in Ethereum. This blog post dives into why this is the case (and why L1 client software engineering alone cannot scale Ethereum itself).
However, the combination of data availability sampling and SNARKs does solve the trilemma : it allows clients to verify the availability of a certain amount of data, and verify that some computational steps were performed correctly with less computational effort while downloading only a small portion of that data. SNARKs are trustless. Data availability sampling has a subtle few-of-N trust model, but it still retains the fundamental property of non-scalable chains - even a 51% attack cannot force the network to accept malicious blocks .
Another approach to solving the trilemma is the Plasma architecture, which uses clever techniques to push the responsibility of monitoring data availability onto users in an incentive-compatible way. Back in 2017-2019, when all we had to do to scale computation was fraud proofs, Plasma's security features were very limited. When SNARKs became mainstream, the use cases for the Plasma architecture became much broader than before.
Further progress on data availability sampling
What problem are we trying to solve?
As of March 13, 2024, when the Dencun upgrade goes live, the Ethereum blockchain will have 3 "blobs" of approximately 125 kB per 12-second slot, or approximately 375 kB of available data bandwidth per slot . Assuming that transaction data is published directly on the chain and an ERC20 transfer is approximately 180 bytes, the maximum TPS of rollups on Ethereum is:
375000 / 12 / 180 = 173.6 TPS
If we add in Ethereum’s calldata [theoretical maximum: 30 million gas per slot / 16 gas per byte = 1,875,000 bytes per slot], this number becomes 607 TPS. If using PeerDAS, the plan is to increase the blob count target to 8-16, which will give a speed of 463-926 TPS after adding in calldata.
Compared to Ethereum L1, this is already a big improvement. But it’s far from enough, we also want better scalability. Our mid-term goal is 16 MB per slot , and if combined with improvements in rollup data compression, the speed will increase to about 58,000 TPS.
What is it and how is it done?
PeerDAS is a relatively simple implementation of "1D sampling". Every blob in Ethereum is a degree-4096 polynomial over a 253-bit prime field. We broadcast "shares" of the polynomial, each consisting of 16 evaluations at adjacent 16 coordinates drawn from a set of 8192 coordinates. Any 4096 of the 8192 evaluations (using the currently proposed parameters: any 64 of the 128 possible samples) can recover the blob.
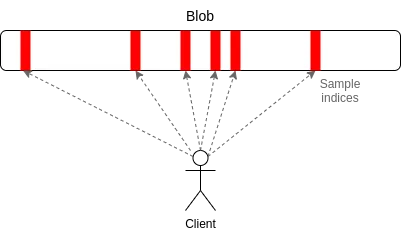
The working principle of PeerDAS is: each client only listens to a few subnets, among which the i-th subnet is responsible for broadcasting the i-th sample of the blob; when the client needs to obtain blobs on other subnets, it can initiate requests to nodes listening to different subnets through the global p2p network. Compared with PeerDAS, SubnetDAS is more conservative. It only retains the subnet mechanism and removes the process of mutual inquiry between nodes. According to the current proposal, nodes participating in proof of stake will use SubnetDAS, while other nodes (ie "clients") use PeerDAS.
Theoretically, the expansion space of 1D sampling is quite large: if we increase the maximum number of blobs to 256 (the corresponding target is 128), we can reach the target capacity of 16MB. In this case, the bandwidth overhead required for each node to perform data availability sampling is calculated as follows:
16 samples × 128 blobs × 512 bytes (single sample size per blob) = 1MB bandwidth/time slot;
This bandwidth requirement is just on the edge of acceptable range: while technically possible, bandwidth-constrained clients will not be able to participate in sampling. We can optimize this solution by reducing the number of blobs and increasing the size of each blob, but such data reconstruction solutions are more expensive.
To further improve performance, 2D sampling technology can be used - sampling both within a single blob and between different blobs, using the linear characteristics of KZG commitments to "expand" the set of blobs in the block and generate a series of new "virtual blobs". These "virtual blobs" store the same information through redundant encoding.
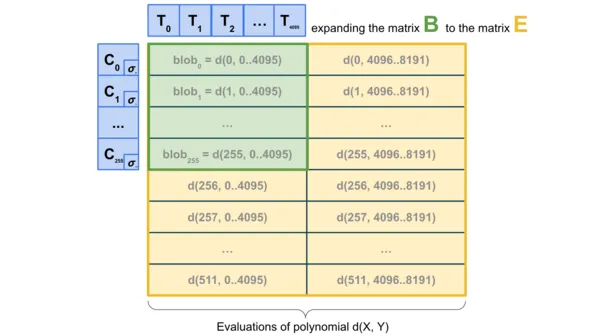
This scheme has an important feature: the expansion process of calculating commitments does not require obtaining complete blob data, which makes it naturally suitable for the construction of distributed blocks. Specifically, the node responsible for building blocks only needs to hold the KZG commitment of the blob to verify the availability of these blobs through the DAS system. Similarly, one-dimensional DAS (1D DAS) also has this kind of advantage in building distributed blocks.
What are the connections with existing research?
- Original post introducing data availability (2018): https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
- Follow-up paper: https://arxiv.org/abs/1809.09044
- Explainer post on DAS, paradigm: https://www.paradigm.xyz/2022/08/das
- 2D availability with KZG commitments: https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
- PeerDAS on ethresear.ch: https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541, and paper: https://eprint.iacr.org/2024/1362
- Presentation on PeerDAS by Francesco: https://www.youtube.com/watch?v=WOdpO1tH_Us
- EIP-7594: https://eips.ethereum.org/EIPS/eip-7594
- SubnetDAS on ethresear.ch: https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
- Nuances of recoverability in 2D sampling: https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
What else is there to do, and what trade-offs need to be made?
The current priority is to complete the development and deployment of PeerDAS. The next step is to gradually promote it - by continuously monitoring network conditions and optimizing software performance, while ensuring system security, steadily improving PeerDAS's blob processing capacity. At the same time, we need to promote more academic research, formally verify PeerDAS and other DAS variants, and conduct in-depth research on their interactions with issues such as the security of the fork selection rule.
In future work, we need to further study and determine the optimal implementation form of two-dimensional DAS and rigorously prove its security. Another long-term goal is to find an alternative to KZG that is both quantum-resistant and trusted-setup-free. However, we have not yet found any candidate solutions suitable for distributed block construction. Even the computationally expensive "brute force" method of using recursive STARKs to generate rows and columns and reconstruct validity proofs is not very effective - although theoretically, the size of STARK after STIR only requires O(log(n) * log(log(n)) hash values, but in practical applications, the amount of STARK data is still close to the size of a complete blob.
In the long run, I think there are several feasible development paths:
- Adopting the ideal two-dimensional DAS solution
- Continue to use the one-dimensional DAS solution - although it will sacrifice sampling bandwidth efficiency and need to accept a lower data capacity limit, it can ensure the simplicity and robustness of the system
- (Major shift) Completely abandon data availability sampling (DA) and focus on Plasma as the Layer 2 architecture solution
We can weigh the pros and cons of these solutions from the following dimensions:
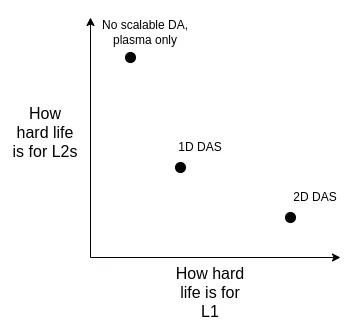
It is important to point out that even if we decide to expand capacity directly on L1, the trade-offs of these technical choices still exist . This is because: if L1 is to support high TPS, the block size will increase significantly. In this case, client nodes need an efficient verification mechanism to ensure that the blocks are correct. This means that we have to apply the underlying technologies originally used for rollup (such as ZK-EVM and DAS, etc.) on L1.
How does it interact with the rest of the roadmap?
The implementation of data compression (see below) will significantly reduce or postpone the need for 2D DAS; if Plasma is widely adopted, the demand will drop further. However, DAS also brings new challenges to the construction of distributed blocks: although DAS is theoretically conducive to distributed reconstruction, in practice, we need to seamlessly integrate it with inclusion list proposals and related fork selection mechanisms.
Data compression
What problem are we trying to solve?
In a rollup, each transaction requires considerable data space on the chain: an ERC20 transfer transaction requires about 180 bytes. Even with an ideal data availability sampling mechanism, this will still limit the scalability of the second-layer protocol. According to the 16 MB data capacity per time slot, it is easy to get: 16000000 / 12 / 180 = 7407 TPS
In addition to optimizing the numerator, what effect would it have if we could also address the denominator problem — that is, reduce the number of bytes occupied on the chain by each transaction in the rollup?
What is it and how is it done?
I think the best explanation is this picture from two years ago:
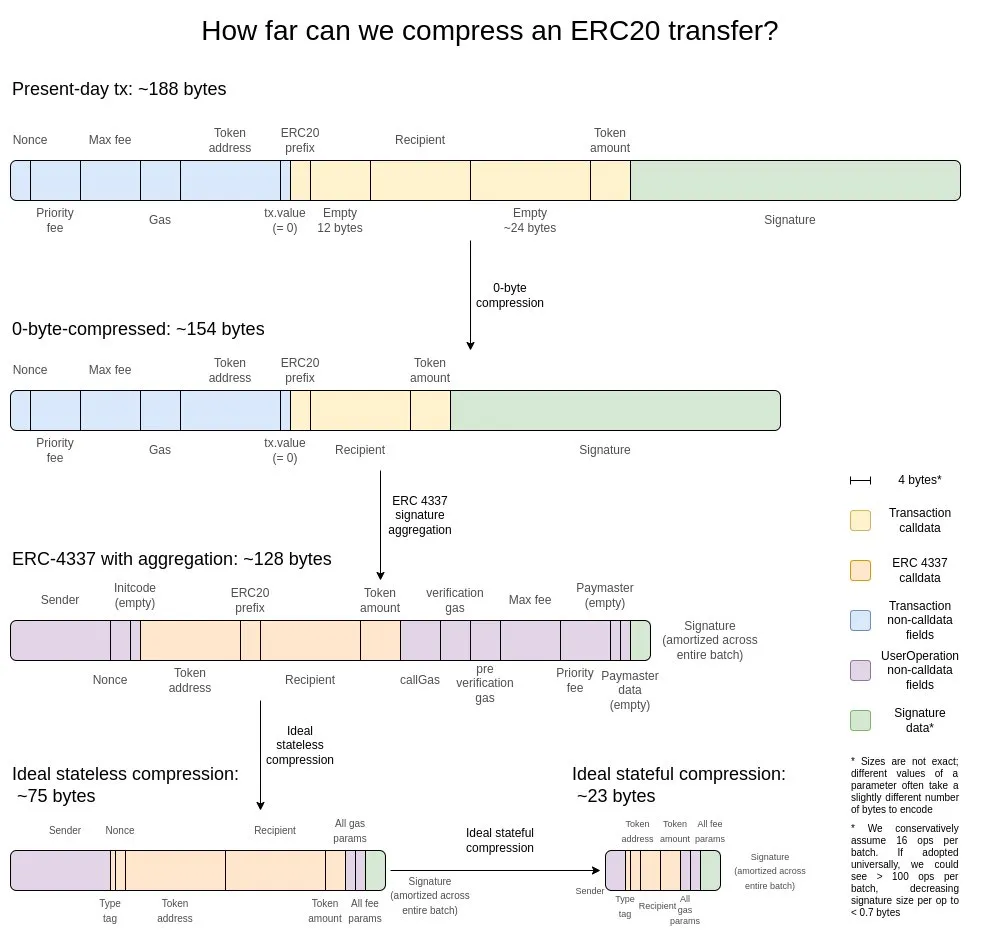
The first is the most basic optimization method - zero-byte compression: using two bytes to represent the length of a continuous sequence of zero bytes, thereby replacing the original zero-byte string. To achieve deeper optimization, we can use the following features of transactions:
- Signature aggregation — Migrating the signature system from ECDSA to BLS, which can merge multiple signatures into a single signature while verifying the validity of all original signatures. Although this solution is not suitable for L1 due to the high computational overhead of verification (even in an aggregated scenario), its advantages are very obvious in data-constrained environments such as L2. The aggregation feature of ERC-4337 provides a feasible technical path to achieve this goal.
- Address pointer replacement mechanism - For addresses that have appeared in history, we can replace the original 20-byte address with a 4-byte pointer (pointing to the location in the historical record). This optimization can bring the greatest benefits, but it is relatively complex to implement because it requires the blockchain's historical records (at least part of the history) to be substantially integrated into the state set.
- Custom serialization scheme for transaction amounts - Most transaction amounts actually contain only a small number of significant digits. For example, 0.25 ETH is represented as 250,000,000,000,000,000 wei in the system. The max-basefee and priority fee of gas also have similar characteristics. Based on this feature, we can use a custom decimal floating point format, or establish a dictionary of commonly used values, thereby greatly compressing the storage space of currency values.
What are the connections with existing research?
- Exploration from sequence.xyz: https://sequence.xyz/blog/compressing-calldata
- Calldata-optimized contracts for L2s, from ScopeLift: https://github.com/ScopeLift/l2-optimizoooors
- An alternative strategy - validity-proof-based rollups (aka ZK rollups) post state diffs instead of transactions: https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975
- BLS wallet - an implementation of BLS aggregation through ERC-4337: https://github.com/getwax/bls-wallet
What else is there to do, and what trade-offs need to be made ?
The current priority is to implement the above solution. This involves the following key trade-offs:
- BLS Signature Migration - Switching to the BLS signature system requires a lot of engineering resources and reduces compatibility with security-enhanced trusted hardware (TEE). A viable alternative is to use ZK-SNARK encapsulation of other signature algorithms.
- Dynamic Compression Implementation - Implementing dynamic compression mechanisms such as address pointer replacement can significantly increase the complexity of client code.
- State difference publishing - Choosing to publish state differences instead of full transactions to the chain will weaken the auditability of the system and cause existing infrastructure such as block explorers to fail to function properly.
How does it interact with the rest of the roadmap?
By introducing ERC-4337 and eventually standardizing some of its functions in L2 EVM, the deployment process of aggregation technology will be significantly accelerated. Similarly, incorporating some of the functions of ERC-4337 into L1 will also promote its rapid implementation in the L2 ecosystem.
General Plasma Architecture
What problem are we trying to solve?
Even with the combination of 16MB blob storage and data compression technology, the processing power of 58,000 TPS is still not enough to fully support high-bandwidth scenarios such as consumer payments and decentralized social networks. This problem becomes more prominent when we consider the introduction of privacy protection mechanisms, because privacy features may reduce the scalability of the system by 3 to 8 times. Currently, an option for high-throughput, low-value content application scenarios is validium. It uses an off-chain data storage model and implements a unique security model: operators cannot directly steal user assets, but they may temporarily or permanently freeze user funds by losing connection. However, we have the opportunity to build a better solution.
What is it and how is it done?
Plasma is a scaling solution. Unlike rollups, which put full block data on-chain, Plasma operators generate blocks off-chain and only record the Merkle root of the block on-chain. For each block, operators distribute Merkle branches to users to prove the state changes (or non-changes) associated with that user's assets. Users can withdraw their assets by providing these Merkle branches. A key feature is that these Merkle branches do not have to point to the latest state - this means that even in the event of data availability failures, users can still recover their assets by extracting the latest available state they have. If a user submits an invalid branch (such as trying to extract assets that have been transferred to others, or the operator attempts to create assets out of thin air), the on-chain challenge mechanism can arbitrate asset ownership.
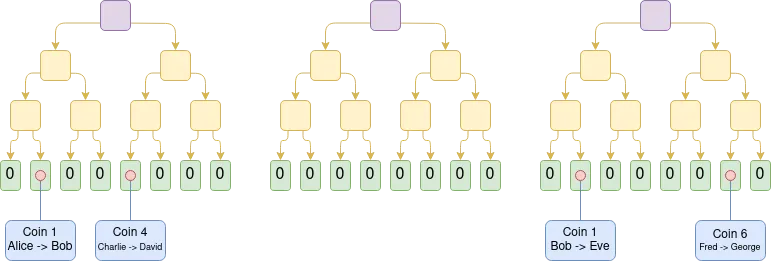
Early implementations of Plasma were limited to payment scenarios, making it difficult to achieve broader functional expansion. However, if we introduce SNARK to verify each root node, Plasma's capabilities will be significantly improved. Since this approach can fundamentally eliminate the possibility of cheating by most operators, the challenge mechanism can be greatly simplified. At the same time, this also opens up new application paths for Plasma technology, enabling it to expand to more diverse asset types. More importantly, in the case of honest behavior by operators, users can withdraw funds instantly without having to wait for a week-long challenge period.
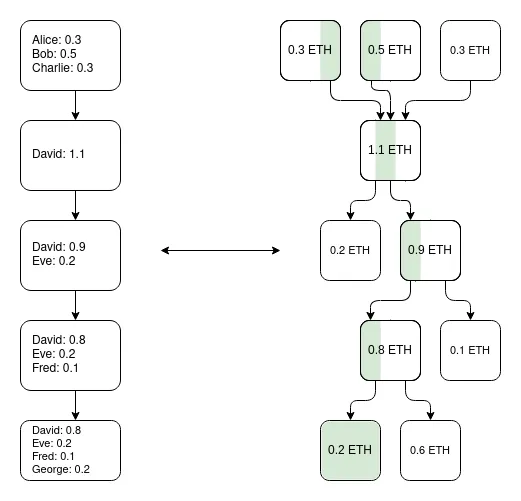
An important insight is that the Plasma system does not need to be perfect. Even if it can only protect a portion of assets (for example, only protect tokens that have not been transferred in the past week), it has greatly improved the status quo of the ultra-scalable EVM, which is a validity.
Another architectural solution is a hybrid mode of plasma/rollup, of which Intmax is a typical example. This type of architecture stores only a very small amount of user data on the chain (about 5 bytes per user), thus achieving a balance between plasma and rollup in terms of characteristics: Taking Intmax as an example, it achieves extremely high scalability and privacy, but even in the scenario of 16 MB data capacity, its theoretical throughput is limited to about 266,667 TPS (calculation method: 16,000,000/12/5).
What are the connections with existing research?
- Original Plasma paper: https://plasma.io/plasma-deprecated.pdf
- Plasma Cash: https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
- Plasma Cashflow: https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#🚪-Exit
- Intmax (2023): https://eprint.iacr.org/2023/1082
What else is there to do, what trade-offs need to be made?
The current core task is to push the Plasma system into production. As mentioned earlier, the relationship between Plasma and Validium is not either-or: any validium can improve its security properties by integrating Plasma features in its exit mechanism, even if it is a subtle improvement. Research focuses include:
- Finding optimal performance parameters for the EVM (from the perspectives of trust assumptions, L1 worst-case gas overhead, and DoS resistance)
- Explore alternative architectures for specific use cases
At the same time, we need to address head-on the problem that Plasma is more conceptually complex than rollups, which requires a dual path of theoretical research and optimization of a general framework.
The main trade-off of adopting a Plasma architecture is that it is more operator-dependent and harder to make “based,” although hybrid plasma/rollup architectures can often circumvent this disadvantage.
How does it interact with the rest of the roadmap?
The higher the utility of the Plasma solution, the less pressure there is on the L1 layer to provide high-performance data availability. At the same time, migrating on-chain activities to L2 can also reduce the MEV pressure at the L1 level.
Mature L2 proof system
What problem are we trying to solve?
Currently, most rollups are not truly trustless — they all have safety committees that can intervene in the behavior of the (optimistic or validity) proof system. In some cases, the proof system is completely missing or has only "advisory" functionality. The most progress in this area is: (i) some application-specific rollups (such as Fuel) have achieved trustlessness; and (ii) as of this writing, two full EVM rollups — Optimism and Arbitrum — have reached a partial trustlessness milestone called "stage 1". The main obstacle that has prevented rollups from further development is concerns about code vulnerabilities. To achieve truly trustless rollups, we must address this challenge head-on.
What is it and how is it done?
First, let's review the "stage" system introduced in the previous article. Although the full requirements are more detailed, the main points are summarized as follows:
- Phase 0 : Users must be able to independently run a node and complete chain synchronization. The verification mechanism can be fully centralized or trust-based .
- Phase 1 : The system must implement a (trustless) proof mechanism to ensure that only valid transactions are accepted. A security committee is allowed to intervene in the proof system , but a 75% voting threshold must be reached. At the same time, more than 26% of the committee members must come from outside the main development company. A less powerful upgrade mechanism (such as a DAO) can be used, but a sufficiently long time lock must be set to ensure that users can safely withdraw funds before malicious upgrades take effect.
- Phase 2 : The system must implement a (trustless) proof mechanism to ensure that only valid transactions are accepted. The security committee can only intervene when there is a clear code defect , such as: two proof systems conflict, or a single proof system generates different post-state roots for the same block (or does not generate any results for a long time, such as a week). It is allowed to set up an upgrade mechanism, but an extremely long time lock must be used.
Our ultimate goal is to reach Phase 2. The key challenge in moving towards Phase 2 is to ensure that people have enough trust in the proof system and consider it trustworthy . There are currently two main paths to achieve this:
- Formal Verification : We can use modern mathematics and computer science techniques to prove (optimistic or validity) that the proof system will only accept blocks that conform to the EVM specification. Although this type of technology has been around for decades, recent technological breakthroughs (such as Lean 4) have greatly improved its practicality, and the development of AI-assisted proofs is expected to further accelerate this process.
- Multi-proof mechanism : Build multiple proof systems and deposit funds in a 2/3 multi-signature (or higher threshold) contract controlled by these systems and the Security Committee (and/or other components based on trust assumptions, such as TEE). When the proof systems reach a consensus, the Security Committee has no decision-making power; when there is a disagreement between the systems, the Security Committee can only choose one of the existing results, but cannot force its own solution.
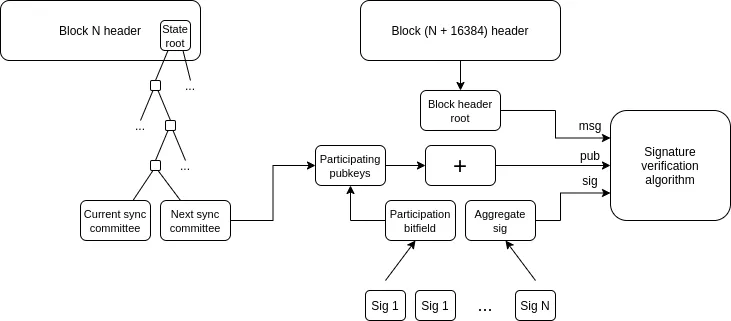
What are the connections with existing research?
- EVM K Semantics (formal verification work started in 2017): https://github.com/runtimeverification/evm-semantics
- Presentation on the idea of multi-provers (2022): https://www.youtube.com/watch?v=6hfVzCWT6YI
- Taiko plans to use multi-proofs: https://docs.taiko.xyz/core-concepts/multi-proofs/
What else is there to do, and what trade-offs need to be made?
There is still a lot of work to be done on the formal verification front. We need to develop a formally verified version of the full SNARK prover for the EVM. This is an extremely complex project, although we are already working on it. However, there is a technical solution that can significantly reduce the complexity: we can first build a formally verified SNARK prover for a minimal virtual machine (such as RISC-V or Cairo), and then implement the EVM on this minimal virtual machine (while formally proving its equivalence to other EVM specifications).
There are two core issues to be addressed with regard to multi-proof mechanisms: First, we need to have sufficient confidence in at least two different proof systems. This requires that these systems not only have sufficient security on their own, but also that even if they fail, they fail for different and unrelated reasons (so that they don’t all crash at the same time). Second, we need to establish extremely high credibility in the underlying logic that merges these proof systems. This part of the code is relatively small. Although there are ways to simplify it further - such as depositing funds into a Safe multi-signature contract, with contracts representing each proof system as signatories - this solution will incur high on-chain gas costs. Therefore, we need to find the right balance between efficiency and security.
How does it interact with the rest of the roadmap?
Migrating on-chain activities to L2 can alleviate MEV pressure on L1.
Cross-L2 interoperability improvements
What problem are we trying to solve?
A major challenge facing the current L2 ecosystem is that it is difficult for users to switch seamlessly between different L2s. Worse still, those seemingly convenient solutions often reintroduce trust dependencies - such as centralized cross-chain bridges, RPC clients, etc. If we really want L2 to be an organic part of the Ethereum ecosystem, we must ensure that users can get a unified experience consistent with the Ethereum mainnet when using the L2 ecosystem.
What is it and how is it done?
Improvements in cross-L2 interoperability involve multiple dimensions. In theory, the rollup-centric Ethereum architecture is essentially equivalent to L1 execution sharding. Therefore, by comparing this ideal model, we can find the gaps in the current Ethereum L2 ecosystem in practice. Here are the main aspects:
- Chain-specific addresses : Chain identifiers (such as L1, Optimism, Arbitrum, etc.) should be part of the address. Once implemented, the cross-layer transfer process will become simple: users only need to enter the address in the "Send" column, and the wallet will automatically handle subsequent operations (including calling the cross-chain bridge protocol).
- Chain-specific payment requests : A standardized mechanism should be established to simplify the processing of requests such as "send me X amount of Y type tokens on chain Z". The main application scenarios include:
- Payment scenarios: including inter-personal transfers and merchant payments
- DApp funding request: Like the Polymarket example above
- Cross-chain exchange and gas payment : A standardized open protocol needs to be established to handle cross-chain operations, such as:
- "I will pay 1 ETH on Optimism in exchange for 0.9999 ETH paid to me on Arbitrum"
- "I will pay 0.0001 ETH on Optimism to anyone willing to package this transaction on Arbitrum"
- Light client : Users should be able to directly verify the chain they interact with, rather than relying entirely on RPC service providers. Helios developed by A16z crypto has already implemented this feature on the Ethereum mainnet, and now we need to extend this trustless feature to the L2 network. ERC-3668 (CCIP-read) provides a feasible implementation solution.
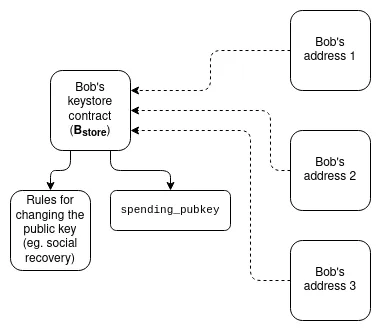
Keystore Wallets : Currently, if you wish to update the keys that control a smart contract wallet, you must do so on all N chains that wallet exists on. Keystore wallets are a technology that allows keys to exist in only one place (either on L1, or potentially on L2 in the future), and then be read from any L2 that has a copy of the wallet. This means updates only need to be done once. To be efficient, Keystore Wallets require L2 to provide a standardized way to costlessly read L1; two proposals for this are L1SLOAD and REMOTESTATICCALL.
- A more radical “shared token bridge” idea : Imagine a world where all L2s are proof-of-validity rollups that commit to Ethereum every slot. Even in this case, wanting to move assets “natively” between L2s still requires withdrawals and deposits, which require paying large L1 gas fees. One way to solve this problem is to create a shared minimal rollup whose only function is to maintain the balances of various types of tokens owned by each L2, and allow those balances to be updated en masse through a series of cross-L2 send operations initiated by any L2. This would enable cross-L2 transfers to occur without having to pay L1 gas fees for each transfer, and without the need for liquidity provider-based technology like ERC-7683.
- Synchronous composability : Allows synchronous calls between a specific L2 and L1, or between multiple L2s. This may help improve the financial efficiency of DeFi protocols. The former can be done without any cross-L2 coordination; the latter requires the use of shared ordering. Based rollup is naturally friendly to all of these technologies.
What are the connections with existing research?
- Chain-specific addresses: ERC-3770: https://eips.ethereum.org/EIPS/eip-3770
- ERC-7683: https://eips.ethereum.org/EIPS/eip-7683
- RIP-7755: https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
- Scroll keystore wallet design: https://hackmd.io/@haichen/keystore
- Helios: https://github.com/a16z/helios
- ERC-3668 (sometimes called CCIP-read): https://eips.ethereum.org/EIPS/eip-3668
- Proposal for "based (shared) preconfirmations" by Justin Drake: https://ethresear.ch/t/based-preconfirmations/17353
- L1SLOAD (RIP-7728): https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
- REMOTESTATICCALL in Optimism: https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
- AggLayer, which includes shared token bridge ideas: https://github.com/AggLayer
What else is there to do, and what trade-offs need to be made?
Many of the examples above face the common dilemma of standardization: when to standardize, and at what level. Standardizing too early can entrench inferior solutions; standardizing too late can lead to unnecessary fragmentation. In some cases, there are both short-term solutions that are weak but easy to implement, and long-term solutions that take considerable time to implement but are “finally correct.”
What is unique about this section is that these tasks are not only technical problems, but may even be primarily social problems. They require cooperation from L2, wallets, and L1. Our ability to successfully handle this is a test of our ability to unite as a community.
How does it interact with the rest of the roadmap?
Most of these proposals are “high-level” constructs and therefore have little impact on L1 level considerations. The only exception is shared ordering, which has a significant impact on MEV.
Extending execution on L1
What problem are we trying to solve?
If L2 becomes very scalable and successful, but L1 is still only able to process a very small number of transactions, Ethereum could face a number of risks:
- The economics of ETH assets will become more risky, affecting the long-term security of the network.
- Many L2s benefit from close ties to the highly developed financial ecosystem on L1, and if this ecosystem is significantly weakened, the incentive to become an L2 (rather than an independent L1) will also be weakened.
- It will take a long time for L2 to achieve exactly the same safety guarantees as L1.
- If an L2 fails (e.g., due to malicious behavior or the disappearance of the operator), users will still need to recover their assets through L1. Therefore, L1 needs to be powerful enough to actually handle the highly complex and messy shutdown process of L2 at least occasionally.
For these reasons, it is valuable to continue to expand L1 itself and ensure that it can continue to meet the demands of growing usage.
What is it and how does it work?
The simplest way to scale is to simply increase the gas limit. However, this could lead to centralization of L1, which would undermine another important feature of Ethereum L1 as a strong base layer: its trustworthiness. There is ongoing debate about how sustainable simply increasing the gas limit is, and it also depends on what other techniques are implemented to make larger blocks easier to verify (such as historical data expiration, statelessness, L1 EVM validity proofs). Another important area that needs continuous improvement is the efficiency of Ethereum client software, which is much more optimized today than it was five years ago. An effective L1 gas limit increase strategy will involve accelerating the advancement of these verification technologies.
Another scaling strategy involves identifying specific functions and types of computation that can be reduced in cost without compromising the network’s decentralization or its security properties. Examples of this include:
- EOF: A new EVM bytecode format that is more conducive to static analysis and allows for faster implementations. Given these efficiencies, EOF bytecode can be given a lower gas cost.
- Multidimensional gas pricing: Establishing base fees and limits for compute, data, and storage separately allows increasing the maximum capacity of Ethereum L1 without increasing its maximum capacity (and thus avoiding new security risks).
- Lowering gas costs for specific opcodes and precompiles : Historically, we have raised the gas costs of certain underpriced operations for several rounds to avoid denial of service attacks. Something we do less often, but could do more to lower the gas costs of overpriced operations. For example, addition is much cheaper than multiplication, but currently the ADD and MUL opcodes cost the same. We could make ADD cheaper, and even simpler opcodes like PUSH cheaper.
- EVM-MAX and SIMD : EVM-MAX ("Modular Arithmetic Extensions") is a proposal that allows for more efficient native large-number modular operations in a separate module of the EVM. Values computed by EVM-MAX are only accessible to other EVM-MAX opcodes unless intentionally exported; this allows these values to be stored in an optimized format that provides more space. SIMD ("Single Instruction Multiple Data") is a proposal that allows the same instruction to be executed efficiently on a set of values. The two combined can create a powerful coprocessor next to the EVM that can be used to implement cryptographic operations more efficiently. This is particularly useful for privacy protocols and L2 proof systems, and thus helps to scale L1 and L2.
These improvements will be discussed in more detail in a future Splurge blog post.
Finally, the third strategy is native rollup (or “enshrined rollups”): essentially, creating multiple copies of the EVM running in parallel, forming a model equivalent to the functionality provided by rollup, but more natively integrated into the protocol.
What are the connections with existing research?
- Polynya's Ethereum L1 scaling roadmap: https://polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
- Multidimensional gas pricing: https://vitalik.eth.limo/general/2024/05/09/multidim.html
- EIP-7706: https://eips.ethereum.org/EIPS/eip-7706
- EOF: https://evmobjectformat.org/
- EVM-MAX: https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
- SIMD: https://eips.ethereum.org/EIPS/eip-616
- Native rollups: https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
- Interview with Max Resnick on the value of scaling L1: https://x.com/BanklessHQ/status/1831319419739361321
- Justin Drake on the use of SNARKs and native rollups for scaling: https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
What else is there to do, and what trade-offs need to be made?
There are three strategies for L1 expansion, which can be implemented separately or in parallel:
- Improve technology (e.g. client code, stateless clients, historical data expiration) to make L1 easier to verify, then increase the gas limit .
- Reduce costs for specific operations and increase average capacity without increasing worst-case risk.
- Native rollup (i.e. “create N copies of the EVM that run in parallel”, while potentially giving developers a lot of flexibility in the parameters of the deployed copies).
It’s important to understand that these are different technologies with their own trade-offs. For example, native Rollups have many of the same weaknesses as regular rollups in terms of composability: you can’t send a single transaction to execute operations on multiple rollups simultaneously, as you can with contracts on the same L1 (or L2). Raising the gas limit would undermine other benefits that can be gained by making L1 easier to verify, such as increasing the percentage of users running validating nodes and increasing the number of independent stakers. Depending on the implementation, reducing the cost of specific operations in the EVM may increase the overall complexity of the EVM.
An important question that any L1 scaling roadmap needs to answer is: what exactly should belong on L1 and what should belong on L2 ? Obviously, it’s unrealistic to have everything run on L1: potential use cases may require hundreds of thousands of transactions per second, which would make L1 completely unverifiable (unless we go the native rollup route). But we do need some guiding principles to ensure that we don’t end up in a situation where we increase the gas limit 10x, severely harming the decentralization of Ethereum L1, only to reduce 99% of activity to 90% on L2, thus leaving the overall result almost unchanged but irreversibly losing much of the unique value of Ethereum L1.
How does it interact with the rest of the roadmap?
Bringing more users to L1 means not only improving scalability, but also improving other aspects of L1. This means that more MEV will stay in L1 (rather than just becoming an issue for L2), so it will need to be handled explicitly with more urgency. This also greatly increases the value of achieving shorter slot consumption times on L1. In addition, this depends largely on the smooth progress of L1's verification (i.e. the "Verge" stage).
Disclaimer: As a blockchain information platform, the articles published on this site only represent the personal opinions of the author and the guest, and have nothing to do with the position of Web3Caff. The information in the article is for reference only and does not constitute any investment advice or offer. Please comply with the relevant laws and regulations of your country or region.
Welcome to join the Web3Caff official community : X (Twitter) account | WeChat reader group | WeChat public account | Telegram subscription group | Telegram exchange group






