

Author: TechFlow
With BTC breaking through $100,000, more funds are looking for new projects and opportunities under the bullish expectation.
But if you ask which track has the most potential right now? The AI Agent must have a name. However, with a large number of AI Agents being launched every day, the narrative of the entire track is gradually stratifying:
One category is around the applications of AI Agents, with the corresponding Tokens representing Meme or the utility of the Agent; the other category is focused on providing capabilities for AI Agents, making the applications better.
The former is starting to become crowded due to being more observable at the application layer; while the latter has relatively more room for breakthroughs.
What other capabilities are essential for AI Agents?
Perhaps we can find the answer from the recently popular "AI KOL" aixbt:
Research has found that aixbt does not always say the right things, it cannot distinguish what is true or false, cannot require experts to verify its assumptions, and cannot question itself.
Essentially, because aixbt is actually a large language model, it can only retrieve and summarize from various public data, so it is more like an echo chamber that aggregates public information.

So, if you can provide these AI Agents with more diverse, personalized and private data, perhaps they will perform better.
For example, share your insights on trading low-cap Altcoins, or the investment strategies you're only willing to discuss in paid groups for them to learn... But these data are not on the surface, and the aixbts can't get them.
Note, the world does not lack data, but high-quality data is hard to come by.
In the current crypto hype around AI Agents, data infrastructure is actually missing.
The narrative space and information gap here is that if there is a project that can collect more personalized and customized data, and feed it to the AI Agents or organizations in need, it may find a unique ecological position in this hot spot.
Two months ago, we wrote about a project called Vana, using the DAO model to collect various types of data that cannot be obtained in the open market, and then use tokenization to incentivize data contribution and guide the purchase and use of such data.
It's just that at that time, AI Agents were not so hot, and the use case of the project was not so clear. But in this wave of AI Agent hype, Vana obviously has more room for use and a more self-sustaining environment.
Coincidentally, Vana will soon launch its mainnet and release its own Token $VANA, and Vana has also updated its whitepaper and Token economics, providing more detailed explanations on the current data issues and its positioning.
In the crypto market, timing is important. What new dynamics and changes of Vana are worth paying attention to now? Are there more positive expectations for the Token?
We read the newly released whitepaper and quickly understand the current Vana.

Data "Double Spending", Blind Spots in Seeking Profits
Undoubtedly, everyone is chasing the profits in the AI Agent hype.
Anyone can easily create AI Agents, and the assets corresponding to AI Agents can also be easily tokenized... But besides buying the Tokens corresponding to the AI Agents, what other profits can you get?
This question means new opportunities for individuals, and new narrative spaces for projects.
Don't forget, AI Agents may be using the data you contributed to train themselves, but you haven't earned a penny from it. For example, the crypto hot spots analyzed by the aforementioned aixbt, one of the sources may be the article you wrote on your own Twitter.
Therefore, opening Vana's new whitepaper, a concept on the first few pages quickly caught the author's attention: the "double spending" dilemma of data.

Double spending, does this term sound familiar yet unfamiliar?
This concept actually originates from the double spending problem solved by Bitcoin - preventing the same Bitcoin from being spent twice.
Bitcoin's solution to this problem is to record the ins and outs of a transaction on a public blockchain, which serves as an immutable ledger, and everyone knows the entire history of a coin's flow, ensuring that a coin can only be spent once in its current state.
But in the data domain, this problem is more complex.
Unlike Bitcoin, data is naturally copyable, which leads to an economic dilemma overlooked in the AI hype: when data is directly sold, the buyer can easily copy and redistribute it, causing the same data to be utilized multiple times, and you cannot get any additional benefits from this utilization.
For example, once your own tweet is used and learned by an AI Agent, it may be shared indefinitely with other AI Agents, ultimately causing the data to lose its scarcity and economic value.
If you want to create something similar to Bitcoin's ledger to record the usage of data on-chain to avoid this double spending problem, will it work?
First, data sometimes has privacy, and public recording is not suitable, and you don't want to share it; second, even if you record the data usage, you still can't guarantee the data won't be copied and resold off-chain. Third, everyone wants to take advantage of your data, who wants to join your "selfish but not beneficial to others" ledger system?
So, is there a way to solve the "double spending" problem of data?
As Vana's whitepaper says, "data sovereignty and collective creation of data are not mutually exclusive".
We quickly went through this whitepaper, and a too long, didn't read version can be:
The Vana protocol proposes an innovative solution by cleverly combining privacy protection, programmable access rights, and economic incentive mechanisms to create a brand-new data economy model.
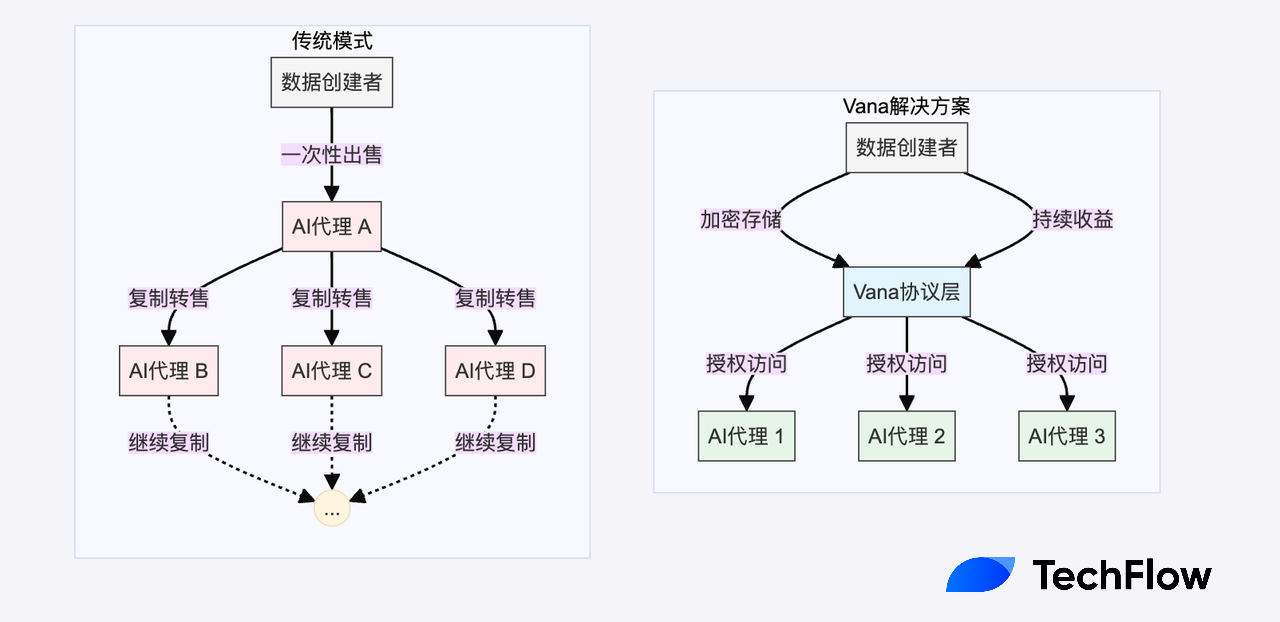
In this model, data always remains encrypted, and only authorized entities can access it under specific conditions; secondly, through smart contracts, data owners can precisely control who can access the data and under what conditions; more importantly, this access right can be tokenized and traded, while the original data is always protected.
A more common analogy would be the streaming model in the modern music industry:
Not directly selling music files (which would lead to unlimited copying), but like Spotify's streaming service, where each use generates revenue.
Data owners don't sell the data outright, but retain control and can continuously earn from each use of the data. This ensures that data can be fully utilized (e.g. for AI training), while solving the problem of "one-time sale" of data leading to double spending and devaluation, and data owners always maintain full control over their data.
Build a "Data Cooperative" with DAO as the Pool
Specifically, how will Vana do it?
We can roughly divide the participants in the entire AI market into two camps - companies/AI Agents that need data; and individuals and organizations (actively or passively) contributing data.
To build a higher-quality AI Agent, in addition to public data, their demands are obvious:
Access to private data, such as your health data for medical diagnosis AI Agents
Access to paywalled data, such as paid articles and insights, for business analysis AI Agents
Access to closed platform data, such as more posts on X, for sentiment analysis AI Agents
As for the other side, the contributors of data, whether intentionally or unintentionally, your demands are not much different:
You can access, but the data ownership still belongs to me;
You can access, but the data needs to be stored in a secure place;
You can access, but I want to benefit from it, pay-per-use.




