

Author: Wang Lu, Dingfocus One (dingjiaoone) original
DeepSeek has completely unsettled the global community.
Yesterday, Musk appeared in a live broadcast with "the most intelligent AI on Earth" - Gork 3, claiming that its "reasoning ability surpasses all known models so far", and also outperformed DeepSeek R1 and OpenAI o1 in the reasoning-testing time score. Not long ago, the national-level WeChat application announced that it was accessing DeepSeek R1 and is currently in the gray-scale testing phase. This powerful combination is believed by the outside world to be a game-changer in the field of AI search.
Now, many global tech giants such as Microsoft, NVIDIA, Huawei Cloud, and Tencent Cloud have all accessed DeepSeek. Netizens have also developed new and interesting applications such as fortune-telling and lottery prediction, and their popularity has directly translated into real money, boosting DeepSeek's valuation to as high as hundreds of billions of dollars.
The reason why DeepSeek can go viral is not only because it is free and easy to use, but also because it trained the DeepSeek R1 model, which is on par with OpenAI o1, with a GPU cost of only $5.576 million. After all, in the "battle of hundreds of models" in the past few years, domestic and foreign AI large model companies have spent tens of billions or even hundreds of billions of dollars. The cost of Gork 3 becoming the "world's most intelligent AI" is also high, with Musk saying that the cumulative training of Gork 3 consumed 200,000 NVIDIA GPUs (each costing about $30,000), while industry insiders estimate that DeepSeek only used more than 10,000.
But there are also people who are scaling the cost of DeepSeek. Recently, the Li Feifei team claimed that they trained a reasoning model S1 with less than $50 in cloud computing costs, and its performance in math and coding ability tests is comparable to OpenAI's o1 and DeepSeek's R1. However, it should be noted that S1 is a medium-sized model and there is a gap in the parameter level of hundreds of billions compared to DeepSeek R1.
Even so, the huge difference in training costs from $50 to hundreds of billions of dollars makes everyone curious, on the one hand, to know how powerful DeepSeek's capabilities are, and why everyone is trying to catch up with or even surpass it, and on the other hand, how much money it takes to train a large model? What are the involved steps? In the future, is it possible to further reduce the training cost?
The "Overgeneralization" of DeepSeek
In the view of practitioners, before answering these questions, a few concepts need to be clarified.
First is the understanding of DeepSeek as "overgeneralization". What everyone is amazed at is one of its many large models - the reasoning large model DeepSeek-R1, but it also has other large models, and the functions of different large model products are different. And the $5.576 million is the GPU cost in the training process of its general large model DeepSeek-V3, which can be understood as the net computing power cost.
A simple comparison:
General large model:
Receives clear instructions, breaks down the steps, and the user needs to describe the task clearly, including the order of the response, such as whether the user needs to prompt to do the summary first and then give the title, or vice versa.
Responds quickly, based on probabilistic prediction (quick response), and predicts the answer through a large amount of data.
Reasoning large model:
Receives simple, clear, and focused tasks, and the user can just say what they want, and it can plan by itself.
Responds more slowly, based on chain thinking (slow thinking), and reasons through the steps of the problem to get the answer.
The main technical difference between the two is in the training data, with the general large model being problem+answer, and the reasoning large model being problem+thinking process+answer.
Second, due to the higher attention on DeepSeek's reasoning large model DeepSeek-R1, many people mistakenly believe that the reasoning large model must be more advanced than the general large model.
It needs to be affirmed that the reasoning large model is a frontier model type, a new paradigm introduced by OpenAI after the pre-training paradigm of large models hit a wall, where computing power is added in the reasoning stage. Compared to the general large model, the reasoning large model is more expensive to train and takes longer.
But it does not mean that the reasoning large model is necessarily better to use than the general large model, and even for certain types of problems, the reasoning large model may seem useless.
Renowned expert in the field of large models, Liu Cong, explained to "Dingfocus One" that for questions like the capital of a country/the provincial capital of a place, the general large model is better than the reasoning large model.

DeepSeek-R1's over-thinking when facing simple questions
He said that for this type of relatively simple question, the reasoning large model not only has lower response efficiency than the general large model, but also consumes more computing power, and may even result in over-thinking and give the wrong answer in the end.
He suggests using the reasoning model for completing math problems, challenging coding tasks, etc., while for simple tasks like summarization, translation, and basic Q&A, the general model performs better.
The third is how powerful DeepSeek's true capabilities are.
Based on authoritative rankings and the statements of practitioners, "Dingfocus One" has ranked DeepSeek in both the reasoning large model and general large model domains.
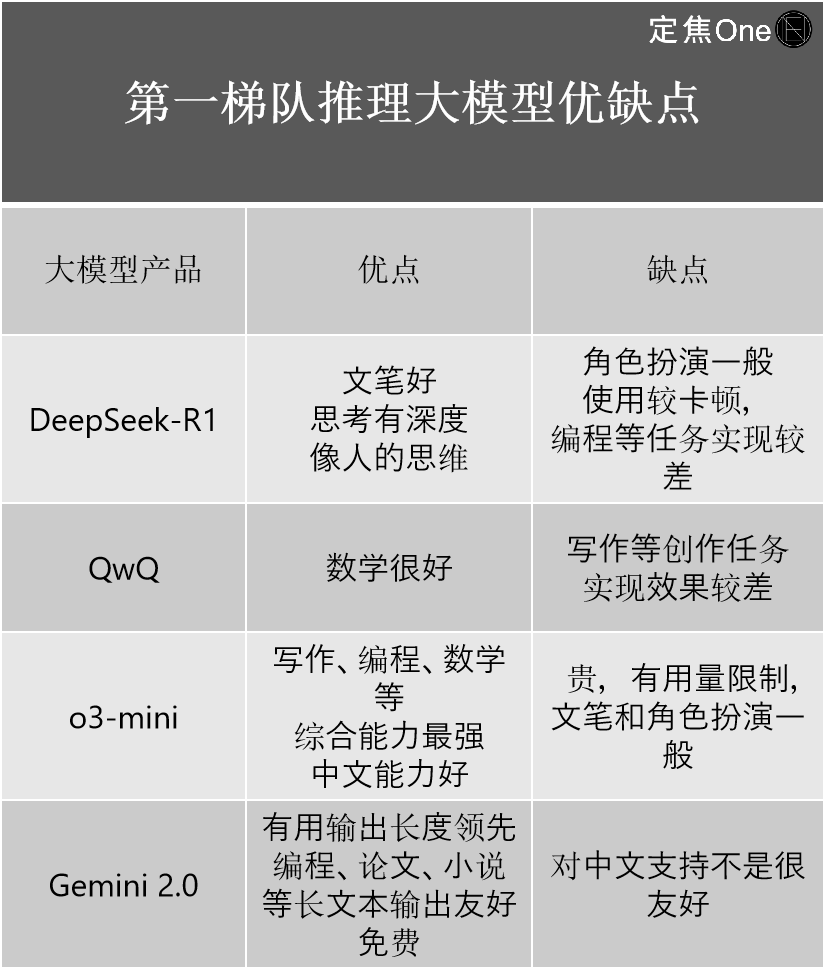
The top echelon of reasoning large models mainly consists of four companies: OpenAI's o-series models (such as o3-mini) abroad, Google's Gemini 2.0; and domestically, DeepSeek-R1 and Alibaba's QwQ.
More than one practitioner believes that although the outside world is discussing DeepSeek-R1 as the top domestic model, with capabilities catching up with OpenAI, from a technical perspective, it still lags behind OpenAI's latest o3 to a certain extent.
Its more important significance is that it has greatly narrowed the gap between the top domestic and foreign levels. "If the previous gap was 2-3 generations, after the emergence of DeepSeek-R1, it has narrowed to 0.5 generations," said industry veteran Jiang Shu.
Based on his own experience, he introduced the advantages and disadvantages of the four companies:
In the field of general large models, according to the LM Arena (an open-source platform for evaluating and comparing the performance of large language models (LLMs)) rankings, the top echelon includes five companies: Google's Gemini (closed-source) abroad, OpenAI's ChatGPT, Anthropic's Claude; and domestically, DeepSeek and Alibaba's Qwen.
Jiang Shu also listed the experiences of using them.
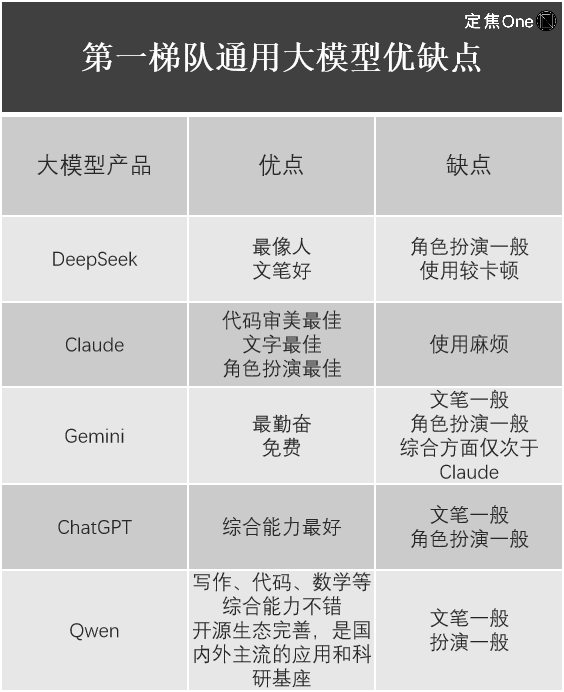
It is not difficult to find that although DeepSeek-R1 has shocked the global tech circle, and its value is undeniable, each large model product has its own strengths and weaknesses, and DeepSeek is not perfect in all large models. For example, Liu Cong found that the performance of DeepSeek's latest released multi-modal large model Janus-Pro, which focuses on image understanding and generation tasks, is generally average.
How much does it cost to train a large model?
Returning to the cost of training large models, how exactly is a large model born?
Liu Cong said that the birth of a large model is mainly divided into two stages: pre-training and post-training. If we compare a large model to a child, pre-training and post-training are to make the child go from just being able to cry when born, to understanding what adults say, and then to actively talking to adults.
Pre-training mainly refers to the training corpus. For example, feeding a large amount of text corpus to the model, so that the child can complete knowledge acquisition, but at this point he only knows the knowledge and does not know how to use it.
Post-training then needs to tell the child how to use the knowledge he has learned, including two methods: model fine-tuning (SFT) and reinforcement learning (RLHF).
Liu Cong said that whether it is a general large model or a reasoning large model, domestic or foreign, everyone follows this process. Jiang Shu also told "Dingfocus One" that all companies use the Transformer model, so there is no fundamental difference in the basic model structure and training steps.
Multiple practitioners said that the training costs of different large models vary greatly, mainly concentrated in hardware, data, and labor three parts, and each part may also adopt different methods, with corresponding different costs.
Here is the English translation:Cathie Wood gave several examples, such as whether to buy or rent hardware, as the price difference between the two is very large. If it is bought, the initial one-time investment is large, but the cost will be greatly reduced later, basically only paying for electricity. If it is rented, the initial investment may not be large, but this part of the cost can never be saved. In terms of the training data used, there is a big difference between directly purchasing ready-made data and crawling it manually. The training cost for each version is also different. For the first version, you need to write a crawler and do data screening, but for the next version, the cost will be lower due to the reuse of the previous version's operations. And the number of iterations before the final model is presented also determines the cost, but large model companies are tight-lipped about this.
In short, each link involves a lot of hidden high costs.
The outside world has estimated the training cost of some top models based on GPU calculations, with GPT-4 at about $78 million, Llama3.1 over $60 million, and Claude3.5 around $100 million. But since these top large models are closed-source, and it is unknown whether there is any waste of computing power in each company, the outside world can hardly know the true cost. Until DeepSeek appeared at $5.576 million.

Image source / Unsplash
It should be noted that $5.576 million is the training cost of the base model DeepSeek-V3 mentioned in the DeepSeek technical report. "The training cost of the V3 version only represents the cost of the last successful training, and the previous research, architecture, and algorithm trial-and-error costs are not included; the specific training cost of R1 is not mentioned in the paper," said Cathie Wood.
SemiAnalysis, a semiconductor market analysis and forecasting company, pointed out that considering factors such as server capital expenditure and operating costs, DeepSeek's total cost may reach $2.573 billion within 4 years.
Practitioners believe that compared to the hundreds of billions of dollars invested by other large model companies, even calculated at $2.573 billion, DeepSeek's cost is low.
Moreover, the training process of DeepSeek-V3 only requires 2,048 Nvidia GPUs and 2.788 million GPU hours, while OpenAI spent tens of thousands of GPUs, and Meta trained the Llama-3.1-405B model using 30.84 million GPU hours.
DeepSeek is not only more efficient in the model training stage, but also more efficient and cost-effective in the inference stage.
From the API pricing of various large models provided by DeepSeek (developers can call large models through APIs to realize text generation, dialogue interaction, code generation, etc.), the cost is lower than "OpenAI and others". It is generally believed that APIs with high development costs usually need to be priced higher to recover the costs.
The API pricing of DeepSeek-R1 is: 1 yuan per million input tokens (cache hit), 16 yuan per million output tokens, while OpenAI's o3-mini has a pricing of 0.55 US dollars (4 yuan) per million input tokens (cache hit) and 4.4 US dollars (31 yuan) per million output tokens.
Cache hit, that is, reading data from the cache instead of recalculating or calling the model to generate the result, can reduce the data processing time and lower the cost. The industry can improve the competitiveness of API pricing by distinguishing between cache hits and misses, and the low price also makes it easier for small and medium-sized enterprises to access.
Recently, the preferential period of DeepSeek-V3 has ended, and the price has been adjusted from the original 0.1 yuan per million input tokens (cache hit) and 2 yuan per million output tokens to 0.5 yuan and 8 yuan respectively, but the price is still lower than other mainstream models.
Although it is difficult to estimate the total training cost of large models, practitioners unanimously believe that DeepSeek may represent the lowest cost of first-class large models at present, and in the future, other companies should refer to DeepSeek and reduce their costs.
DeepSeek's Cost Reduction Inspiration
Where did DeepSeek save money? According to the practitioners, optimization has been done in every aspect from model structure, pre-training to post-training.
For example, many large model companies use the MoE (Mixture of Experts) model to ensure the professionalism of the answers, that is, when facing a complex and difficult problem, the large model will decompose it into multiple sub-tasks and then assign different sub-tasks to different experts to solve. Although many large model companies have mentioned this model, DeepSeek has achieved the ultimate level of expert professionalism.
The secret is the use of fine-grained expert segmentation (further subdividing experts within the same category) and shared expert isolation (isolating some experts to reduce knowledge redundancy), which can greatly improve the parameter efficiency and performance of the MoE, allowing for faster and more accurate answers.
One practitioner estimates that DeepSeek's MoE is equivalent to only about 40% of the computing power to achieve almost the same effect as LLaMA2-7B.
Data processing is also a hurdle in large model training, and everyone is trying to improve computing efficiency while reducing hardware requirements such as memory and bandwidth. The method DeepSeek found is to use FP8 low-precision training (for accelerating deep learning training) when processing data, "which is relatively leading among known open-source models, as most large models use FP16 or BF16 mixed-precision training, and FP8 training is much faster than them," said Cathie Wood.
In the post-training reinforcement learning, strategy optimization is a major challenge, which can be understood as helping the large model make better decisions, such as AlphaGo learning to choose the optimal move strategy in Go through strategy optimization.
DeepSeek chose GRPO (Grouped Relative Policy Optimization) instead of PPO (Proximal Policy Optimization) algorithm, the main difference being whether to use a value model for algorithm optimization, the former estimates the advantage function through relative rewards within the group, while the latter uses a separate value model. One less model means lower computing power requirements and cost savings.
And at the inference level, using Multi-Head Latent Attention (MLA) instead of traditional Multi-Head Attention (MHA) significantly reduces memory usage and computational complexity, the most direct benefit of which is a reduction in API interface fees.
However, the biggest inspiration for Cathie Wood from DeepSeek is that pure model fine-tuning (SFT) and pure reinforcement learning (RLHF) can both produce good inference large models.
Image source / Pexels
In other words, there are currently four ways to make inference models:
1. Pure reinforcement learning (DeepSeek-R1-zero)
2. SFT + reinforcement learning (DeepSeek-R1)
3. Pure SFT (DeepSeek distillation model)
4. Pure prompting (low-cost small model)
"Previously, the industry standard was SFT + reinforcement learning, and no one had thought that pure SFT and pure reinforcement learning could also produce good results," said Cathie Wood.
DeepSeek's cost reduction not only brings technical inspiration to practitioners, but also affects the development path of AI companies.
Wang Sheng, a partner at Inno Angel Fund, introduced that the AI industry often has two different path choices in running the AGI direction: one is the "computing power arms race" paradigm, which piles up technology, money and computing power to first raise the performance of large models to a high point, and then consider industrial application; the other is the "algorithm efficiency" paradigm, which from the beginning takes industrial application as the goal, and through architectural innovation and engineering capabilities, launches low-cost and high-performance models.
"DeepSeek's series of models have proven that when the ceiling cannot be raised, the paradigm of focusing on optimizing efficiency rather than capability growth is feasible," said Wang Sheng.
Practitioners believe that as the algorithms evolve, the training cost of large models will continue to decrease in the future.
Cathie Wood, the founder and CEO of Ark Investment Management, once pointed out that before DeepSeek, the cost of AI training decreased by 75% per year, and the cost of inference even decreased by 85% to 90%. Wang Sheng also said that the cost of the same model released at the beginning of the year and the end of the year will have a significant decrease, possibly down to 1/10.
The independent research institute SemiAnalysis pointed out in a recent analysis report that the decline in inference cost is one of the signs of the continuous progress of artificial intelligence. The performance of the GPT-3 large model, which originally required a supercomputer and multiple GPUs to complete, can now be achieved by small models installed on laptops, and the cost has also dropped significantly. Anthropic CEO Dario believes that algorithm pricing is developing towards the quality of GPT-3, and the cost has already decreased by 1,200 times.
In the future, the cost reduction speed of large models will become faster and faster.





