OpenAI launched SearchGPT a few days ago, and the open-source version has also arrived.
The CUHK MMLab, Shanghai AI Lab, and Tencent team have easily implemented the
Vision Search Assistant, with a simple model design that only requires
two RTX3090s to reproduce.
The Vision Search Assistant (VSA) is based on the Visual Language Model (VLM) and cleverly integrates Web search capabilities, allowing the knowledge within the VLM to be updated in real-time, making it more flexible and intelligent.
Currently, VSA has conducted experiments on general images, with good visualization and quantification results. However, different categories of images have their own characteristics, and more specific VSA applications can be built for different types of images (such as tables, medical, etc.).
More excitingly, the potential of VSA is not limited to image processing. There is a wider space to explore, such as in the fields of video, 3D models, and sound, and it is expected to push multimodal research to new heights.
Let VLM handle unseen images and new concepts
The emergence of large language models (LLMs) has enabled humans to leverage the powerful zero-shot answering capabilities of the models to acquire unfamiliar knowledge.
Building on this, technologies like Retrieval-Augmented Generation (RAG) have further improved the performance of LLMs on knowledge-intensive, open-domain question-answering tasks. However, VLMs often cannot effectively utilize the latest multimodal knowledge from the internet when faced with unseen images and new concepts.
Existing Web Agents mainly rely on retrieving user questions and summarizing the retrieved HTML text content, and therefore have obvious limitations in handling tasks involving images or other visual content, as the visual information is ignored or not processed adequately.
To address this issue, the team proposed the Vision Search Assistant. The Vision Search Assistant, based on the VLM model, can answer questions about unseen images or new concepts, behaving similarly to the process of a human searching the internet and solving problems, including:
- Understanding the query
- Deciding which objects in the image to focus on and inferring the relationships between them
- Generating query text for each object
- Analyzing the content returned by the search engine based on the query text and inferred relevance
- Determining whether the obtained visual and textual information is sufficient to generate an answer, or if it should iterate and improve the above process
- Answering the user's question by combining the retrieval results
Visual Content Description
The Visual Content Description module is used to extract object-level descriptions and relationships between objects in the image, as shown in the following figure.
First, an open-domain detection model is used to obtain the regions of interest in the image. Then, for each detected region, the VLM is used to obtain the object-level textual description.
Finally, to more comprehensively express the visual content, the VLM is further used to associate different visual regions to obtain more accurate descriptions of different objects.
Specifically, let the user's input image be , and the user's question be . An open-domain detection model can be used to obtain regions of interest:
Then, a pre-trained VLM model can be used to describe the visual content of these regions respectively:
To associate the information of different regions and improve the accuracy of the description, the description of region can be concatenated with the descriptions of other regions to allow the VLM to refine the description of region :
At this point, precise visual descriptions highly relevant to the user's input have been obtained.
Web Knowledge Search: "Search Chain"
The core of Web knowledge search is an iterative algorithm called the "Search Chain", which aims to obtain comprehensive Web knowledge related to the visual descriptions, as shown in the following figure.
In the Vision Search Assistant, an LLM is used to generate sub-questions related to the answer, called the "Planning Agent". The pages returned by the search engine are analyzed, selected, and summarized by the same LLM, called the "Searching Agent". In this way, Web knowledge related to the visual content can be obtained.
Specifically, since the search is performed separately for the visual content description of each region, taking region as an example and omitting the superscript, the same LLM model is used to construct the Planning Agent and the Searching Agent in this module. The Planning Agent controls the overall process of the search chain, and the Searching Agent interacts with the search engine, filtering and summarizing the web page information.
Taking the first iteration as an example, the Planning Agent will decompose the question into search sub-questions and have the Searching Agent process them. The Searching Agent will submit each to the search engine, obtaining a set of pages . The search engine will read the page summaries and select the set of pages most relevant to the question (with index set ), using the following method:
For these selected pages, the Searching Agent will read their content in detail and summarize them:
Finally, the summaries of all sub-questions are fed to the Planning Agent, and the Planning Agent summarizes the Web knowledge obtained after the first iteration:
Repeat the above iterative process times, or until the Planning Agent believes the current Web knowledge is sufficient to respond to the original question, and the search chain stops, obtaining the final Web knowledge .
Collaborative Generation
Finally, based on the original image , the visual descriptions , and the Web knowledge , the VLM is used to answer the user's question , with the process shown in the following figure. Specifically, the final answer is:
Experimental Results
Open-ended QA Visualization Comparison
The figure below compares the open-ended question-answering results for new events (first two rows) and new images (last two rows).
Comparing Vision Search Assistant with Qwen2-VL-72B and InternVL2-76B, it is clear that Vision Search Assistant excels at generating more up-to-date, accurate, and detailed results.
For example, in the first sample, Vision Search Assistant summarizes the situation of Tesla in 2024, while Qwen2-VL is limited to information from 2023, and InternVL2 explicitly states that it cannot provide the real-time status of the company.
Open-ended QA Evaluation
In the open-ended question-answering evaluation, a total of 10 human experts conducted a comparative evaluation, covering 100 image-text pairs collected from news during the period from July 15 to September 25, covering all domains of novel images and events.
The human experts evaluated the responses based on three key dimensions: factuality, relevance, and supportiveness.
As shown in the figure below, compared to Perplexity.ai Pro and GPT-4-Web, Vision Search Assistant performed excellently in all three dimensions.
Factuality: Vision Search Assistant scored 68%, significantly outperforming Perplexity.ai Pro (14%) and GPT-4-Web (18%). This substantial lead indicates that Vision Search Assistant consistently provides more accurate, fact-based answers.
Relevance: Vision Search Assistant's relevance score was 80%, demonstrating a significant advantage in providing highly relevant answers. In comparison, Perplexity.ai Pro and GPT-4-Web scored 11% and 9% respectively, showing a substantial gap in maintaining the timeliness of web search.
Supportiveness: Vision Search Assistant also outperformed the other models in providing sufficient evidence and reasons for its responses, with a supportiveness score of 63%. Perplexity.ai Pro and GPT-4-Web scored 19% and 24% respectively. These results highlight the excellent performance of Vision Search Assistant in open-ended tasks, particularly in providing comprehensive, relevant, and well-supported answers, making it an effective approach for handling new images and events.
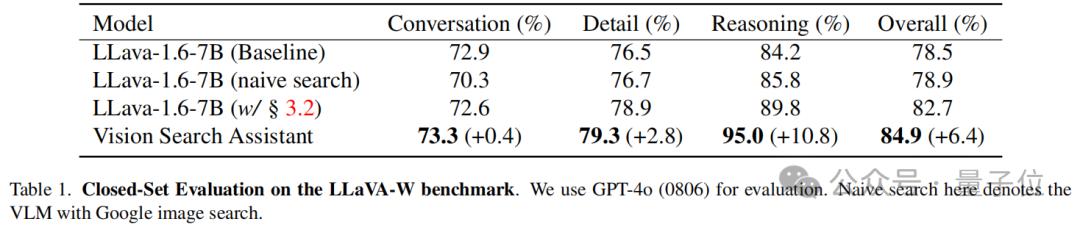
Closed-set Question Answering Evaluation
The LLaVA W benchmark is used for closed-set evaluation, which includes 60 questions covering VLM's dialogue, detail, and reasoning capabilities in the wild.
The GPT-4o(0806) model is used for evaluation, with LLaVA-1.6-7B as the baseline model, which is evaluated in two modes: standard mode and "naive search" mode using a simple Google image search component.
Additionally, an enhanced version of LLaVA-1.6-7B equipped with a search chain module is also evaluated.
As shown in the table below, the Vision Search Assistant (VSA) exhibits the strongest performance across all categories. Specifically, it scored 73.3% in the dialogue category, a slight improvement of +0.4% over the LLaVA model. In the detail category, VSA stands out with a score of 79.3%, which is +2.8% higher than the best-performing LLaVA variant.
In terms of reasoning, the VSA method outperforms the best-performing LLaVA model by +10.8%. This indicates that the advanced integration of visual and text search greatly enhances the reasoning capabilities of the Vision Search Assistant.
The overall performance of the Vision Search Assistant is 84.9%, which is +6.4% higher than the baseline model. This demonstrates that the Vision Search Assistant excels in both dialogue and reasoning tasks, giving it a clear advantage in open-domain question-answering capabilities.
Paper: https://arxiv.org/abs/2410.21220 Homepage: https://cnzzx.github.io/VSA/ Code: https://github.com/cnzzx/VSA
This article is from the WeChat public account "Quantum Position", written by the VSA team, and published with authorization from 36Kr.








