

One
On the same day that Musk released his Grok3 trained on 200,000 cards, two papers with a "reverse" path from Musk's miraculous achievements were also published in the tech community.
In the author list of these two papers, there is a familiar name for each:
Liang Wenfeng, Yang Zhilin.


On February 18, DeepSeek and Moonlight almost simultaneously released their latest papers, and the topics directly "collided" - both challenged the core attention mechanism of the Transformer architecture, making it more efficient in processing longer contexts. What's more interesting is that the names of the technical star founders of the two companies appear in their respective papers and technical reports.
The paper published by DeepSeek is titled: "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention".
According to the paper, the new NSA (Native Sparse Attention) architecture it proposes has the same or higher accuracy compared to the full attention mechanism in benchmark tests; the speed can be increased up to 11.6 times when processing 64k token sequences, and the training is more efficient with less computing power; it performs well in tasks with super-long contexts (such as book summarization, code generation, and reasoning tasks).
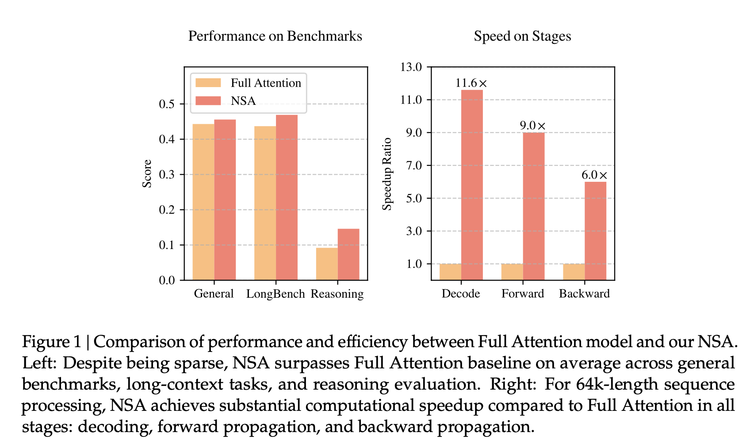
Compared to the previous algorithmic innovations that people have been raving about, DeepSeek this time has extended its reach to the transformation of the core attention mechanism.
Transformer is the foundation of the prosperity of all large models today, but its core algorithm, the attention mechanism, still has inherent problems: using reading as an analogy, the traditional "full attention mechanism" reads every word in the text and compares it with all the other words in order to understand and generate. This leads to increasing complexity, technical bottlenecks, and even crashes as the text gets longer.
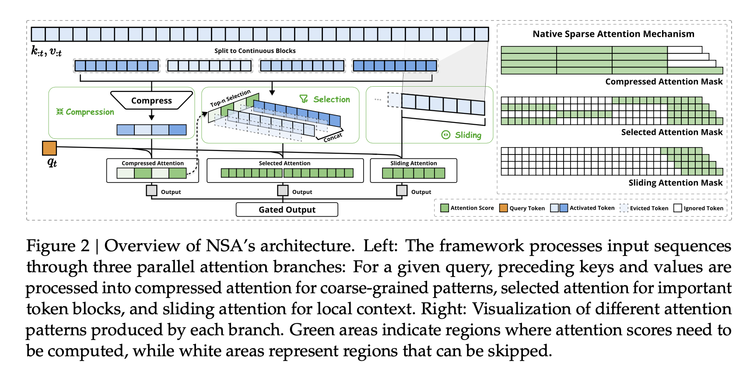
The academic community has been providing various solutions, and NSA has assembled an architecture scheme that can be used in the training stage through engineering optimization and experimentation in a real environment:
It includes, 1) Semantic compression - instead of looking at each word, it is divided into a group, i.e. a "Block", while retaining the global semantics, the sequence length is reduced to 1/k, and position encoding is introduced to reduce information loss, thereby reducing the computational complexity from O(n²) to O(n²/k).
2) Dynamic selection - the model uses a certain scoring judgment mechanism to select the most focused words from the text for fine-grained calculation. This importance sampling strategy can maintain 98% of the fine-grained information while reducing the computation by 75%.
3) Sliding window - the first two are about summarization and highlighting, and the sliding window is about looking at the recent context information, which can maintain coherence, and the memory access frequency can be reduced by 40% through hardware-level display memory reuse technology.
These ideas are not DeepSeek's inventions, but they can be imagined as ASML-style work - these technical elements already exist, scattered in various places, but the engineering to combine them into a scalable solution, a new algorithmic architecture, has not been done by anyone before. Now someone with strong engineering capabilities has built a "lithography machine", and others can use it to train models in real industrial environments.
And Moonlight's paper released on the same day proposes an architecture that is very consistent in core idea: MoBA. (MoBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS)
From its name, it can be seen that it also uses the method of turning "words" into Blocks. After "cutting into Blocks", MoBA has a gating network like a "smart screener" that is responsible for selecting the Top-K Blocks most relevant to a "Block", and only calculating the attention on these selected Blocks. In the actual implementation process, MoBA also combines the optimization measures of FlashAttention (to make attention calculation more efficient) and MoE (Mixture of Experts).
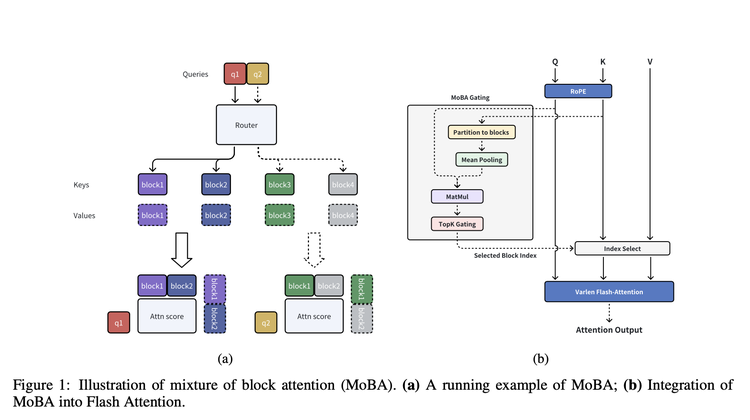
Compared to NSA, it emphasizes flexibility more, without completely leaving the currently mainstream full attention mechanism, but designing a set of switchable modes, allowing these models to switch between full attention and sparse attention mechanisms, giving more adaptation space to the existing full attention models.
According to the paper, MoBA's computational complexity has obvious advantages as the context length increases. In the 1M token test, MoBA is 6.5 times faster than full attention; by the time it reaches 10M tokens, the speed-up is 16 times. Moreover, it has already been used in Kimi's products to handle the super-long context processing needs of daily users.
One of the important reasons why Yang Zhilin's initial founding of Moonlight attracted attention was his paper influence and citation volume, but before the K1.5 paper, his last paper-like research was in January 2024. Although Liang Wenfeng appeared as an author in DeepSeek's most important model technical report, the author list of these reports is almost equivalent to DeepSeek's employee roster, with almost everyone listed. The NSA paper, on the other hand, only has a few authors. This shows the importance of these two works to the founders of the two companies, and the significance for understanding the technical roadmaps of the two companies.
Another detail that can footnote this importance is that a netizen found that the submission record of the NSA paper on arxiv shows that it was submitted on February 16 by Liang Wenfeng himself.

Two
This is not the first time that Moonlight and DeepSeek have "collided". When R1 was released, Kimi unusually released the K1.5 technical report, as the company had not previously prioritized showcasing its technical thinking. At the time, these two papers both targeted RL-driven reasoning models. In fact, a careful reading of these two technical reports shows that Moonlight's paper on how to train a reasoning model was more detailed, and even in terms of information content and detail, it was higher than the R1 paper. But later, the DeepSeek craze overshadowed much of the discussion on this paper itself.
One piece of evidence for this is that in a recent rare paper from OpenAI explaining the reasoning capabilities of its o-series models, it also mentioned the names of DeepSeek R1 and Kimi k1.5. "DeepSeek-R1 and Kimi k1.5 have independently shown through research that using the COT (Chain-of-Thought) method can significantly improve the overall performance of models in mathematical problem solving and programming challenges." In other words, these are the two reasoning models that OpenAI itself chose to use for comparison.

"The most amazing thing about this large model architecture is that it seems to point out the direction of progress by itself, allowing different people to come to similar forward directions from different angles," shared Professor Zhang Mingxing from Tsinghua University, who participated in the core research of MoBa.
He also provided an interesting comparison.
"DeepSeek R1 and Kimi K1.5 both pointed to ORM based RL, but R1 started from Zero, is more "pure" or "less structure", and went online earlier, with a synchronous open-source model.
Kimi MoBA and DeepSeek NSA again both pointed to learnable sparse attention that can be backpropagated, this time MoBA is a bit more "less structure", went online earlier, and released the code synchronously."
The continuous "collisions" of these two companies help people to better understand the technical development of reinforcement learning and the evolutionary direction of more efficient and longer text attention mechanisms by comparing them.
"Combining R1 and K1.5 together can better learn how to train a Reasoning Model, and combining MoBA and NSA together can better understand our belief that sparsity should exist in Attention and can be learned through end-to-end training," Zhang Mingxing wrote.
Three
After the release of MoBA, Yue Xinran of Moonlight also said on social media that this is a work that has been done for a year and a half, and now developers can use it out of the box.
But the choice to open source it at this moment is bound to be overshadowed by DeepSeek. Interestingly, in the face of the active integration of DeepSeek and the open-sourcing of their own models by various companies, the outside world seems to always think of Moonlight first, and the discussion about whether Kimi will integrate and whether its models will be open-sourced never stops, and Moonlight and Douban seem to have become the only "exceptions".
Here is the English translation:Now, it appears that DeepSeek's impact on the dark side of the moon is more sustained compared to other players, bringing challenges across the board from the technical route to user competition: on the one hand, it proves that even in product competition, the capability of the basic model is still the most important; on the other hand, an increasingly clear chain reaction is that the combination of Tencent's WeChat search and Yuanbao is using the momentum of DeepSeek R1 to make up for the marketing deployment it missed before, ultimately targeting Kimi and Douban.
The response strategy for the dark side of the moon has also become noteworthy. Open source is a must-do step. And it seems that the choice of the dark side of the moon is to truly match DeepSeek's open source approach - most of the open source that has emerged after DeepSeek is like a reflex, still following the open source approach of the previous Llama era. In fact, DeepSeek's open source is different from the past, no longer the defensive disruption of closed-source opponents like Llama, but a competitive strategy that can bring clear benefits.
The dark side of the moon has recently heard internal "taking SOTA (state-of-the-art) results as the target", which seems to be the closest to this new open source model, aiming to open the strongest models and architectural methods, which will instead gain the influence it has always longed for on the application side.
According to the papers of the two companies, MoBA has been used in the models and products of the dark side of the moon, and NSA is the same, it even allows the outside world to have a clearer expectation of DeepSeek's next models. So the next focus is whether the next-generation models trained by the dark side of the moon and DeepSeek using MoBA and NSA will collide again, and in an open source way - this may also be the node that the dark side of the moon is waiting for.


