Original: Ye Zhang
Compile: FF
The speech is divided into four parts. In the first part, Zhang Ye introduced the development background and why we need zkEVM in the first place and why it has become so popular in the past two years. The second part explains how to build zkEVM from scratch including arithmetic through a complete process. and the proof system, the third part talks about the problems that Scroll encountered when building zkEVM through some interesting research questions, and finally introduces some other applications using zkEVM.


background and motivation

In the traditional Layer 1 blockchain, some nodes will be jointly maintained through the P2P network. When they receive the user's transaction, they will be executed in the virtual machine of the EVM, read the calling contract and storage, and update the global state tree according to the transaction.
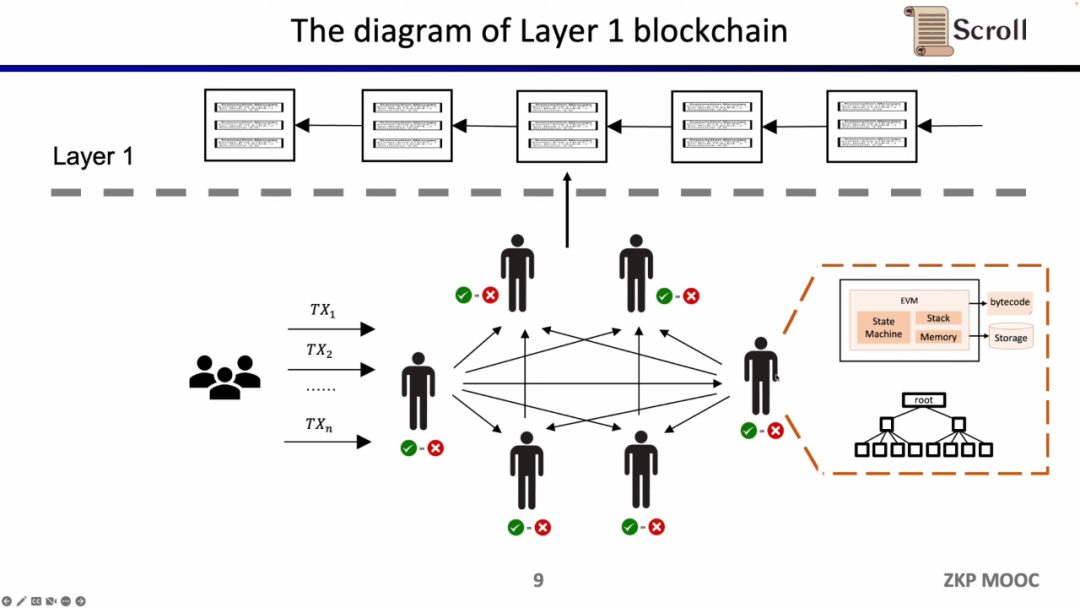
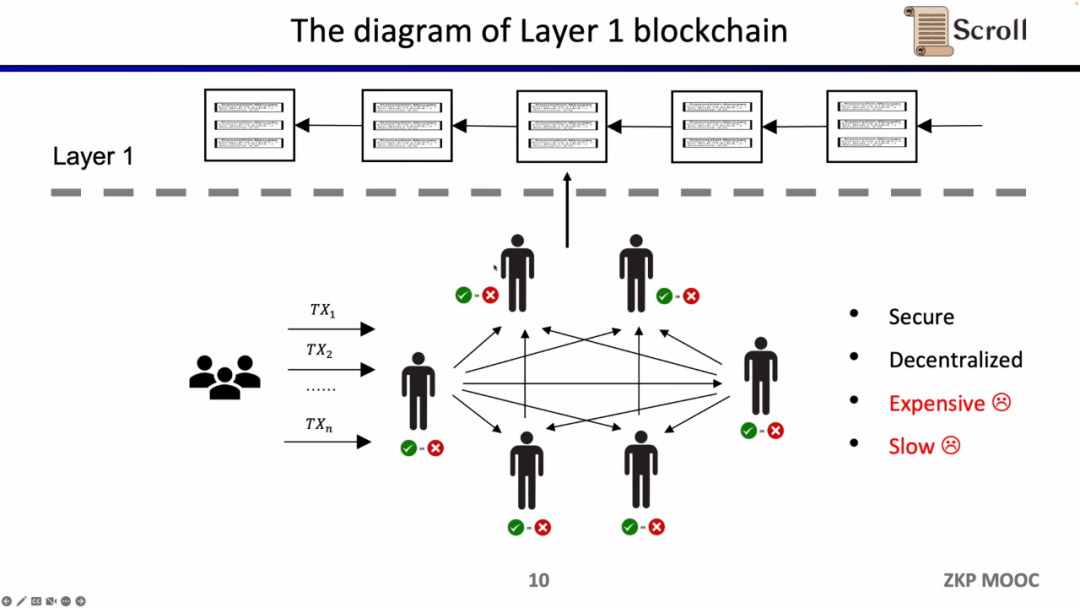
The advantage of such an architecture lies in decentralization and security. The disadvantage is that the transaction fee on L1 is expensive and the transaction confirmation is slow.
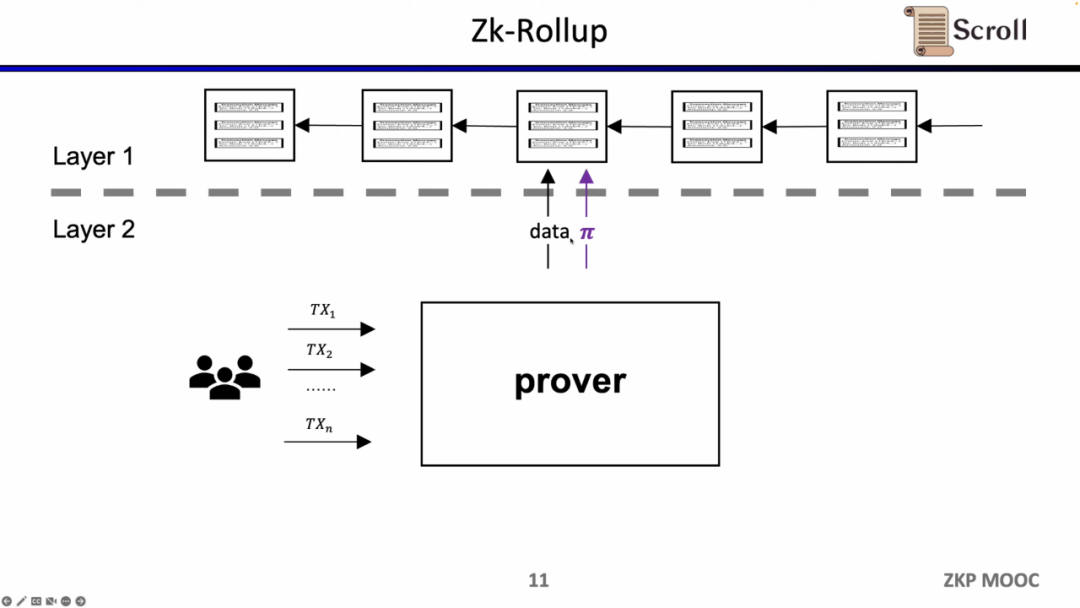
In the ZK- Rollup architecture, the L2 network only needs to upload the data and verify the correctness of the data to the L1, where the proof is calculated through the Zero-knowledge Proof circuit.
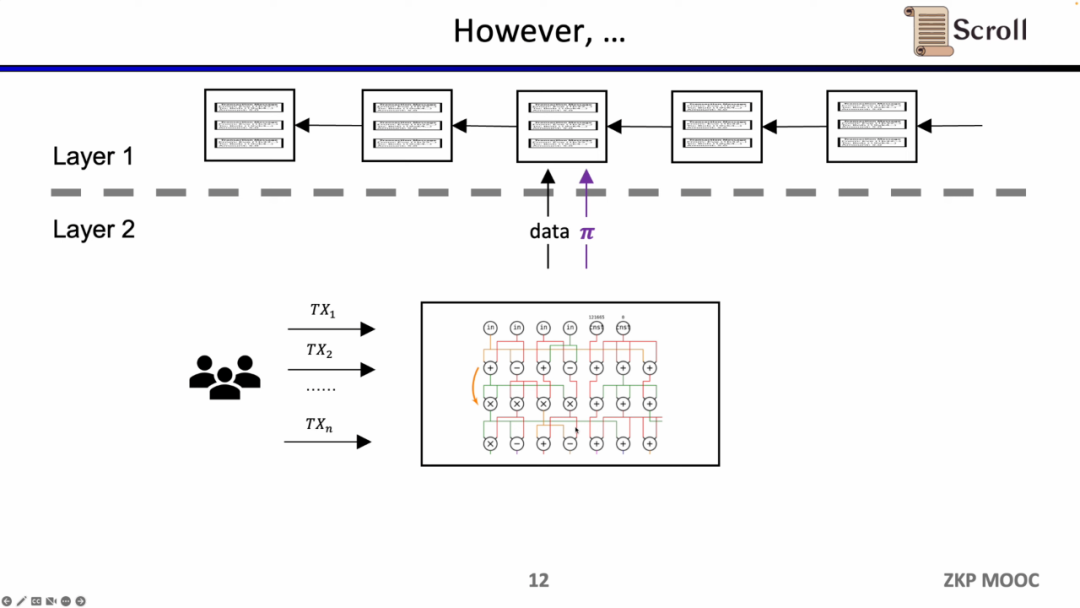
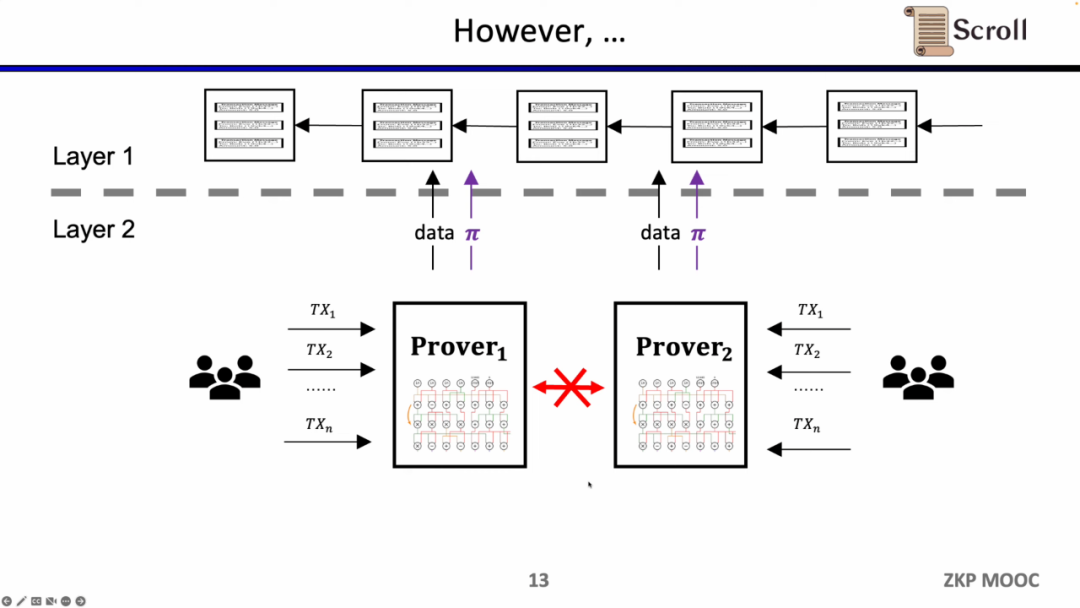
In the early ZK- Rollup, the circuit was designed for specific applications. Users need to send transactions to different provers, and then ZK- Rollup of different applications submits their own data and proofs to L1. The problem brought about by this is that the composability of the original L1 contract is lost.
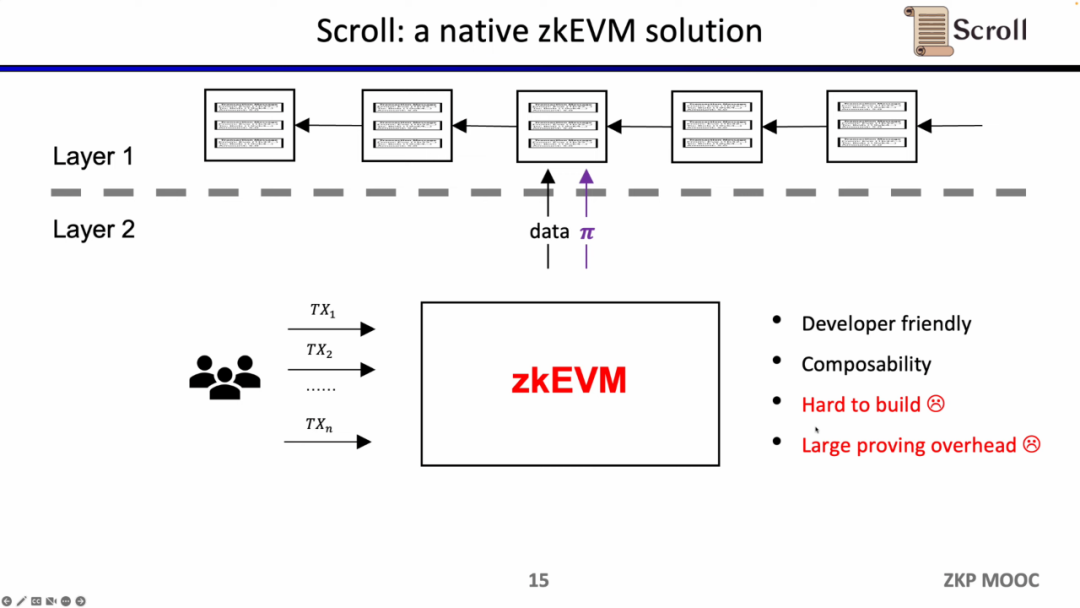
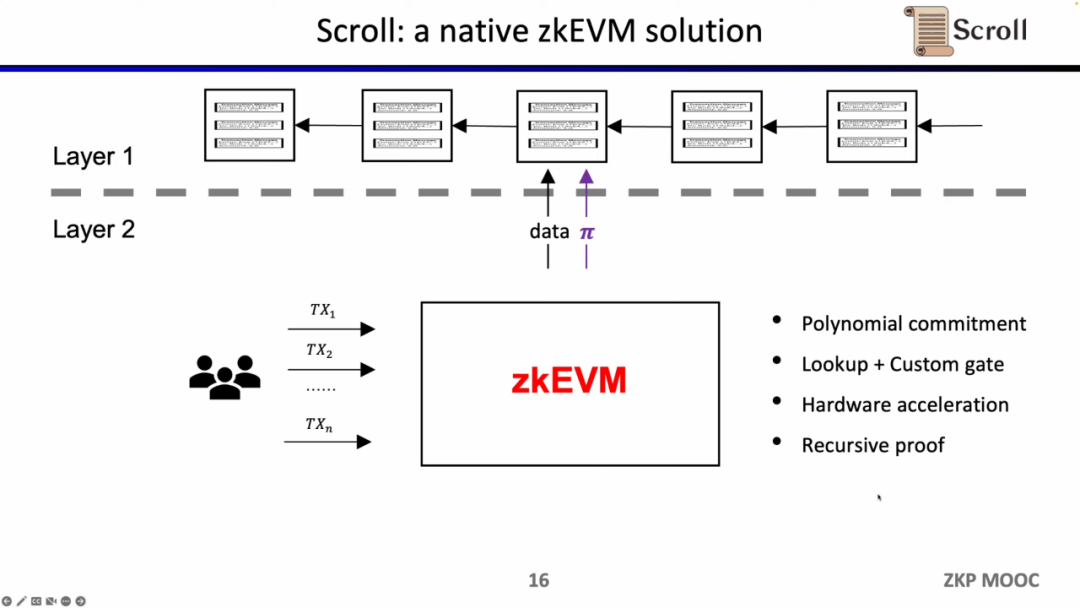
What Scroll needs to do is a native zkEVM solution, which is a general-purpose ZK- Rollup. This is not only more friendly to users, but also allows developers to gain a development experience on L1. Of course, the development behind this is very difficult, and the cost of current proof generation is also very high.
Fortunately, the efficiency of Zero-knowledge Proof has improved dramatically over the past two years, which is why zkEVM has become so popular in the last two years. There are at least four reasons to make it feasible. The first is the emergence of polynomial commitments. Under the original Groth16 proof system, the scale of constraints is very large, and polynomial commitments can support higher-order constraints and reduce the scale of proofs; the second is The emergence of lookup tables and custom gates can support more flexible designs and make proofs more efficient; the third is a breakthrough in hardware acceleration, which can shorten the proof time by 1-2 orders of magnitude through GPU, FPGA and ASIC; the fourth is Under recursive proof, multiple proofs can be compressed into one proof, making the proof smaller and easier to verify. Therefore, combining these four factors, the generation efficiency of Zero-knowledge Proof is three orders of magnitude higher than that of two years ago, which is also the origin of Scoll.
According to Justin Drake's definition, zkEVM can be divided into three categories. The first category is language-level compatibility. The main reason is that EVM is not designed for ZK, and there are many opcodes that are not friendly to ZK, which will cause a lot of additional overhead. . So like Starkware and zkSync choose to compile Solidity or Yul into a ZK-friendly compiler at the language level.
The second type is the bytecode level compatibility that Scroll is doing, which directly proves whether the bytecode processing of EVM is correct or not, and directly inherits the execution environment of Ethereum. Some trade-offs that can be made here are to use a different state root than the EVM, such as using a ZK-friendly data structure. Hermez and Consensys are doing something similar.
The third category is compatibility at the consensus level. The trade-off here is not only the need to keep the EVM unchanged, but also the storage structure to achieve full compatibility with Ethereum. The cost is that it takes longer to prove. And Scroll is building in cooperation with the PSE team of the Ethereum Foundation to realize the ZKization of Ethereum

Build zkEVM from 0 to 1

In the second part, Zhang Ye showed everyone how to build ZKVM from scratch.
complete process
First of all, in the front-end part of ZKP, you need to express your calculations through mathematical arithmetic. The most commonly used ones are linear R1CS, as well as Plonkish and AIR. After the constraints are obtained through arithmetic, you need to run the proof algorithm on the backend of the ZKP to prove the correctness of the calculation. Here are the most commonly used polynomial interactive oracle proofs (Polynomial IOP) and polynomial commitment schemes (PCS).
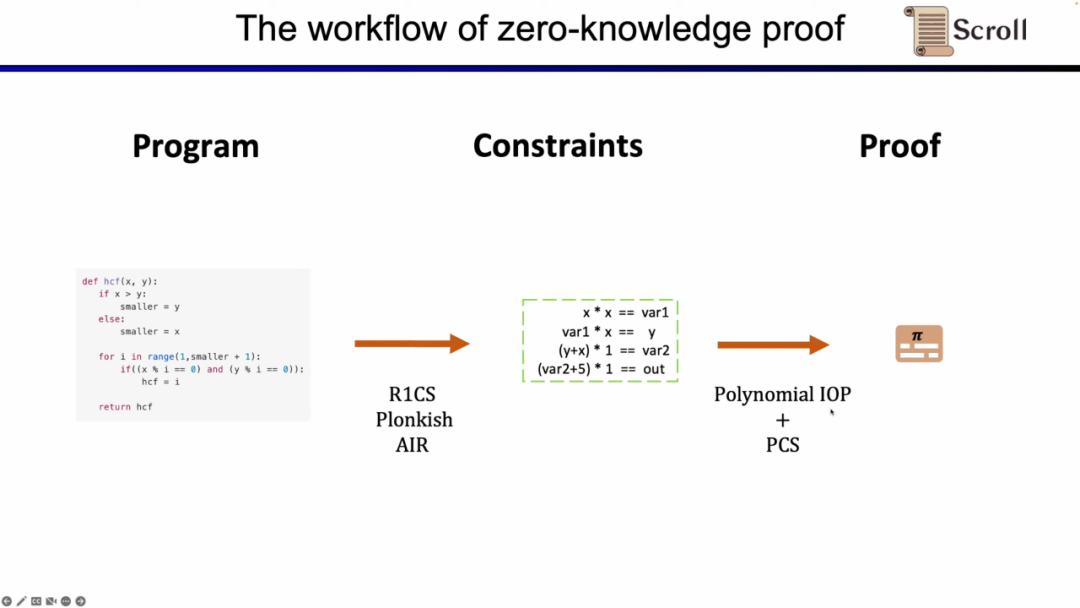
Here we need to prove that zkEVM, Scroll uses a combination of Plonkish, Plonk IOP, and KZG.
To understand why we use the three schemes. We start with the simplest R1CS first. The constraint in R1CS is that the linear combination multiplied by the linear combination is equal to the linear combination. You can add any linear combination of variables without additional overhead, but the order is at most 2 in each constraint. Therefore, for higher-order operations, more constraints are required.

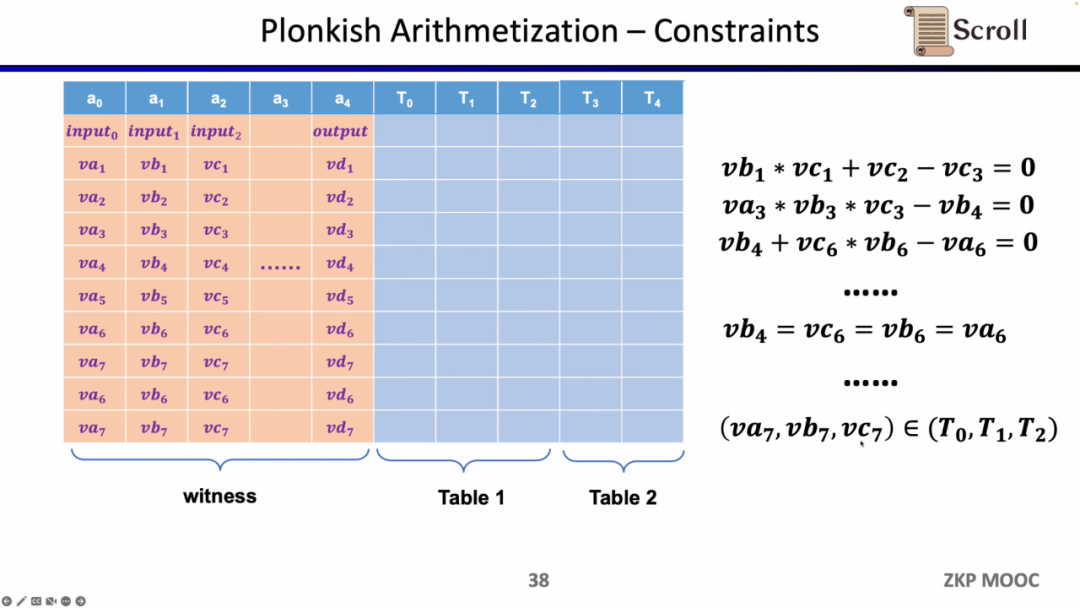
Whereas in Plonkish, you need to fill in the table with all variables, including input, output, and witnesses for intermediate variables. On top of this, you can define different constraints. There are three types of constraints available in Plonkish.
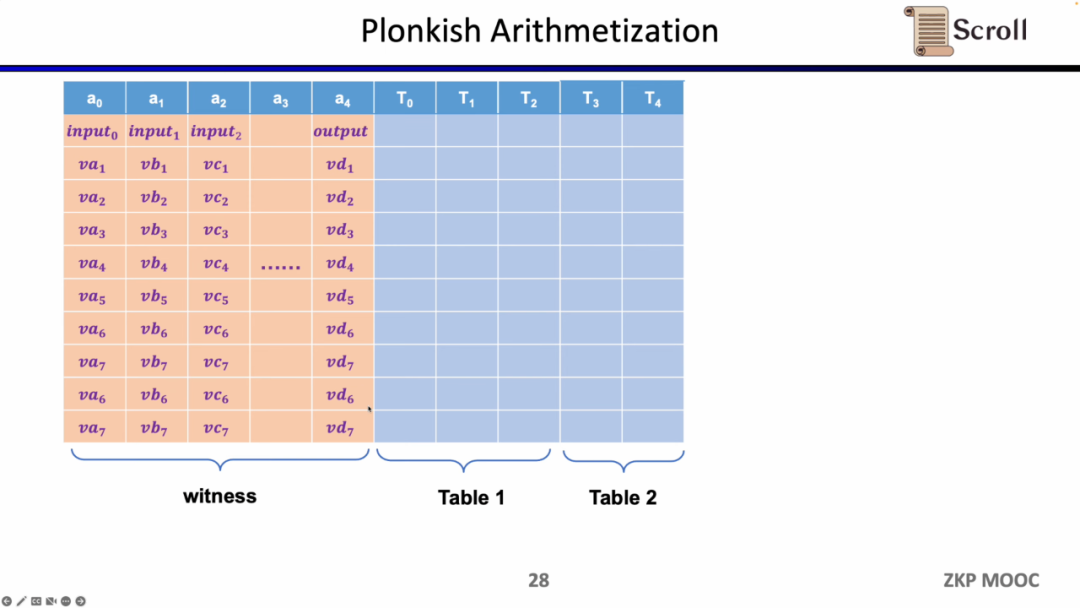
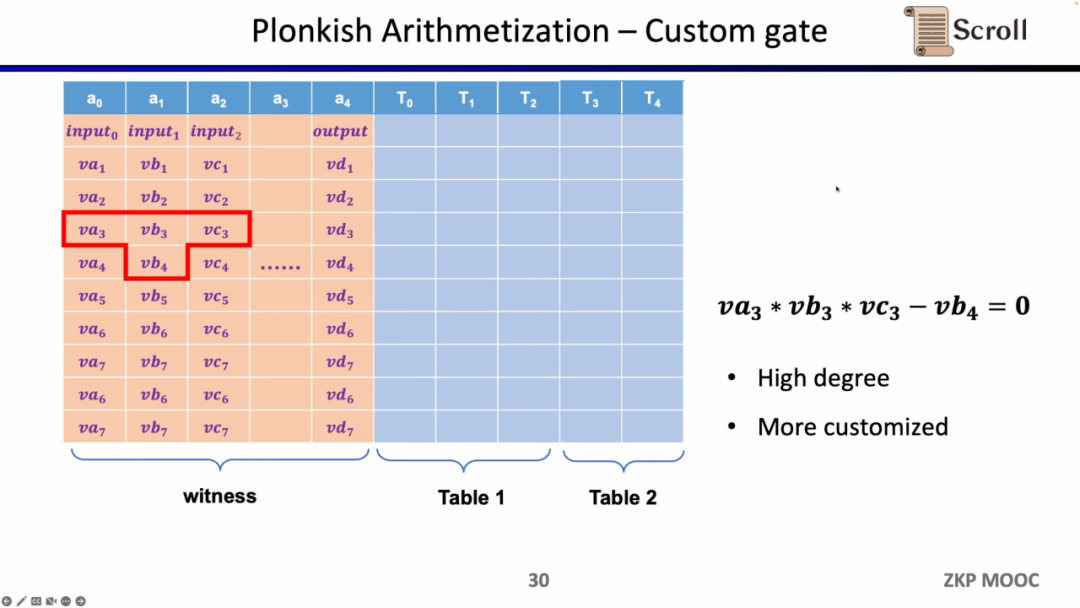
The first constraint is a custom gate (Custom Gate), you can define a polynomial constraint relationship between different cells, such as va3 * vb3 * vc3 - vb4 =0. Compared to R1CS, the order can be higher, because you can define constraints on any variable, and you can define some very different constraints.
The second constraint is Permuation, that is, equivalence checks (equality checks). It can be used to check the equivalence of different cells, and is often used to associate different gates in a circuit, such as proving that the output of the previous gate is equal to the input of the next gate.

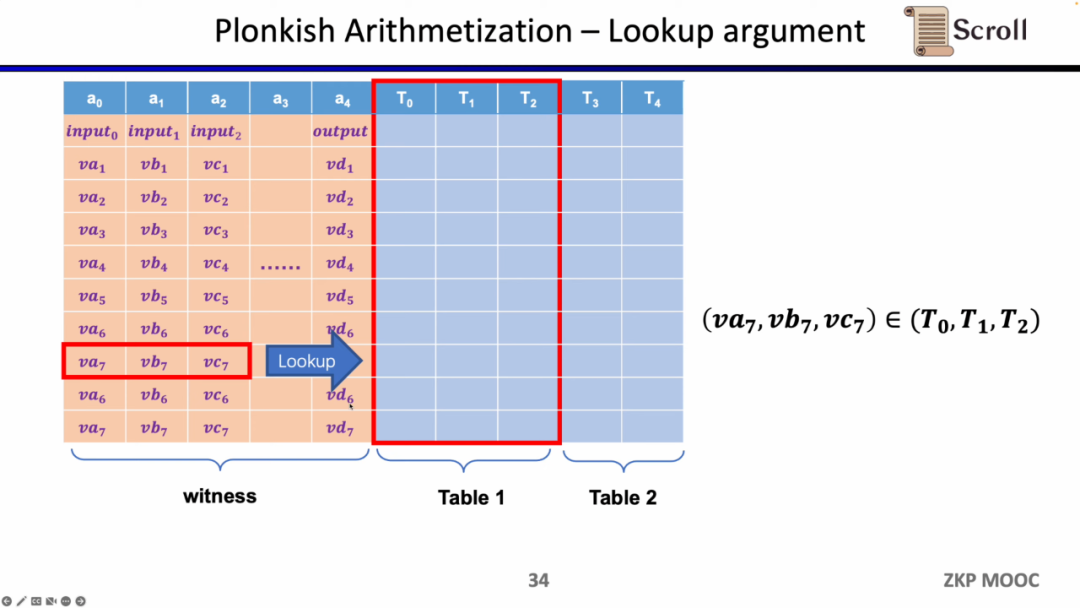
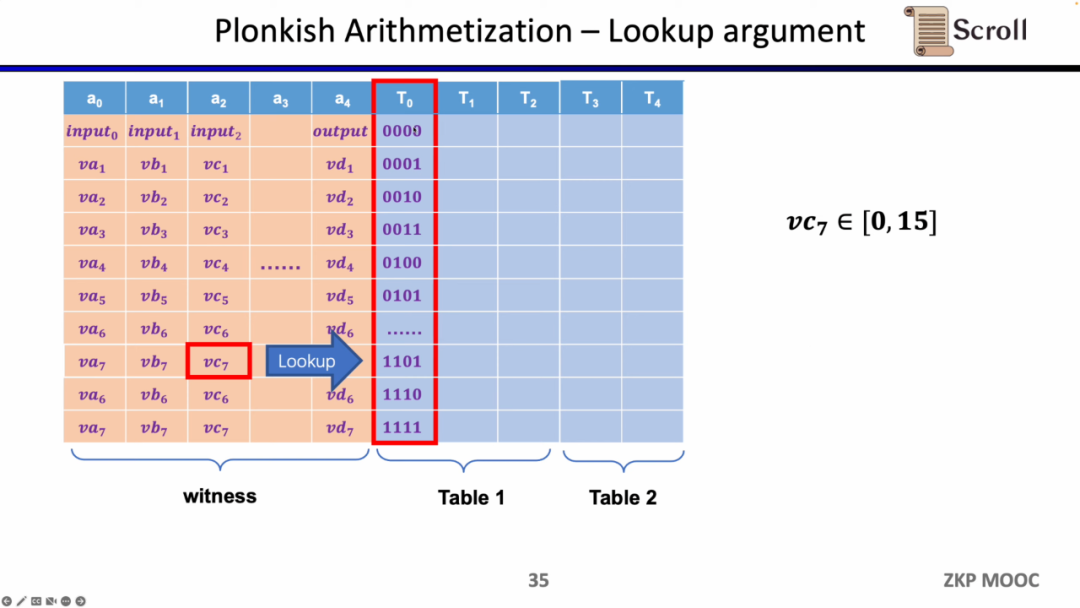
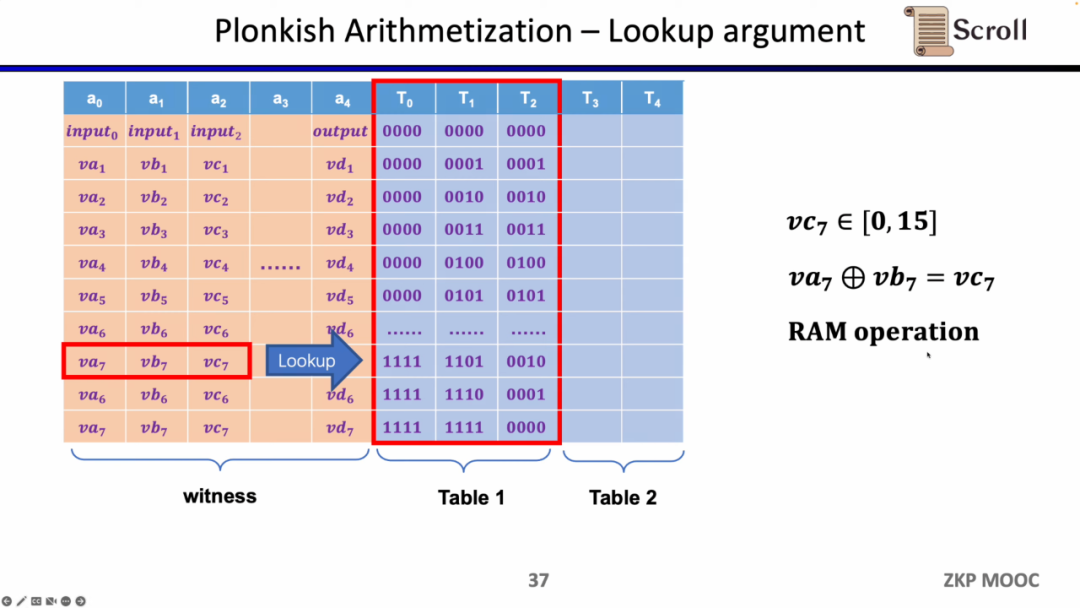
The last type of constraint is the Lookup Table. We can understand the lookup table as a relationship between variables, which can be expressed as a table. For example, we want to prove that vc7 is in the range of 0-15. In R1CS, you first need to decompose this value into 4 binary bits, and then prove that each bit is in the range of 0-1, which will require four constraints. In Plonkish, you can list all possible ranges in the same column, and you only need to prove that vc7 belongs to that column, which is very efficient for range proofs. In zkEVM, lookup tables are very useful for proving memory reads and writes.
To sum up, Plonkish also supports custom gates, equivalence checks and lookup tables, which can be very flexible to meet different circuit needs. In simple comparison with STARK, each row in STARK is a constraint, and the constraint needs to represent the state transition between rows, but the custom constraints in Plonkish are obviously more flexible.
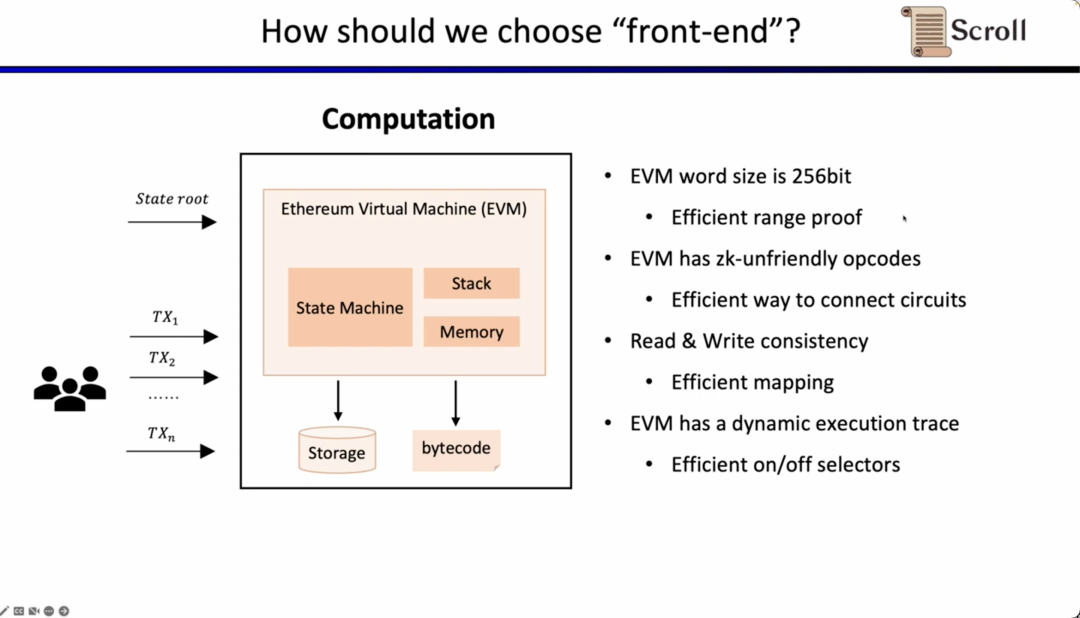
Now the question is how do we choose the frontend in zkEVM. There are four main challenges for zkEVM. The first challenge is that the field of the EVM is 256 bits, which means that variables need to be efficiently bound; the second challenge is that the EVM has many ZK-unfriendly opcodes, so very large-scale constraints are required to prove these operations code, such as Keccak-256; the third challenge is the memory read and write problem, you need some effective mapping to prove that what you read is consistent with what you wrote before; the fourth challenge is that the execution trace of EVM is Dynamic, so we need custom gates to adapt to different execution traces. For the above considerations, we chose Plonkish.
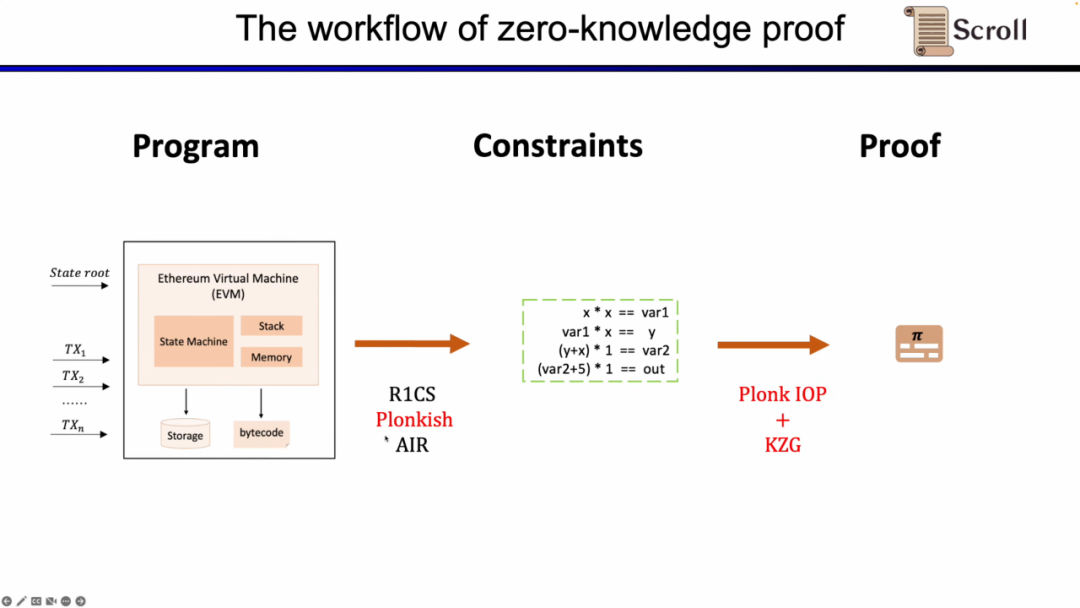
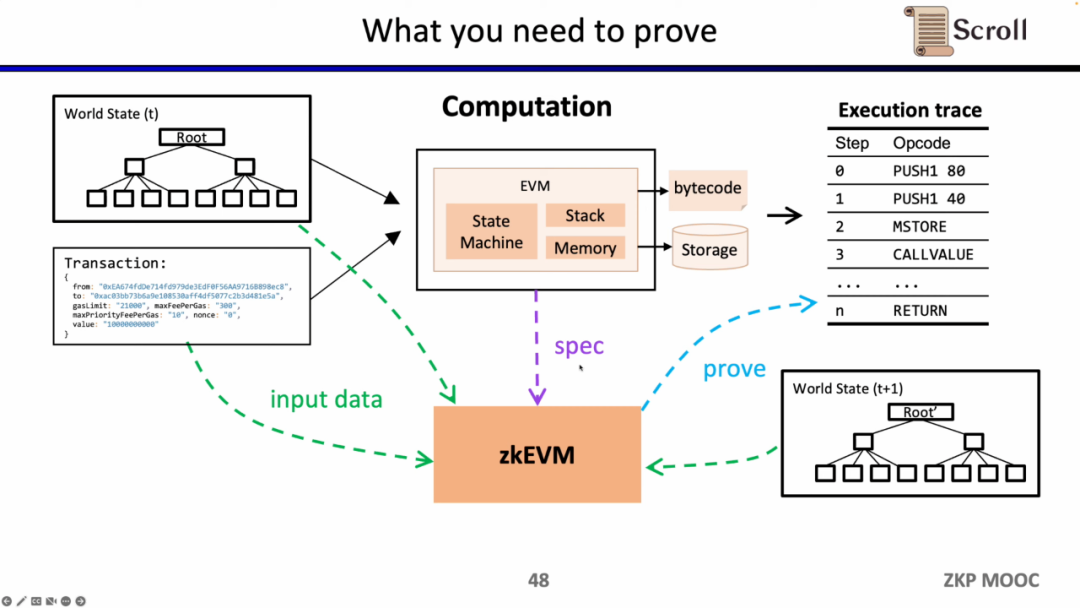
Next, let's look at the complete process of zkEVM. Based on the initial global state tree, after a new transaction comes in, the EVM will read the bytecode of the stored and invoked contract, and generate corresponding execution traces such as PUSH, PUSH, STORE, CALLVALUE, and then step by step to update the global state to obtain the global state tree after the transaction. The zkEVM takes the initial global state tree, the transaction itself, and the global state tree after the transaction as input, and according to the EVM specification, it proves the execution correctness of the execution trace.
In-depth EVM circuit details, each step of the execution trace has a corresponding circuit constraint. Specifically, the circuit constraints of each step include Step Context, Case Switch, and Opcode Specific Witness. Step Context contains the codehash corresponding to the execution trace, remaining gas and counter; Case Switch contains all opcodes, all error conditions, and the corresponding operation of the step; Opcode Specific Witness contains additional witnesses required by the opcode, such as operands wait.
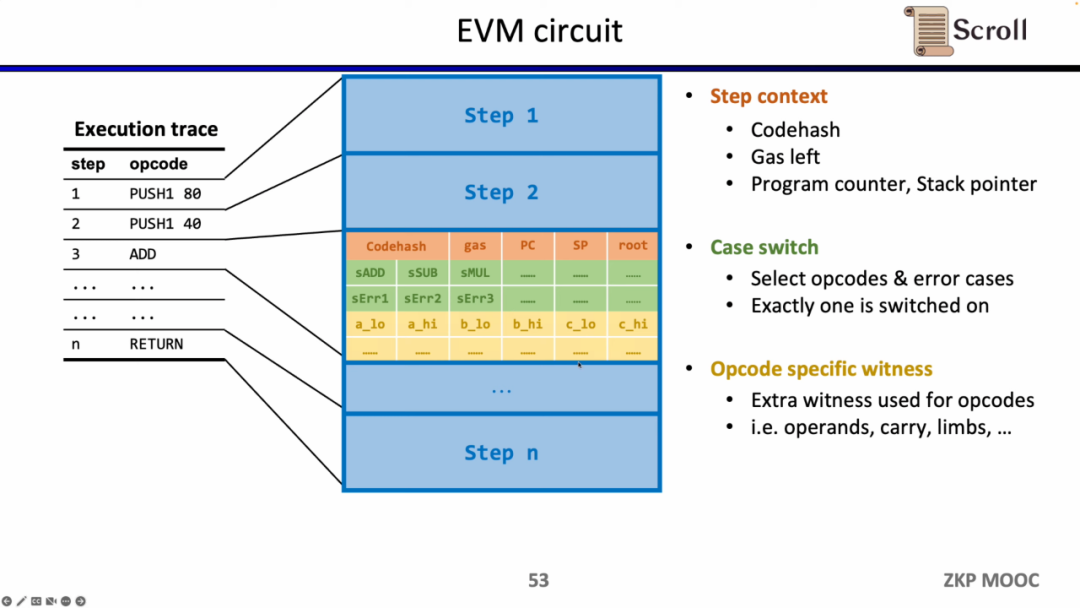
Taking simple addition as an example, it is necessary to ensure that the control variable sADD of the opcode of addition is set to 1, and the control variables of other opcodes are all zero. In the Step Context, constrain the consumed gas to be equal to 3 by setting gas' - gas - 3 = 0. Similarly, constrain the counter, and the stack pointer will accumulate 1 after this step; in the Case Switch, control the variable sum to 1 through the opcode To constrain this step to be an addition operation; in Opcode Specific Witness, constrain the actual addition of operands.
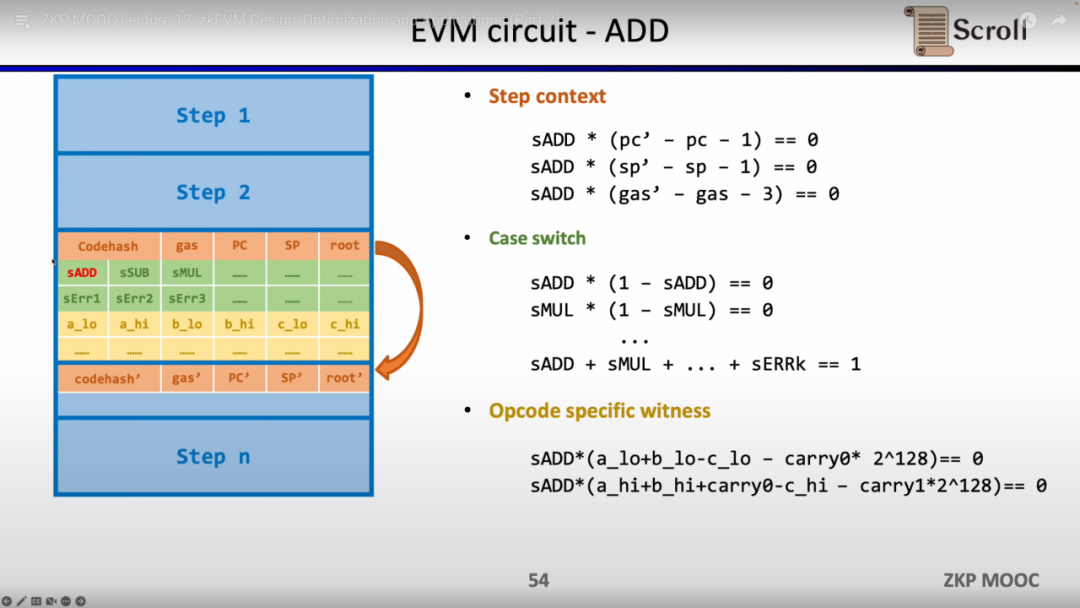
In addition, additional circuit constraints are required to ensure the correctness of operand reads from memory. Here we first need to build a lookup table to prove that the operand belongs to memory. And through the memory circuit (RAM Circuit) to verify the correctness of the memory table.
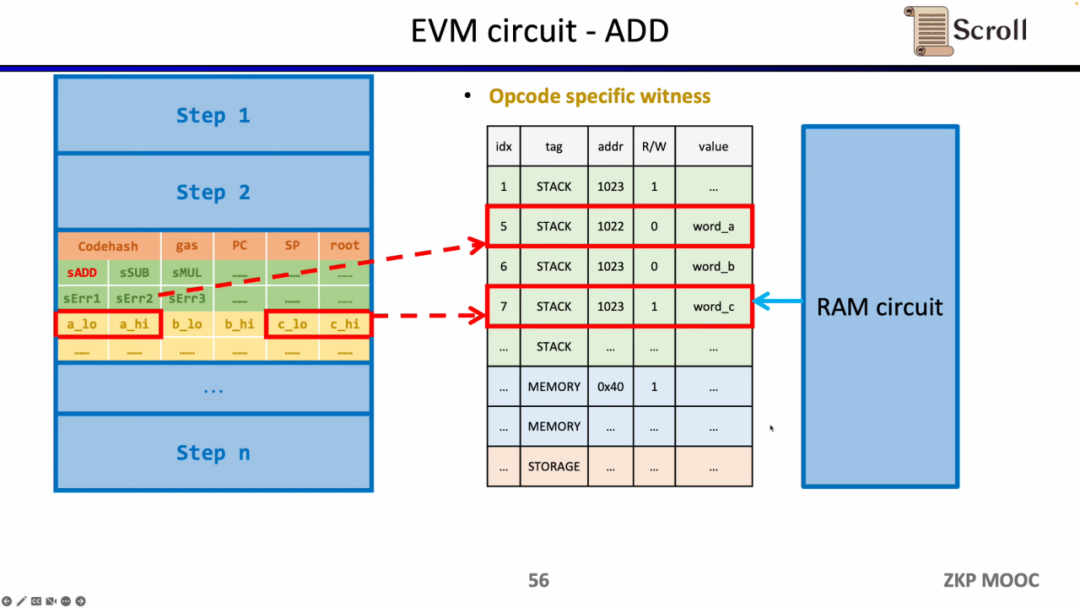
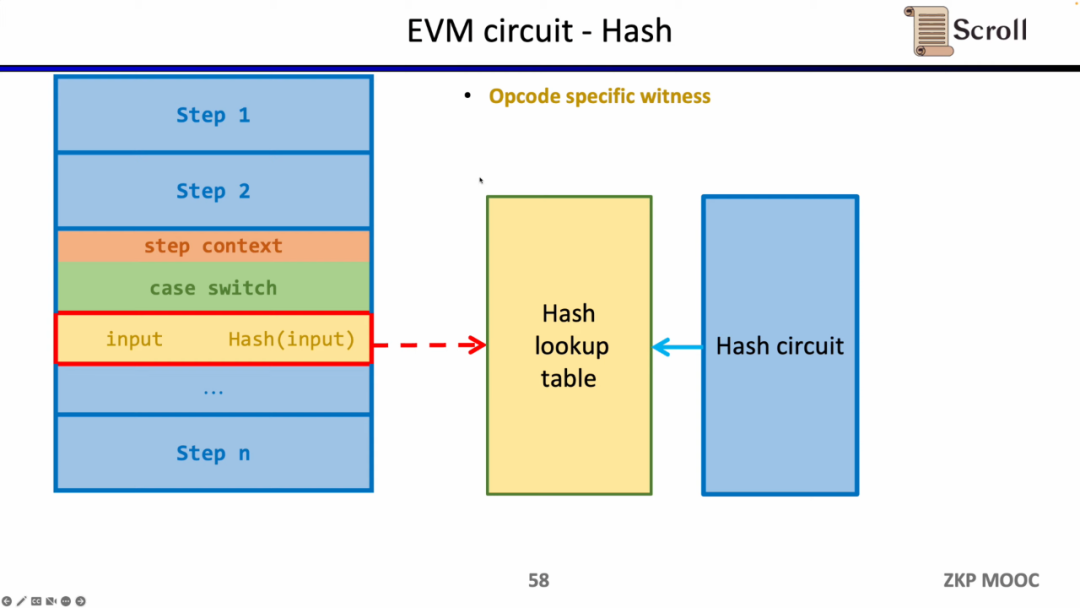
The same method can be applied to zk-unfriendly hash functions, build a lookup table of the hash function, map the hash input and output in the execution trace to the lookup table, and use an additional hash circuit (Hash Circuit) to verify the hash Hope the correctness of the lookup table.
Now let's look at the circuit architecture of zkEVM. The core EVM circuit is used to constrain the correctness of each step of the execution trace. In some places where the EVM circuit constraints are difficult, we use a lookup table to map, including Fixed Table, Keccak Table, RAM Table, Bytecode, Transaction, Block Context, and then use separate circuits to constrain these lookup tables, for example, Keccak circuits are used to constrain Keccak tables.
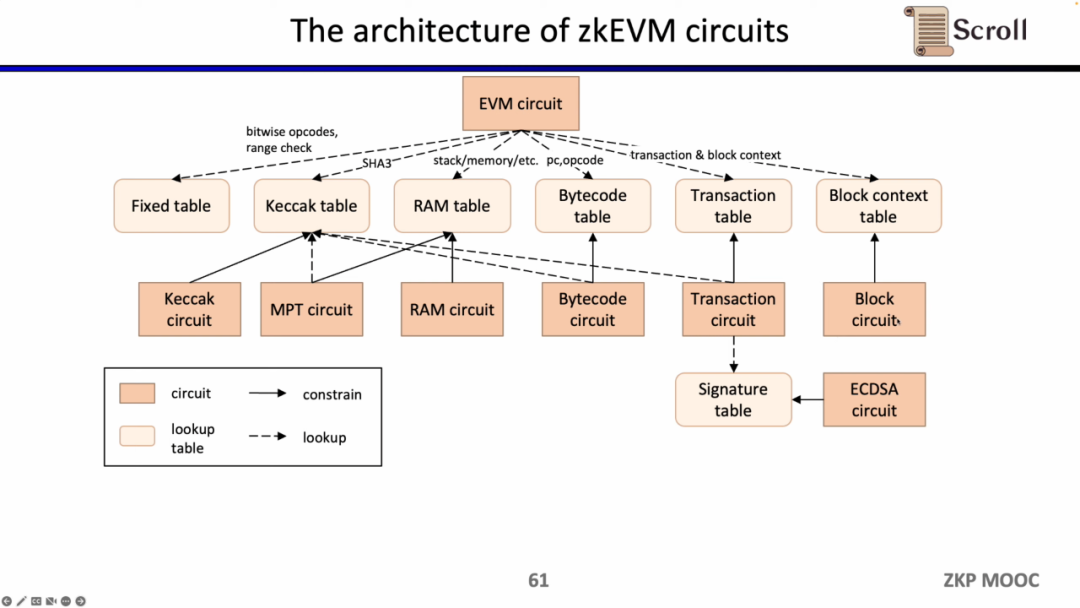
To summarize, the complete workflow of zkEVM is shown in the figure below.
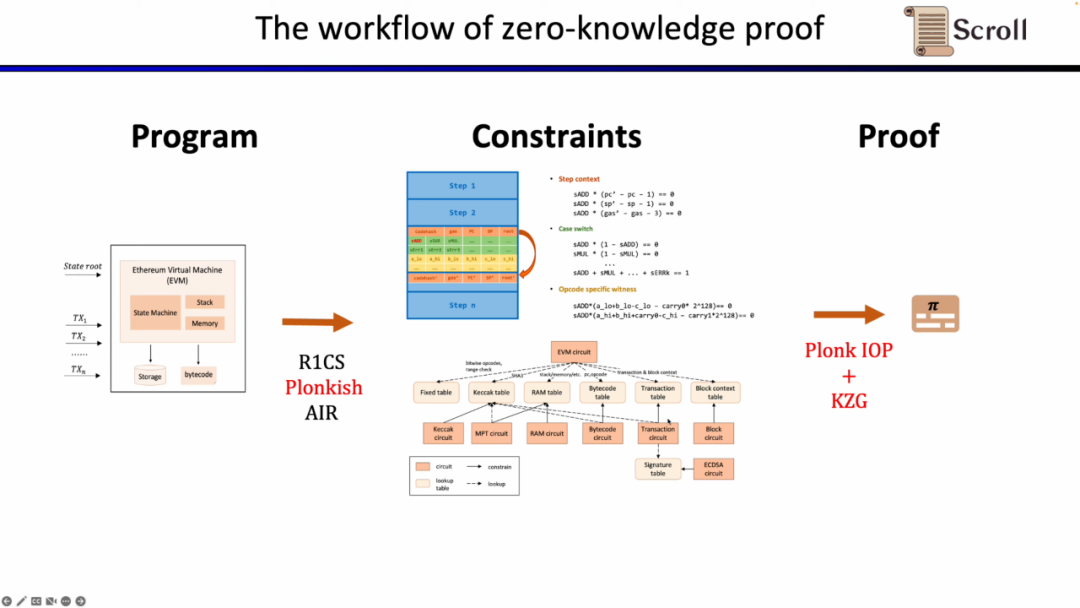
proof system
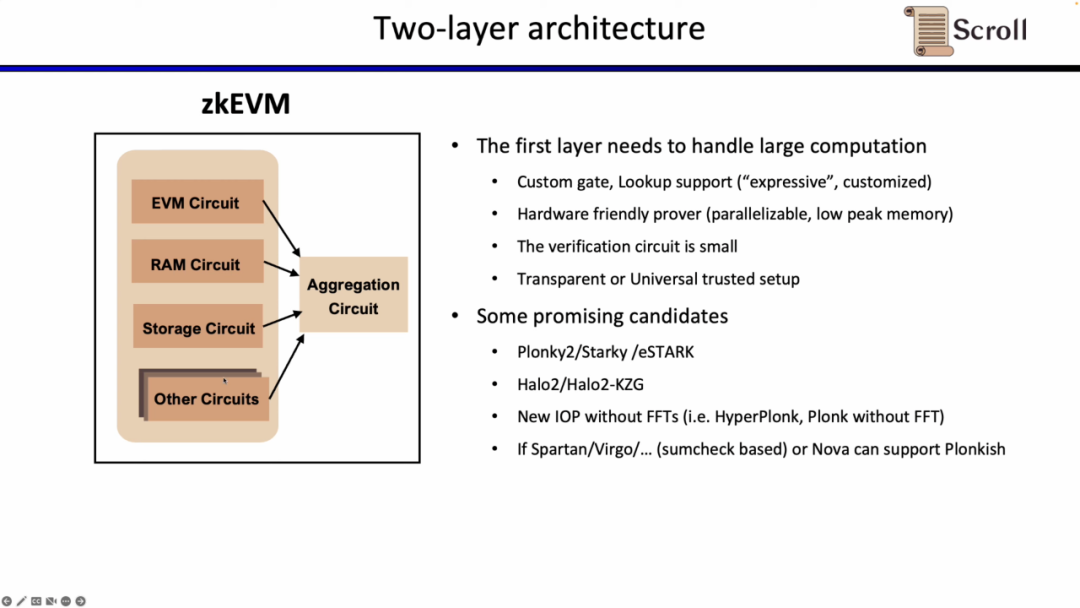
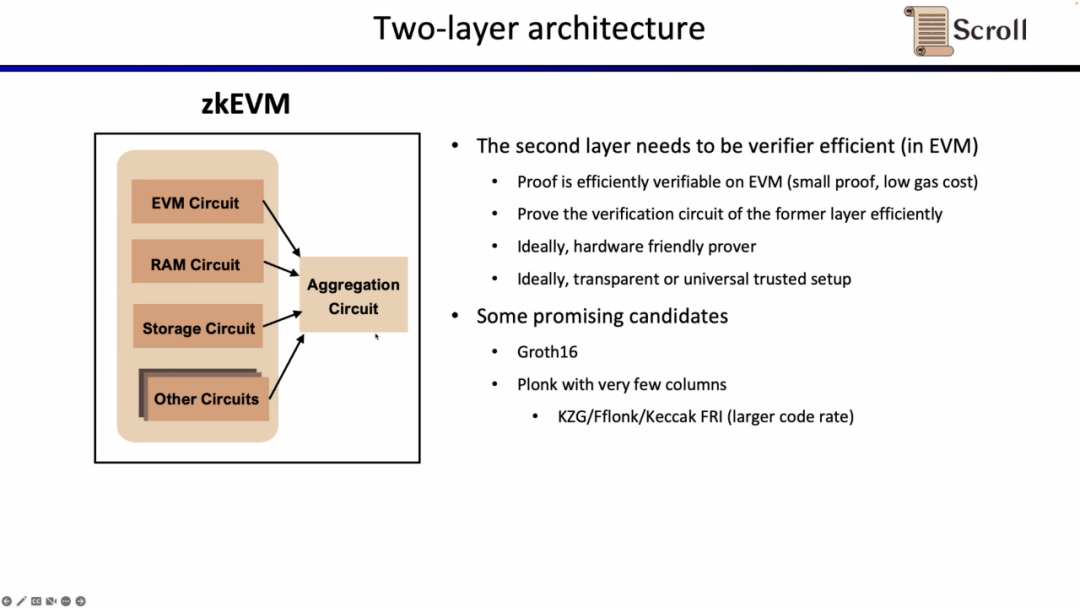
Because the overhead of directly verifying the above-mentioned EVM circuit, memory circuit, storage circuit, etc. on L1 is huge, Scroll's proof system adopts a two-layer architecture.
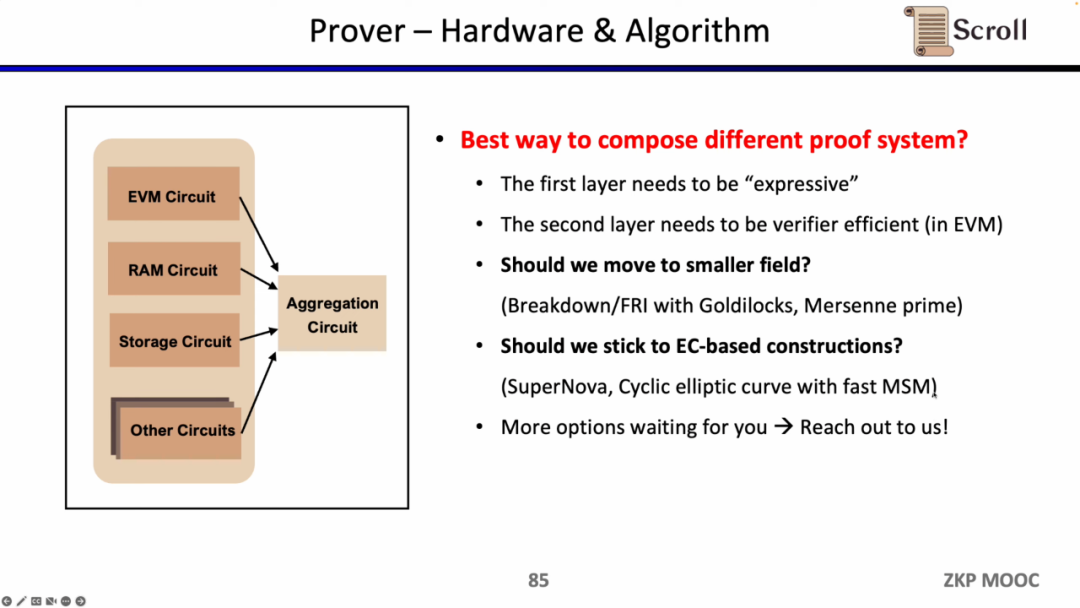
The first layer is responsible for directly proving the EVM itself, which requires a lot of computation to generate the proof. Therefore, the first-level proof system is required to support custom gates and look-up tables, be friendly to hardware acceleration, generate calculations in parallel under low peak memory, and verify that the scale of the circuit is small and can be quickly verified. Promising alternatives include Plonky2, Starky, and eSTARK, which basically use Plonk in the front end, but may use FRI in the back end, and all of them meet the above four characteristics. Another type of optional scheme includes Halo2 developed by Zcash, and Halo2 of the KZG version.
There are also some new proof systems that are promising, such as HyperPlonk, which recently removed FFT, and the NOVA proof system can achieve smaller recursive proofs. But they only support R1CS in research, if they can support Plonkish in the future and apply it in practice, it will be very practical and efficient.
The second-level proof system is used to prove the correctness of the first-level proof, and it needs to be able to efficiently verify in the EVM. Ideally, it should be hardware-accelerated-friendly and support transparent or universal setup. Promising alternatives include Groth16 and the Plonkish proof system with fewer columns. Groth16 is still the representative of extremely high proof efficiency in the current research, and the Plonkish proof system can also achieve high proof efficiency when the number of columns is small.
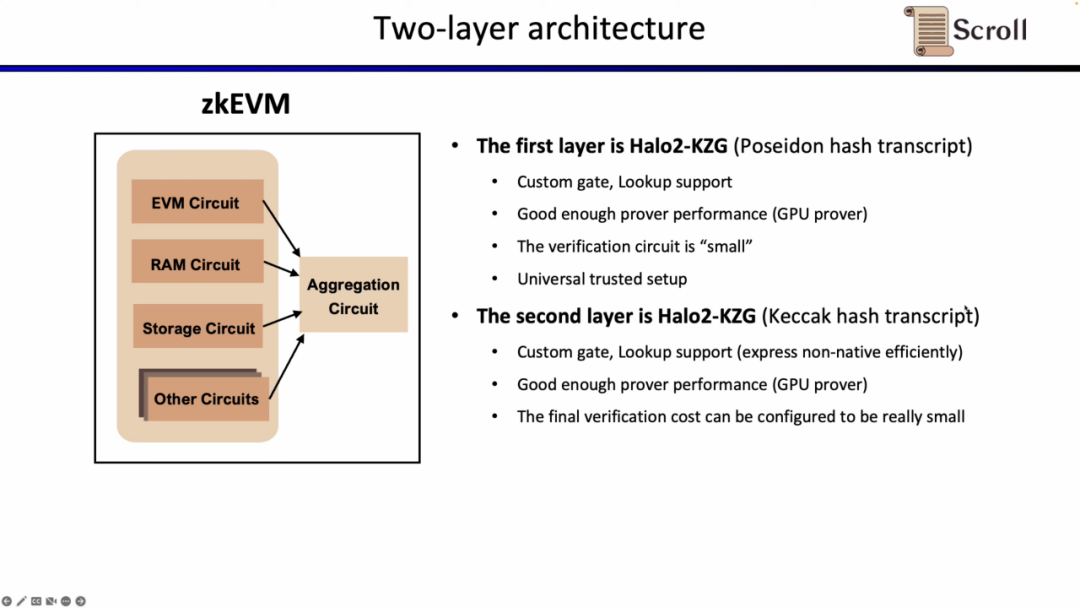
At Scroll, we have adopted the Halo2-KZG proof system in the two-tier proof system. Because Halo2-KZG can support custom gates and lookup tables, it has good performance under GPU hardware acceleration, and the verification circuit is small in scale, which can be quickly verified. The difference is that we use Poseidon hashes in the first-tier proof system to further improve proof efficiency, while the second-tier proof system still uses Keccak hashes because it is directly verified on Ethereum. Scroll is also exploring the possibility of a multi-layer proof system to further aggregate the aggregated proofs generated by the second-level proof system.
Under the current implementation, Scroll's first-level proof system EVM circuit has 116 columns, 2496 custom gates, 50 look-up tables, the highest order is 9, and 2^18 rows are required under 1M Gas; while the second-level proof system's The aggregation circuit has only 23 columns, 1 custom gate, 7 look-up tables, and the highest order is 5. In order to aggregate EVM circuits, memory circuits, and storage circuits, 2^25 rows are required.

Scroll has also done a lot of research and optimization work on GPU hardware acceleration. For the EVM circuit, the optimized GPU certifier only takes 30s, which is 9 times more efficient than the CPU certifier; and for the aggregation circuit, the optimized The GPU prover only takes 149s, which is 15 times more efficient than the CPU. Under the current optimization conditions, the 1M Gas first-level proof system takes about 2 minutes, and the second-level proof system takes about 3 minutes.

interesting research questions

In the third part, Zhang Ye talked about some interesting research issues in the process of building zkEVM in Scroll, from the front-end arithmetic circuit to the realization of the prover.
circuit
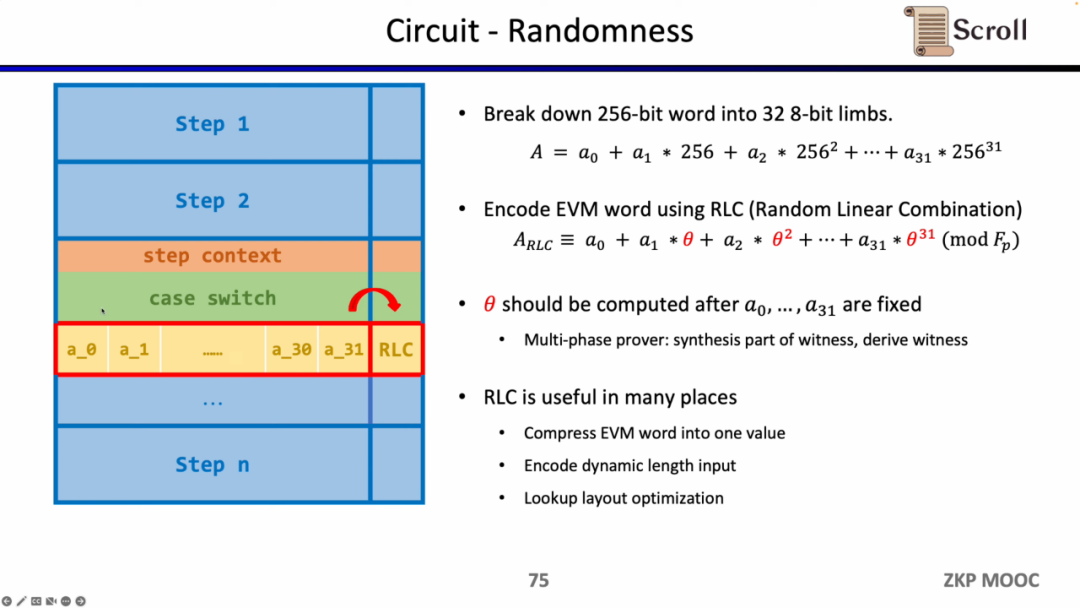
The first is the randomness in the circuit, because the EVM field is 256 bits, we need to split it into 32 8-bit fields, so as to perform range proof more efficiently. Then we use the random linear combination (Random Linear Combination, RLC) method to use random numbers to encode 32 fields into one, and only need to verify this field to verify the original 256-bit field. But the problem is that the generation of the random number needs to be split after the field to ensure that it is not tampered with. Therefore, the Scroll and PSE teams proposed a multi-stage prover scheme to ensure that after field splitting, random numbers are used to generate RLC. This scheme is encapsulated in the Challenge API. RLC has many application scenarios in zkEVM. It can not only compress EVM fields into one field, but also encrypt variable-length inputs, or optimize the layout of lookup tables. However, there are still many open problems to be solved.
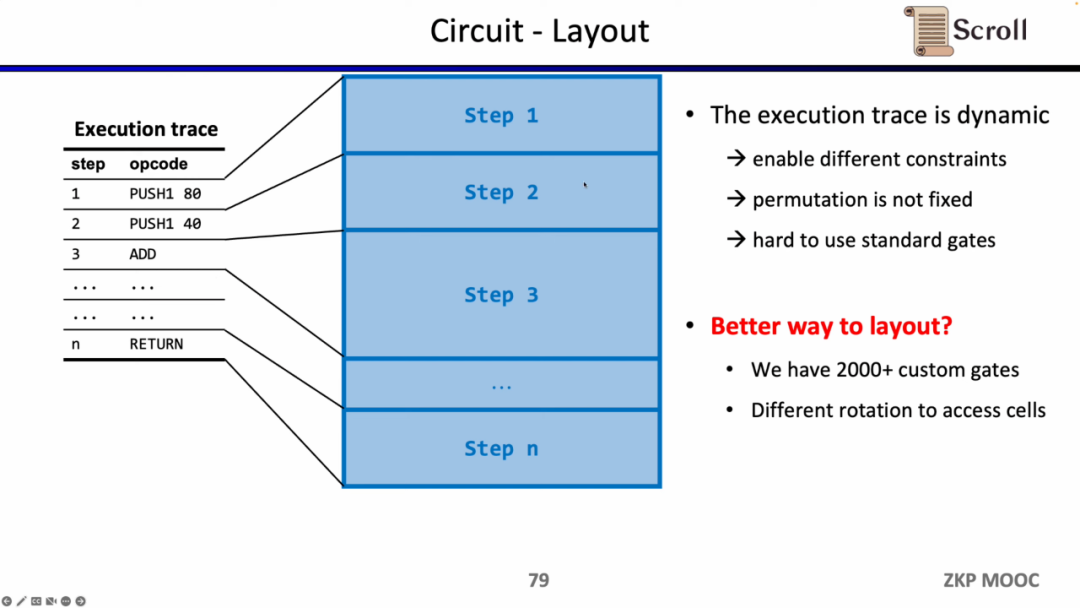
A second interesting research problem in terms of circuits is circuit layout. The reason why the Scroll front-end uses Plonkish is because the execution trace of the EVM is dynamically changing, and it needs to be able to support different constraints and change equivalence tests, while the standardized gate of R1CS requires a larger circuit scale to realize. However, Scroll currently uses more than 2,000 custom gates to meet dynamically changing execution traces, and is also exploring how to further optimize the circuit layout, including splitting Opcode into Micro Opcode, or reusing cells in the same table.
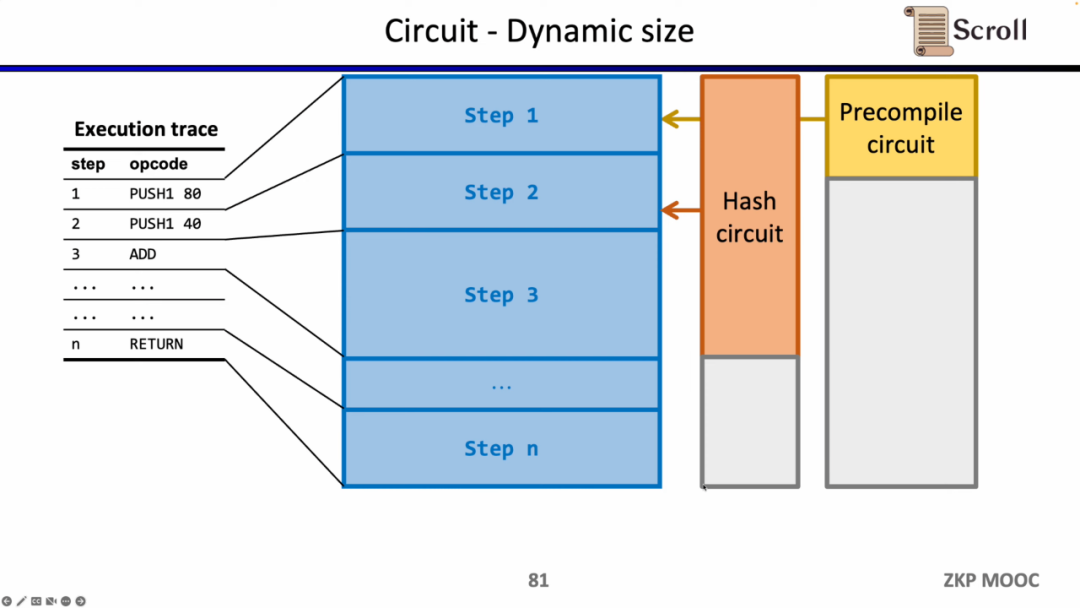
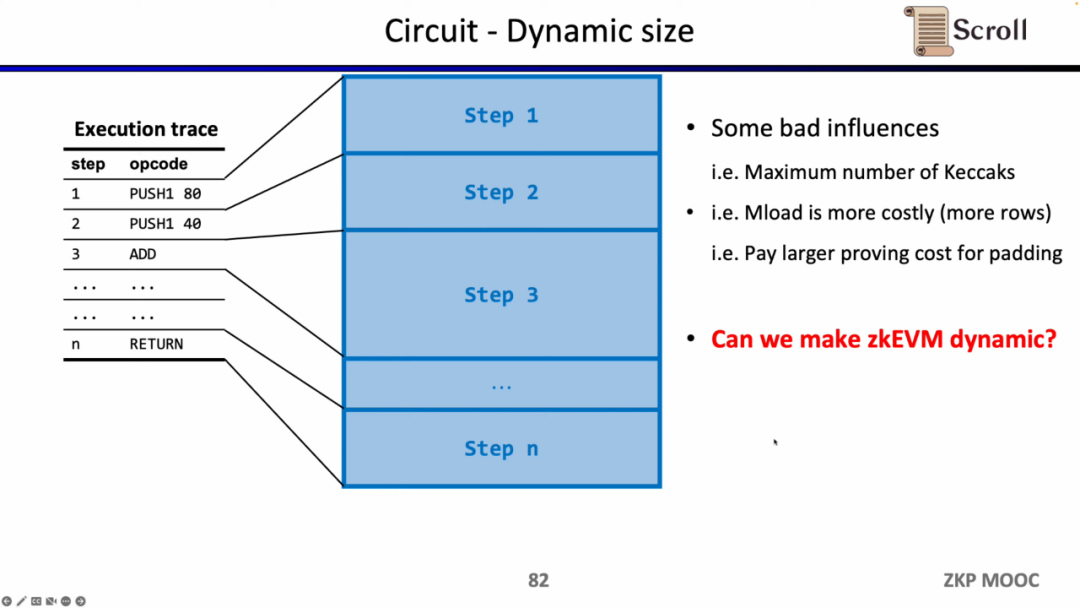
A third interesting research problem in terms of circuits is dynamic scaling. Because the circuit scale of different opcodes is different, but in order to meet the dynamically changing execution trace, the opcode of each step needs to meet the maximum circuit scale, such as Keccak hashing, so we actually pay extra overhead. Assuming we can dynamically adapt zkEVM to dynamically changing execution traces, this will save unnecessary overhead.
certifier
As for the prover, Scroll has optimized MSM and NTT in terms of GPU acceleration, but now the bottleneck has shifted to witness generation and data replication. Assuming that MSM and NTT account for 80% of the proof time, even if hardware acceleration can improve this part of the efficiency by several orders of magnitude, the original 20% proof time for witness generation and copying data will become a new bottleneck. Another problem with the prover is that it requires a lot of memory, so it is also necessary to explore cheaper and more decentralized hardware solutions.
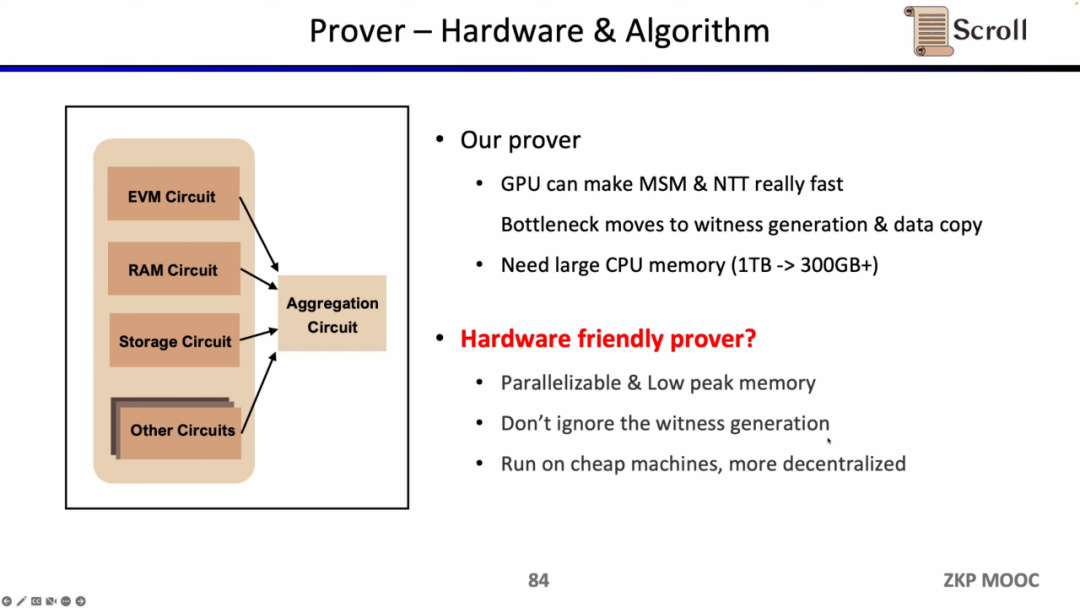
At the same time, Scroll is also exploring hardware acceleration and proof algorithms to improve the efficiency of the prover. At present, there are two main directions, or switch to a smaller domain, such as using 64-bit Goldilocks domain, 32-bit Mersenne Prime, etc., or stick to the new proof system based on elliptic curve (EC), Such as SuperNova. Of course, there are other possible paths. Friends with ideas are welcome to contact Scroll directly.
safety
Security is paramount when building the zkEVM. The zkEVM jointly built by PSE and Scroll has about 34,000 lines of code. From the perspective of software engineering, it is impossible for these complex code bases to be free of loopholes for a long time. Scroll is currently auditing the zkEVM code base through a large number of audits, including the top auditing companies in the industry.


Other applications using zkEVM

Section IV explores some other applications that use zkEVM.
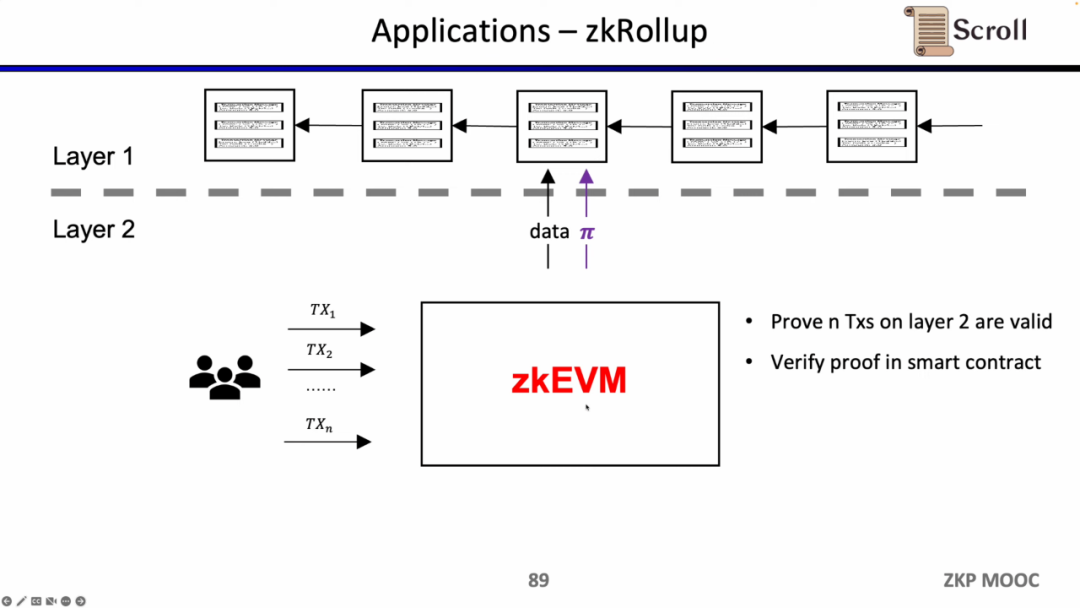
In the architecture of zkRollup, we verify that the n transactions on L2 are valid through the smart contract on L1.
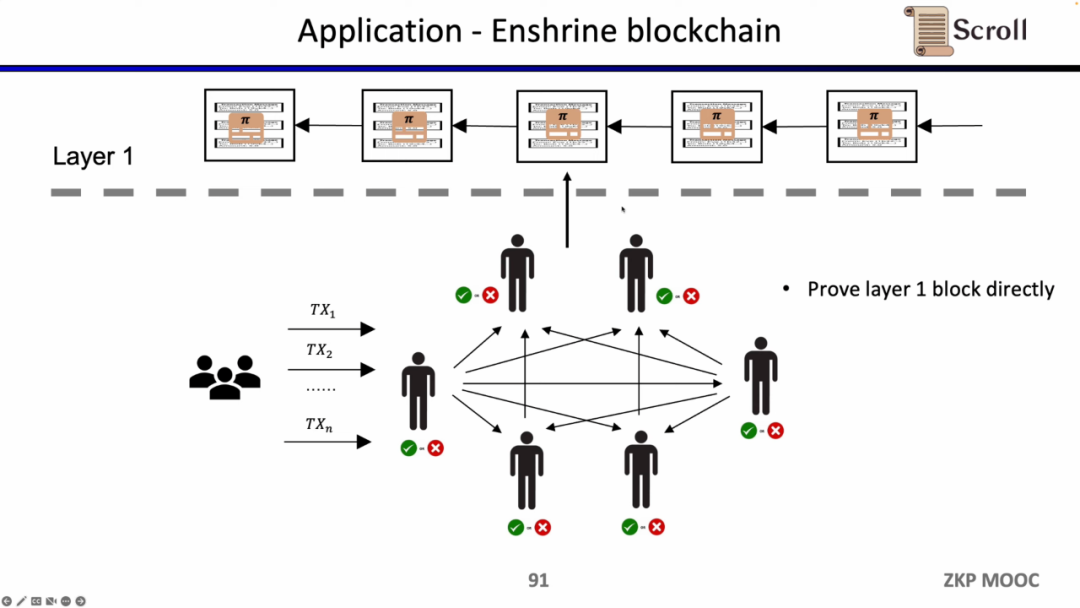
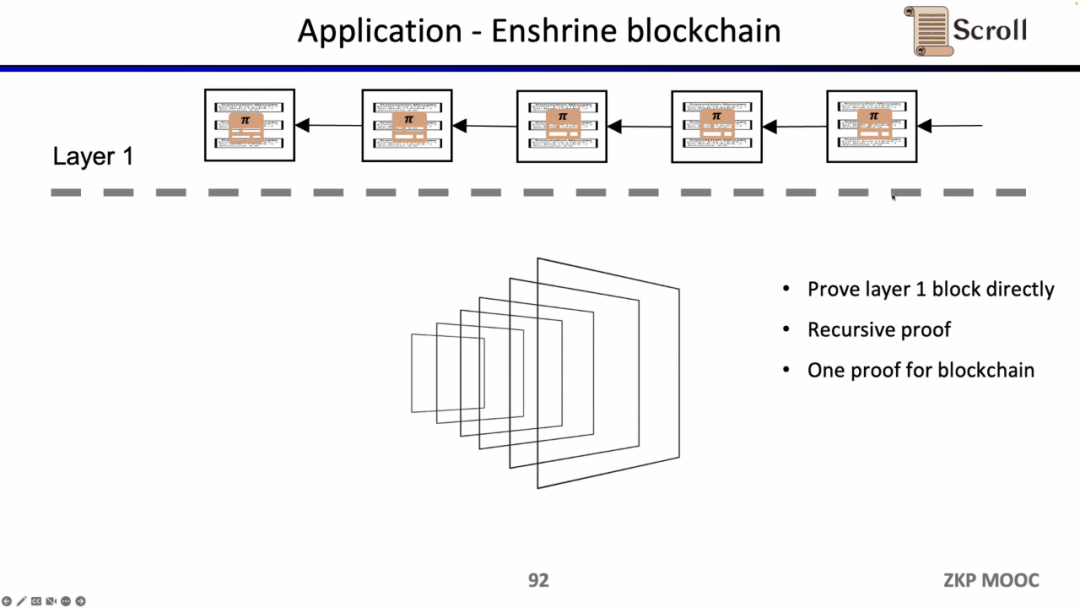
If we directly verify the L1 block, then the L1 node does not need to execute the transaction repeatedly, but only needs to verify the validity of each block proof. Such an architectural solution is called Enshrine Blockchain. At present, it is very difficult to directly implement it on Ethereum, because it needs to verify the entire Ethereum block, which will include verifying a large number of signatures, which will bring longer proof time and lower security. Of course, there are already some other public chains that use a single proof to verify the entire blockchain through recursive proofs, such as MINA.
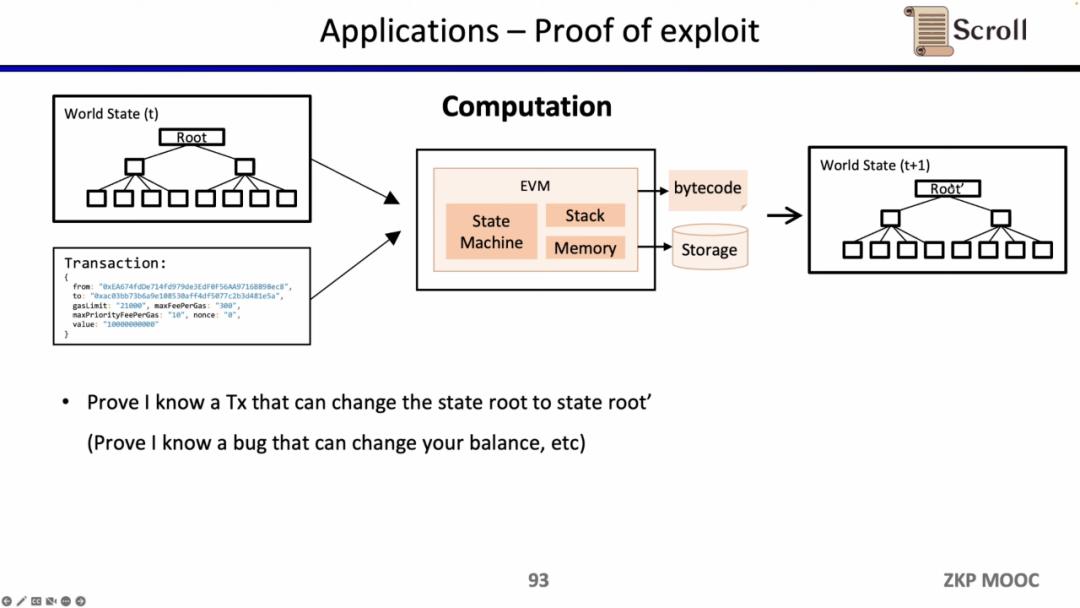
Because zkEVM can prove the state transition, it can also be used by white hats to prove that they know the loopholes of some smart contracts and seek bounties from the project side.
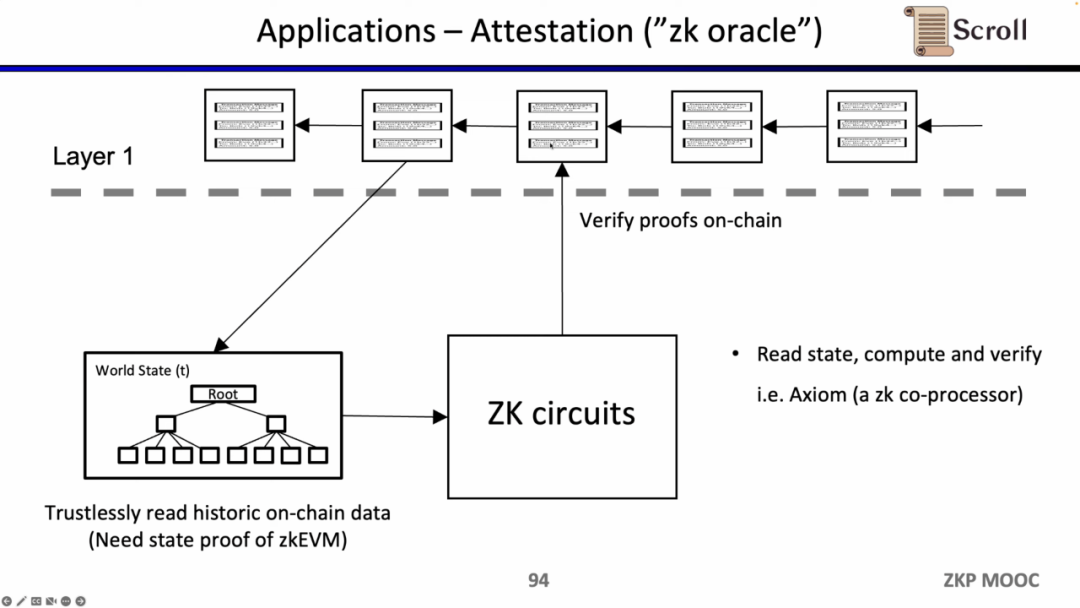
The last use case is to prove the statement of historical data through Zero-knowledge Proof, and use it as an oracle machine. Axiom is currently working on products in this area. At the recent ETHBeijing hackathon, the GasLockR team took advantage of this feature to prove the historical Gas overhead.
Finally, Scroll is building zkRollup's general scaling solution for Ethereum, which uses a very advanced arithmetic circuit and proof system, and builds a fast validator through hardware acceleration to prove recursion. At present, the Alpha test network has been launched and has been running stably for a long time.
Of course, there are still some interesting problems to be solved, including protocol design and mechanism design, zero-knowledge engineering and practical efficiency. Welcome everyone to join Scroll to build together!