Author:IOSG
TL/DR
We have discussed how AI and Web3 can complement each other in various vertical industries such as computing networks, proxy platforms, and consumer applications. When focusing on the vertical field of data resources, Web3 representative projects provide new possibilities for data acquisition, sharing, and utilization.
• Traditional data providers have difficulty meeting the needs of AI and other data-driven industries for high-quality, real-time verifiable data, especially due to limitations in transparency, user control and privacy protection.
• Web3 solutions are working to reshape the data ecosystem. Technologies such as MPC, zero-knowledge proof, and TLS Notary ensure the authenticity and privacy of data when it circulates between multiple sources, while distributed storage and edge computing provide greater flexibility and efficiency for real-time data processing.
• Among them, the emerging infrastructure of decentralized data network has spawned several representative projects, including OpenLayer (modular real data layer), Grass (utilizing users' idle bandwidth and decentralized crawler node network) and Vana (user data sovereignty Layer 1 network), which have opened up new prospects for areas such as AI training and application with different technical paths.
• Through crowdsourced capacity, trustless abstraction layers, and token-based incentives, decentralized data infrastructure can provide more private, secure, efficient, and cost-effective solutions than Web2 hyperscale service providers, and give users control over their data and related resources, building a more open, secure, and interoperable digital ecosystem.
1. The wave of data demand
Data has become a key driver of innovation and decision-making in various industries. UBS predicts that the amount of global data is expected to grow more than tenfold between 2020 and 2030, reaching 660 ZB. By 2025, each person in the world will generate 463 EB (Exabytes, 1 EB = 1 billion GB) of data every day. The data-as-a-service (DaaS) market is expanding rapidly. According to a report by Grand View Research, the global DaaS market is valued at US$14.36 billion in 2023 and is expected to grow at a compound annual growth rate of 28.1% by 2030, eventually reaching US$76.8 billion. Behind these high-growth figures is the demand for high-quality, real-time, reliable data in multiple industries.
AI model training relies on a large amount of data input to identify patterns and adjust parameters. After training, a data set is also needed to test the performance and generalization ability of the model. In addition, as an emerging form of intelligent application that is foreseeable in the future, AI agents require real-time and reliable data sources to ensure accurate decision-making and task execution. (Source: Leewayhertz)
AI model training relies on a large amount of data input to identify patterns and adjust parameters. After training, a data set is also needed to test the performance and generalization ability of the model. In addition, as an emerging form of intelligent application that is foreseeable in the future, AI agents require real-time and reliable data sources to ensure accurate decision-making and task execution. (Source: Leewayhertz)
The demand for business analytics is also becoming more diverse and extensive, and has become a core tool to drive corporate innovation. For example, social media platforms and market research companies need reliable user behavior data to formulate strategies and gain insights into trends, integrate multivariate data from multiple social platforms, and build a more comprehensive user portrait.
For the Web3 ecosystem, reliable and real data is also needed on the chain to support some new financial products. As more and more new assets are tokenized, flexible and reliable data interfaces are needed to support the development of innovative products and risk management, so that smart contracts can be executed based on verifiable real-time data. In addition, there are also fields such as scientific research and the Internet of Things (IoT).
New use cases indicate that industries are experiencing a surge in demand for diverse, authentic, and real-time data, and traditional systems may struggle to cope with the rapidly growing data volumes and changing demands.
2. Limitations and problems of traditional data ecology
A typical data ecosystem includes data collection, storage, processing, analysis and application. The centralized model is characterized by data being collected and stored in a centralized manner, managed and maintained by the core enterprise IT team, and implementing strict access control.
For example, Google's data ecosystem covers multiple data sources from search engines, Gmail to the Android operating system. It collects user data through these platforms, stores it in its globally distributed data centers, and then processes and analyzes it using algorithms to support the development and optimization of various products and services.
In the financial market, take LSEG (formerly Refinitiv) as an example. Its data and infrastructure obtains real-time and historical data from global exchanges, banks and other major financial institutions, while using its own Reuters News network to collect market-related news, and uses proprietary algorithms and models to generate analytical data and risk assessments, which are provided as additional products.
Traditional data architecture is effective in professional services, but the limitations of the centralized model are becoming increasingly apparent. In particular, the traditional data ecosystem is facing challenges in terms of coverage, transparency, and user privacy protection of emerging data sources. Here are a few examples:
• Insufficient data coverage: Traditional data providers face challenges in quickly capturing and analyzing emerging data sources such as social media sentiment and IoT device data. Centralized systems have difficulty efficiently acquiring and integrating “long-tail” data from numerous small-scale or non-mainstream sources.
Traditional data architecture is effective in professional services, but the limitations of the centralized model are becoming increasingly apparent. In particular, the traditional data ecosystem is facing challenges in terms of coverage, transparency, and user privacy protection of emerging data sources. Here are a few examples:
• Insufficient data coverage: Traditional data providers face challenges in quickly capturing and analyzing emerging data sources such as social media sentiment and IoT device data. Centralized systems have difficulty efficiently acquiring and integrating “long-tail” data from numerous small-scale or non-mainstream sources.
For example, the 2021 GameStop incident also revealed the limitations of traditional financial data providers in analyzing social media sentiment. Investor sentiment on platforms such as Reddit quickly changed market trends, but data terminals such as Bloomberg and Reuters failed to capture these dynamics in time, making market forecasts more difficult.
• Limited data accessibility: Monopoly limits accessibility. Many traditional providers open some data through API/cloud services, but high access fees and complex authorization processes still increase the difficulty of data integration.
It is difficult for on-chain developers to quickly access reliable off-chain data, high-quality data is monopolized by a few giants, and the access cost is high.
• Data transparency and credibility issues: Many centralized data providers lack transparency about their data collection and processing methods, and lack effective mechanisms to verify the authenticity and integrity of large-scale data. The verification of large-scale real-time data remains a complex issue, and the centralized nature also increases the risk of data being tampered with or manipulated.
• Privacy protection and data ownership: Large technology companies and large-scale commercial platforms use user data extensively. As private data creators, it is difficult for users to obtain the value they deserve from it. Users usually cannot understand how their data is collected, processed and used, and it is difficult for them to decide the scope and method of data use. Excessive collection and use of data leads to serious privacy risks.
For example, Facebook’s Cambridge Analytica incident exposed how traditional data providers have huge gaps in transparency and privacy protection when using data.
• Data silos: In addition, scattered data from different sources and formats are difficult to quickly integrate, affecting the possibility of comprehensive analysis. A lot of data is often locked within the organization, limiting data sharing and innovation across industries and organizations. The data silo effect hinders cross-domain data integration and analysis.
For example, in the consumer industry, brands need to integrate data from e-commerce platforms, physical stores, social media, and market research, but these data may be difficult to integrate due to the lack of uniformity or isolation of the platforms. For another example, ride-sharing companies such as Uber and Lyft, although they both collect a large amount of real-time data from users about traffic, passenger demand, and geographic location, cannot present and share these data due to competition.
In addition, there are issues such as cost efficiency and flexibility. Traditional data providers are actively responding to these challenges, but the emerging Web3 technology provides new ideas and possibilities for solving these problems.
For example, in the consumer industry, brands need to integrate data from e-commerce platforms, physical stores, social media, and market research, but these data may be difficult to integrate due to the lack of uniformity or isolation of the platforms. For another example, ride-sharing companies such as Uber and Lyft, although they both collect a large amount of real-time data from users about traffic, passenger demand, and geographic location, cannot present and share these data due to competition.
In addition, there are issues such as cost efficiency and flexibility. Traditional data providers are actively responding to these challenges, but the emerging Web3 technology provides new ideas and possibilities for solving these problems.
3. Web3 Data Ecosystem
Since the release of decentralized storage solutions such as IPFS (InterPlanetary File System) in 2014, a series of emerging projects have emerged in the industry to address the limitations of the traditional data ecosystem. We have seen that decentralized data solutions have formed a multi-layered, interconnected ecosystem that covers all stages of the data life cycle, including data generation, storage, exchange, processing and analysis, verification and security, as well as privacy and ownership.
• Data storage: The rapid development of Filecoin and Arweave proves that decentralized storage (DCS) is becoming a paradigm shift in the storage field. The DCS solution reduces the risk of single point failure through a distributed architecture while attracting participants with more competitive cost-effectiveness. With the emergence of a series of large-scale application cases, the storage capacity of DCS has shown explosive growth (for example, the total storage capacity of the Filecoin network has reached 22 exabytes in 2024).
• Processing and analysis: Decentralized data computing platforms such as Fluence improve the real-time and efficiency of data processing through edge computing technology, which is particularly suitable for application scenarios with high real-time requirements such as the Internet of Things (IoT) and AI reasoning. The Web3 project uses technologies such as federated learning, differential privacy, trusted execution environment, and fully homomorphic encryption to provide flexible privacy protection and trade-offs at the computing layer.
• Data Market/Exchange Platform: In order to promote the re-valuation and circulation of data, Ocean Protocol has created an efficient and open data exchange channel through tokenization and DEX mechanisms, such as helping traditional manufacturing companies (Mercedes-Benz parent company Daimler) to cooperate in the development of a data exchange market to help share data in supply chain management. On the other hand, Streamr has created a permissionless, subscription-based data stream network suitable for IoT and real-time analysis scenarios, and has shown excellent potential in transportation and logistics projects (such as cooperation with the Finnish smart city project).
With the increasing frequency of data exchange and utilization, the authenticity, reliability and privacy protection of data have become key issues that cannot be ignored. This has prompted the Web3 ecosystem to continue to innovate and iterate in the fields of data verification and privacy protection, giving rise to a series of groundbreaking solutions.
3.1 Innovation in Data Verification and Privacy Protection
Many web3 technologies and native projects are working to solve the problems of data authenticity and private data protection. In addition to ZK, MPC and other technical developments are widely used, among which Transport Layer Security Protocol Notary (TLS Notary) as an emerging verification method is particularly worthy of attention. Introduction to TLS Notary Transport Layer Security Protocol (TLS) is an encryption protocol widely used in network communications, designed to ensure the security, integrity and confidentiality of data transmission between clients and servers. It is a common encryption standard in modern network communications and is used in multiple scenarios such as HTTPS, email, and instant messaging.
3.1 Innovation in Data Verification and Privacy Protection
Many web3 technologies and native projects are working to solve the problems of data authenticity and private data protection. In addition to ZK, MPC and other technical developments are widely used, among which Transport Layer Security Protocol Notary (TLS Notary) as an emerging verification method is particularly worthy of attention. Introduction to TLS Notary Transport Layer Security Protocol (TLS) is an encryption protocol widely used in network communications, designed to ensure the security, integrity and confidentiality of data transmission between clients and servers. It is a common encryption standard in modern network communications and is used in multiple scenarios such as HTTPS, email, and instant messaging.
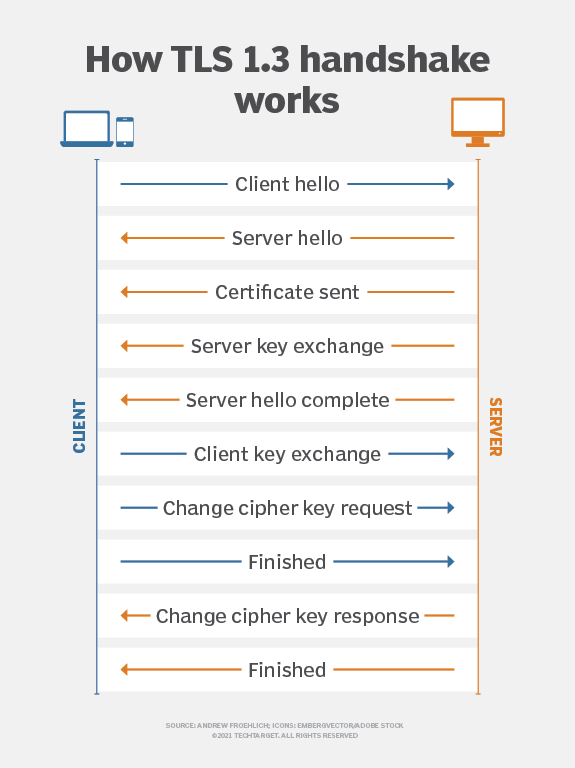
When it was first created ten years ago, the original goal of TLS Notary was to verify the authenticity of TLS sessions by introducing a third-party "notary" outside the client (Prover) and server.
Using key splitting technology, the master key of the TLS session is divided into two parts, held by the client and the notary respectively. This design allows the notary to participate in the verification process as a trusted third party, but cannot access the actual communication content. This notarization mechanism is designed to detect man-in-the-middle attacks, prevent fraudulent certificates, ensure that communication data has not been tampered with during transmission, and allow a trusted third party to confirm the legitimacy of the communication while protecting the privacy of the communication.
As a result, TLS Notary provides secure data verification and effectively balances verification requirements and privacy protection.
In 2022, the TLS Notary project was rebuilt by the Privacy and Extension Exploration (PSE) research lab of the Ethereum Foundation. The new version of the TLS Notary protocol was rewritten from scratch in Rust, incorporating more advanced cryptographic protocols (such as MPC). The new protocol features allow users to prove the authenticity of the data they received from the server to a third party without revealing the specific content of the data. While maintaining the original TLS Notary core verification function, the privacy protection capability has been greatly improved, making it more suitable for current and future data privacy needs.
3.2 TLS Notary variants and extensions
TLS Notary technology has continued to evolve in recent years, with multiple variants developed on the basis to further enhance privacy and verification capabilities:
• zkTLS: A privacy-enhanced version of TLS Notary that combines ZKP technology and allows users to generate cryptographic proofs of web page data without exposing any sensitive information. It is suitable for communication scenarios that require extremely high privacy protection.
• 3P-TLS (Three-Party TLS): Introduces the client, server, and auditor, allowing auditors to verify the security of communications without revealing the content of the communication. This protocol is very useful in scenarios that require transparency but also require privacy protection, such as compliance reviews or audits of financial transactions.
Web3 projects use these encryption technologies to enhance data verification and privacy protection, break down data barriers, solve data silos and trusted transmission problems, and allow users to prove information such as social media account ownership, shopping records for financial loans, bank credit records, professional background and academic certification without leaking privacy. For example:
• Reclaim Protocol uses zkTLS technology to generate zero-knowledge proofs for HTTPS traffic, allowing users to securely import activity, reputation, and identity data from external websites without exposing sensitive information.
• zkPass combines 3P-TLS technology to allow users to verify real-world private data without leakage. It is widely used in scenarios such as KYC and credit services, and is compatible with HTTPS networks.
• Opacity Network is based on zkTLS, allowing users to securely prove their activities on various platforms (such as Uber, Spotify, Netflix, etc.) without directly accessing the APIs of these platforms, achieving cross-platform activity proof.
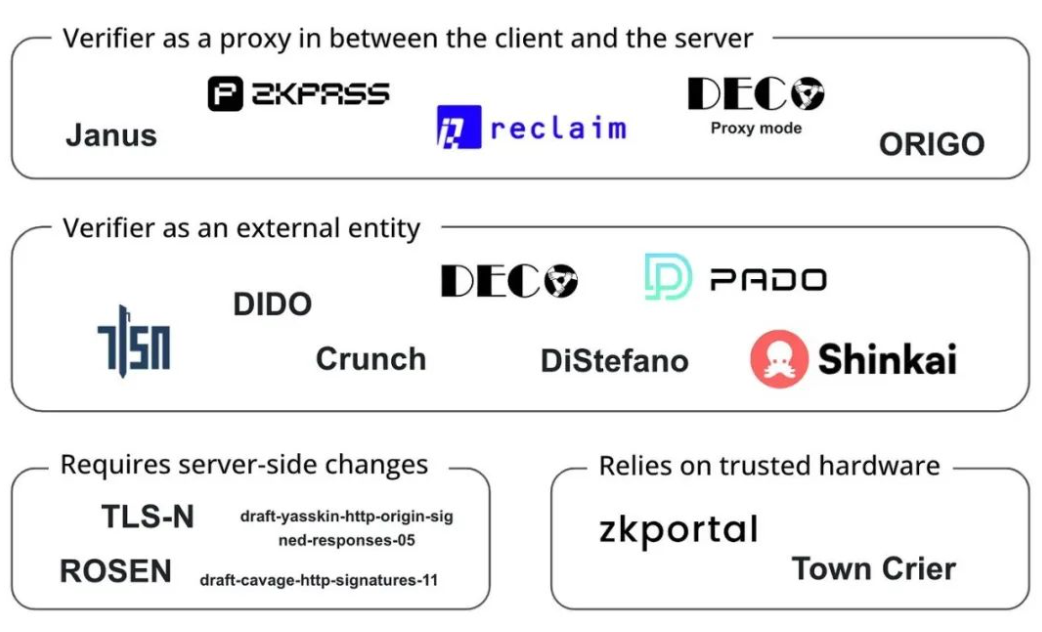
As an important link in the data ecological chain, Web3 data verification has a broad application prospect, and the prosperity of its ecology is leading to a more open, dynamic and user-centric digital economy. However, the development of authenticity verification technology is only the beginning of building a new generation of data infrastructure.
4. Decentralized Data Network
Some projects combine the above data verification technologies to make deeper explorations in the upstream of the data ecosystem, namely data traceability, distributed data collection and trusted transmission. The following focuses on several representative projects: OpenLayer, Grass and Vana, which have shown unique potential in building a new generation of data infrastructure.
4.1 OpenLayer
OpenLayer is one of the a16z Crypto 2024 Spring Encryption Startup Accelerator projects. As the first modular real data layer, it is committed to providing an innovative modular solution for coordinating the collection, verification and transformation of data to meet the needs of both Web2 and Web3 companies. OpenLayer has attracted support from well-known funds and angel investors including Geometry Ventures and LongHash Ventures.
The traditional data layer faces multiple challenges: lack of a trusted verification mechanism, reliance on a centralized architecture that results in limited access, lack of interoperability and liquidity of data between different systems, and no fair data value distribution mechanism.
A more specific problem is that as AI training data becomes increasingly scarce, many websites on the public internet are beginning to adopt crawler restrictions to prevent AI companies from obtaining data on a large scale.
When it comes to private and proprietary data, the situation is even more complicated. Many valuable data are stored in a privacy-preserving manner due to their sensitive nature, and there is a lack of effective incentive mechanisms. Under this status quo, users cannot safely obtain direct benefits by providing private data, so they are unwilling to share this sensitive data.
To solve these problems, OpenLayer combines data verification technology to build a modular authentic data layer, and coordinates the data collection, verification and conversion process in a decentralized economic incentive manner, providing Web2 and Web3 companies with a more secure, efficient and flexible data infrastructure.
To solve these problems, OpenLayer combines data verification technology to build a modular authentic data layer, and coordinates the data collection, verification and conversion process in a decentralized economic incentive manner, providing Web2 and Web3 companies with a more secure, efficient and flexible data infrastructure.
4.1.1 Core components of OpenLayer modular design
OpenLayer provides a modular platform to simplify the process of data collection, trusted verification, and transformation:
a) OpenNodes
OpenNodes is the core component responsible for decentralized data collection in the OpenLayer ecosystem. It collects data through users' mobile applications, browser extensions and other channels. Different operator nodes can optimize returns by performing the most suitable tasks based on their hardware specifications.
OpenNodes supports three main data types to meet the needs of different types of tasks:
• Publicly available internet data (such as financial data, weather data, sports data, and social media streams)
• User private data (such as Netflix viewing history, Amazon order history, etc.)
• Self-reported data from a secure source (e.g., data signed by a proprietary owner or verified by specific trusted hardware)
Developers can easily add new data types, specify new data sources, requirements, and data retrieval methods, and users can choose to provide de-identified data in exchange for rewards. This design allows the system to be continuously expanded to adapt to new data needs. The diverse data sources enable OpenLayer to provide comprehensive data support for various application scenarios and also lower the threshold for data provision.
b) OpenValidators
OpenValidators is responsible for data validation after collection, allowing data consumers to confirm that the data provided by the user exactly matches the data source. All provided validation methods can be cryptographically proven, and the validation results can be verified after the fact. There are multiple different providers providing the same type of proof. Developers can choose the most suitable validation provider according to their needs.
In initial use cases, specifically for public or private data from Internet APIs, OpenLayer uses TLS Notary as a verification solution to export data from any web application and prove the authenticity of the data without compromising privacy.
Not limited to TLS Notary, thanks to its modular design, the verification system can easily integrate other verification methods to adapt to different types of data and verification requirements, including but not limited to:
1. Attested TLS connections: Use the Trusted Execution Environment (TEE) to establish authenticated TLS connections to ensure the integrity and authenticity of data during transmission.
2. Secure Enclaves: Use hardware-level secure isolation environments (such as Intel SGX) to process and verify sensitive data, providing a higher level of data protection.
3. ZK Proof Generators: Integrate ZKP to allow verification of data properties or calculation results without revealing the original data.
c) OpenConnect
OpenConnect is the core module in the OpenLayer ecosystem responsible for data conversion and availability. It processes data from various sources and ensures data interoperability between different systems to meet the needs of different applications. For example:
• Convert data into an on-chain oracle format for direct use by smart contracts.
• Convert unstructured raw data into structured data for preprocessing purposes such as AI training.
For data from users' private accounts, OpenConnect provides data desensitization to protect privacy, and also provides components to enhance security during data sharing and reduce data leakage and abuse. To meet the needs of applications such as AI and blockchain for real-time data, OpenConnect supports efficient real-time data conversion.
Currently, through the integration of Eigenlayer, OpenLayer AVS operators listen to data request tasks, are responsible for grabbing data and verifying it, and then report the results back to the system, staking or re-staking assets through EigenLayer to provide financial guarantees for their actions. If malicious behavior is confirmed, there will be a risk of confiscation of pledged assets. As one of the earliest AVS (Active Verification Service) on the EigenLayer mainnet, OpenLayer has attracted more than 50 operators and $4 billion in re-staking assets.
In general, the decentralized data layer built by OpenLayer expands the scope and diversity of available data without sacrificing practicality and efficiency, while ensuring the authenticity and integrity of the data through encryption technology and economic incentives. Its technology has a wide range of practical applications for Web3 Dapps seeking to gain off-chain trust, companies that need real input to train and infer AI models, and companies that want to segment and price users based on their identity and reputation. Users can also value their private data.
4.2.1 Main Components of Grass
4.2 Grass
Grass is a flagship project developed by Wynd Network, which aims to create a decentralized web crawler and AI training data platform. At the end of 2023, the Grass project completed a $3.5 million seed round led by Polychain Capital and Tribe Capital. Then, in September 2024, the project received a Series A round led by HackVC, with participation from well-known investment institutions such as Polychain, Delphi, Lattice and Brevan Howard.
We mentioned that AI training requires new data input, and one of the solutions is to use multiple IPs to break through data access permissions and feed data for AI. Grass started from this and created a distributed crawler node network dedicated to decentralized physical infrastructure, using users' idle bandwidth to collect and provide verifiable data sets for AI training. The node routes web requests through the user's Internet connection, accesses public websites and compiles structured data sets. It uses edge computing technology for preliminary data cleaning and formatting to improve data quality.
Grass adopts the Solana Layer 2 Data Rollup architecture, built on top of Solana to improve processing efficiency. Grass uses validators to receive, verify, and batch web transactions from nodes, generating ZK proofs to ensure data authenticity. The verified data is stored in the data ledger (L2) and linked to the corresponding L1 on-chain proof.
4.2.1 Main Components of Grass
a) Grass Node
Similar to OpenNodes, C-end users install the Grass application or browser extension and run it, using idle bandwidth for web crawling operations. The node routes web requests through the user's Internet connection, accesses public websites and compiles structured data sets, and uses edge computing technology for preliminary data cleaning and formatting. Users are rewarded with GRASS tokens based on the bandwidth and data volume they contribute.
b) Routers
Connecting Grass nodes and validators, managing the node network and relaying bandwidth. Routers are incentivized to operate and receive rewards, the reward ratio is proportional to the total verification bandwidth relayed through them.
c) Validators
Receive, verify and batch web transactions from the router, generate ZK proofs, use unique key sets to establish TLS connections, and select appropriate cipher suites for communication with the target web server. Grass currently uses centralized validators, with plans to move to a validator committee in the future.
d) ZK Processor
Receives proofs of each node’s session data generated by validators, batches validity proofs for all web requests and submits them to Layer 1 (Solana).
e) Grass Data Ledger (Grass L2)
The complete dataset is stored and linked to the corresponding L1 chain (Solana) for proof.
f) Edge Embedding Model
Responsible for converting unstructured web data into structured models that can be used for AI training.
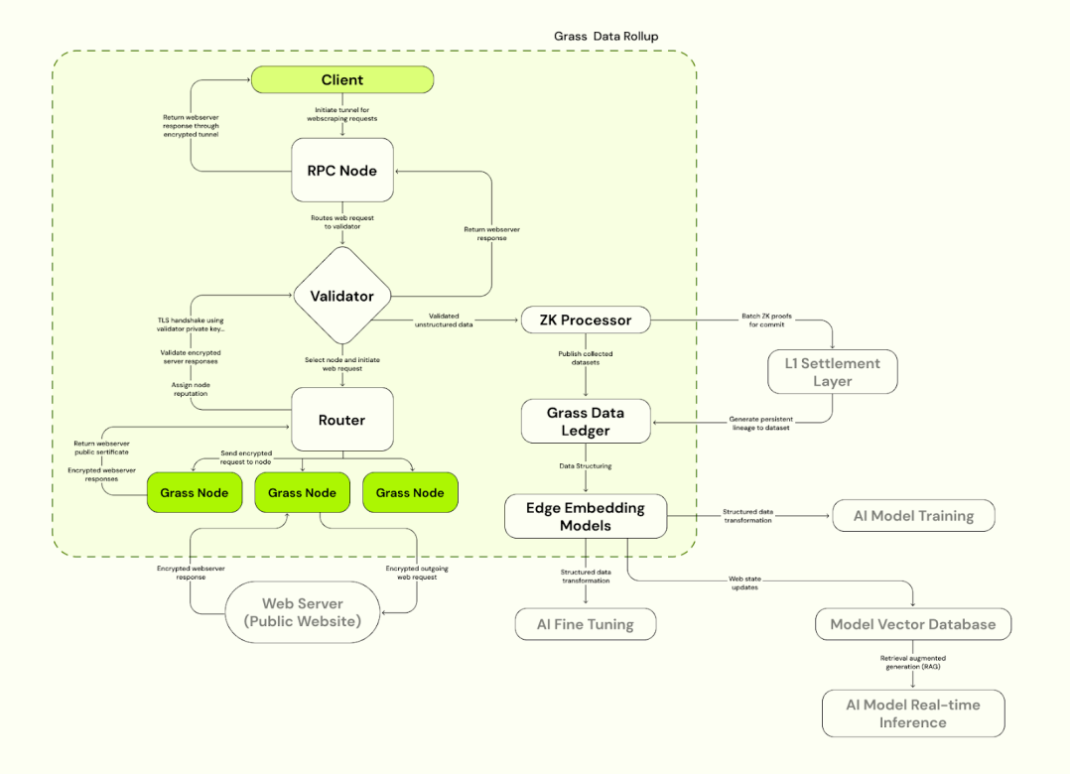
Analysis and comparison of Grass and OpenLayer
Both OpenLayer and Grass use distributed networks to provide companies with access to open Internet data and closed information that requires identity verification. Incentive mechanisms promote data sharing and the production of high-quality data. Both are committed to creating a decentralized data layer to solve the problem of data access and verification, but use slightly different technical paths and business models.
Differences in technical architecture
Grass uses the Solana Layer 2 Data Rollup architecture and currently uses a centralized verification mechanism with a single validator. As one of the first AVS, OpenLayer is built on EigenLayer and uses economic incentives and confiscation mechanisms to implement a decentralized verification mechanism. It also adopts a modular design, emphasizing the scalability and flexibility of data verification services.
Product Differences
Both provide similar To C products, allowing users to realize the value of data through nodes. On the To B side, Grass provides an interesting data market model and uses L2 to verify and store complete data, which comes from AI companies to provide structured, high-quality, and verifiable training sets. OpenLayer does not have a dedicated data storage component for the time being, but provides a wider range of real-time data stream verification services (Vaas). In addition to providing data for AI, it is also suitable for scenarios that require rapid response, such as serving as an Oracle to feed prices for RWA/DeFi prediction market projects and provide real-time social data.
Therefore, Grass's target customer base today is mainly AI companies and data scientists, providing large-scale, structured training data sets, and also serving research institutions and enterprises that need large amounts of network data; while OpenLayer is temporarily aimed at on-chain developers who need off-chain data sources, AI companies that need real-time, verifiable data streams, and Web2 companies that support innovative user acquisition strategies, such as verifying product usage history.
Potential future competition
However, considering the development trend of the industry, the functions of the two projects may indeed converge in the future. Grass may also provide real-time structured data in the near future. As a modular platform, OpenLayer may also expand to data set management and have its own data ledger in the future, so the competition areas of the two may gradually overlap.
In addition, both projects may consider adding data labeling, a key step. Grass may advance faster in this regard because they have a large node network - reportedly more than 2.2 million active nodes. This advantage gives Grass the potential to provide human feedback-based reinforcement learning (RLHF) services, using large amounts of labeled data to optimize AI models.
However, OpenLayer, with its expertise in data verification and real-time processing, and its focus on private data, may maintain its advantage in data quality and credibility. In addition, as one of EigenLayer's AVS, OpenLayer may have deeper developments in decentralized verification mechanisms.
While the two projects may compete in certain areas, their respective unique advantages and technology paths may also lead them to occupy different niches in the data ecosystem.

4.3 VAVA
As a user-centric data pool network, Vana is also committed to providing high-quality data for AI and related applications. Compared with OpenLayer and Grass, Vana adopts a more different technical path and business model. Vana completed a $5 million financing in September 2024, led by Coinbase Ventures. Previously, it received $18 million in Series A financing led by Paradigm. Other well-known investors include Polychain, Casey Caruso, etc.
Initially launched as a research project at MIT in 2018, Vana aims to be a Layer 1 blockchain designed specifically for users' private data. Its innovations in data ownership and value distribution enable users to profit from AI models trained on their data. The core of Vana is to enable the circulation and value of private data through a trustless, private and visible data liquidity pool and an innovative Proof of Contribution mechanism:
4.3.1 Data Liquidity Pool
Vana introduces a unique concept of Data Liquidity Pool (DLP): As a core component of the Vana network, each DLP is an independent peer-to-peer network used to aggregate specific types of data assets. Users can upload their private data (such as shopping records, browsing habits, social media activities, etc.) to a specific DLP and flexibly choose whether to authorize the data to specific third parties. Data is integrated and managed through these liquidity pools, and the data is de-identified to ensure user privacy while allowing the data to participate in commercial applications, such as AI model training or market research.
Users submit data to DLP and receive corresponding DLP tokens (each DLP has a specific token) as rewards. These tokens not only represent the total contribution of user data, but also give users the right to govern DLP and the right to distribute future profits. Users can not only share data, but also obtain continuous income from subsequent calls to the data (and provide visual tracking). Unlike traditional one-time data sales, Vana allows data to continuously participate in the economic cycle.
4.3.2 Proof of Contribution Mechanism
Another core innovation of Vana is the Proof of Contribution mechanism. This is a key mechanism for Vana to ensure data quality, allowing each DLP to control a unique contribution proof function based on its characteristics to verify the authenticity and integrity of the data and evaluate the contribution of the data to the performance improvement of the AI model. This mechanism ensures that the user's data contribution is quantified and recorded, thereby providing rewards to the user.
Similar to the "Proof of Work" in cryptocurrency, Proof of Contribution distributes benefits to users based on the quality, quantity and frequency of data contributed by users. It is automatically executed through smart contracts to ensure that contributors receive rewards that match their contributions.
Vana's Technical Architecture
1. Data Liquidity Layer
This is the core layer of Vana, responsible for data contribution, verification and recording to DLPs, and introducing data as a transferable digital asset on the chain. DLP creates and deploys DLP smart contracts, setting data contribution purposes, verification methods and contribution parameters. Data contributors and custodians submit data for verification, and the Proof of Contribution (PoC) module performs data verification and value assessment, granting governance rights and rewards based on parameters.
2. Data Portability Layer
This is an open data platform for data contributors and developers, and also the application layer of Vana. The Data Portability Layer provides a collaborative space for data contributors and developers to build applications using the data liquidity accumulated in DLPs. It provides infrastructure for distributed training of User-Owned models and AI Dapp development.
3. Universal Connectome
A decentralized ledger and a real-time data flow graph throughout the Vana ecosystem, using Proof of Stake consensus to record real-time data transactions in the Vana ecosystem. Ensures the effective transfer of DLP tokens and provides cross-DLP data access for applications. Compatible with EVM, allowing interoperability with other networks, protocols, and DeFi applications.
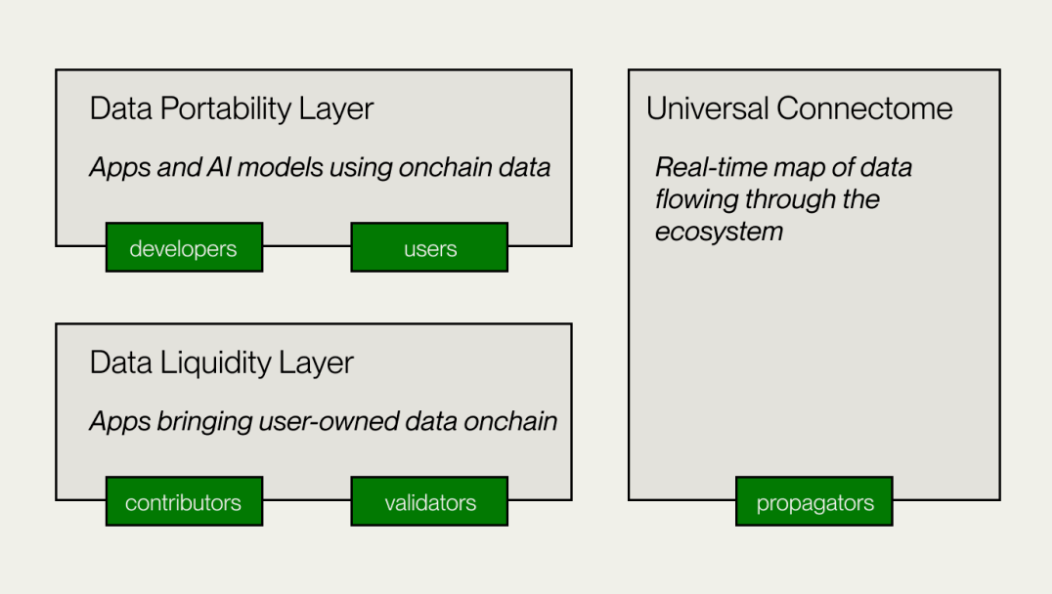
Vana provides a different path, focusing on the liquidity and value empowerment of user data. This decentralized data exchange model is not only suitable for scenarios such as AI training and data markets, but also provides a new solution for cross-platform interoperability and authorization of user data in the Web3 ecosystem, ultimately creating an open Internet ecosystem where users can own and manage their own data, as well as the smart products created from this data.
5. Value Proposition of Decentralized Data Networks
In 2006, data scientist Clive Humby said that data is the oil of the new era. In the past 20 years, we have witnessed the rapid development of "refining" technology. Technologies such as big data analysis and machine learning have unprecedentedly released the value of data. According to IDC's forecast, by 2025, the global data circle will grow to 163 ZB, most of which will come from individual users. With the popularization of emerging technologies such as IoT, wearable devices, AI and personalized services, a large amount of data needed in the future will also come from individuals.
Pain points of traditional solutions: Unlocking innovations of Web3
Web3 data solutions break through the limitations of traditional facilities through a distributed node network, achieving more extensive and efficient data collection, while improving the efficiency of real-time acquisition and verification credibility of specific data. In this process, Web3 technology ensures the authenticity and integrity of the data and can effectively protect user privacy, thereby achieving a fairer data utilization model. This decentralized data architecture promotes the democratization of data acquisition.
Whether it is the user node model of OpenLayer and Grass, or the monetization of user private data by Vana, in addition to improving the efficiency of specific data collection, it also allows ordinary users to share the dividends of the data economy, creating a win-win model for users and developers, allowing users to truly control and benefit from their data and related resources.
Through token economic incentives, the Web3 data solution redesigns the incentive model and creates a fairer data value distribution mechanism, attracting a large number of users, hardware resources and capital injection, thereby coordinating and optimizing the operation of the entire data network.
Compared with traditional data solutions, they also have modularity and scalability: For example, the modular design of OpenLayer provides flexibility for future technology iteration and ecological expansion. Thanks to the technical characteristics, the data acquisition method for AI model training is optimized to provide richer and more diverse data sets.
From data generation, storage, verification to exchange and analysis, Web3-driven solutions solve many of the shortcomings of traditional facilities through unique technical advantages, while also giving users the ability to monetize their personal data, triggering a fundamental change in the data economy model. As technology further develops and evolves and application scenarios expand, the decentralized data layer is expected to become the next generation of critical infrastructure together with other Web3 data solutions, providing support for a wide range of data-driven industries.
From data generation, storage, verification to exchange and analysis, Web3-driven solutions solve many of the shortcomings of traditional facilities through unique technical advantages, while also giving users the ability to monetize their personal data, triggering a fundamental change in the data economy model. As technology further develops and evolves and application scenarios expand, the decentralized data layer is expected to become the next generation of critical infrastructure together with other Web3 data solutions, providing support for a wide range of data-driven industries.