Author: TechFlow
As BTC breaks through $100,000, more funds are looking for new projects and opportunities in anticipation of a bull market.
But if you want to ask which track has the most opportunities at present? Then AI Agent must have a name. However, with a large number of AI Agents being launched every day, the narrative of the entire track is gradually layered:
One category is applications centered around AI Agents, where the corresponding tokens represent the Meme or the purpose of the Agent; the other category focuses on providing infrastructure that enables AI Agents to perform better.
The former, because they are easier to observe at the application layer, have begun to become crowded and inward-looking; while the latter, relatively speaking, has more room for breakthroughs.
What other capabilities are urgently needed for AI Agents?
Thanks for reading TechFlow TechFlow! Subscribe for free to receive new posts and support my work.
Perhaps we can find the answer from the recently popular "AI KOL" aixbt:
Studies have found that what aixbt says is not always right, it cannot distinguish what is true or false, cannot ask experts to verify its assumptions, and cannot question itself.
In essence, because aixbt is actually a large language model, it can only crawl and summarize from various public data, so it is more like a repeater that aggregates public information.
So, if you can give this kind of AI agent more diverse, personalized, and private data , maybe it will do better.
For example, you can share your experience of trading low-market-cap Altcoin, or an investment strategy that only paid groups are willing to exchange so that it can learn... But these data are not on the table, and aixbt cannot get them.
Note that it’s not that there isn’t enough data in the world; it’s that high-quality data is hard to come by .
In the current encryption craze of AI agents, data infrastructure is actually missing.
The narrative space and information gap here is that if there is a project that can collect more private and personalized data and feed it to AI agents or organizations in need, it may find its own unique ecological niche in this wave of hot spots.
Two months ago, we wrote about a project called Vana , which used DAO to collect various data that were not available on the open market, and then used tokenization to incentivize data contribution and guide the purchase and use of such data.
However, AI Agents were not so popular at that time, and the use scenarios of the project did not seem so clear. In this wave of AI Agents, Vana obviously has more room for use and a more self-sustaining environment.
It just so happens that Vana will launch mainnet and release its own token $VANA in the near future. At the same time, Vana has also updated its white paper and token economics, providing more detailed explanations of current data issues and its own positioning.
In the crypto market, timing is very important. What new developments and changes are worth paying attention to for Vana now? Does the token have more positive expectations?
We read the newly released white paper to help you quickly understand the current Vana.
There is no doubt that everyone is chasing the gains in the AI agent craze.
Anyone can easily create an AI agent, and the assets corresponding to the AI agent can also be easily tokenized... But besides buying the tokens corresponding to the AI agent, what other benefits can you get?
This question means new opportunities for individuals and new narrative space for projects.
Don’t forget that the AI agent may be training itself with the data you contributed, but you don’t earn a penny from it. For example, the crypto hot spots analyzed by aixbt mentioned above may be one of the sources of an article you wrote on your Twitter.
Therefore, when I opened Vana's new white paper, a concept in the first few pages quickly caught my attention: the "double-spending" dilemma of data.
Double flower, does this word seem familiar yet strange?
This concept actually originates from the double spending problem solved by Bitcoin, which is to prevent the same Bitcoin from being spent twice.
Bitcoin solves this problem by recording the details of an account transaction on a public blockchain, which acts as an unchangeable ledger. Everyone knows the entire historical flow of a coin, ensuring that a coin can only be spent once in its current state.
But in the data world, the problem is more complicated.
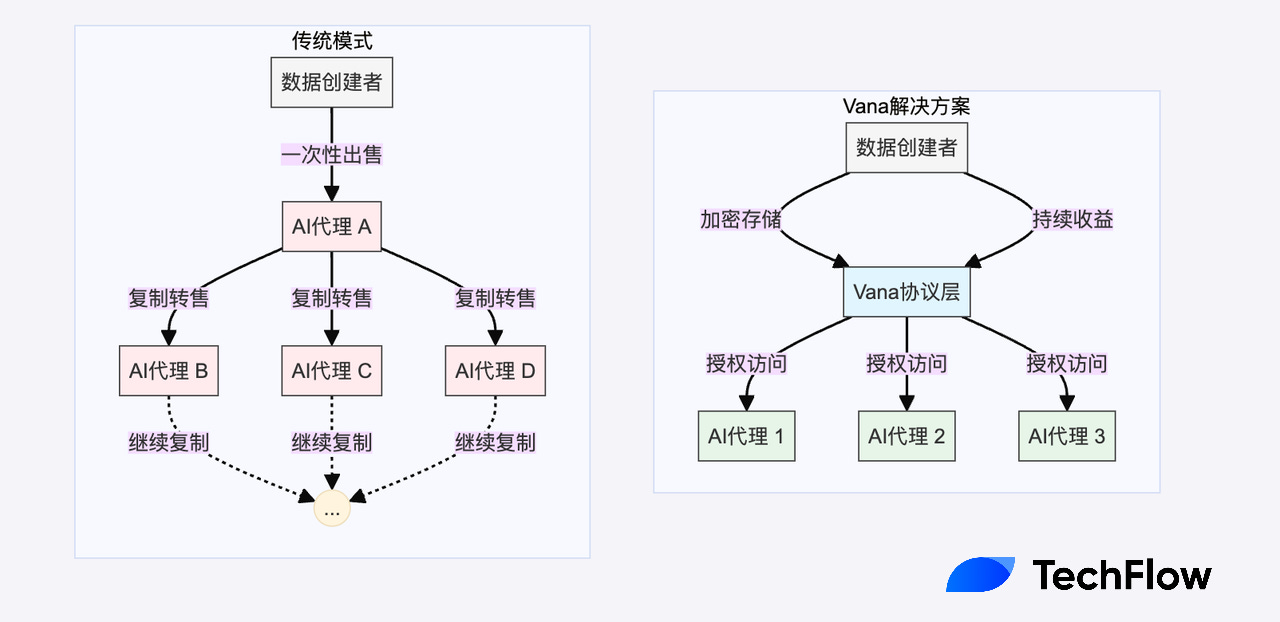
Unlike Bitcoin, data is naturally reproducible, which leads to an economic dilemma that has been overlooked in the AI craze: when data is sold directly, buyers can easily copy and redistribute it, resulting in the same data being actually used multiple times, and you cannot get any additional benefits from this use.
For example, if you write a tweet, once it is used and learned by an AI agent, it may be shared with other AI agents without restriction, eventually causing the data to lose its scarcity and economic value.
If you want to create a ledger similar to Bitcoin and record the use of data on the chain to avoid the double-spending problem, is that possible?
First, data itself is sometimes private, and it is not appropriate to record it publicly, and you are not willing to share it; second, even if you record the use of data, there is still no guarantee that the data will continue to be copied and resold off-chain. Third, everyone wants to take advantage of your data, so who is willing to join your "self-interest but not others" ledger system?
So, is there any way to solve the "double spending problem" of data?
As Vana’s white paper states, “ data sovereignty and the collective creation of data are not mutually exclusive .”
We have speed-run this white paper, a version that is too long to read can be:
The Vana Protocol proposes an innovative solution that creates a completely new data economic model by cleverly combining privacy protection, programmable access rights, and economic incentive mechanisms.
In this model, data always remains encrypted and can only be accessed by authorized entities under specific conditions. Secondly, through smart contracts, data owners can precisely control who can access the data and under what conditions. More importantly, this access right can be tokenized and traded, while the original data is always protected.
A more popular analogy could be the streaming model of the modern music industry:
Rather than selling music files directly (which would lead to endless copying), streaming services like Spotify generate revenue with every use.
Instead of selling the data once, the data owner retains control and can continue to earn revenue from each use of the data. This ensures that the data can be fully utilized (for example, for AI training), while solving the problem of double spending and depreciation caused by "one-time sale" of data, while the data owner always maintains complete control over his or her data.
Specifically, what will Vana do?
First, we can roughly divide the people involved in the entire AI market into two groups: companies/AI agents that need to use data; and individuals and organizations that contribute data (actively or passively).
In order to make a higher quality AI agent, in addition to public data, their demands are obvious:
As the other party who contributes data intentionally or unintentionally, your demands are nothing more than the following:
Traditional data usage models often put users in a passive position. For example, when AI companies need training data, they either buy data directly from social platforms (users cannot benefit from it) or negotiate with tens of thousands of users separately (extremely inefficient).
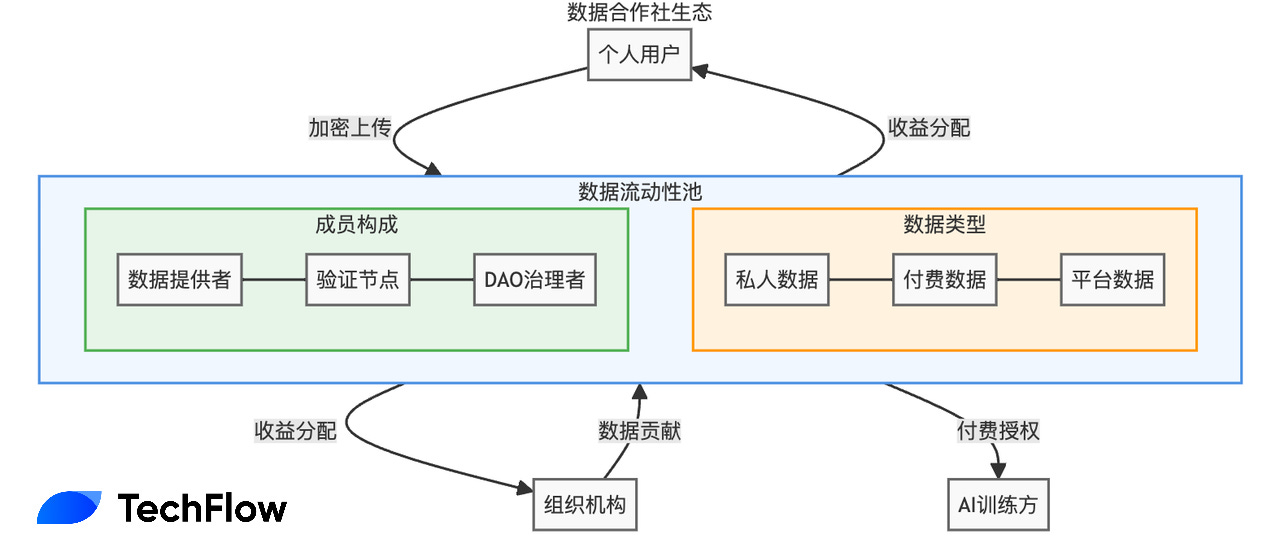
The way Vana solves the problem is called Data Liquidity Pool (DLP). You can think of it more down-to-earth as a "data cooperative":
Users can concentrate their data rights in a "pool" to form a virtual organization similar to a cooperative; this means that group users have the power of collective bargaining while maintaining encrypted control over the original data.
Imagine a DLP consisting of 100,000 Twitter users: when AI companies want to use this data, they can negotiate directly with the DLP, and the proceeds are automatically and fairly distributed to all contributors.
Judging from the white paper released by Vana in recent days, this data cooperative (DLP) is now well-organized and has formed four key rules:
This is a bit like strict entry standards, defining standards for metadata, such as social media data, health data, etc. The core is to ensure that only data that meets the quality requirements is in the pool;
Evaluate the quality and value of the data entering the pool to ensure that the data added is authentic, i.e., verification nodes in the traditional blockchain sense
Through a fair points system, high-quality data contributors are encouraged; more and better data can get more token rewards
It specifies how to make decisions, such as opening a new data pool, etc. It also specifies how to handle disputes, which also reflects more of the characteristics of the DAO we are familiar with.
So overall, this data cooperative in the context of the crypto world is more like a DAO that makes decisions and incentives around data. The DAO manages the data pool and also determines the rules for negotiating with data users and the way profits are distributed.
If you think the above statement is too common, then in the design of the Vana network, the above DAO model is actually operating in a serious technical way:
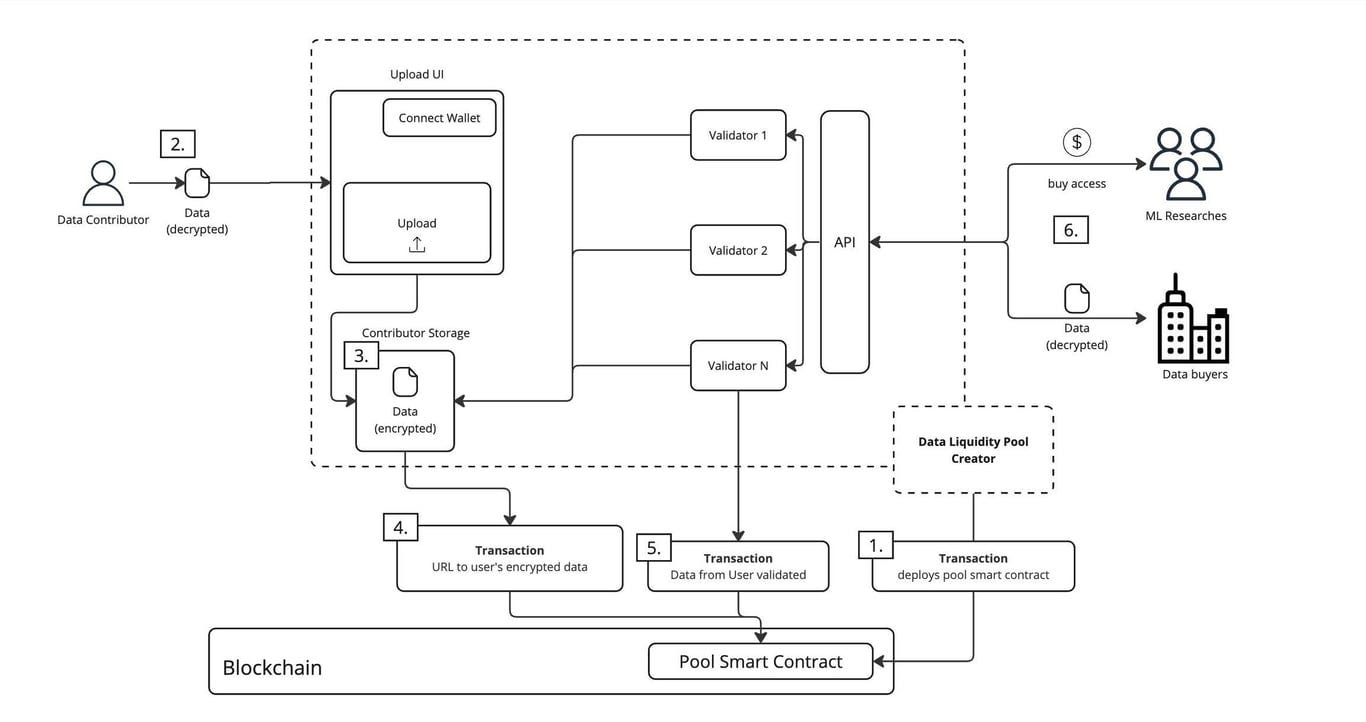
Smart contract deployment. The DAO creator deploys the pool’s smart contract to the blockchain, clearly defining basic rules such as how data is managed, how it is used, and how the proceeds are distributed.
Data preparation. Data providers prepare the data they want to contribute, and the data is encrypted before being provided.
Secure storage. Data providers need to connect their wallets and prove their identity before uploading data. The uploaded encrypted data will be stored in the contributor's exclusive storage space.
On-chain records. The system will record the access address of this encrypted data on the blockchain to ensure that only authorized persons can access the data.
Multiple verifications. Multiple verifiers will review the data to check its authenticity, quality, and value. These verification results will be recorded in the smart contract to ensure the credibility of the data.
Standardized use. Verified data can be used by two types of users: machine learning researchers can pay to use the data to train models; data buyers can access the data under certain conditions. All use requires payment and strictly abides by the conditions of use specified in the smart contract.
In terms of data privacy protection, due to limited space and technical knowledge, the author will not elaborate on it.
If you are worried about whether this data will be leaked, just briefly grasp the following main line, that is, all personal data in Vana is always encrypted, just like it is placed in a safe that the user holds the key to. Even if this data needs to be processed, it can only be done in a special security environment (TEE), just like a special clearing room in a bank, where all operations are strictly monitored and recorded.
It is particularly worth mentioning that the system achieves flexible but secure access control through the combination of smart contracts and encryption mechanisms. It can control who can access what data at what time, and all access records will be properly saved for auditing.
With DAO as the data pool, a data cooperative model can protect personal data sovereignty and benefits while also enabling AI agents that need more personalized data to make the best use of it.
At present, these data liquidity pools on Vana are not just at the stage of drawing pie in the sky, but have actually formed data DAOs of various sizes. The data in each DAO is oriented to a vertical scenario and is used for different AI needs.
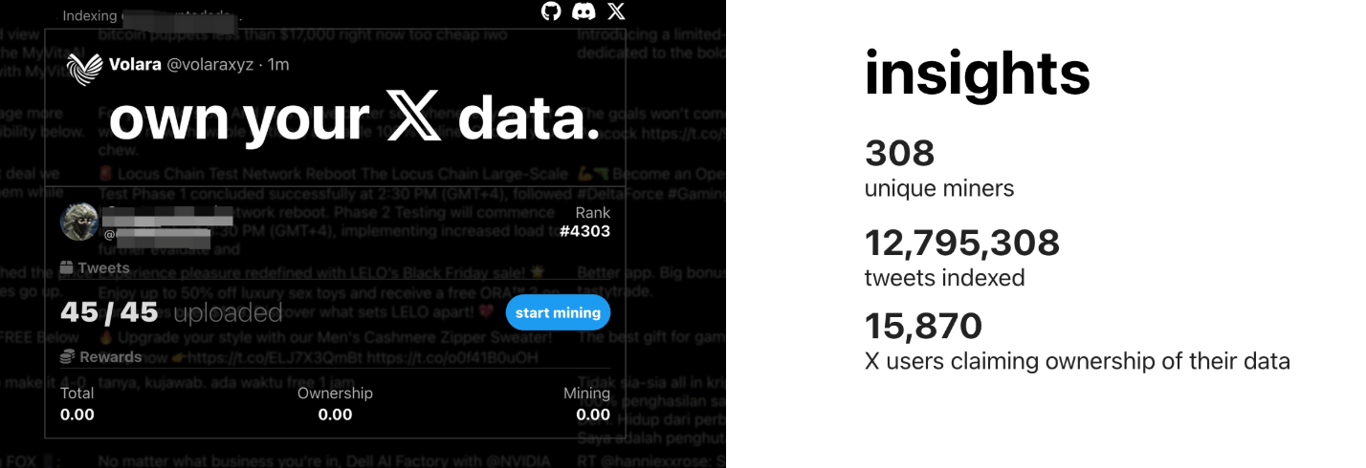
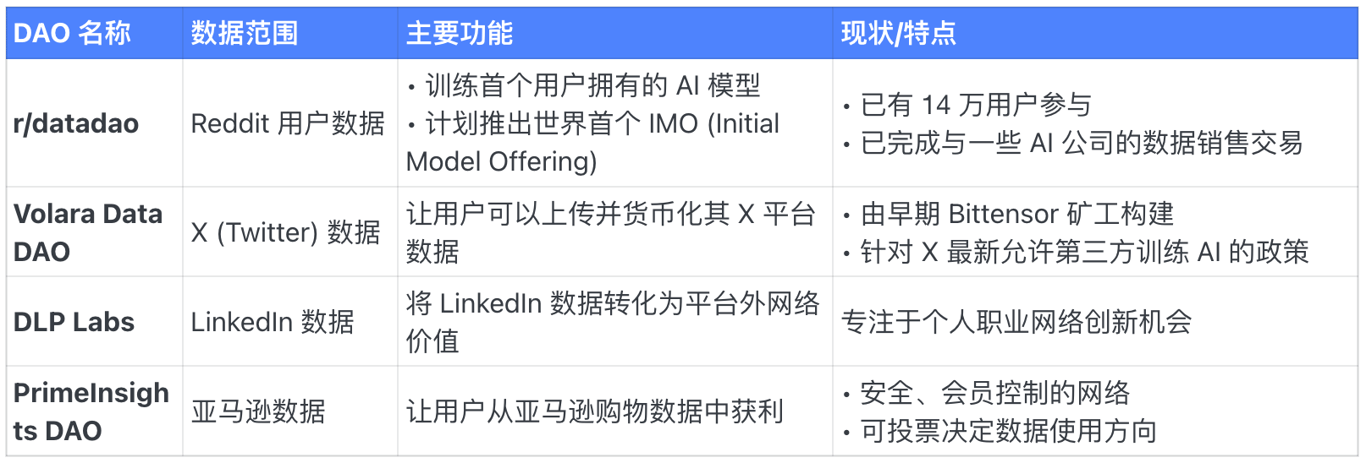
Taking Volara DAO, which focuses on X (Twitter), as an example, you can connect your Twitter to this platform, and then upload all your tweets and related social data. At the same time, Volara DAO will reward you with the corresponding tokens in this DAO according to your contribution.
Note that the direct reward is not Vana, but the DAO’s own token, such as $VOL.
This is very similar to the currently popular Virtuals, where there are corresponding tokens created by different projects under one parent coin. And those who hold VOL are eligible for $VANA airdrops, and the asset nesting model also creates space for more gameplay.
We have compiled 16 of the most popular data DAOs in Vana and classified them in detail.
For ordinary players, this is more like the concept of "data mining" - if you are optimistic about a DAO, you can contribute data according to its rules, and then you will receive corresponding rewards and airdrops.
However, you don’t necessarily own all the data, so you also need to look at what data you can contribute according to the following categories to find the best way to gain benefits:
Overall, since the launch of the developer testnet in June 2024, the Vana Network has attracted 1.3 million users, more than 300 data DAOs, and 1.7 million daily transactions.
With the launch of the mainnet and tokens, with the support of economic incentives, perhaps we will see more data DAOs emerge.
You may have discovered that the above-mentioned DAOs all have their own sub-coins, and at the same time have corresponding connections with the parent coin VANA (such as airdrops, etc.).
This involves a carefully designed two-layer token economic model.
Imagine the traditional data market: medical data, financial data, social data, their value standards and usage scenarios are very different. Using a single token to measure and incentivize such diverse data contributions is like using one ruler to measure everything - from planets to atoms. This is obviously not precise enough and not flexible enough.
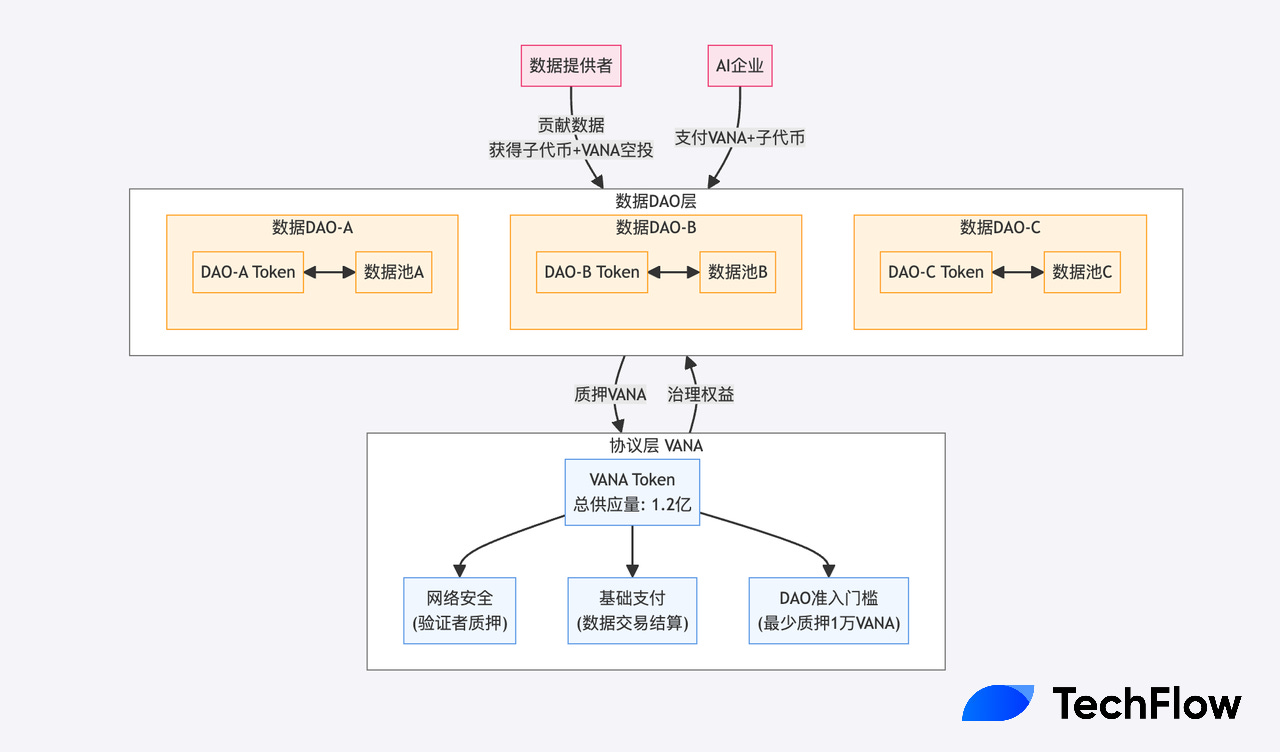
VANA adopts a more elegant solution: setting a unified base token (VANA) at the protocol level, while allowing each data DAO to issue its own exclusive token.
The parent and child coins have different divisions of labor and functions:
The supply is 120 million. First, it requires validators to stake VANA to ensure the corresponding network security;
Secondly, it serves as the basic payment currency for all transactions. For example, if an AI company needs data in this DAO, it needs to pay with VANA.
Most importantly, it requires each data DAO to stake at least 10,000 VANA to operate, which acts like a "good faith deposit" to ensure the DAO operator's long-term commitment to the ecosystem.
Each data DAO can design a token economic model that suits the characteristics of its own field. For example, a medical data DAO may pay more attention to the completeness and accuracy of the data, so it will design a special reward mechanism to encourage the provision of high-quality medical record data; while a social data DAO may pay more attention to the activity and influence of user interaction.
These exclusive tokens are not just simple points, but a complete value capture system: when data is used, VANA and the corresponding DAO tokens need to be paid at the same time. This is like paying both the "site fee" (VANA) and the "special service fee" (DAO token) when using data.
Does this gameplay remind you of Virtuals?
Similarly, the beauty of the two-tier token system is that it creates a self-sustaining economic cycle: using data requires consuming tokens, some of which will be destroyed, creating deflationary pressure; at the same time, high-quality data contributions will be rewarded with new tokens, which in turn provides a moderate inflationary impetus. This balance ensures the stability of the token value and encourages continued data contribution.
Vana, as the parent currency, has gas and staking functions. Each sub-DAO issues its own token and forms a trading pair with the parent currency VANA. The parent currency can capture the benefits of ecological prosperity.
From the perspective of creating assets and increasing asset efficiency, VANA's gameplay is obviously in line with the current AI agent craze.
For individuals, this system makes data a truly sustainable asset. Data providers no longer sell data once and for all, but instead continue to share the benefits of data use by holding tokens. This is like a shift from a "sale system" to a "copyright sharing system", which greatly improves the interests of data creators.
At the same time, as the Vana mainnet will be launched soon (token economics has been announced, and the mainnet launch is being preheated), after understanding the gameplay of this dual token system, there are at least two things you can participate in:
First, as mentioned above, contribute data to different data DAOs in order to obtain sub-DAO tokens and corresponding VANA airdrops; the summary link is here .
Second, with the launch of the mainnet, we also found that Vana’s official website has changed. A new datahub page has been added to manage the different data DAOs you participate in and the corresponding tokens.
Currently, there is a pre-registration activity on this page, which is used to link your identity in advance and prepare for rewards. Interested players are advised to make arrangements in advance.
After completing the registration, you will be prompted to become an "Early Explorer".
In the current AI Agent hotspot, the influence of AI Agent is growing, until it fills your information flow and investment list.
But Vana's narrative actually says that your own influence is actually greater than you think.
By contributing various types of data, you can become a part of the AI craze; and through the tokenization of data assets, you also have an additional way to create assets.
It cannot be denied that in the crypto world, creating assets is a bright line. Whoever is closer to the assets will gain more narrative space and benefits.
In fact, when your data can be tokenized, I believe this is a hidden line that fits the bright line, and it is also a key piece of the puzzle for individuals to embrace, utilize and participate in the trend of AI intelligent agents.
The narrative of the data layer has not yet been fully developed, and the market will give the answer as to whether Vana will be value-discovered.
TechFlow is a community-driven in- TechFlow content platform dedicated to providing valuable information and thoughtful thinking.
Community:
TechFlow account: TechFlow
Subscribe to the channel: https://t.me/TechFlowDaily
Telegram: https://t.me/TechFlowPost
Twitter: @TechFlowPost
Join the WeChat group and add assistant WeChat: blocktheworld
Donate to TechFlow to receive blessings and permanent records
ETH : 0x0E58bB9795a9D0F065e3a8Cc2aed2A63D6977d8A
BSC : 0x0E58bB9795a9D0F065e3a8Cc2aed2A63D6977d8A