

This report, written by Tiger Research , explores the question posed by Nesa: What happens when you start to confront this issue directly? Most people use AI daily without considering where the data goes.
Key points
- AI has become integrated into daily life, but users often overlook how data is transmitted through a central server.
- Even the acting director of CISA in the United States unknowingly leaked confidential documents to ChatGPT.
- Nesa restructured this process through pre-transfer data transformation (EE) and cross-node splitting (HSS-EE), ensuring that no single party can view the original data.
- Academic accreditation (COLM 2025) and real-world enterprise deployment (Procter & Gamble) have given Nesa a first-mover advantage.
- Whether the wider market will choose decentralized privacy AI over the accustomed centralized API remains a key question.
1. Is your data secure?

Source: CISA
In January 2026, Madhu Gottumukkala, acting director of CISA, the U.S. cybersecurity leadership agency, uploaded sensitive government documents to ChatGPT simply to summarize and organize contract-related information.
This leak went undetected by ChatGPT and was not reported to the government by OpenAI. Instead, it was captured by the organization's own internal security system, triggering an investigation due to a violation of security protocols.
Even the top U.S. cybersecurity official uses AI on a daily basis, and even inadvertently uploaded classified materials.
We all know that most AI services store user input in encrypted form on a central server. But this encryption is reversible by design. Under legitimate authorization or in an emergency, the data can be decrypted and disclosed without the user's knowledge.
2. Privacy-preserving AI for everyday use: Nesa
AI has become a part of daily life—summarizing articles, writing code, drafting emails. What is truly worrying is that, as the aforementioned cases have shown, even confidential documents and personal data are being handed over to AI with almost no awareness of the risks involved.
The core problem is that all this data passes through the service provider's central server. Even if encryption is used, the decryption key is still held by the service provider. Why should users trust this arrangement?
User-input data may be exposed to third parties through various channels: model training, security audits, and legal requests. In the enterprise version, organizational administrators can access chat logs; in the personal version, data may also be transferred with legal authorization.

Now that AI is deeply embedded in daily life, it's time to seriously examine privacy issues.
Nesa is a project designed to fundamentally change this structure. It builds a decentralized infrastructure that enables AI inference without entrusting data to a central server. User input is processed in an encrypted state, and no single node can view the raw data.
3. How did Nesa solve the problem?
Imagine a hospital using Nesa. Doctors want AI to analyze a patient's MRI images to detect tumors. In existing AI services, the images would be sent directly to OpenAI or Google's servers.
When using Nesa, the images undergo mathematical transformation before leaving the doctor's computer.
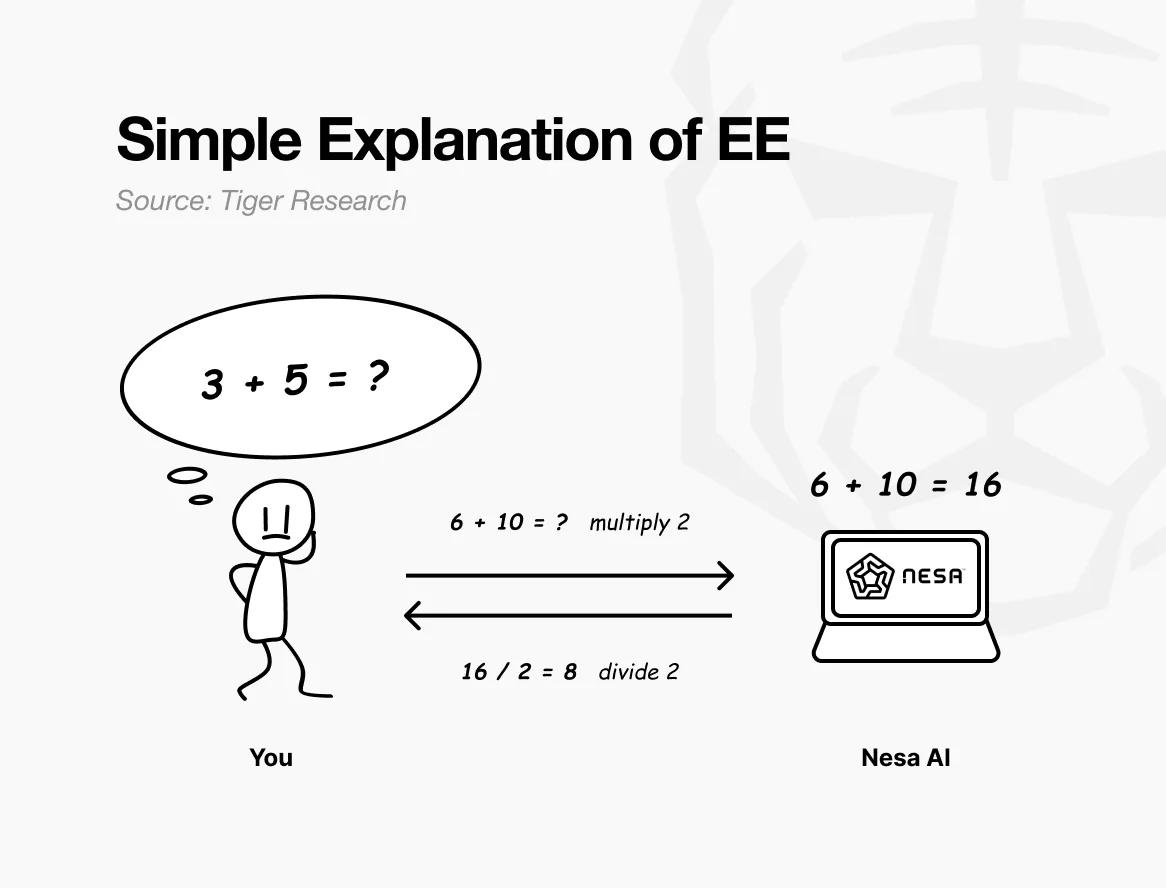
To put it simply: Suppose the original question is "3 + 5 = ?" If you send it directly, the receiver will know exactly what you are calculating.
However, if you multiply each number by 2 before sending, the receiver sees "6 + 10 = ?" and returns 16. Dividing by 2 again gives 8—exactly the same answer as directly calculating the original problem. The receiver has completed the calculation but remains unaware that your original numbers were 3 and 5.
This is precisely what Nesa's Equivalent Encryption (EE) achieves. Data undergoes mathematical transformation before transmission, and the AI model performs calculations on the transformed data.
When a user applies the reverse transformation, the result is exactly the same as using the original data. In mathematics, this property is called equivariance: whether the transformation is performed before or after the calculation, the final result is consistent.
In practice, the transformation is far more complex than simple multiplication—it is specifically tailored to the internal computational structure of the AI model. Because the transformation is perfectly aligned with the model's processing flow, accuracy remains unaffected.
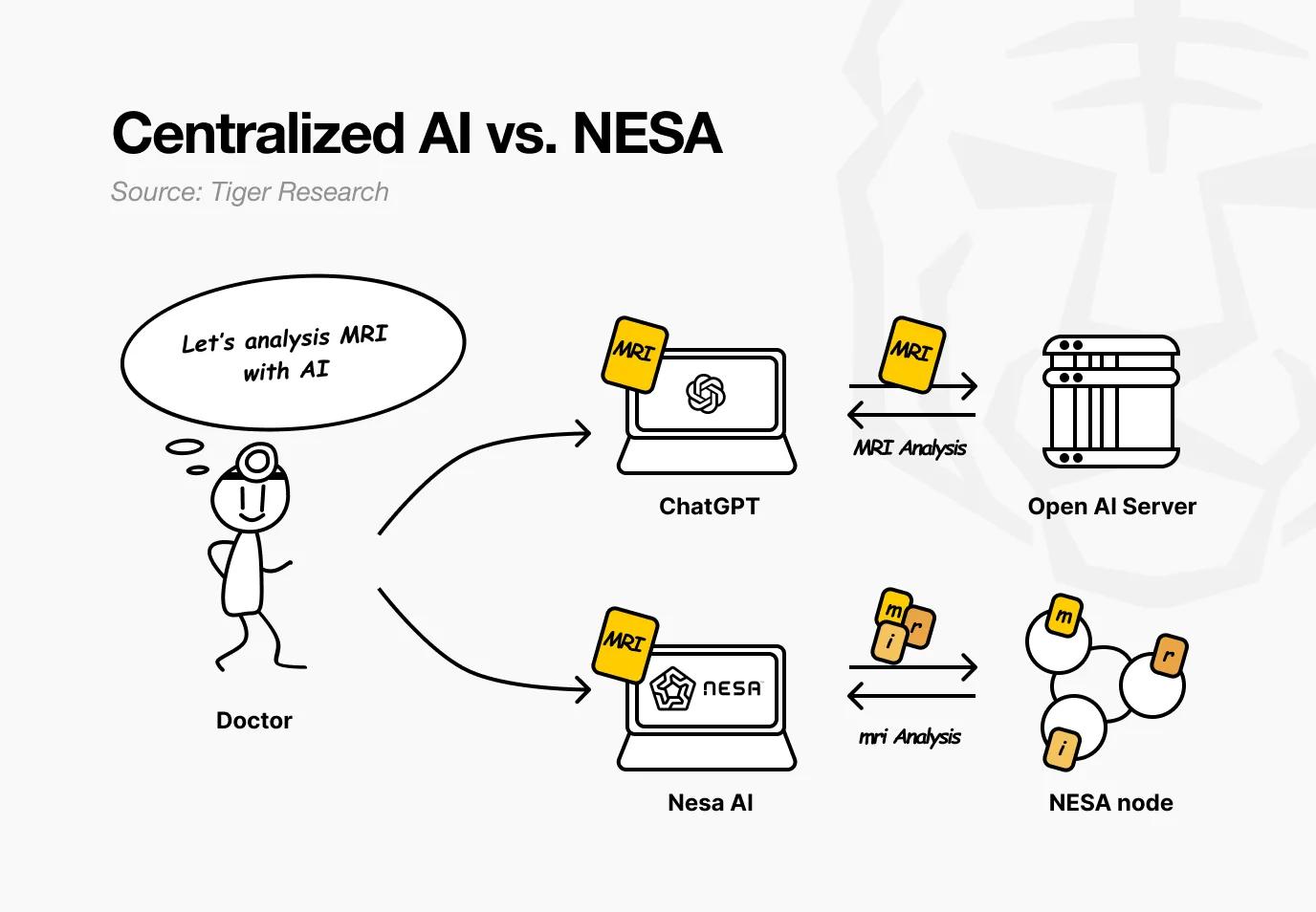
Returning to the hospital setting, for the doctor, the entire process remains unchanged—uploading images, receiving results, everything as usual. The only difference is that the patient's original MRI is no longer accessible at any point in the process.
Nesa goes a step further. EE alone can prevent nodes from viewing the raw data, but the transformed data still exists intact on a single server.
HSS-EE (Homomorphic Secret Sharing over Cryptographic Embedding) further segments the transformed data.
Continuing the previous analogy, EE is like applying a multiplication rule before sending the exam paper; HSS-EE, on the other hand, tears the transformed exam paper in half—the first part is sent to node A, and the second part is sent to node B.
Each node can only solve its own fragment and cannot see the complete question. The complete result can only be obtained when the two partial answers are merged—and only the original sender can perform this merging operation.
In short: EE transforms the data, making the original content invisible; HSS-EE further segments the transformed data, ensuring it never appears in its entirety anywhere. Privacy protection is thus doubled.
4. Will privacy protection slow down performance?
Stronger privacy often means slower performance—a long-standing ironclad rule in cryptography. The most well-known fully homomorphic encryption (FHE) is 10,000 to 1,000,000 times slower than standard computation, making it utterly unsuitable for real-time AI services.
Nesa's Equivalent Encryption (EE) employs a different path. Returning to the mathematical analogy: the cost of multiplying by 2 before sending and dividing by 2 after receiving is negligible.
Unlike FHE, which transforms the entire problem into a completely different mathematical system, EE simply adds a lightweight transformation layer to the existing computation.
Performance benchmark data:
- EE : On LLaMA-8B, latency increased by less than 9%, accuracy matched the original model, exceeding 99.99%.
- HSS-EE : 700 to 850 milliseconds per inference attempt on LLaMA-2 7B.
Furthermore, the MetaInf meta-learning scheduler further optimizes overall network efficiency. It evaluates model size, GPU specifications, and input features, automatically selecting the fastest inference method.
MetaInf achieves a selection accuracy of 89.8% and is 1.55 times faster than traditional ML selectors. This work has been presented at the COLM 2025 main conference and has gained recognition from the academic community.
The above data comes from a controlled testing environment. More importantly, Nesa's inference infrastructure has been deployed and is running in a real enterprise environment, validating its production-grade performance.
5. Who is using it? How is it used?
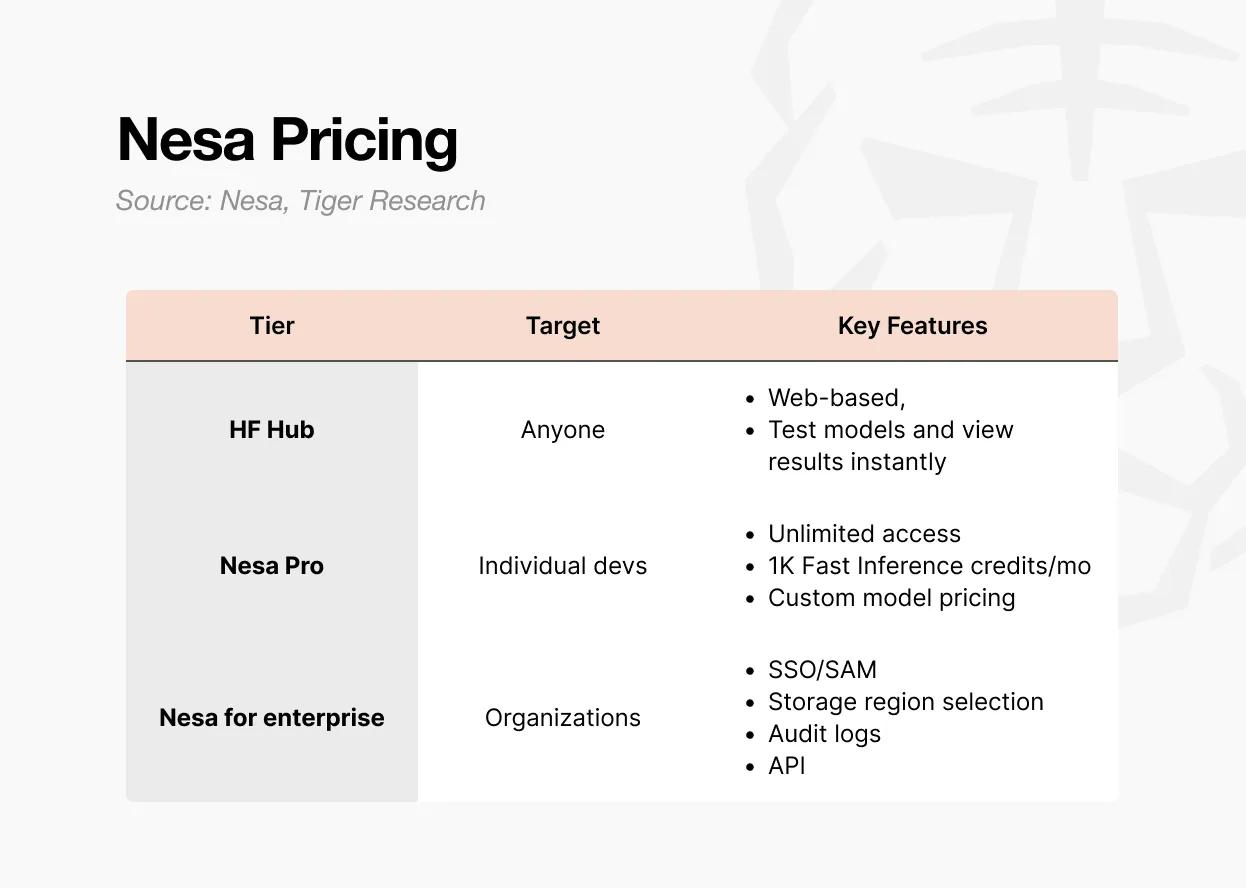
There are three ways to access Nesa.
The first option is Playground . Users can directly select and test models on a webpage without any development background. You can experience the complete process of inputting data and viewing the output results of each model.
This is the fastest way to understand how decentralized AI inference actually works.
The second option is the Pro subscription . It costs $8 per month and includes unlimited access, 1,000 quick inference points per month, customizable model pricing controls, and a featured model page.
This tier is designed for individual developers or small teams who want to deploy and monetize their own models.
The third option is the Enterprise Edition . This is not a publicly priced plan, but a customized contract. It includes SSO/SAML support, optional data storage areas, audit logs, fine-grained access control, and annual contract billing.
The starting price is $20 per user per month, but actual terms are subject to negotiation based on scale. It is designed for organizations integrating Nesa into their internal AI processes, providing API access and organization-level management capabilities through a separate protocol.
In summary: Playground is for exploration and experience, Pro is suitable for individual or small team development, and Enterprise is for organizational-level deployment.
6. Why are tokens needed?
Decentralized networks have no central administrator. Entities running servers and verifying results are located globally. This naturally raises the question: why would anyone be willing to keep their GPUs running continuously to process AI inference for others?
The answer is economic incentives. In the Nesa network, this incentive is the $NES token.
Source: Nesa
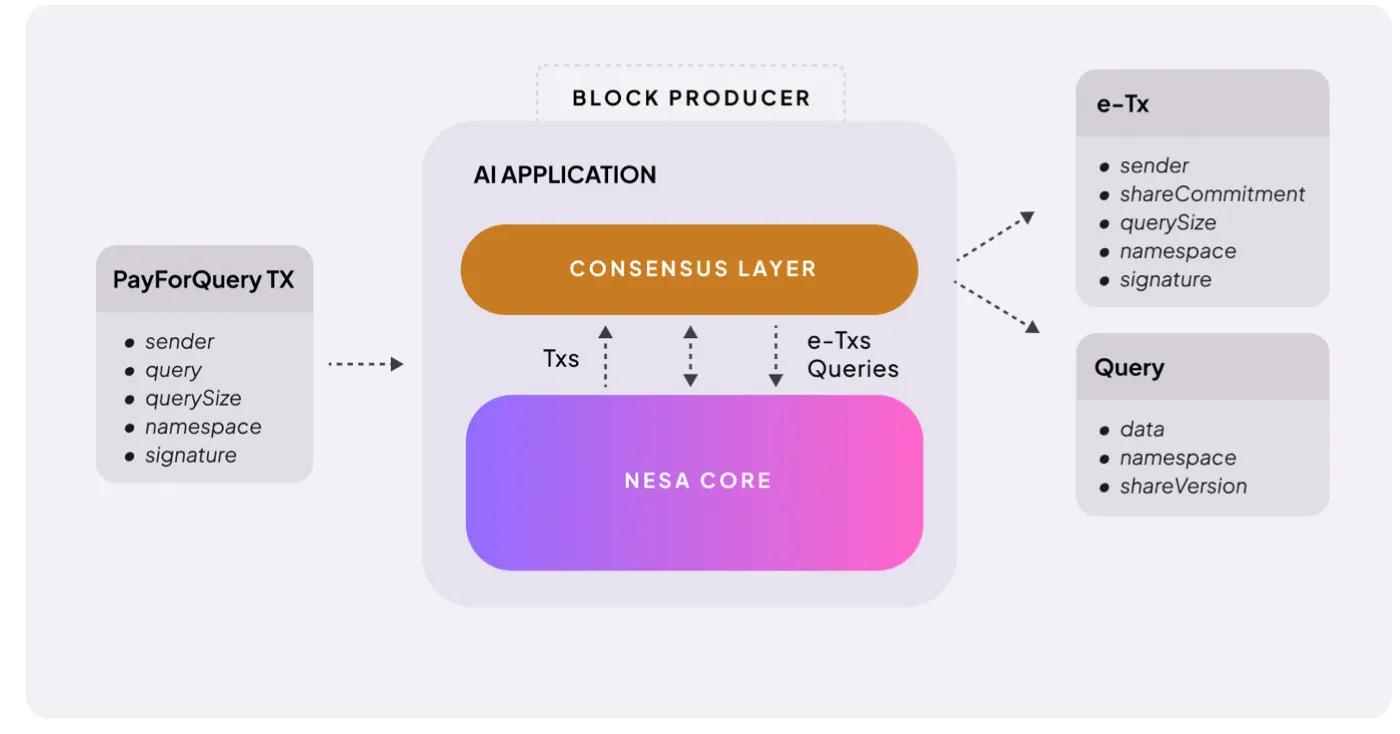
The mechanism is very straightforward. When a user initiates an AI inference request, a fee is charged. Nesa calls it PayForQuery , which consists of a fixed fee per transaction plus a variable fee proportional to the amount of data.
The higher the fee, the higher the processing priority—this is the same principle as gas fees on the blockchain.
The recipients of these fees are the miners. To participate in the network, miners must stake a certain amount of $NES—putting their tokens at risk before being assigned tasks.
If a miner returns an incorrect result or is unable to respond, a penalty will be deducted from their stake; if the processing is accurate and prompt, they will receive a higher reward.
$NES also serves as a governance tool. Token holders can submit proposals and vote on core network parameters such as fee structure and reward ratios.
In summary, $NES serves a triple purpose: a means of payment for inference requests, collateral and rewards for miners, and a token of participation in network governance. Without the token, nodes cannot function; without nodes, privacy-preserving AI is impossible.
It is worth noting that the operation of a token economy depends on certain preconditions.
For reasoning demand to be sufficient, miner rewards are meaningful; for rewards to be meaningful, miners will remain; and for the number of miners to be sufficient, network quality can be maintained.
This is a virtuous cycle where demand drives supply and supply sustains demand—but starting this cycle is precisely the most difficult stage.
The fact that enterprise clients like Procter & Gamble are already using the network in production environments is a positive sign. However, whether the balance between token value and mining rewards can be maintained as the network scales remains to be seen.
7. The Necessity of Privacy-Focusing AI
Nesa is trying to address a clear problem: changing the structural dilemma of users exposing their data to third parties when using AI.
The technology is based on solid and reliable principles. Its core encryption technologies— Equivalent Equivalence (EE) and HSS-EE— originate from academic research. The inference optimization scheduler MetaInf has been presented at the COLM 2025 main conference.
This is not as simple as simply citing a paper. The research team designed the protocol themselves and implemented it in the network.
In decentralized AI projects, only a handful are capable of academically validating their proprietary cryptographic primitives and deploying them on real-world infrastructure. Large companies like Procter & Gamble are already running inference tasks on this infrastructure—a significant sign for early-stage projects.
That being said, the limitations are also clearly visible:
- Market Scope : Institutional clients are preferred; ordinary users are unlikely to pay for privacy at this time.
- Product Experience : Playground feels more like a Web3/investment tool interface than a typical AI application.
- Scaled validation : Controlled benchmark testing ≠ production environment with thousands of concurrent nodes
- Market Timing : The demand for privacy-preserving AI is real, but the need for decentralized privacy-preserving AI has not yet been validated; enterprises are still accustomed to centralized APIs.
Most enterprises are still accustomed to using centralized APIs, and the threshold for adopting blockchain-based infrastructure remains high.
We live in an era where even the head of U.S. cybersecurity uploads classified documents to AI. The need for privacy-preserving AI already exists and will only continue to grow.
Nesa possesses academically proven technology and operational infrastructure to meet this need. Despite its limitations, it has a head start over other projects.
When the privacy AI market truly opens up, Nesa will undoubtedly be one of the first names mentioned.






