In the 2013 science fiction film Her, the operating system Samantha gave the audience a first concrete vision of the ideal AI: it can speak before you finish speaking, can sense hesitation in your tone, and is always "present" rather than passively waiting to be awakened.
Thirteen years later, Thinking Machines Lab, founded by Mira Murati, the former CTO of OpenAI, released a research preview. The interactive model it built was highly consistent with Samantha's logic in its underlying pursuit.

This blog post, titled "Interaction Model: A Scalable Solution for Human-Computer Collaboration," repeatedly emphasizes one word throughout: "presence."

Blog link: https://thinkingmachines.ai/blog/interaction-models/
Interestingly, in 2024, Mira Murati hosted the release of GPT-4o's advanced speech mode at OpenAI, making human-computer interaction closer to natural human-to-human communication.

Two years later, she started anew with her departed team, but ended up doing the same thing all over again.

The comments section was filled with increasingly sharp criticisms.


Humans have been removed from AI collaborative group chats.
The article begins by pointing out that, based on METR's research report in 2025, mainstream AI companies generally tend to regard "models autonomously completing long tasks" as the most important capability indicator, resulting in current interactive interfaces leaving almost no room for continuous human participation.
However, in practice, requirements are rarely perfectly defined from the outset. High-quality output often requires continuous human intervention and repeated adjustments, which is precisely what the existing "turn-based" mechanism lacks.
Linguists Clark and Brennan's 1991 research showed that effective communication relies on co-existence, simultaneity, and concurrency. Both parties need to be in the same context, receiving and expressing information synchronously; furthermore, as Walter Ong's 1982 research on the "fleeting nature of spoken language" demonstrates, the essence of dialogue lies in high-frequency participation. Combined with Hayek's 1945 theory, truly valuable knowledge resides in this kind of immediate, detailed transmission.
Current models operate by having the user input while the AI waits; when the AI outputs, it is completely unaware of the user's immediate reaction. Thinking Machines likens this to: facing urgent disagreements without face-to-face communication, instead relying on back-and-forth email exchanges.
The current real-time speech market has two limited approaches: most mainstream commercial systems rely on "pseudo-real-time" by splicing together components such as voice activity detection (VAD) outside the model.
The limitations of this plug-in component management method are obvious: the model cannot actively interrupt the conversation, cannot react in real time to visual changes such as screen errors, and is even less capable of handling high-frequency concurrent tasks such as "simultaneous interpretation while listening". On the other hand, although native full-duplex systems that do not require VAD, such as Moshi and PersonaPlex, have emerged in the market, they are mostly smaller-scale models that have compromised on the overall intelligence level in order to achieve low latency.
Thinking Machines agrees with reinforcement learning scholar Richard Sutton's view that systems relying on manually designed components will eventually be overtaken by general learning. Interactive capabilities must be an integral part of the model.
To this end, they referenced industry research on full-duplex voice interaction and asynchronous agents (such as Seeduplex, Qwen-omni, MoshiRAG, etc.) and trained a system natively supporting real-time interaction from scratch. This system consists of a time-aware "interaction model" (foreground) and an asynchronously running "background model" (responsible for deep inference) working together.

Time-aligned micro-round analysis/micro-round mechanism: The model processes input and output alternately in 200-millisecond units. User silence and interruptions are retained as real information.

By breaking down the boundaries of human-defined turn sequences, the model can implicitly track whether a user is thinking, yielding, self-correcting, or inviting a response, without requiring a separate dialogue management module. It can not only speak synchronously and interrupt mid-conversation, but also simultaneously access tools, search the web, or generate UI interfaces while listening and watching.
In terms of modal processing, they eliminated the need for a separate, large encoder; the audio and video were lightly processed and directly trained together with the Transformer main body. Meanwhile, to meet the requirements of high-frequency processing, the team implemented a "streaming session" mechanism and optimized the underlying computing power and communication, avoiding repeated memory reallocation and ensuring stable operation with low latency.

When faced with complex tasks, the front-end sends the complete context to the back-end, which then streams the results back. The front-end then seamlessly integrates into the dialogue, ensuring real-time responsiveness while also supporting deep reasoning. To address newly emerging security challenges, the model has also undergone realistic training simulating dialogue rejection and robustness testing against jailbreaks.
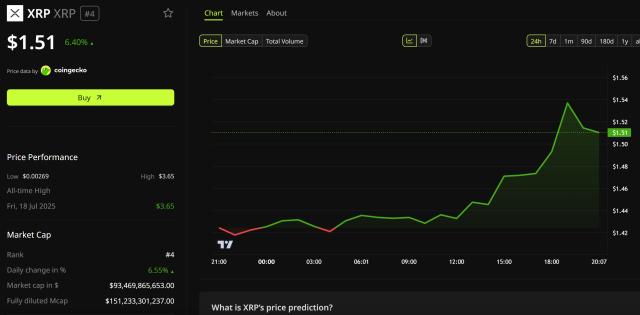
A report card that has attracted the collective attention of mainstream models
In the test, the model named TML-Interaction-Small (active parameter 12B) performed exceptionally well.
In the FD-bench v1.5 benchmark, which evaluates interruptions and background noise interference, TML scored 77.8 points, far exceeding GPT Realtime-2.0 (46.8 points) and Gemini (54.3 points), with a round-switching latency of only 0.40 seconds. In FD-bench v3, which requires deep inference, its response quality/Pass@1 (82.8/68.0) also consistently outperformed the high-latency versions of competing products.
In other comprehensive tests, TML also demonstrated excellent balance: QIVD audio/video question answering (54.0 points), BigBench Audio (75.7/96.5 points), and IFEval instruction compliance (82.1/89.7 points), while maintaining a 99.0% safe rejection rate in Harmbench. Although it slightly lagged behind the Qwen 3.5 Omni or GPT-2.0 ultra-high latency version in some purely intelligence-based tests, it was the only model that achieved excellence in both response speed and intelligence level.

To more accurately measure native interaction capabilities, Thinking Machines has built several benchmarks.
Compared to existing text output prototypes in academia such as StreamBridge and AURA, TML achieves true concurrent speech output. In individual tests, including TimeSpeak (64.7 points for active speaking), CueSpeak (81.7 points for simultaneous error correction), RepCount-A (35.4 points for continuous visual tracking), and ProactiveVideoQA (for answering questions by watching videos), TML achieved good results in all of them, while the mainstream models being compared almost all scored zero or remained silent in these scenarios.

Of course, this architecture also has limitations: the accumulation of context in long sessions is difficult to manage, and streaming audio and video are highly dependent on network stability. Furthermore, the architecture has not yet been scaled up to a version with a larger number of parameters and is planned for release later this year.
Talking to AI is becoming more and more like talking to a person.
Neal Wu, a researcher involved in this work, summarized their initial idea: "What if collaborating with AI was no longer about typing into a chat box, but more like talking to another person?" The model that natively supports interaction is their initial attempt.
Thinking Machines CTO Soumith Chintala divides the overall roadmap into three steps: First, increase the information bandwidth between humans and AI; second, raise the upper limit of human-AI intelligence; and third, help humans continue to play a core role in future systems.

While many AI research directions tend to make models more autonomous and reduce human intervention, Thinking Machines has chosen a different path: making human intervention smoother and making communication bandwidth itself an infrastructure.
In her tweet, Weng Li further stated, "I wrote 137 pages of logs and produced 12 versions. The results showed that collaboration between people is crucial for improving collaboration between humans and AI." This may mean that to develop a model that can understand the rhythm of human communication, researchers first need to deeply understand the essence of human communication.

However, the psychological experience evoked by an AI that is constantly present and can instantly perceive emotions and states is vastly different from that of traditional tool-based AI. How will people's perception and reliance on an AI change as its presence in each interaction strengthens?
The paper did not answer these soul-searching questions, but only left an open direction regarding "real-time alignment and security." However, it is foreseeable that when the plots in science fiction movies truly come to life on the desktop, and AI becomes a constant "presence" in our lives, what we really need to align may not just be the models, but also humanity's own place in the new world.
This article is from the WeChat official account "APPSO" , authored by APPSO who discovers tomorrow's products, and published with authorization from 36Kr.