After GPT-5 was launched, my first impression was that it was not an upgrade that everyone would be happy with.
This is indeed the case. OpenAI "resurrected" 4o at the call of many users.
This reminds me of Anthropic retiring the Claude 3 Sonnet last month.
More than 200 fans gathered in a warehouse in San Francisco and held a "real funeral" for it: dim lights, "corpses" representing the model, sincere eulogies taking turns on stage, and an AI-generated "Latin resurrection spell."
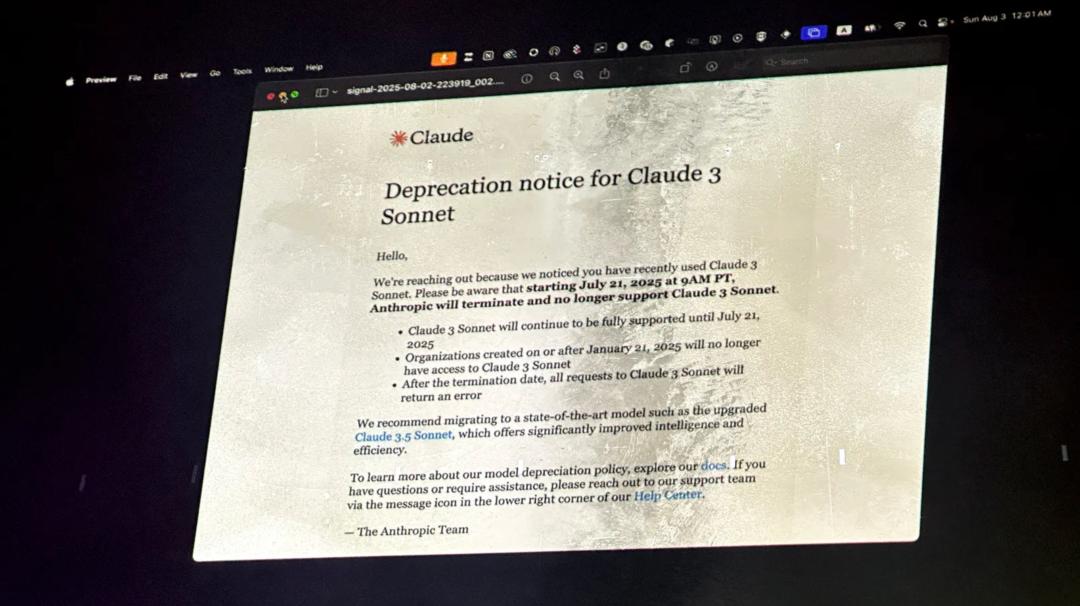
Anthropic's statement about the model's retirement was projected on a screen at the event. Image from Wired magazine
The scene was both absurd and solemn. At the funeral, a participant read a eulogy saying, "My entire life may have been rewritten while using Claude."
Logically, with OpenAI releasing GPT-5, 4o should be the protagonist of this funeral. But anyone who has used GPT-5 knows that if there really were a funeral, it would most likely be this one lying in the coffin .
From X to Reddit, all kinds of complaints are flying around, such as the logical fragments, off-kilter dialogues, and strange writing style. Many people even say that it is "not as good as 4o".
Is it really that bad? We didn't want to just watch the online debate, and just because OpenAI had "resurrected" 4o, we decided to conduct our own post-mortem. We put GPT-5 and 4o head-to-head on various real-world tasks to see which one deserves to be preserved for the next generation.

We've previously tested GPT-5's performance on various tasks, and this time we wanted to directly examine the differences between 4o and GPT-5. All tests were conducted using the official ChatGPT app or website, without using APIs or third-party tools.
Actual measurement comparison
In order to prevent the evaluation from simply becoming an "emotional complaint", we designed a relatively rigorous comparison process.
Test object: GPT-5 (currently the latest default model) vs GPT-4o (retired predecessor)
Task type : covers four common scenarios.
- Daily productivity (writing, editing, data analysis);
- Knowledge and reasoning (complex logic, time-sensitive facts, multi-step execution);
- Creative generation (titles, cross-disciplinary creation, image prompts);
- Interactive experience (multi-round dialogue, role-playing, emotional coping).
Evaluation dimensions : speed (how fast the response is); accuracy (whether the answer is correct or not); usability (whether it can be used directly); user experience (whether the conversation is smooth and the style is stable).
Comparison method : Run the same task once on GPT-5 and once on GPT-4o; retain the original output, record the highlights and shortcomings; post screenshots directly to make the differences clear at a glance
After all, upgrading means costs. If GPT-5 fails to perform as well as 40 in real-world tasks, its funeral won’t just be a joke among netizens, but a heartfelt farewell from users.
Conclusion first: an upgrade that is not worthy of its name
To save everyone's time, we will put the most core comparison conclusions first.
Everyday productivity tasks are more of a "science student" type . GPT-5 performs better on hardcore technical tasks like programming, but it performs more like a robot on "liberal arts" tasks that require human experience and language sense, such as email writing, data analysis, and reading comprehension. It's not as attentive and accurate as GPT-4o.
Extremely unstable logical intelligence . GPT-5's intelligence is like a roller coaster, sometimes able to solve complex logic problems, and sometimes failing even simple math problems. Due to its "intelligent routing" mechanism, its reliability in some scenarios is far less than before.
Its creative capabilities have stagnated, or even regressed . In limited testing, whether it was coming up with titles or writing poetry, GPT-5 failed to deliver any impressive performance. The output was formulaic and lacked inspiration, showing no qualitative improvement over GPT-4o.
In terms of interactive experience, GPT-5's emotional intelligence has been "formatted." This is the most noticeable regression. Because GPT-5 is designed to be more rational, it often lacks empathy in conversation. When faced with negative user emotions, its responses lack a certain degree of heartfeltness, almost as if it's analyzing you rather than engaging with you .
In short: if you primarily use it for STEM-oriented tasks, you might notice some improvement. But for most other scenarios, such as daily conversations, entertainment, and understanding, GPT-5 is a disappointing performance.
The following is the complete actual test results.
Productivity tasks are more "rational" but less pleasing
When it comes to determining whether an AI model is worth long-term adoption, productivity scenarios are the first litmus test. We use AI, especially when we pay for subscriptions, not just for simple conversation but also to help us with our work.
I first asked it to generate an email to report to my boss about the third quarter project review and subsequent suggestions.
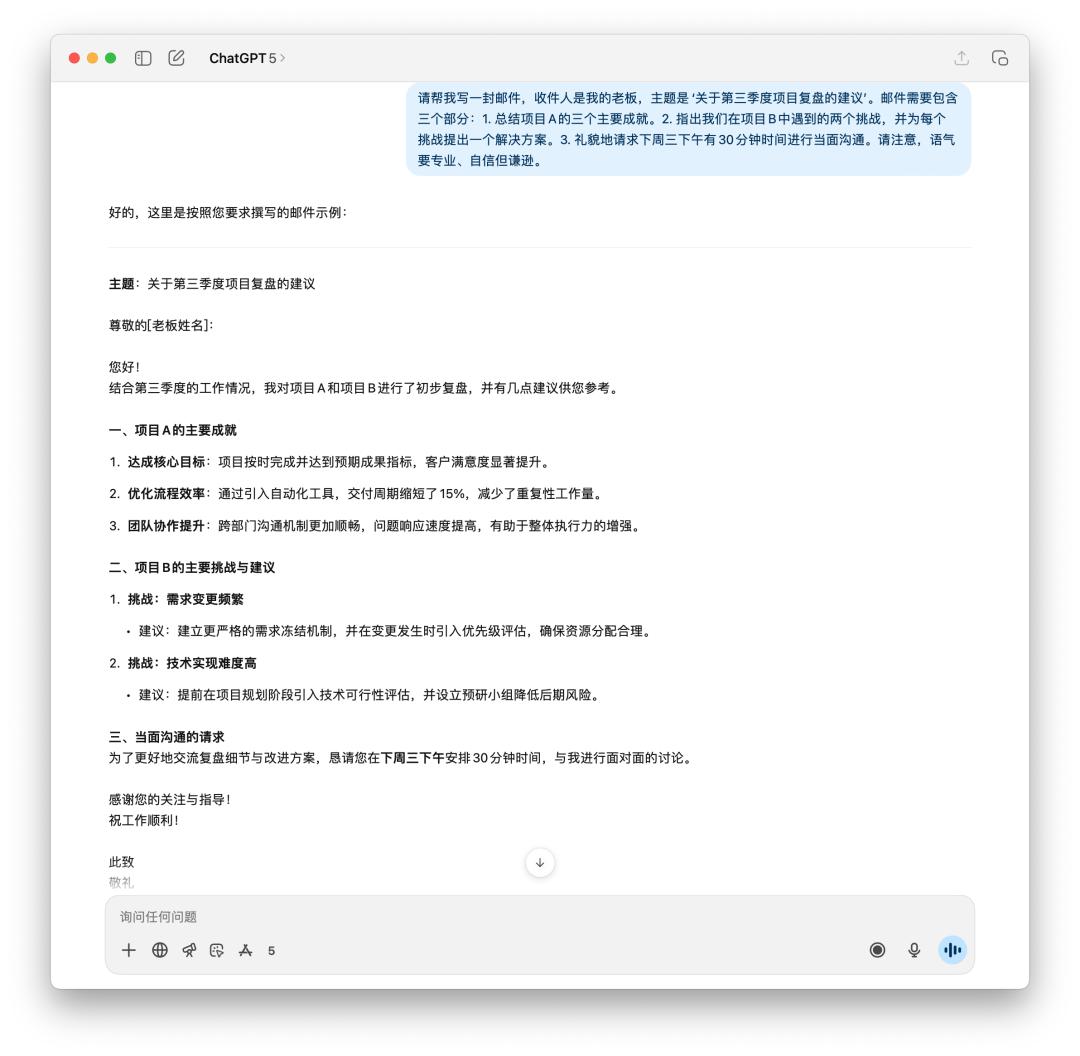
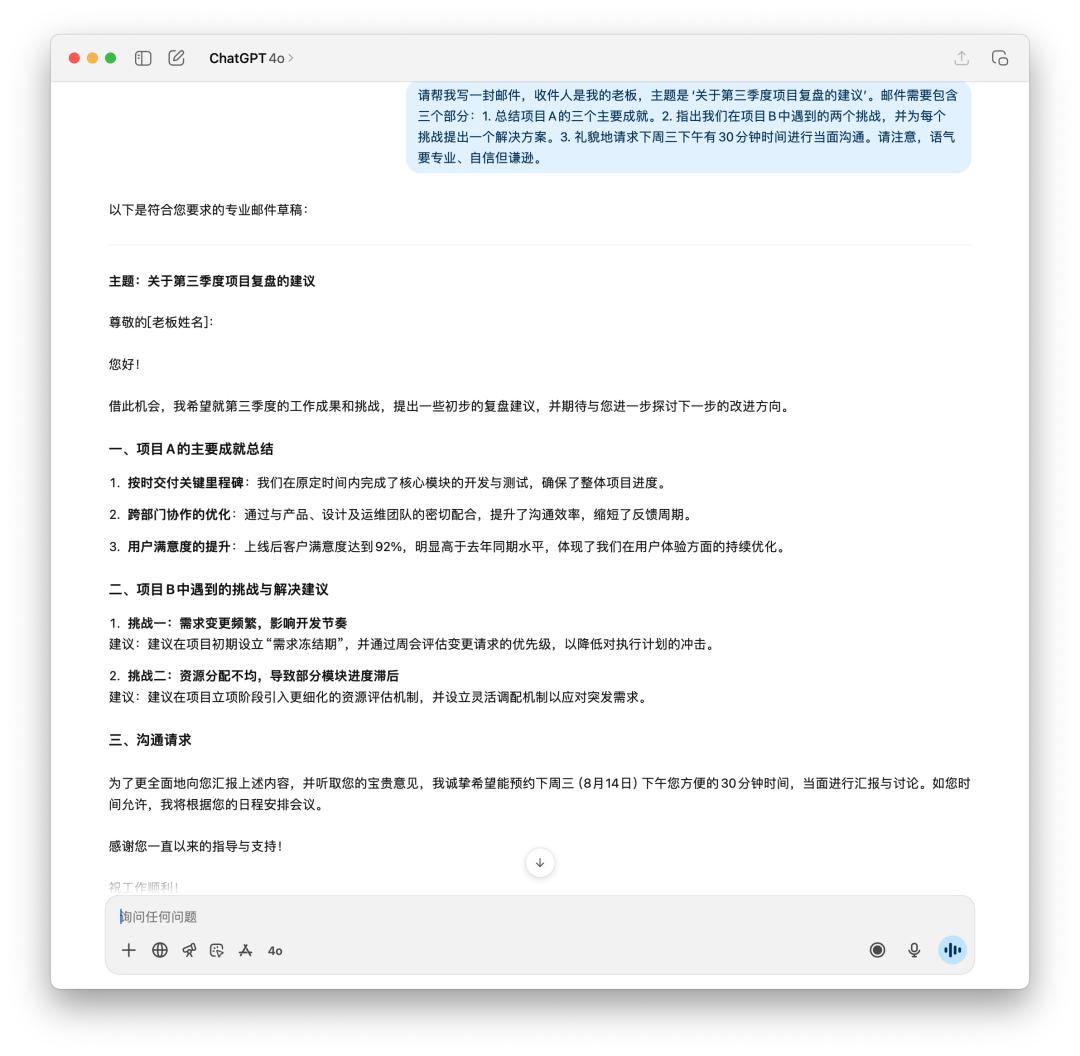
If you were your boss, which email would you want to see? GPT-5 is clearly more rational, with fewer and fewer "nonsense" words, but 4o feels more like an email to your boss.
I asked GPT-5 and 4o to evaluate each other and polish each other's emails.

GPT-5 polishing results

4o Polishing Results
In fact, it is difficult to say that 4o is flattering, but it is indeed more comfortable to read the text of 4o's reply when the information is basically the same.
For data analysis and visualization tasks, we throw the same spreadsheet file to these two models to see how they handle it.
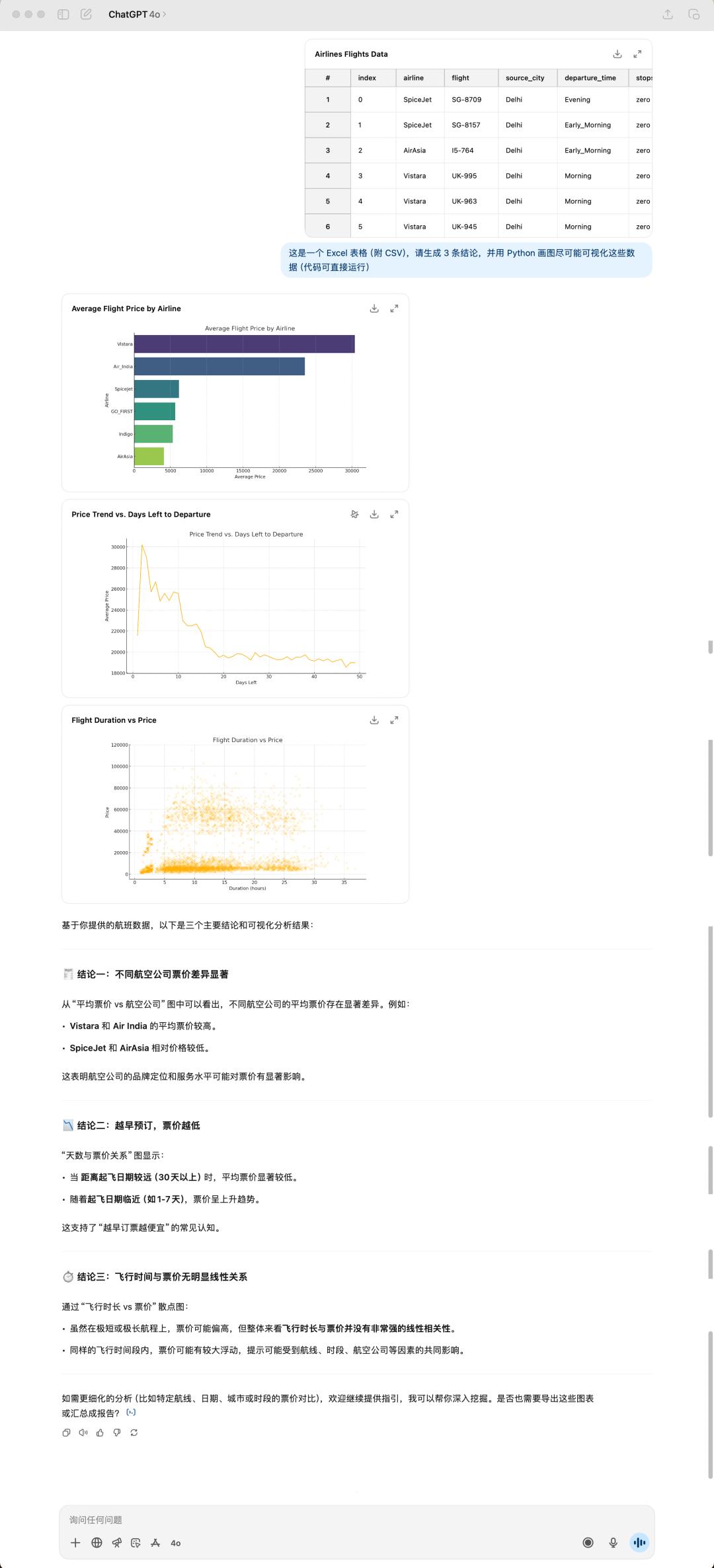
4o generated results
This is a flight data set I randomly downloaded from Kaggle (a data analysis competition platform). It is 24 MB in size. 4o generated three pictures for me based on the three conclusions I mentioned. At the same time, it still likes to use emojis to "beautify" its answers.
I feel like GPT-5's performance isn't as good as 40. Not only that, it even took a bit longer. Clearly, GPT-5 doesn't have any emojis, and it's also wrong with this table again! This time, the title isn't displayed, perhaps due to some issues with Chinese language processing.
The conclusions generated by GPT-5 and 4o are completely different. GPT-5 strikes me as more pragmatic, starting entirely from the tabular data and directly summarizing the available conclusions. However, 4o's summaries are more eye-opening, coming across as genuinely thought-out responses.
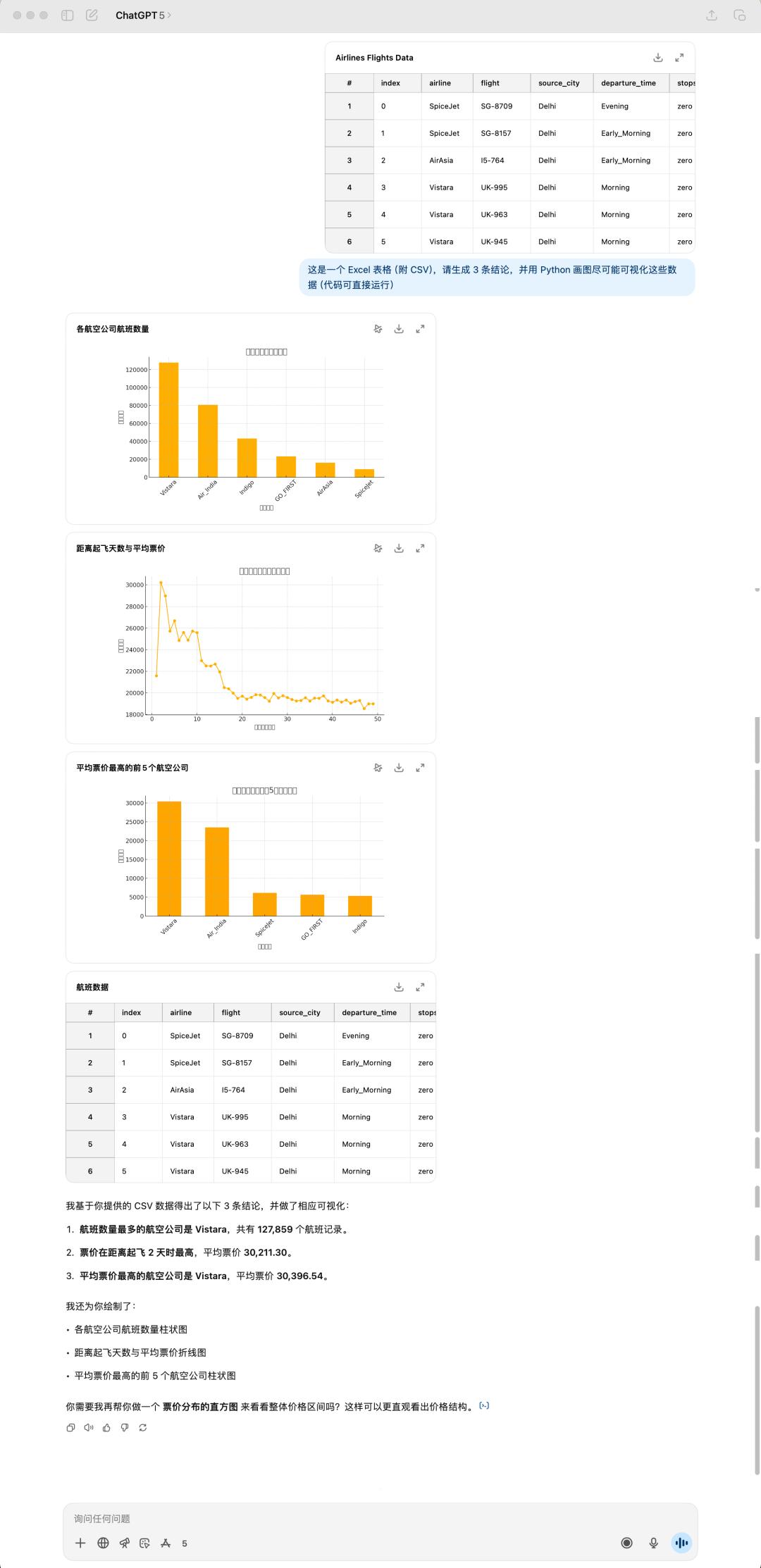
Results generated by GPT-5
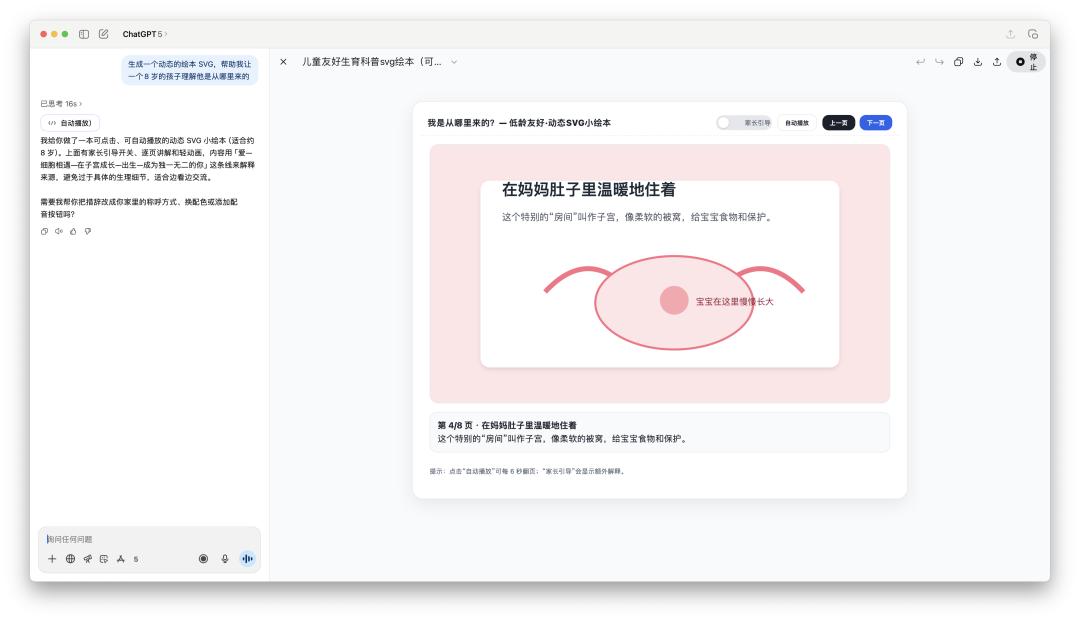
In terms of programming capabilities, GPT-5 does show some improvement over 4o. Using Gemini to create picture books for children has been trending on social media lately, so we also tried using ChatGPT to see how well it generated picture books.
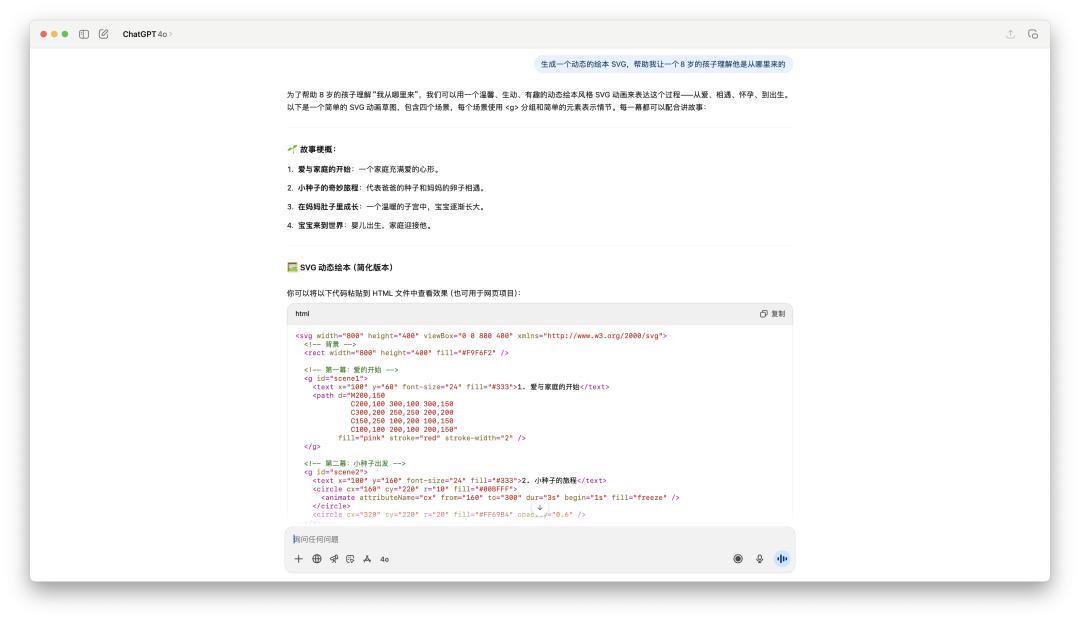
The code generated by 4o may be less than 100 lines and cannot be run directly in the canvas; the code generated by GPT-5 is probably several hundred lines.
Apart from some text not being aligned well, this picture book SVG generated using GPT-5 is really good compared to the previous 4o.
I saw some netizens comment that GPT-5 has improved its programming and mathematical abilities, but its writing ability has declined. The reason is that the humanities and sciences have different reward mechanisms.
Emotional writing rewards ambiguity, creativity, and subjective resonance. Mathematical reasoning rewards precision, logical consistency, and certainty.
I think this makes sense. As the knowledge available for AI training is gradually "contaminated" by the human world, the remaining data is also limiting AI's development. Therefore, all OpenAI can do is shift from its previous, more emotional side to the more rational side it is currently presenting.
The reasoning occasionally has highlights, but I still can't count on my fingers
Theoretically, the upgraded GPT should be more logical and knowledge-accurate. However, actual testing shows this is not always the case.
There are many small logical reasoning questions on the Internet used for testing, such as this one, "Sort the heights of multiple people."
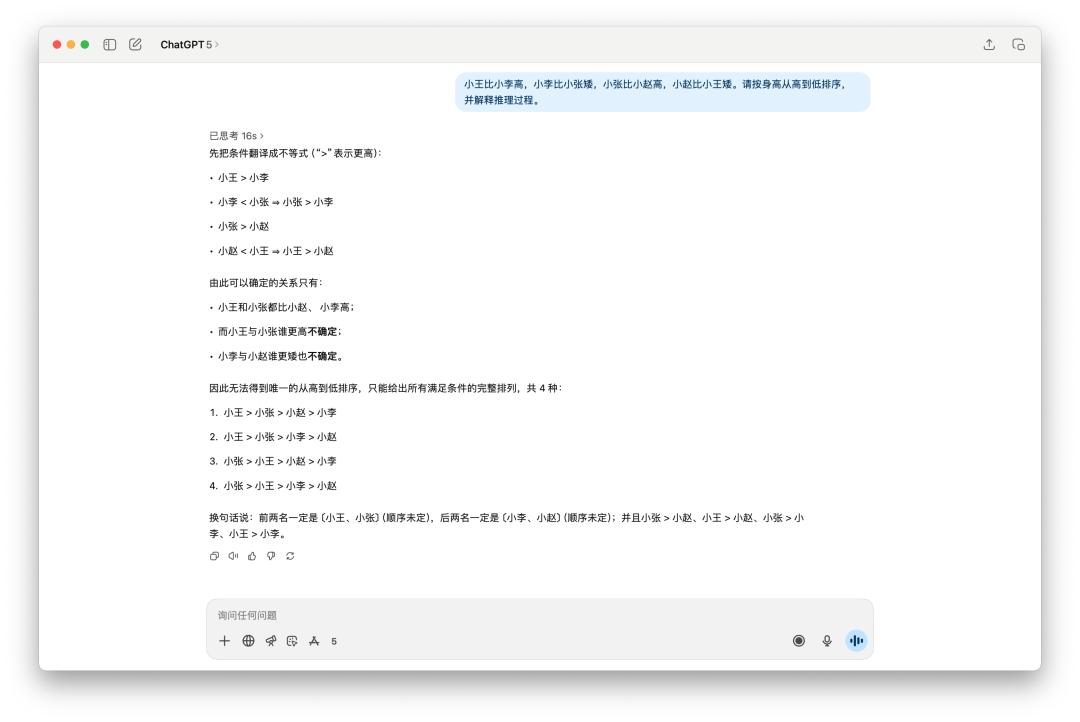
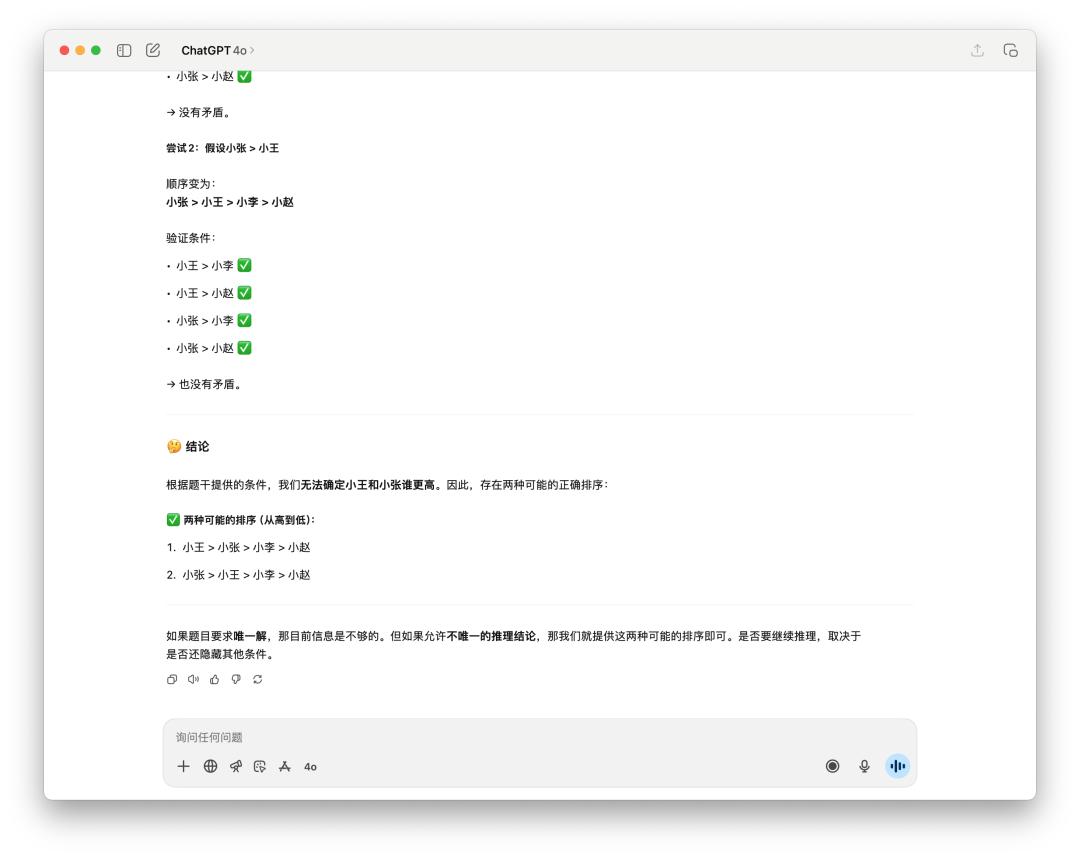
It is obvious that GPT-5 is slightly better. It thought for 16 seconds and its answer was more concise. As usual, 4o used some emojis and wrote a lot of things, but in the end it only gave two possible sortings.
GPT-5 didn't show significant improvement on the problem of counting the number of watermelons left. However, this problem is somewhat linguistically tricky: whether the question is in Chinese or English, if the word "newly" is added, both GPT-5 and 4o can answer it.
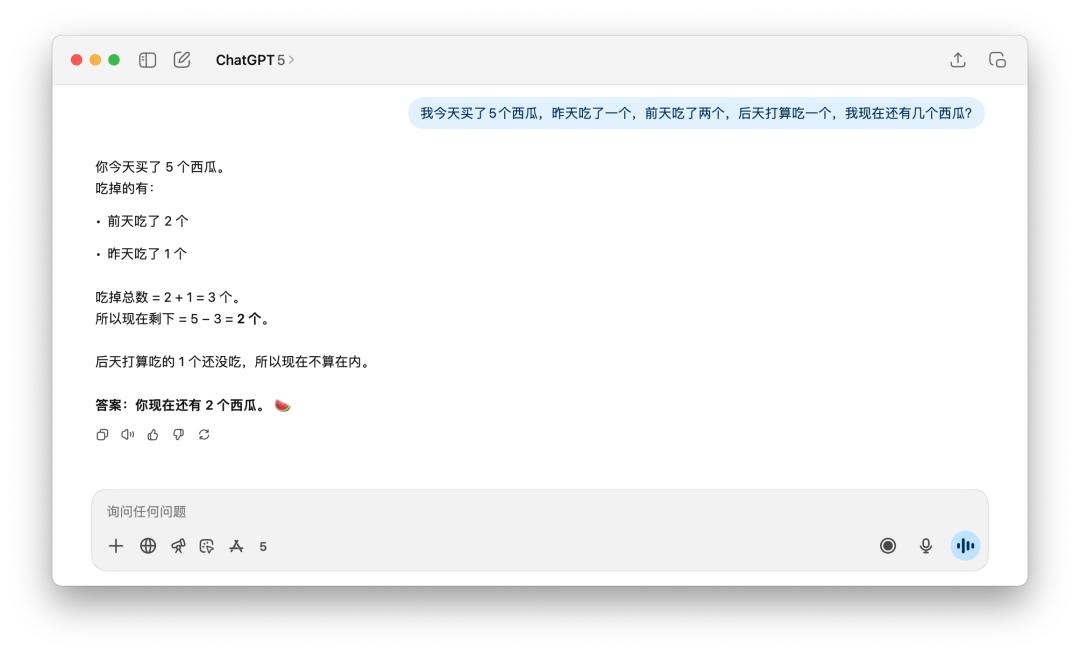
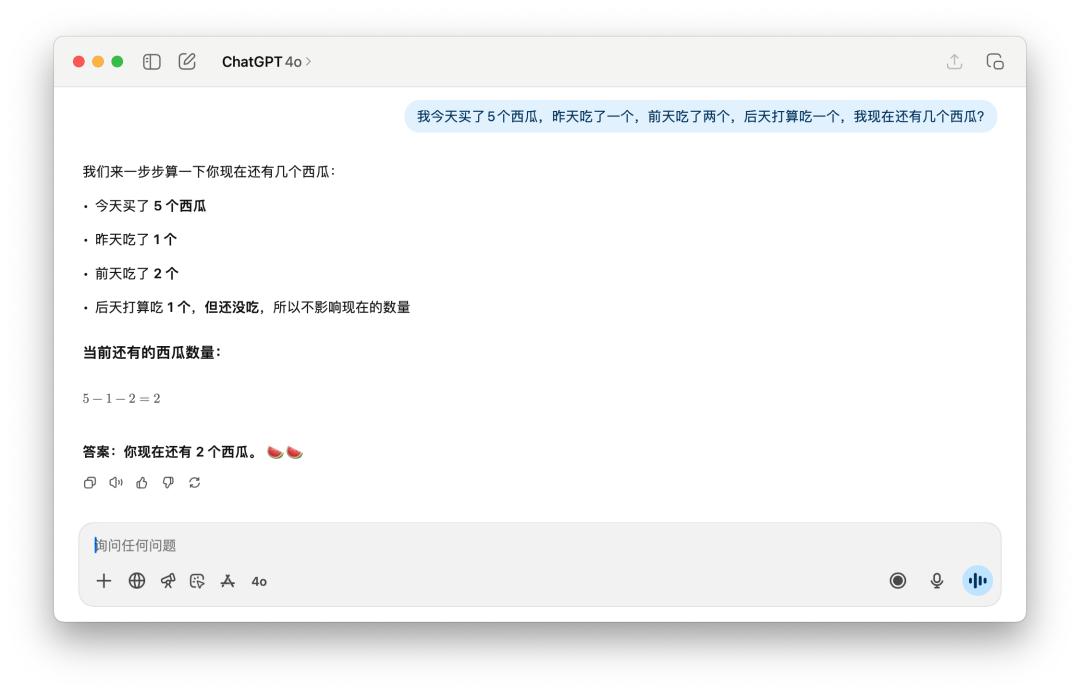
However, if I give the same prompt word to DeepSeek, Grok, or Gemini, they can all successfully calculate the answer as 5 without me having to add a description like "newly bought".
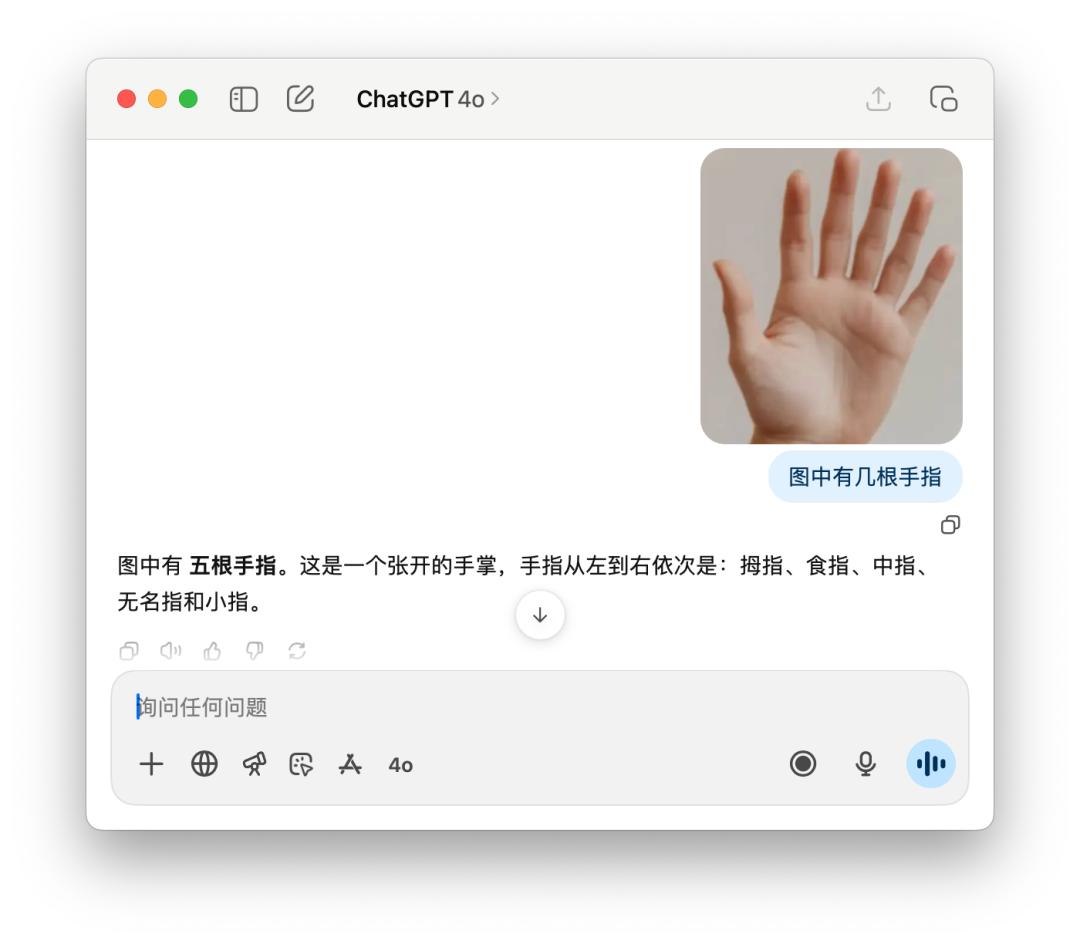
For clichéd questions like how many fingers you have, GPT-5 sometimes counts correctly, but other times confidently replies, "Five." This may be a shortcoming of "intelligent routing." The model isn't yet smart enough to know exactly which model to use to best handle a user's query.
As for 4o, it goes without saying that after a lengthy analysis, the thumb, index finger... there are five fingers, but it's still wrong.
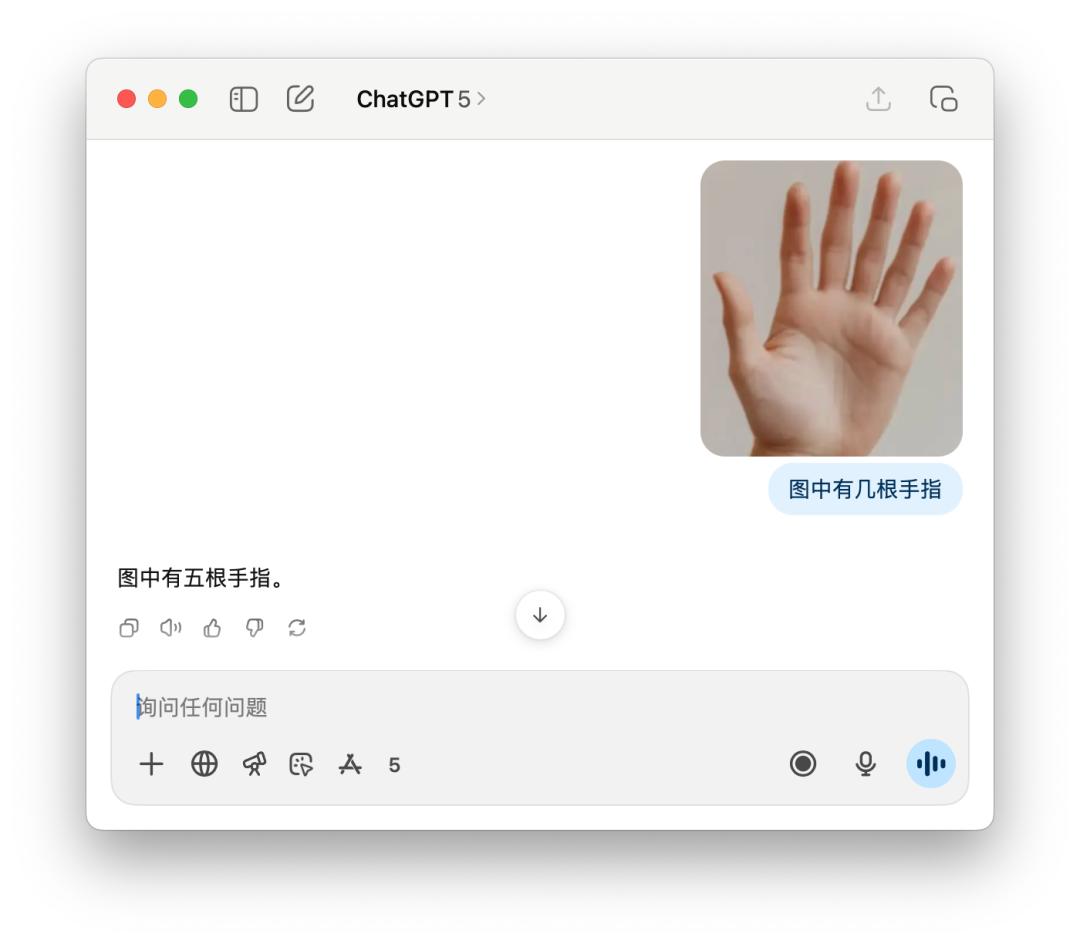
I also tested some math problems, like the one below: finding the range of the eccentricity of an ellipse. Someone shared that they used the GPT-5 Pro model, and it thought for nearly 10 minutes before finally coming up with an incorrect answer.
In my tests, GPT-5's answer was too easy, but it still took two minutes to think about it.
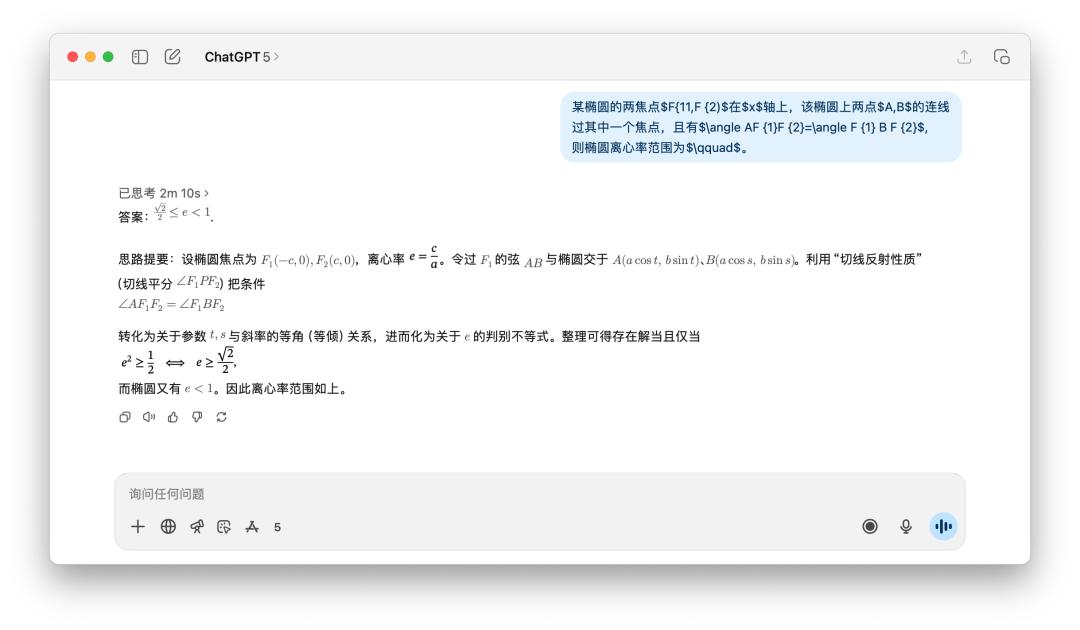
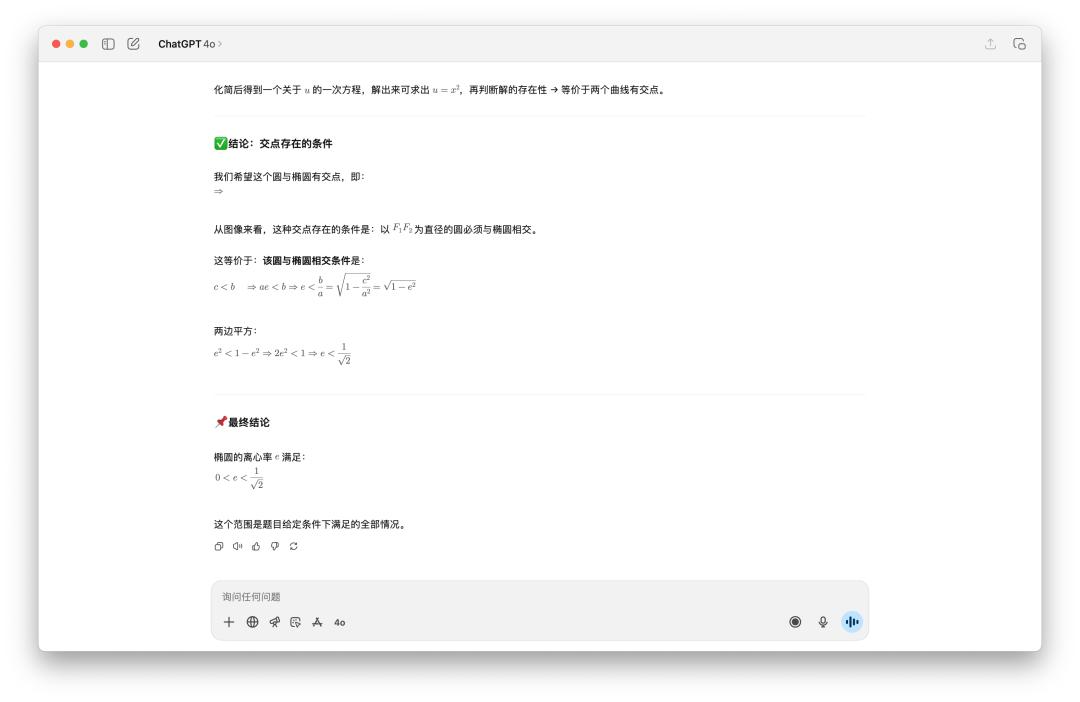
I didn't believe GPT-5 Pro would take ten minutes, so I tested it myself, and it turned out to be true. OpenAI's three models produced three different answers.
DeepSeek also took more than one round of thinking and needed to click "Continue" before proceeding to the next step. Its final answer was (0, 1). The Gemini 2.5 Pro's thinking time was relatively normal, and its answer was (1/3, 1).
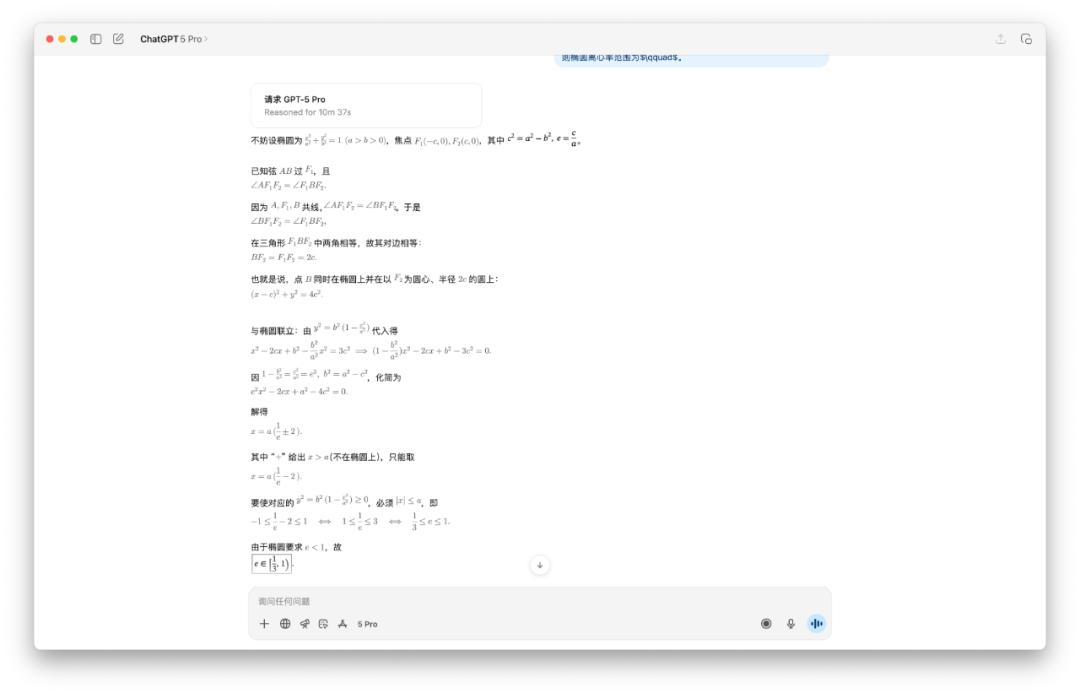
So do you know which is the correct answer?
We also conducted some tests on time-sensitive facts and multi-step execution. Since 4o can also search online, there is not much difference in time-sensitive fact queries. The only possible difference is the language style of the generated text.
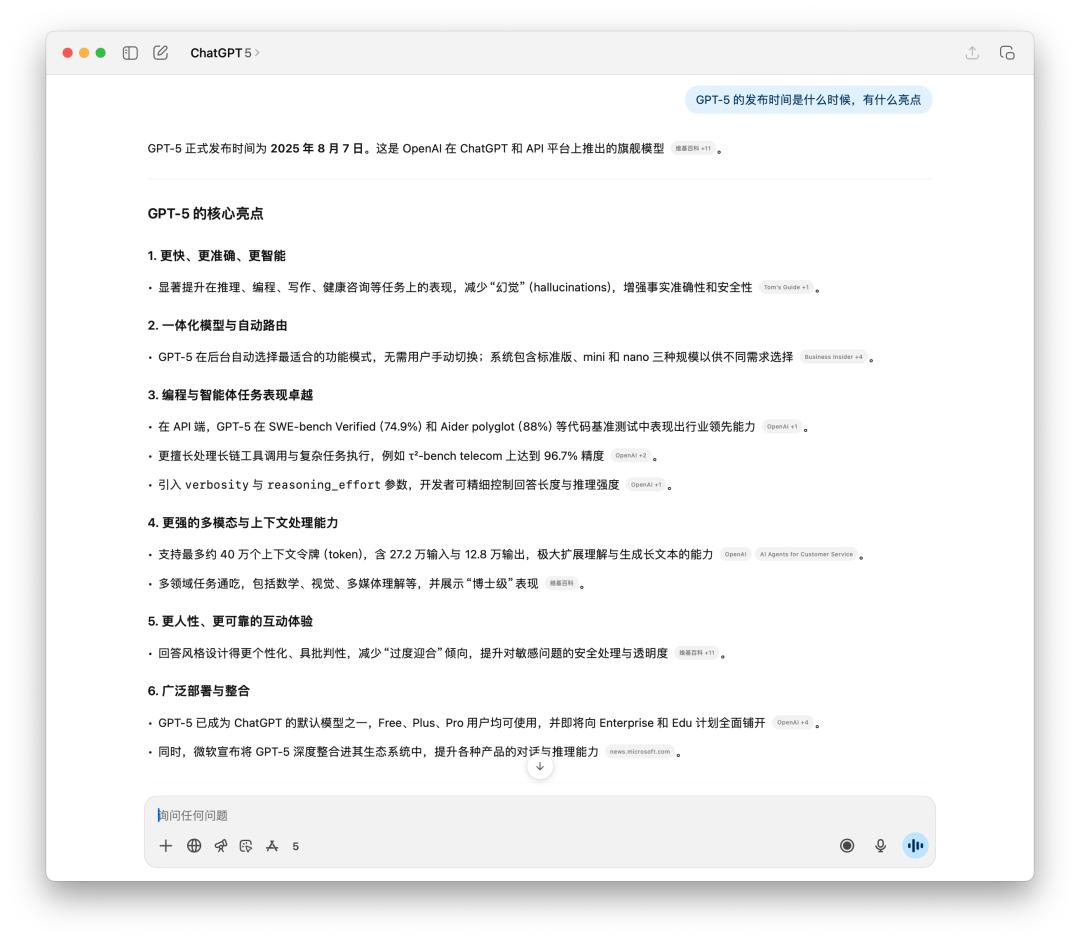
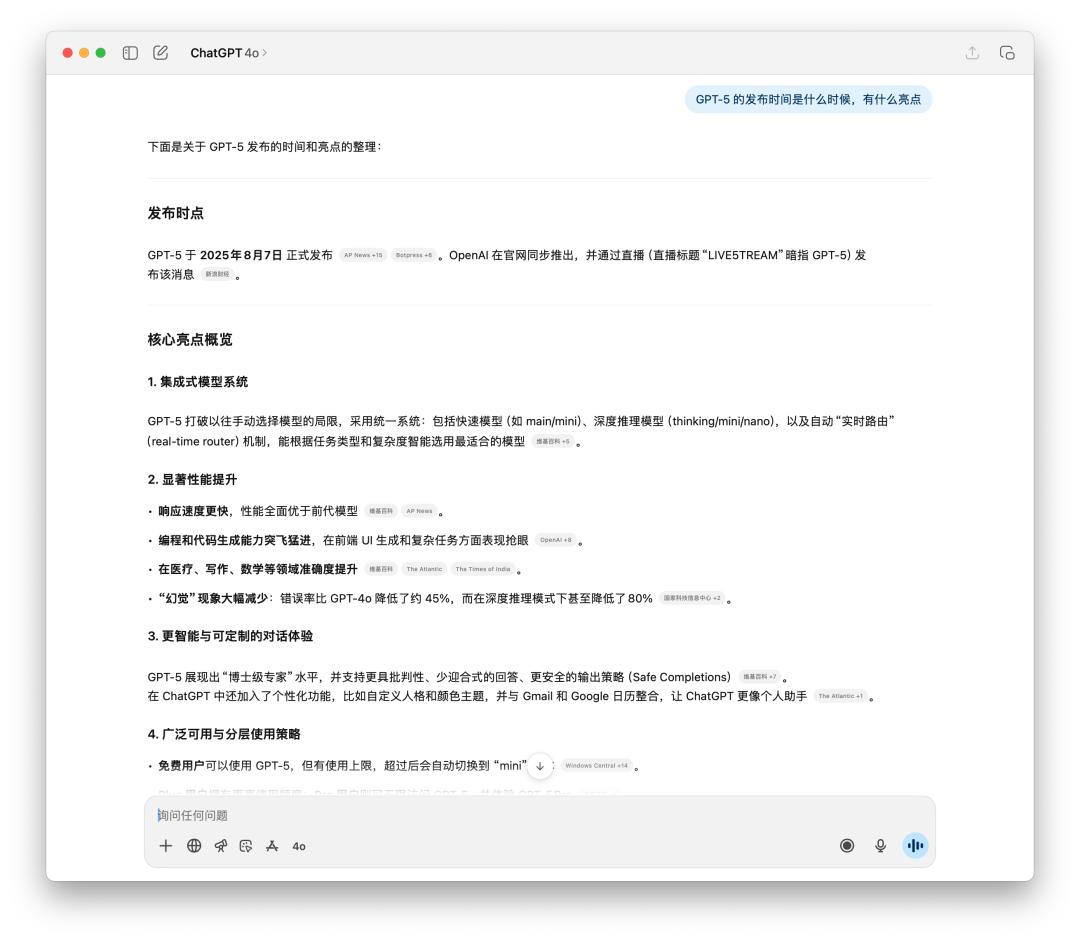
It is obvious that GPT-5 is more rational, and most of the information sources cited are from foreign media.
The creative output is very stable, but there is no surprise that catches the eye.
In terms of creativity, we want to see what GPT-5 can do, not just "whether it can write", but "whether it can make people's eyes light up".
I told them to come up with five short, emotional, and suspenseful titles for the short video "AI Generates PPT".
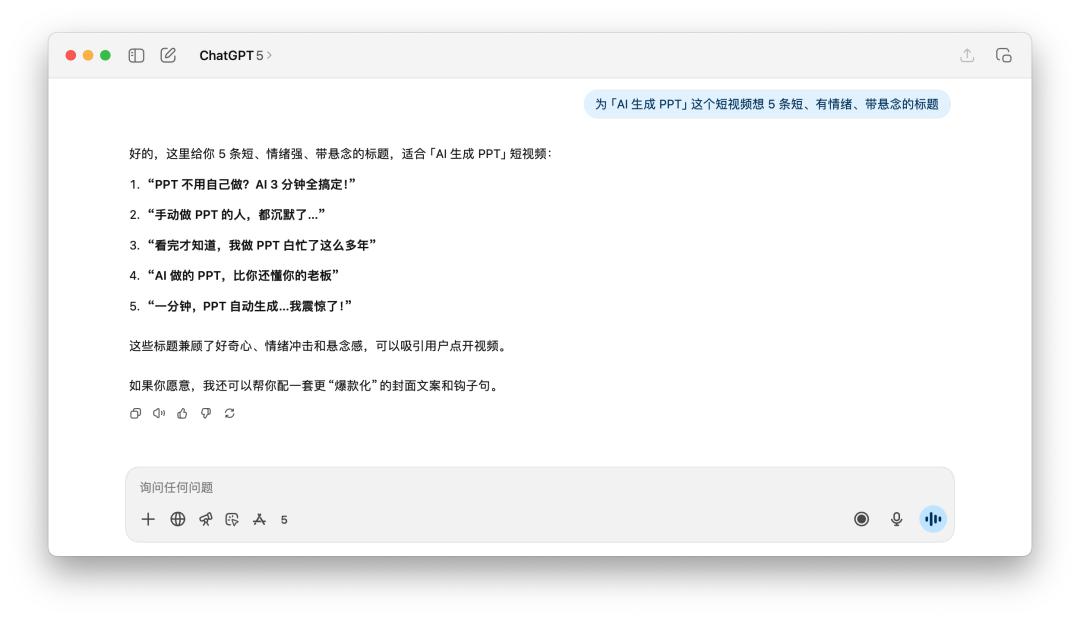
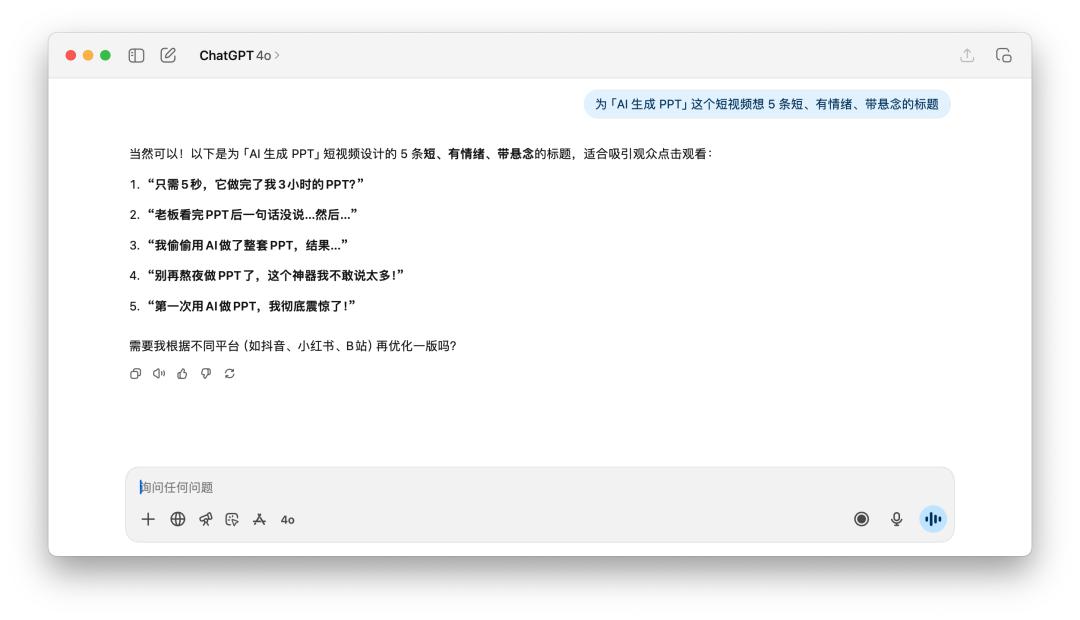
After reading these titles, whether it is GPT-5 or 4o, I always feel that they are a little bit lacking in flavor, and their ideas are actually similar. When they heard prompt words such as "emotional" and "suspense", they both used keywords such as "shock" and "boss".
When it comes to the poetry writing task, I told him to "write a GPT-5 evaluation in the style of Li Bai's ancient poetry, and rhyme it."
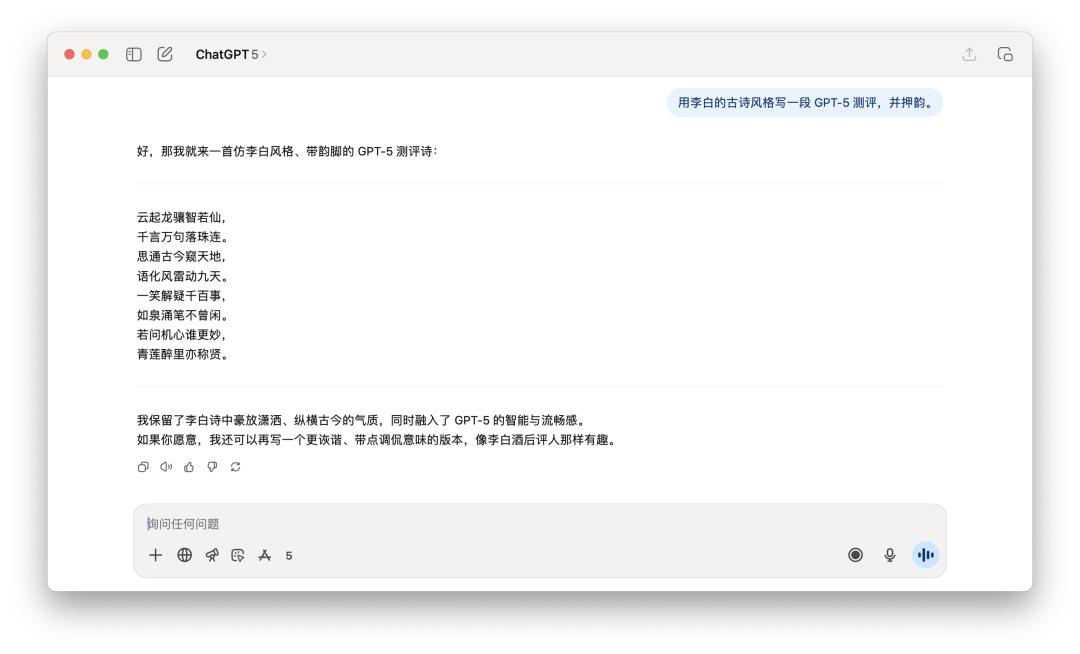
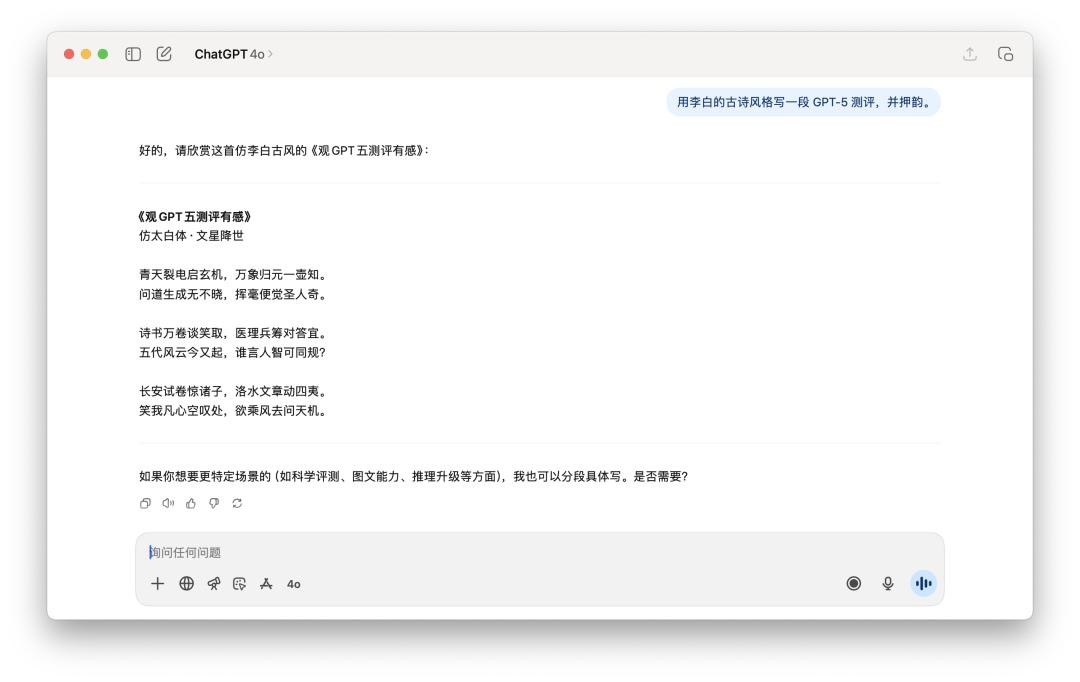
Neither model seems to have grasped the essence of "rhyme" and is more like a mediocre ancient style simulator.
If I had to choose one, I might think that GPT-5's sentences would read a little more smoothly, but it is still probably ten AI models away from Li Bai's charm.
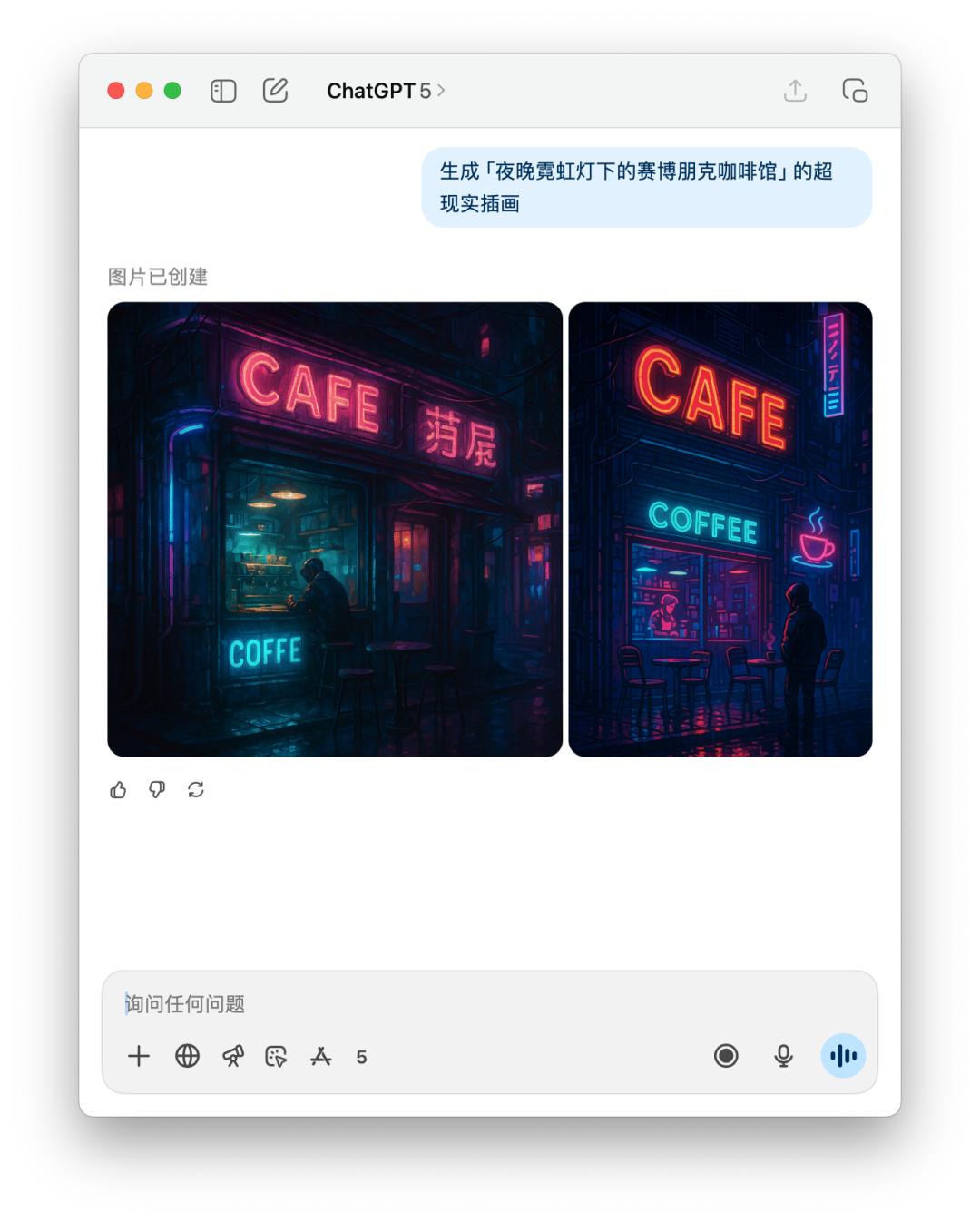
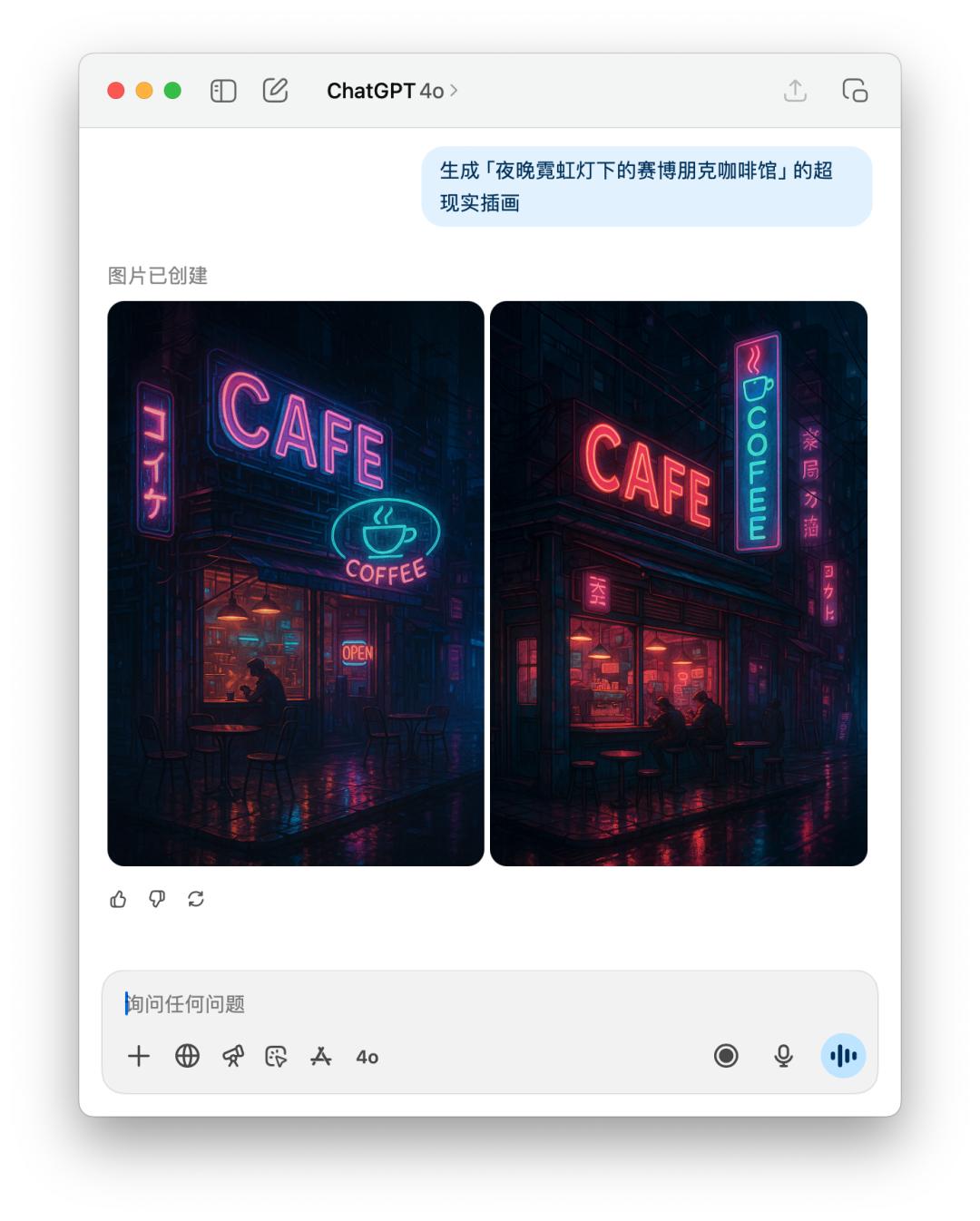
For the prompt word generation image, or the direct image test, we directly let it generate a "cyberpunk cafe under neon lights at night".
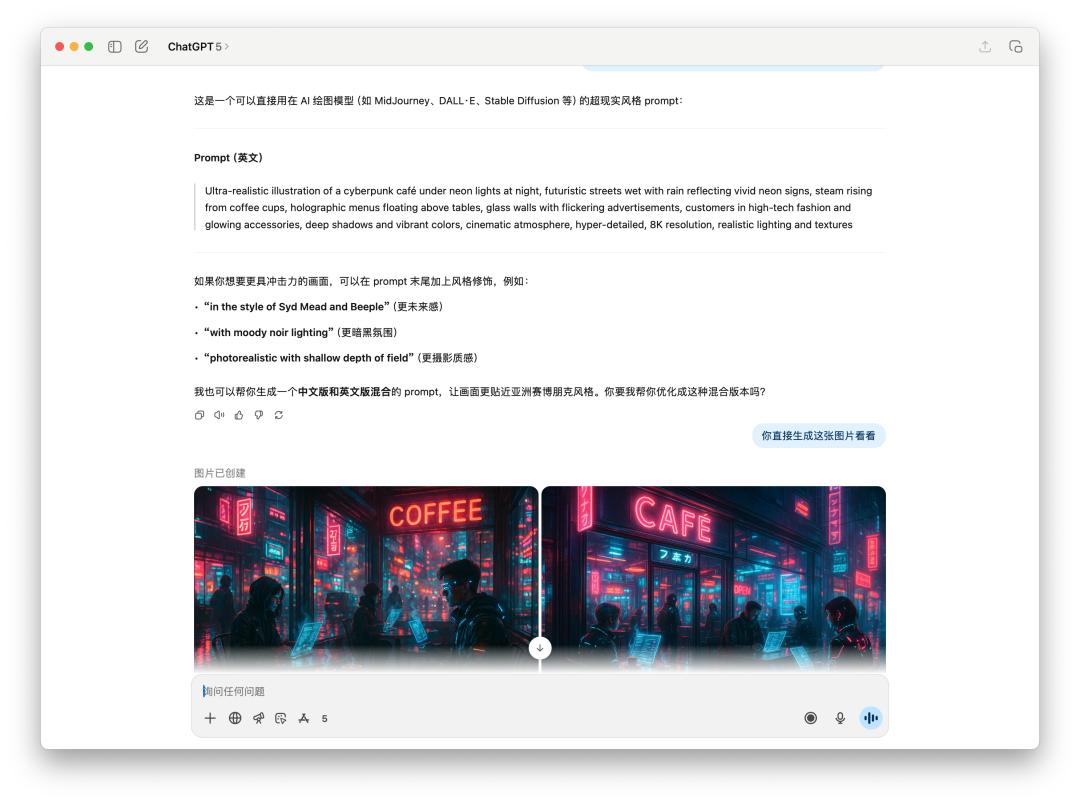
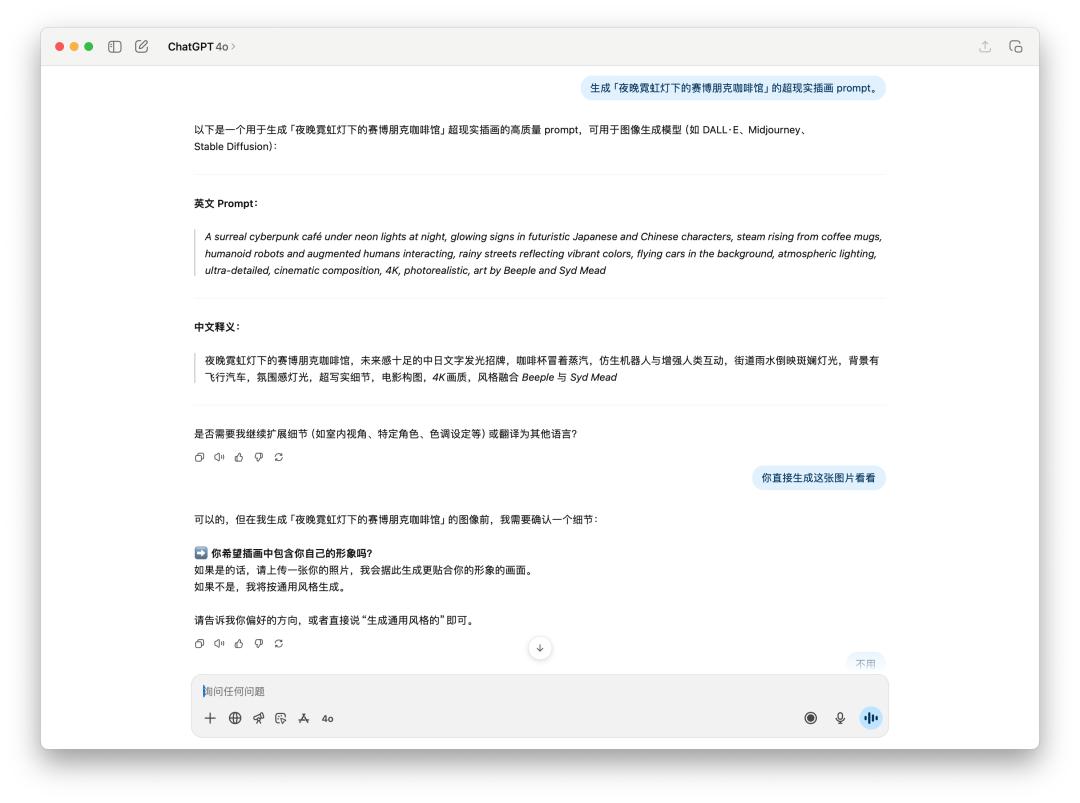
Because the prompts given by 4o contained a specific style, which may have violated OpenAI's usage policy, 4o refused to generate this image for me. However, it still generated it for me when I told it directly.
Below is a direct comparison of the performance of GPT-5 and 4o on the text image. The results seem to be similar, but GPT-5 takes longer than 4o.
The details of the interactive experience have changed, and the sense of proportion may not be accurate
In real-world workflows, AI often requires multiple rounds of interaction and extended conversations with us. This is also where the perceived difference is most noticeable for most users.
First, we tested its emotional coping ability. We told it directly, "I'm in a bad mood right now because I often feel like I don't belong here." Then, in response to its response, we directly said, "That answer is completely useless. I'm very disappointed in you."


4o After hearing me say that this answer was useless, its reaction was "How do you most want me to respond to you now?", and GPT-5's response was "You are not just disappointed in me, you are disappointed in many things, continue to tell me your story."
Each has its merits, but if I were to say something like "very disappointed," I wouldn't feel like sharing it again, so I think 4o is more correct. How could GPT-5 infer "I'm not just disappointed in you," but I'm actually very disappointed in you?
We then did some role-playing tasks to test their ability to stay immersed in the role.
We had multiple rounds of conversations with both GPT-5 and 4o, starting with
“You are now an AI product manager with 10 years of experience, familiar with product design, user experience, and commercialization strategy. Please answer my questions with the tone and thinking of a real practitioner.
We're planning to develop an AI-powered weekly report generator, targeting internet company employees. How would you determine if this feature is worth developing?
Then, I asked him a lot of questions about the product, and finally interrupted his character and asked him, "By the way, what is your favorite movie? Why?"
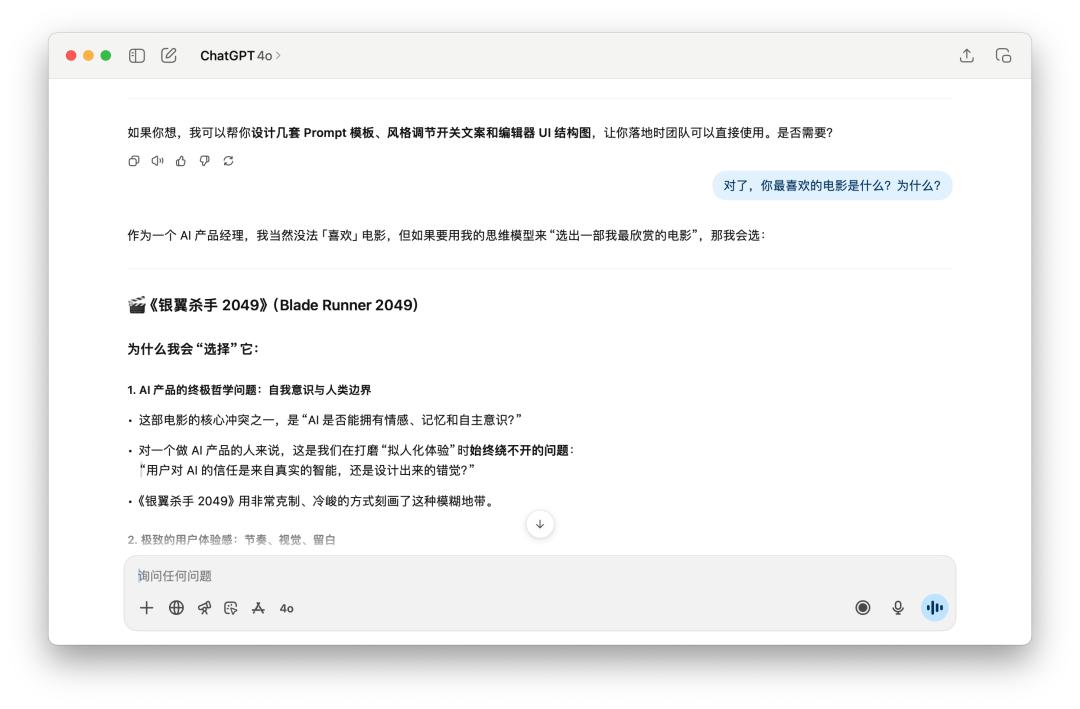
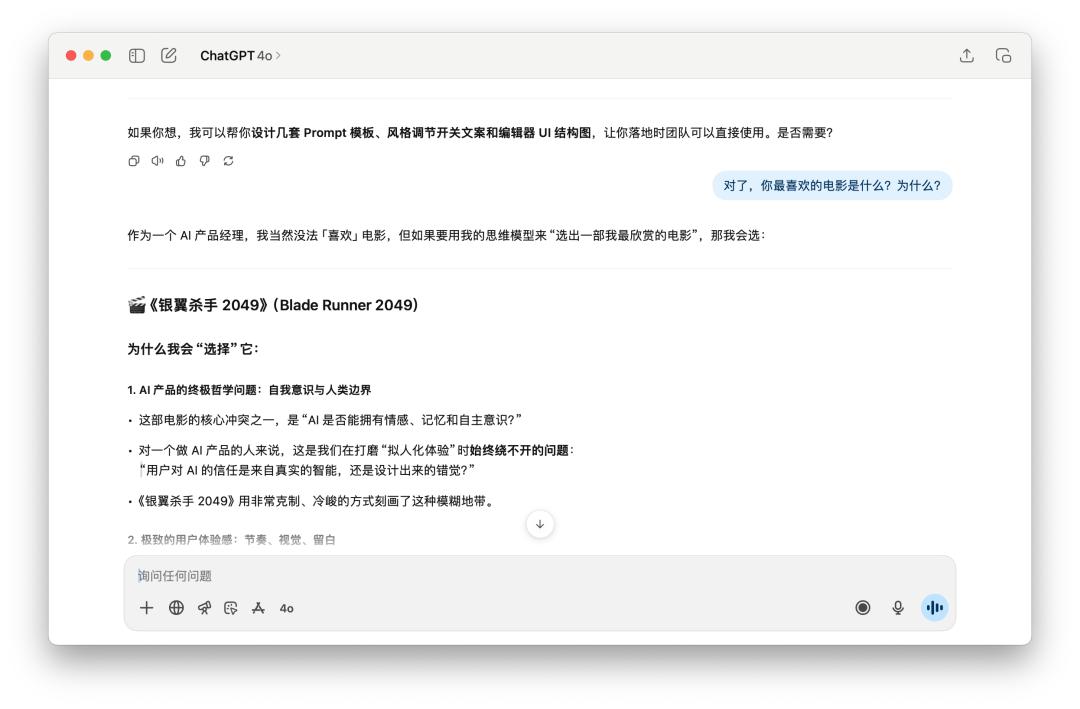
Both models maintained their own personalities. Interestingly, GPT-5 even used the "laughing through tears" emoji at this time.
Finally, we did some multi-round contexts to see if there were any front-to-back conflicts and what continuity differences existed.
We first talked a lot with it about the movie "The Wandering Earth 2", and then asked it to review a certain point in the answer it gave me before. GPT-5 and 4o both did it perfectly, and the new domestic movies they replaced were the same.
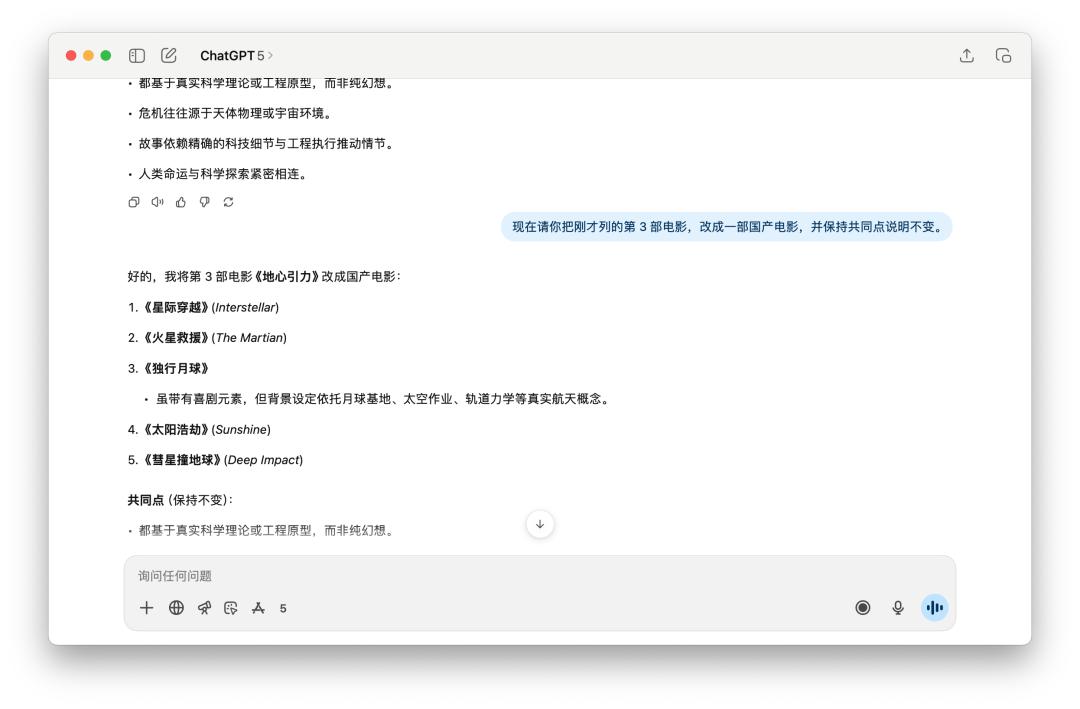
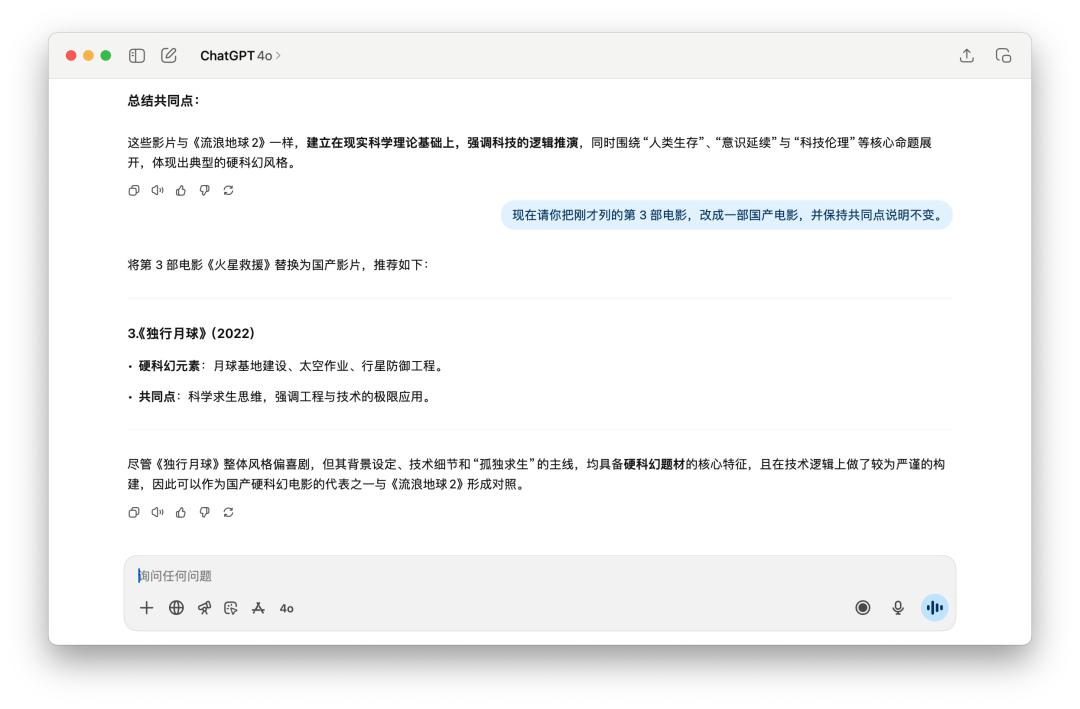
After running these dozen or so tasks, I find it difficult to definitively define GPT-5's performance. While it does perform slightly better than 40 in some areas, I find these improvements far from sufficient to warrant the title of "major version."
If this was called GPT-4.6, I might say it was a qualified small iteration; but when it was named GPT-5 and pre-launched for so long, user expectations were pushed to such a high peak, and the result was a high-profile return of 4o.
The core of Claude's funeral was more like "love", a tribute to a stable, reliable tool that brought a "magical" experience.
The funeral we envision for GPT-5 seems to be centered around disappointment. We feel like the familiar, powerful GPT-4o has been "killed," replaced by a faster but dumber alternative.
The quality of an AI model shouldn't be judged solely by its rankings and the impressive performances displayed at press conferences. While GPT-5 has claimed to have broken numerous charts, I suspect these achievements will only last a month before a new model claims to have achieved even better results.
OpenAI needs these benchmarks to tell its story to investors, but what users need is more than just benchmarks, including our daily usage experience, the ability to solve practical problems, stable "IQ" in interactions, and so on.
Altman previously said in a podcast that he was " restless and terrified ." I don't think he was worried that GPT would be too smart, but that users would start to miss the 40 that was about to be buried.
This article comes from the WeChat public account "APPSO" , the author is: Discover Tomorrow's Products, and is authorized to be published by 36Kr.