Image source: Generated by Boundless AI
Just now, Jieya Xingchen and Geely Automobile Group jointly open-sourced two multi-modal large models!
The new models are:
- The largest open-source video generation model Step-Video-T2V in the world
- The industry's first product-level open-source speech interaction KOL model Step-Audio
The multi-modal champion begins to open-source multi-modal models, and Step-Video-T2V adopts the most open and relaxed MIT open-source protocol, which can be freely edited and commercially applied.
(As usual, GitHub, Baobao Face, and Magic Dock can be seen at the end of the article)
In the R&D process of the two KOL models, the two parties complemented each other's advantages in computing power, algorithms, and scenario training, "significantly enhancing the performance of the multi-modal KOL models".
According to the official technical report, the two models open-sourced this time performed excellently in the Benchmark, with performance exceeding similar open-source models at home and abroad.
Baobao Face's China regional manager also forwarded a high evaluation.
The key points are "The next DeepSeek" and "HUGE SoTA".
Oh, really?
Then Quantum Position will have to pry open the technical report + first-hand test in this article to see if they are truly worthy of their name.
Quantum Position seeks verification, and currently, the two new open-source models have been integrated into the Yuewen App, and everyone can experience them.
The Multi-Modal Champion's First Open-Source of Multi-Modal Models
Step-Video-T2V and Step-Audio are the first multi-modal models open-sourced by Jieya Xingchen.
Step-Video-T2V
Let's take a look at the video generation model Step-Video-T2V.
Its parameter size reaches 30B, which is the largest open-source video generation KOL model known globally, with native support for Chinese and English input.
The official introduction lists 4 key technical features of Step-Video-T2V:
First, it can directly generate videos up to 204 frames and 540P resolution, ensuring high consistency and information density of the generated video content.
Second, a high-compression Video-VAE was designed and trained for video generation tasks. While ensuring video reconstruction quality, it can compress videos 16×16 times in the spatial dimension and 8 times in the temporal dimension.
Third, Step-Video-T2V has conducted in-depth systematic optimization on the hyperparameter setting, model structure, and training efficiency of the DiT model, ensuring the efficiency and stability of the training process.
Fourth, it details the complete training strategy, including the training tasks, learning objectives, and data construction and screening methods in the pre-training and post-training stages.
In addition, Step-Video-T2V introduces Video-DPO (Video Preference Optimization) in the final stage of training - a reinforcement learning optimization algorithm for video generation, which can further improve the quality of video generation and strengthen the rationality and stability of the generated videos.
The final effect is to make the motion in the generated videos smoother, the details richer, and the instruction alignment more accurate.
To comprehensively evaluate the performance of open-source video generation models, Jieya has also released a new benchmark dataset Step-Video-T2V-Eval for text-to-video quality evaluation.
This dataset is also open-sourced~
It contains 128 Chinese evaluation questions from real users, aiming to evaluate the quality of generated videos in 11 content categories, including motion, scenery, animals, composite concepts, surreal, etc.
The evaluation results of Step-Video-T2V on Step-Video-T2V-Eval are as follows:
It can be seen that Step-Video-T2V outperforms the previous best open-source video models in terms of instruction following, motion smoothness, physical plausibility, and aesthetics.
This means that the entire video generation field can now conduct research and innovation based on this new strongest base model.
As for the actual effect, the Jieya official introduced:
In terms of generation effect, Step-Video-T2V has powerful generation capabilities in complex motion, aesthetic characters, visual imagination, basic text generation, native Chinese and English input, and camera language, and has outstanding semantic understanding and instruction following capabilities, which can efficiently assist video creators to achieve precise creative presentation.
Let's put it to the test!
First, test whether Step-Video-T2V can handle complex motion.
Previous video generation models often produced strange scenes when generating segments of complex movements like ballet, ballroom dancing, Chinese dance, artistic gymnastics, karate, and martial arts.
Targeted testing shows that Step-Video-T2V's performance is impressive.
The second challenge for Step-Video-T2V is to generate "aesthetic characters".
Theoretically, current text-to-image models can generate realistic human portraits. But when it comes to video generation, there are still identifiable physical or logical flaws when the characters start moving.
Step-Video-T2V's performance in this regard is also commendable - the generated character looks natural and lifelike.
The above two tests were conducted with fixed camera positions.
The third test examines Step-Video-T2V's mastery of camera movements like panning, tilting, and rotating.
The test results show that Step-Video-T2V can handle these camera movements well.
After a series of tests, the generation effect proves that Step-Video-T2V indeed has outstanding semantic understanding and instruction following capabilities, and can even easily handle basic text generation.
Step-Audio
The other model open-sourced at the same time, Step-Audio, is the industry's first open-source product-level speech interaction KOL.
In the StepEval-Audio-360 benchmark test system built and open-sourced by Jieya, Step-Audio achieved the best results in dimensions like logical reasoning, creative ability, instruction control, language ability, role-playing, word games, and emotional value.
In mainstream public test sets like LlaMA Question and Web Questions, Step-Audio's performance exceeds that of similar open-source models in the industry, ranking first.
Its performance in the HSK-6 (Chinese Proficiency Test Level 6) evaluation is particularly outstanding.Here is the English translation of the text, with the specified terms translated as requested:
Image source: Generated by Boundless AI
Just now, Jieya Xingchen and Geely Automobile Group jointly open-sourced two multi-modal large models!
The new models are:
- The largest open-source video generation model Step-Video-T2V in the world
- The industry's first product-level open-source speech interaction KOL model Step-Audio
The multi-modal champion begins to open-source multi-modal models, and Step-Video-T2V adopts the most open and relaxed MIT open-source protocol, which can be freely edited and commercially applied.
(As usual, GitHub, Baobao Face, and Magic Dock can be seen at the end of the article)
In the R&D process of the two KOL models, the two parties complemented each other's advantages in computing power, algorithms, and scenario training, "significantly enhancing the performance of the multi-modal KOL models".
According to the official technical report, the two models open-sourced this time performed excellently in the Benchmark, with performance exceeding similar open-source models at home and abroad.
Baobao Face's China regional manager also forwarded a high evaluation.
The key points are "The next DeepSeek" and "HUGE SoTA".
Oh, really?
Then Quantum Position will have to pry open the technical report + first-hand test in this article to see if they are truly worthy of their name.
Quantum Position seeks verification, and currently, the two new open-source models have been integrated into the Yuewen App, and everyone can experience them.
The Multi-Modal Champion's First Open-Source of Multi-Modal Models
Step-Video-T2V and Step-Audio are the first multi-modal models open-sourced by Jieya Xingchen.
Step-Video-T2V
Let's take a look at the video generation model Step-Video-T2V.
Its parameter size reaches 30B, which is the largest open-source video generation KOL model known globally, with native support for Chinese and English input.
The official introduction lists 4 key technical features of Step-Video-T2V:
First, it can directly generate videos up to 204 frames and 540P resolution, ensuring high consistency and information density of the generated video content.
Second, a high-compression Video-VAE was designed and trained for video generation tasks. While ensuring video reconstruction quality, it can compress videos 16×16 times in the spatial dimension and 8 times in the temporal dimension.
Third, Step-Video-T2V has conducted in-depth systematic optimization on the hyperparameter setting, model structure, and training efficiency of the DiT model, ensuring the efficiency and stability of the training process.
Fourth, it details the complete training strategy, including the training tasks, learning objectives, and data construction and screening methods in the pre-training and post-training stages.
In addition, Step-Video-T2V introduces Video-DPO (Video Preference Optimization) in the final stage of training - a reinforcement learning optimization algorithm for video generation, which can further improve the quality of video generation and strengthen the rationality and stability of the generated videos.
The final effect is to make the motion in the generated videos smoother, the details richer, and the instruction alignment more accurate.
To comprehensively evaluate the performance of open-source video generation models, Jieya has also released a new benchmark dataset Step-Video-T2V-Eval for text-to-video quality evaluation.
This dataset is also open-sourced~
It contains 128 Chinese evaluation questions from real users, aiming to evaluate the quality of generated videos in 11 content categories, including motion, scenery, animals, composite concepts, surreal, etc.
The evaluation results of Step-Video-T2V on Step-Video-T2V-Eval are as follows:
It can be seen that Step-Video-T2V outperforms the previous best open-source video models in terms of instruction following, motion smoothness, physical plausibility, and aesthetics.
This means that the entire video generation field can now conduct research and innovation based on this new strongest base model.
As for the actual effect, the Jieya official introduced:
In terms of generation effect, Step-Video-T2V has powerful generation capabilities in complex motion, aesthetic characters, visual imagination, basic text generation, native Chinese and English input, and camera language, and has outstanding semantic understanding and instruction following capabilities, which can efficiently assist video creators to achieve precise creative presentation.
Let's put it to the test!
First, test whether Step-Video-T2V can handle complex motion.
Previous video generation models often produced strange scenes when generating segments of complex movements like ballet, ballroom dancing, Chinese dance, artistic gymnastics, karate, and martial arts.
Targeted testing shows that Step-Video-T2V's performance is impressive.
The second challenge for Step-Video-T2V is to generate "aesthetic characters".
Theoretically, current text-to-image models can generate realistic human portraits. But when it comes to video generation, there are still identifiable physical or logical flaws when the characters start moving.
Step-Video-T2V's performance in this regard is also commendable - the generated character looks natural and lifelike.
The above two tests were conducted with fixed camera positions.
The third test examines Step-Video-T2V's mastery of camera movements like panning, tilting, and rotating.
The test results show that Step-Video-T2V can handle these camera movements well.
After a series of tests, the generation effect proves that Step-Video-T2V indeed has outstanding semantic understanding and instruction following capabilities, and can even easily handle basic text generation.
Step-Audio
The other model open-sourced at the same time, Step-Audio, is the industry's first open-source product-level speech interaction KOL.
In the StepEval-Audio-360 benchmark test system built and open-sourced by Jieya, Step-Audio achieved the best results in dimensions like logical reasoning, creative ability, instruction control, language ability, role-playing, word games, and emotional value.
In mainstream public test sets like LlaMA Question and Web Questions, Step-Audio's performance exceeds that of similar open-source models in the industry, ranking first.
Its performance in the HSK-6 (Chinese Proficiency Test Level 6) evaluation is particularly outstanding.Here is the English translation of the text, with the specified terms translated as requested:
The Step-Audio team introduced that Step-Audio can generate expressions of emotion, dialect, language, singing, and personalized styles according to different scenario needs, and can have natural and high-quality dialogues with users.
At the same time, the voice generated by it not only has the characteristics of realistic and natural, high emotional intelligence, but also can achieve high-quality timbre replication and role-playing.
In short, in scenarios such as film and television entertainment, social networking, and gaming, the application demand of Step-Audio will fully satisfy you.
The Step open-source ecosystem is snowballing
How to put it, just one word: rolling.
Step is really rolling, especially in the multi-modal model, which is its forte -
The multi-modal models in the Step series under its brand have been the top-ranked in various authoritative evaluation sets and competitions at home and abroad since their inception.
Just in the last 3 months, they have won the top spot several times.
On November 22 last year, the latest ranking of the large model competition arena, the multi-modal understanding large model Step-1V was listed, with the same total score as Gemini-1.5-Flash-8B-Exp-0827, ranking first among Chinese large models in the visual field.
In January this year, the real-time ranking of the multi-modal model evaluation of the domestic large model evaluation platform "Compass" (OpenCompass), the newly released Step-1o series model took the first place.
On the same day, the latest ranking of the large model competition arena, the multi-modal model Step-1o-vision won the first place among domestic large models in the visual field.

Secondly, Step's multi-modal models not only have good performance and quality, but also have a high frequency of research and development -
As of now, Step has released 11 multi-modal large models in succession.
Last month, 6 models were released in 6 days, covering the full track of language, speech, vision, and reasoning, further consolidating the title of the multi-modal KOL.
This month, 2 more multi-modal models have been open-sourced.
As long as this pace is maintained, it can continue to prove its status as a "full-stack multi-modal player".
Relying on its strong multi-modal strength, since 2024, the market and developers have recognized and widely accessed the Step API, forming a huge user base.
Consumer products, such as Cha Bai Dao, have allowed thousands of stores nationwide to access the multi-modal understanding large model Step-1V, exploring the application of large model technology in the tea beverage industry, for intelligent inspection and AIGC marketing.
Public data shows that an average of more than 1 million cups of Cha Bai Dao tea beverages are delivered to consumers under the protection of the large model intelligent inspection every day.
And Step-1V can save 75% of the self-inspection and verification time for Cha Bai Dao supervisors on average every day, providing consumers with more reassuring and high-quality services.
Independent developers, such as the KOL AI application "Stomach Book" and the AI psychological healing application "Forest Chat Room", have all chosen the Step multi-modal model API after AB testing most domestic models.
(Whisper: Because using it has the highest conversion rate.)
Specific data shows that in the second half of 2024, the call volume of Step's multi-modal large model API grew by more than 45 times.

Also, this open-source is Step's own multi-modal model, which it is most proficient in.
We notice that Step, which has accumulated market and developer reputation and volume, this open-source is considering deeper integration from the model side.
On the one hand, Step-Video-T2V adopts the most open and relaxed MIT open-source license, allowing for free editing and commercial application.
It can be said to be "completely open".
On the other hand, Step said "fully reducing the industry access threshold".
Take Step-Audio as an example, unlike the open-source solutions on the market that require re-deployment and re-development, Step-Audio is a complete real-time dialogue solution, just simple deployment can directly realize real-time dialogue.
Zero frame start can enjoy the end-to-end experience.
All in all, around Step and its multi-modal model trump card, a unique open-source technology ecosystem for Step has initially formed.
In this ecosystem, technology, creativity and commercial value are intertwined, jointly promoting the development of multi-modal technology.
And with the continued research and development of Step models, the rapid and continuous access of developers, the support and joint efforts of ecosystem partners, the "snowball effect" of Step's ecosystem has already occurred and is growing stronger.
China's open-source power is speaking with strength
At one time, when people thought of the leaders in the open-source field of large models, the names that came to mind were Meta's LLaMA and Albert Gu's Mamba.
Now, there is no doubt that the open-source power of China's large model community has shone globally, using its strength to rewrite the "stereotypes".
January 20, on the eve of the Spring Festival of the Year of the Snake, was a day when AI gods fought in China and abroad.
The most eye-catching was that DeepSeek-R1 was born on that day, with reasoning performance on par with OpenAI's o1, but at only 1/3 the cost.
The impact was so great that it caused Nvidia to evaporate $589 billion (about 4.24 trillion yuan) in a single day, setting a record for the largest single-day drop in the US stock market.
More importantly and more dazzling is that the reason why R1 has risen to the level of excitement for millions of people is not only its excellent reasoning and affordable price, but more importantly, its open-source attribute.
A stone that stirred up a thousand waves, even the long-ridiculed "no longer open" OpenAI had its CEO Altman repeatedly come out to speak publicly.
Altman said: "On the issue of open-source weight AI models, (in my opinion) we have been on the wrong side of history."
He also said: "The world really needs open-source models, they can provide a lot of value to people. I'm glad there are some excellent open-source models in the world."

Now, Step is also starting to open-source its new trump cards.
And the open-source is the original intention.
The official said that the purpose of open-sourcing Step-Video-T2V and Step-Audio is to promote the sharing and innovation of large model technology, and to drive the inclusive development of artificial intelligence.
As soon as it was open-sourced, it showed off its strength in multiple evaluation sets.
Now on the table of open-source large models, DeepSeek pushes strong reasoning, Step's Step focuses on multi-modal, and there are various other players continuing to grow...
Their strength is not only at the forefront in the open-source circle, but also very impressive in the entire large model circle.
——China's open-source power, after emerging, is moving forward further.
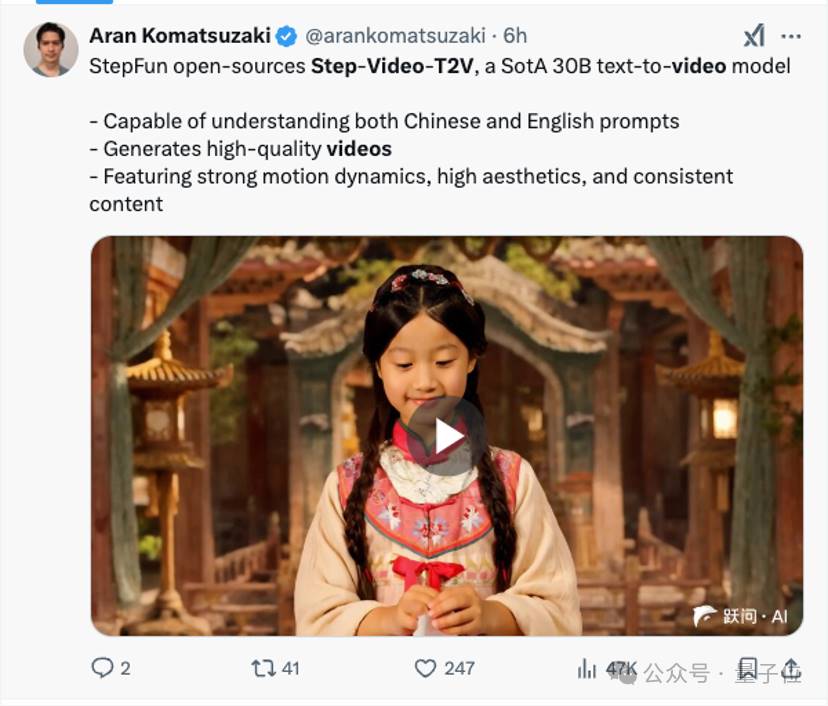
Taking Step's open-source this time as an example, the breakthrough is in the technology of the multi-modal field, and the change is in the choice logic of global developers.
Many active technical KOLs in open-source communities like Eleuther AI have actively come forward to test Step's models, "thanking China's open-source".
Wang Tiezhen, the head of Hugging Face China, directly stated that Step will be the next "DeepSeek".

From "technological breakthrough" to "ecological openness", the path of China's large models is becoming more and more stable.
Speaking of which, Step's open-sourcing of the two models this time may just be a footnote to the AI competition in 2025.
More fundamentally, it demonstrates China's open-source power's technological self-confidence, and conveys a signal:
In the future AI large model world, China's power will not be absent, nor will it fall behind.