

After DeepSeek just released the V3 model 0324 version update 24 hours ago, OpenAI seems to have a real sense of "not wanting to be outdone", announcing a new product launch preview in the early morning of March 26, Beijing time.

Although there were rumors speculating about a possible GPT-5 release before the official start, based on OpenAI's previous product release rhythm, this would not be a major update. However, the new version of Sora integrated into ChatGPT brought an unexpected "program effect" during the live broadcast.
Currently, the Sora integrated into ChatGPT is temporarily limited to image generation compared to the standalone application version, but according to OpenAI's introduction during the live broadcast, the model has made a qualitative leap.
According to the introduction, the development team used the GPT-4o "multi-modal" capabilities (a model that can generate text, images, audio, and video, or any type of data) as the basis for developing this version of Sora. Therefore, users can directly express their needs or even upload or take a photo to use as a prompt.
For example, during the live demonstration, they took a selfie of Sam Altman and two others with a mobile phone and requested Sora to generate an "anime-style version".
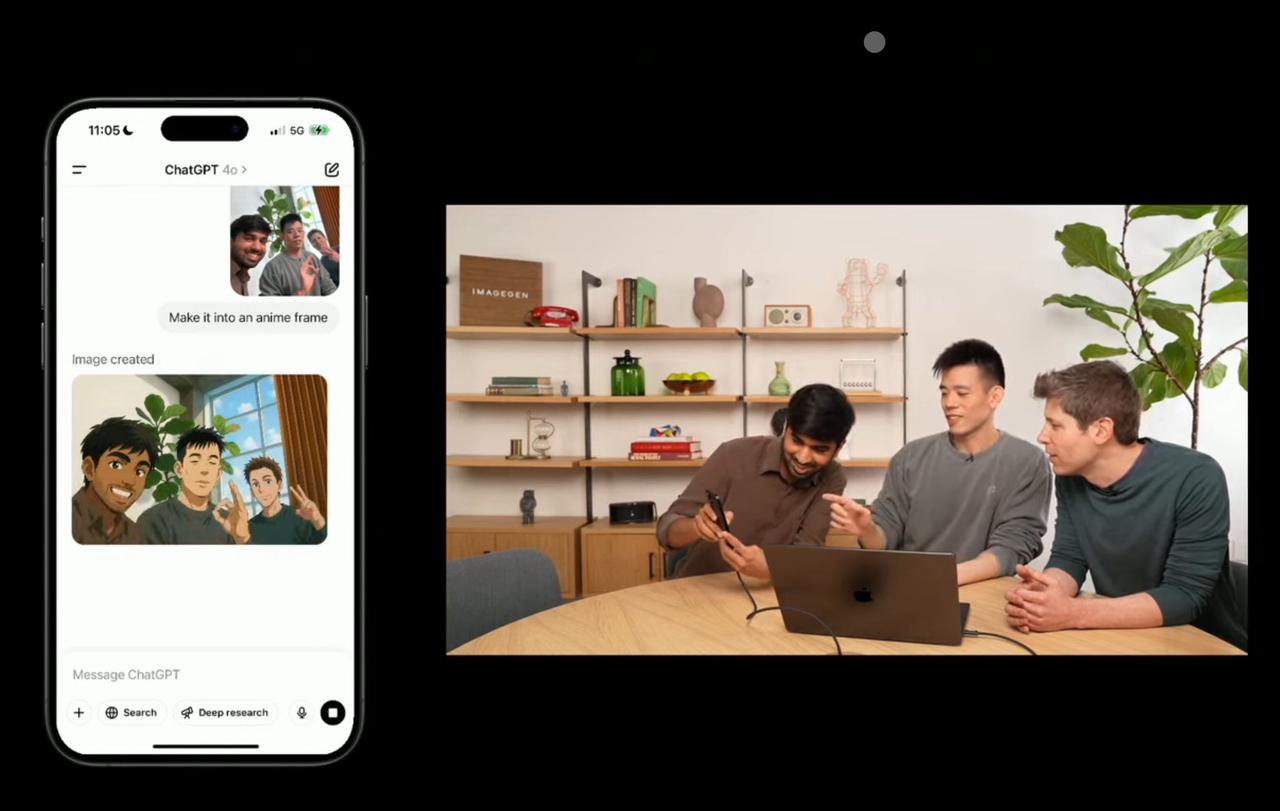
That's not all, they even demonstrated adding text to the image "Feel The AGI" (Feel the General Artificial Intelligence). They created the first meme of the new Sora version on-site.
This on-site generated meme not only had accurate and clear text but also accurately understood the essential elements of contemporary popular meme images, including bold text, and could be directly used as a meme in various groups.

Since it was the OpenAI official team leading the way, many users in the comments were also inspired to try feeding the same prompts to Grok with the same photo to generate similar content - but obviously, the effect was still far inferior to the new Sora, instead bringing a more humorous effect.

Besides creating meme images, OpenAI also demonstrated improvements in text rendering in the new Sora version, significantly increasing the success rate of generating coherent text without spelling errors on images.
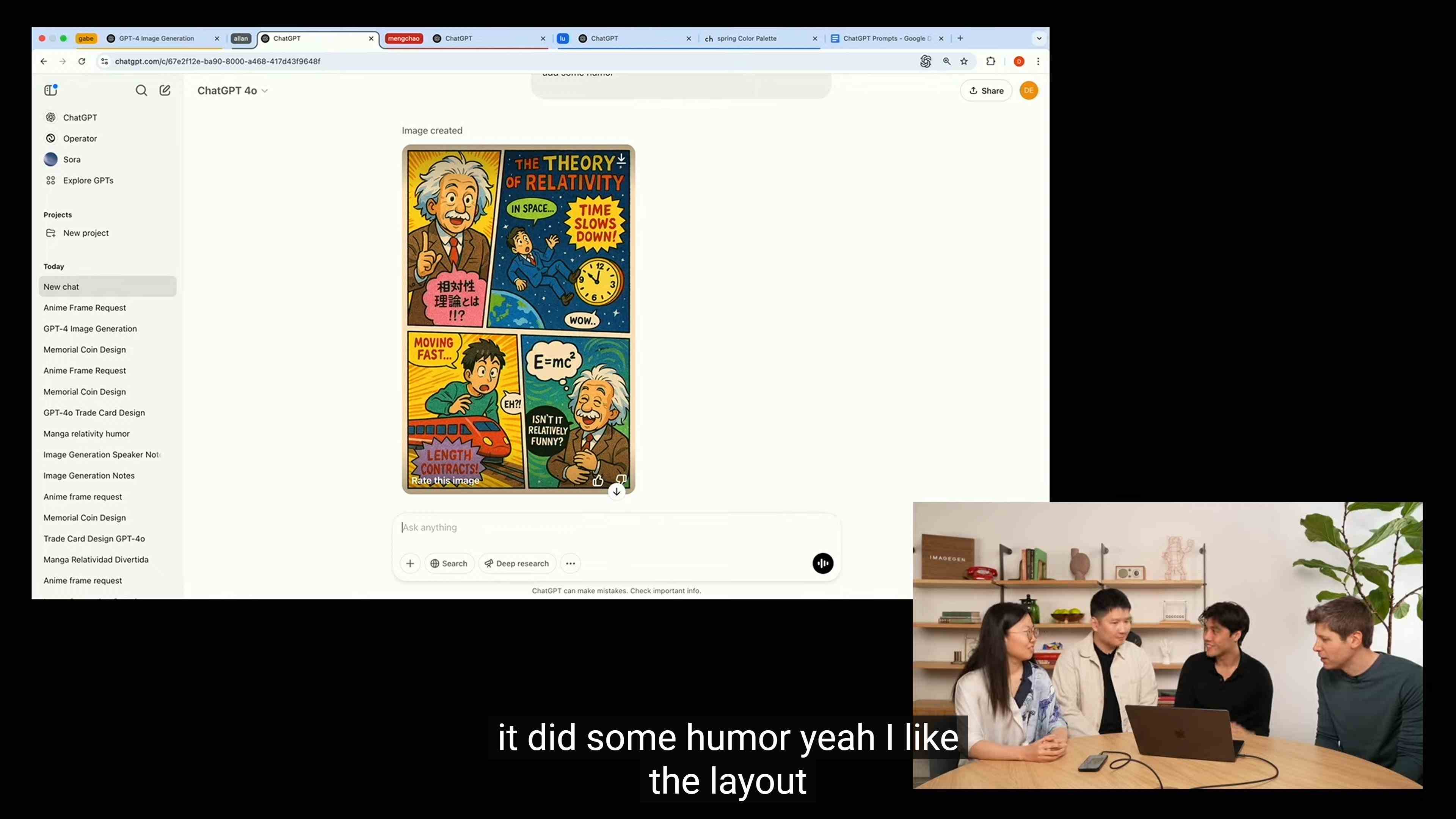
In another demonstration scenario, the OpenAI team had Sora generate a comic card to help understand relativity.
Unlike previous image generation models where text generation often became chaotic and even "AI-generated characters", the new Sora's native image generation has text without any obvious errors, and even generated very natural and smooth Japanese, unexpectedly causing a stir in the Japanese community.
For image generation models, correctly rendering text has been a huge challenge. If a subtitle or text element has spelling errors, the entire image could become unusable.
Additionally, in this case, OpenAI also demonstrated correct citation of "existing world knowledge" like relativity.

"If I draw an image, I am limited by my own skills... and all the world knowledge I have accumulated," explained Jackie Shannon, head of ChatGPT's multi-modal products, in a media interview.
"The model incorporates world knowledge, so when you ask to generate an image of Newton's prism experiment, you don't need to explain what the 'Newton's prism experiment' is, and you can get an accurate image."

Besides these model capability improvements mentioned in the live broadcast, OpenAI also stated that the new Sora significantly improved its ability to maintain correct relationships between attributes and objects. For example, a model with poor binding capabilities might generate a red star without a triangle when asked to generate a blue star and red triangle.
According to OpenAI, most existing image models are prone to "mistakes" in this aspect, especially when asked to render multiple items (usually 5 to 8), often confusing colors and shapes. The new Sora's image generation can correctly bind attributes of 15 to 20 objects, understanding their complex requirements without being misled, thereby significantly improving success rates.

In addition to these user experience improvements, another detail is that OpenAI has confirmed that the new Sora takes longer to generate images, but OpenAI believes this is a worthwhile trade-off.
"Although we certainly have room for improvement in latency... we believe the quality, functionality, and world knowledge of these generated images indeed compensate for the extra few seconds users need to wait," Shannon said.
Regarding safety issues in image generation - with multiple instances of fake celebrity inappropriate images, false images of hot events, and issues like Google Gemini removing original watermarks from last year to this year - the OpenAI team emphasized that the new Sora can remove photo watermarks, block the generation of sexually explicit deepfake images, and refuse related content requests. Additionally, all generated images will include standard C2PA metadata to mark that the image was created by OpenAI.
Currently, the new Sora image generation model integrated into ChatGPT is available to Pro and Plus subscription users, and OpenAI promises that the new Sora will also be provided to free versions and API in the near future.
Now, all I want to do is immediately have it help me create my own meme.





