If this essay is truncated by your email client, you can read the online version here. Also, please read this footnote: 1
INTRODUCTION
Data Is The New Moat
There is a growing consensus that data is not the new oil or the new gold; it’s something better. Data is the new moat.
We’re in the middle of a remarkable land-grab in software. LLMs are changing the way software is built, opening up vast new markets previously untouched by tech (especially in services), and making many incumbents look decidedly long in the tooth. This is a generational opportunity for companies to capture market share, and many startups are doing precisely that.
Startups riding the AI wave are reporting growth rates that have never been seen before. Bolt grew to $20M ARR in 2 months; Cursor went from $1M to $100M ARR in 21 months; OpenAI has billions in revenue (and remember, GPT-3 was released less than 5 years ago). Stories of hyper-growth abound.
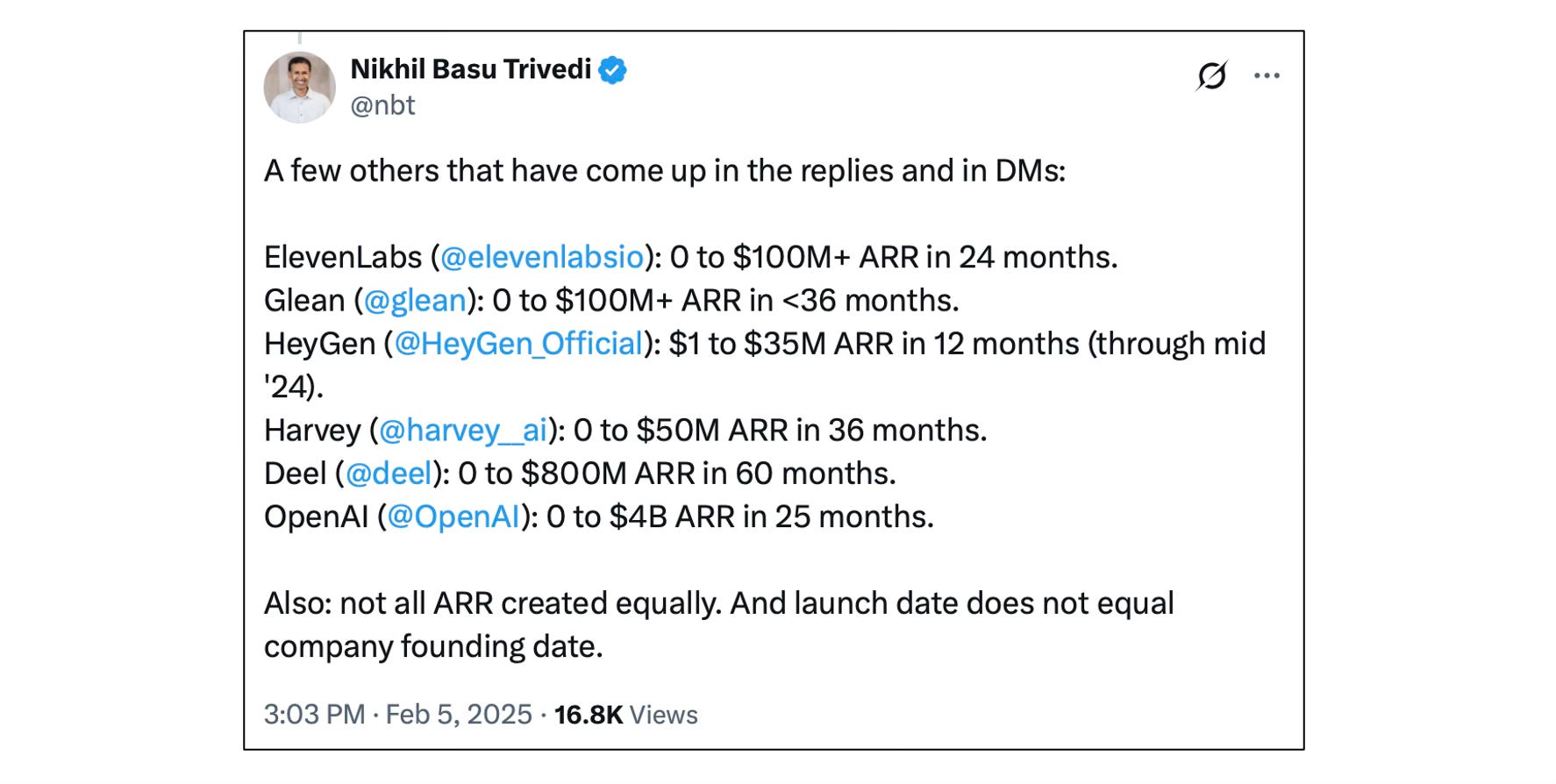
But so do cautionary tales. Competition is fierce: if you can build a crazy powerful app in a weekend, so can others. Any capabilities you create might be eaten by the next generation of foundation models. Churn is high, sometimes driven by disillusionment when your product doesn’t live up to the hype, sometimes driven by excitement when a competitor releases something that blows your solution away.
Massive opportunities; killer environment. What’s a company to do? Moats.
In warfare, moats are what prevent a castle from being stormed. In business, they’re what prevent a company from being overrun by competition, engulfment, or slow decay. Moats help you acquire and retain customers; they help you outperform and undercut rivals; they help you buy low and sell high, move fast and play bigger; they help you win, and keep winning.
Some moats are known and loved: network effects, user lock-in and switching costs, brand and positioning, process power, unique IP, economies of scale. Others are obscure or questionable.2
But with the advent of AI, a new kind of moat has come to prominence: the data moat. And this is not a coincidence.
AI companies have a special resonance with data moats, because data and AI are two sides of the same coin. LLMs require vast amounts of data, for training, fine-tuning, learning, reasoning. And LLMs unlock the value of data like almost no technology before. It’s a match made in business-model heaven.3
All the old moats are still valid — brand, for example, or network effects. You can (and should) build them. But they’re orthogonal to and independent of AI, in way that data moats are not. Data moats reinforce AI advantages, and AI advantages reinforce data moats.
What Even Is A Data Moat?
Everybody’s talking about how to build a data moat. Moats are in the air.4
Unfortunately, much of this conversation is ill-posed. There is an incredible amount of incomplete, inconsistent, or simply outdated thinking about data moats and how they work.
Classic mistakes in this vein include thinking data is a moat when it isn’t; relying too much on weak data moats; confusing other moats (like scale) for data moats; misunderstanding which attributes of data contribute to its “moatiness”; failing to distinguish between software moats and data moats; and not realizing when a data moat has lost its effectiveness. The Underpants Gnomes remain undefeated.5
This essay aims to bring some structure, rigour, and current best practices to the discussion. I’ll define a few different categories of data moats, explain when and how (and if!) they work, and explore some tactics to maximize their potency.
There will be case studies! Rampant speculation! Counter-intuitive conclusions! Clever turns of phrase which I hope go viral! And snarky asides!6 Read on.
Control And Loops
Let’s begin with some taxonomy.
I posit that there are two and exactly two categories of data moat. I call them data control and data loops; every type of data advantage can be put into one or both of these categories.
Data Control. If you have sole control of a critical asset, you have a moat. In the world of data, this control comes in various forms: uniqueness, aggregation, movement, usage, records, action, catalysis and more. We’ll learn about data control in Part One of this essay.
Data Loops. Many well-known business moats rely on positive feedback loops7 that accelerate some core business dynamic — for example, marketplace gravity, user network effects, protocol adoption. A number of data moats exhibit the same pattern. We’ll learn about data loops in Part Two of this essay,
PART ONE: DATA CONTROL
Controlling data really means controlling the value of data; moats arise when nobody else can access this value.
There are a few ways to do this: you can control the production and ownership of (unique) data; you can control the movement of data, either internally or externally; or you can control the usage of data, through technological or other means. Create value; transport value; extract value: each of these approaches can lead to a data moat.
A pre-condition here is that the data being controlled has to be meaningful. Otherwise, “control” is pointless: you can’t make money from tolls on a road going nowhere.
Unique And Proprietary Data
Okay, so you produce, capture or own unique data. Maybe the data’s about product usage, or customer behaviour, or industry dynamics, or something else. Do you have a moat? Probably not.
Unique data is neither necessary nor sufficient to establish a data moat. It’s not necessary because, as we shall see, there are other (often better) methods: controlling movement or usage of data, and building data loops. And it’s not sufficient, thanks to the “meaningfulness” criterion mentioned above. What does this criterion entail?
The data must offer substantial value to either you or your customers. A small delta in value means you can be overtaken by someone who outperforms you on other fronts, even without this data; a large delta means you cannot.
The data must be genuinely rivalrous. Your using it should prevent others from using it, or at least, from getting the same value from it.
The data must have no functional substitutes. Competitors should not be able to achieve similar outcomes no matter what data they use, similar or not.
Most datasets don’t satisfy even one of these conditions, let alone all three. But if all three conditions are met — if you have unique, high-value, irreplaceable data that only you can use — then you may have a moat.8
Historically, there have been a few ways to get such data:
As a by-product of your core business. (This is sometimes called exhaust data, by analogy with exhaust from a combustion engine). A good example here is stock market data, captured by NYSE and NASDAQ as a by-product of their core exchange business. But this is not a data moat. A larger core business might result in more (or better) exhaust data, but the converse is not true: NYSE’s data sales don’t give their exchange business any “extra” defensibility.9
Via process power. Many well-established data businesses follow this template. Think of Factset’s financial statement data, or Moody’s ratings data, or Nielsen’s media consumption data: they all depend on decades of expertise working with specific datasets and internalizing all their nuances. This is a moat; whether you want to call it a data moat or a process moat is a matter of semantics.
Through brute force investment of time and resources. Some examples of this pattern include search engines crawling the web, logistics and delivery firms mapping roads, and robotaxis recording driver-environment interactions. In each case, companies acquire data that becomes the foundation of their technology and hence their business model, that others cannot easily replicate. These are genuine data moats. But …
Brute Force Is Dead ...
The business theory behind brute force is “my capex is your barrier to entry”. Firms spend time and resources acquiring data before their rivals do, and use that data to gain market dominance.
Unfortunately, this works less well these days:
LLMs make data acquisition easier. Not just a little easier, orders of magnitude easier. You don’t need 100s of curators working 1000s of hours, just tell an AI agent to go get the data for you. Companies that spent years building complex human-mediated data pipelines must now contend with upstarts who can replicate 99% of their work for 1% of the cost. Synthetic data is another end-run around brute-force methods.10
Capital for data acquisition is cheap. Funding markets have fully internalized “the bitter lesson” and “the unreasonable effectiveness of data”. As a result, the capital to finance brute force data acquisition is cheaper than ever. Brute force is ultimately a bet on market timing and the cost of capital; change those, and the tactic vaporizes.11
Knowledge diffuses, capabilities increase. The planet-scale infrastructure that Google built in the 2000s, that allowed them to crawl and index the entire internet fast, was a major moat for them (though PageRank gets all the credit). Today, there are dozens of firms who can do the same, and much cheaper. Knowledge diffuses, tools improve, hyperscalers service-ify anything computable, and Moore’s Law marches inexorably onwards. Yesterday’s edge is today’s commodity.
Using an expansive definition of “data” puts this effect in stark relief. Studio Ghibli spent decades painstakingly perfecting a gorgeous visual style that no other animation studio could replicate: the very essence of brute force to generate unique content.
And then last month, ChatGPT blew the doors open for anybody to create their own Ghibli-fied art.

What this implies for creativity, intellectual property, democratization and artist economics is beyond the scope of this essay, but the underlying theme — that LLMs make mere “effort” less of a moat — is clear.
... Long Live Brute Force!
So are moats from brute force data acquisition a thing of the past? Not quite. There are still a few cases where brute force has its place:
In industries where that last 1% of accuracy or coverage or quality makes a meaningful difference — for example, finance. (And maybe art! TBD.)
Upstream of LLMs — for example, labelling data for LLMs to train on (Scale, Mercor, and friends), synthetic data pipelines, proprietary evals and so on.
In domains where LLMs are currently disadvantaged — for example, ‘real world’ data acquisition — audio, video, physics, bio. (This won’t last, btw) (which is also why there’s a land-grab happening here).
The other interesting play here is to recognize that sure, brute force isn’t a long-term moat, but if you have a funding advantage, you can use it to establish first-mover advantage, and then find your moat elsewhere — perhaps via workflow lock-in, or non-data network effects, or platform status, or brand. We’ll come back to this point.
Fragmented Data
A second powerful way to control data is to be the clearinghouse; the central repository that unifies fragmented data assets or data value.
This is a well-known pattern for data businesses; indeed, it’s probably the default mode for them. Think of Bloomberg, LexisNexis and CoStar: clearinghouses for financial, legal and real-estate data, respectively.
The very best clearinghouses add so much value to their fragmented source data — aggregating, harmonizing, licensing, transforming — that they essentially create new proprietary data value of their own. In other words, datasets that are low-value and commoditized in isolation, become high-value and unique in aggregate.
Clearinghouse / unification is a genuine data moat, combining elements of uniqueness, process power and brute force. And it’s not just for specialist data businesses! An interesting recent phenomenon is the emergence of a similar pattern for non-data businesses.
The idea is to aggregate / unify fragmented data, but then monetize it through a software offering. Here are some examples:
Rippling, Gusto and Remote.com aggregate regulatory data on payroll, contractors, benefits, tax etc. from dozens of countries. This allows them to offer “unified global payroll” as a service.
Stripe and Adyen do the same thing for “global payment processing”, again incorporating local rules and regulations on tax, authentication, KYC and AML, data privacy, reporting, dispute resolution etc., not to mention local customer habits and preferences.
Aggregators like Kayak and Skyscanner, and OTAs like Expedia and Booking unify flight information, prices, seats and other travel data from multiple airlines, from GDS providers, and from each other, but they don’t sell the data. Instead, OTAs sell tickets, while aggregators charge referral fees.
Zapier and Plaid aggregate information on “interfaces”, for SaaS tools and bank accounts respectively, which they can then offer unified access to. Plaid wraps multiple bank websites into a single API; Zapier wraps multiple SaaS APIs into a single no-code tool.
Numeral and Quandri, both early stage startups, focus on state-by-state sales tax and personal insurance lines, respectively. These are highly fragmented regimes with lots of interaction effects, making data unification super valuable.
In each case, the data collected is both essential to the business offering, and difficult for others to collect: a data moat.
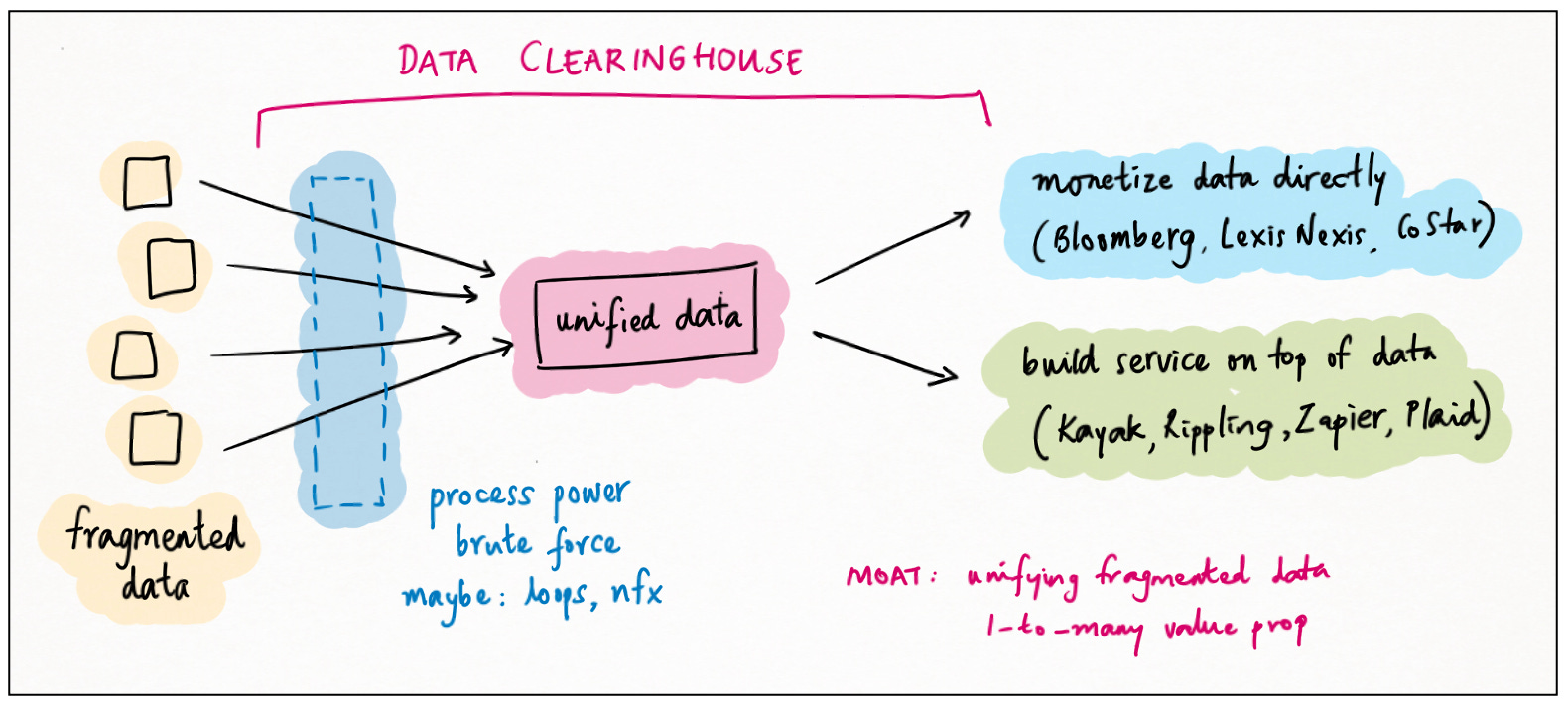
There’s a subtlety here. Firms like Airbnb, Shopify and Uber also collect data from around the world, but their customers don’t really care: any individual transaction is localized, and doesn’t benefit from aggregation. For clearinghouse effects to kick in, there needs to be a one-to-many relationship between the customer use case and the fragmented data.
Information Produces Action
Zooming out, what are we unifying here? Data, yes, but which data, and why?
Essentially, this is data that is a substrate for action. Rules and regulations have to be complied with, and they’re mostly deterministic: they lead directly to action. Flight info is both necessary and sufficient for the action of booking tickets; sales intel likewise for conducting outreach. Information produces action.12
Data unification is genuinely hard, which makes it a good moat. And data unification with an action layer on top often requires domain specialization, which makes it even moatier.
Sales enrichment shows how the frontier changes with time. The progression from D&B to Clearbit to ZoomInfo to Apollo to Clay is a story of value being captured from unifying fragmented data, making it API-accessible, exploiting network effects, adding workflows, and layering in AI actions, respectively.
Controlling Data Movement
This is a blurry category. Partly because of boundaries: where does data movement end, and data usage begin? And partly because of overlaps: companies with this type of control often achieve it via a combination of tactics, both data and non-data. Let’s look at some examples!
Visa has perhaps the single most famous network effect in all of business13. An intriguing (and perhaps provocative) claim is that their network effect is largely based on the control of data movement.
Consider: when I buy something with my credit card, money doesn’t actually flow. Instead, data flows: customer name and verification, transaction details, credit limits, outstanding balances, merchant and bank IDs, payment schedules. The money flows much later, and not 1-for-1 either.
The Visa network orchestrates all of this — across consumer, merchant, payment gateway, payment processor, acquiring bank, issuing bank, and more. The nodes and edges are the network effect; the knowledge (and control) of these nodes and edges is the data moat.
Any middleman business is vulnerable to disintermediation. In Visa’s case, merchants could communicate directly with banks to inquire about customer credit scores. But they don’t! Visa controls that interaction. Visa controls almost all data movement across the network. Abstracting away the (immense) complexity of the network is precisely what brings participants on board and keeps them from defecting; in a very real way, data control underlies the network effect.
Amadeus and Sabre are like specialized Visas for the travel industry, controlling the flow of data (inventory, bookings, identities) across airlines, hotels, car rentals, travel agents and aggregators, and of course travellers. Change Healthcare is a Visa for the healthcare industry, controlling the flow of data (and payments) between patients, healthcare providers, insurance companies, and government payers programs.
Businesses built on controlling external data movement are lucrative, but rare. More common are businesses that manage the flow of data internally for their clients. Do they have moats?
Usually, no. Managing the movement of data is not the same as controlling it. Moving data around is what 99% of software tools do, and most such tools self-evidently do not have moats.
The exception is data flow in highly regulated industries. In healthcare, for example, patient data is highly sensitive and you can’t just access it or move it around willy-nilly. So you have firms like Epic, that specialize in managing internal data access (this is also a system-of-record effect; see below), and firms like Datavant, that specialize in transporting data between organizations while remaining secure and privacy-compliant (via a data-standards effect; see below again). It’s not so easy to rip these out: there’s limited upside and large downside, so most clients stick instead of twisting.14
Data Usage
The final type of data control is the most powerful: when you control the usage of data. This is a large sub-category, encompassing systems of record and action, catalyst data, and exogenous data moats.
System Of Record
System of Record (“SoR”) is one of the oldest, best-known and most effective data moats.
In any large organization, information is scattered. It’s scattered across excel files and databases, emails and slack channels, PDFs and decks, user manuals and policy handbooks, contracts and filings.
There is substantial defensibility in owning the platform that collates all this scattered information. Such a platform is called a “system of record”, and the goal is for it to become the “single source of truth” for the organization. Data is piped into the SoR; queries are addressed to the SoR; answers come from the SoR. If it’s in the SoR, you can assume it’s true; if it isn’t, you cannot.15
The canonical example of a SoR is Salesforce, which collates everything businesses need to know about their customer and sales pipelines: dates, contact information, interaction history, pipeline stage, expected value, progress from opportunity to close, marketing campaigns, customer service and case management, and more (much much more). Entire sales orgs run on Salesforce; they cannot run without it.
Salesforce has analogies in other domains. Indeed, this is typical for SoRs. It’s impractical and inefficient to unify all an organization’s data in a single SoR; instead, there are separate SoRs for each function. Salesforce is aimed at the sales function; Oracle does financial management, Workday does human resources, Quickbooks does accounting, Ariba does supply chain and so on. Each of these SoRs acts as the single source of truth for their specific function.161718
It’s instructive to look at the founding years of some of these SoR companies:
SAP: 1972
Oracle: 1977
Epic: 1979
Quickbooks: 1983
Ariba: 1996
Zoho: 1996
Salesforce: 1999
That’s pretty staggering. These are incredibly long-lived businesses — especially given the pace of change in software; they must have incredible moats.
Why Are SoRs So Sticky?
Salesforce is not, shall we say, a widely loved product. Nobody is passionate about their Salesforce instance. But they can’t live without it; Salesforce is as sticky as hell.
Why so? Because Salesforce controls data usage. If you need “accurate” data about your prospects and customers you have to get it from Salesforce19. Without Salesforce, you can’t do anything: you can’t email prospects, update their status, understand their needs, close a contract, support them post-close, model your pipeline, run a campaign, anything. Salesforce has a monopoly on your internal sales data.
What’s more, this privileged position means that most Salesforce instances have years of “workflow barnacles” adhering to them. These are both procedural: rules that sales and marketing and customer success staff have to follow — and technological: Salesforce has a whole app store’s worth of third-party tools to read, write, modify, visualize, present, and analyze its data.
Salesforce isn’t great, but the thought of how much work it would take to rip out an instance, export all its data, load it elsewhere, replicate all that app functionality, transition all the users, and get back to full productive flow, intimidates almost all switchers. And this goes for most at-scale SoRs, which is why they’re so moated.20
Sticky No More?
And then came LLMs. It turns out that exporting data from a SoR is just the kind of tedious task that AI agents excel at.
One of my favourite go-to-market motions from recent years is where would-be SoR disruptors offer to do all the migration work themselves: we’ll export the data, put it into the new system, add in new app hooks, you name it. The key insight here is that this is not a “risk”, it’s just a “cost”, and vendors are happy to pay that cost in return for years of LTV.
Ironically, it’s probably better for this GTM if the cost doesn’t go down too much. The difficulty of migrating SoRs leads to low churn rates and high LTVs, which justifies the investment in doing the migration work as a vendor — but if migration costs drop too far, others can do the same to you; churn will tick back up, meaning LTVs drop, and soon you’re in a race to the bottom. Data viscosity is your friend, until it isn’t.
Systems Of Action
Systems of Record have a monopoly on internal data. This control makes them both valuable and defensible. But what if they could do more?
After all, the value of data lies, solely and entirely, in the value of what can be done with it. You don’t want your SoR to be the place where data goes to die21 ; you want to act on the data.
This thought leads to the next, perhaps even more powerful type of data moat: the System of Action (“SoA”).
Systems of Action don’t just store data passively; they enable actions on top of it. The key, and what sets SoAs apart from SoRs, is how specific these actions are: how well the action layer coheres with the data layer and the user function.
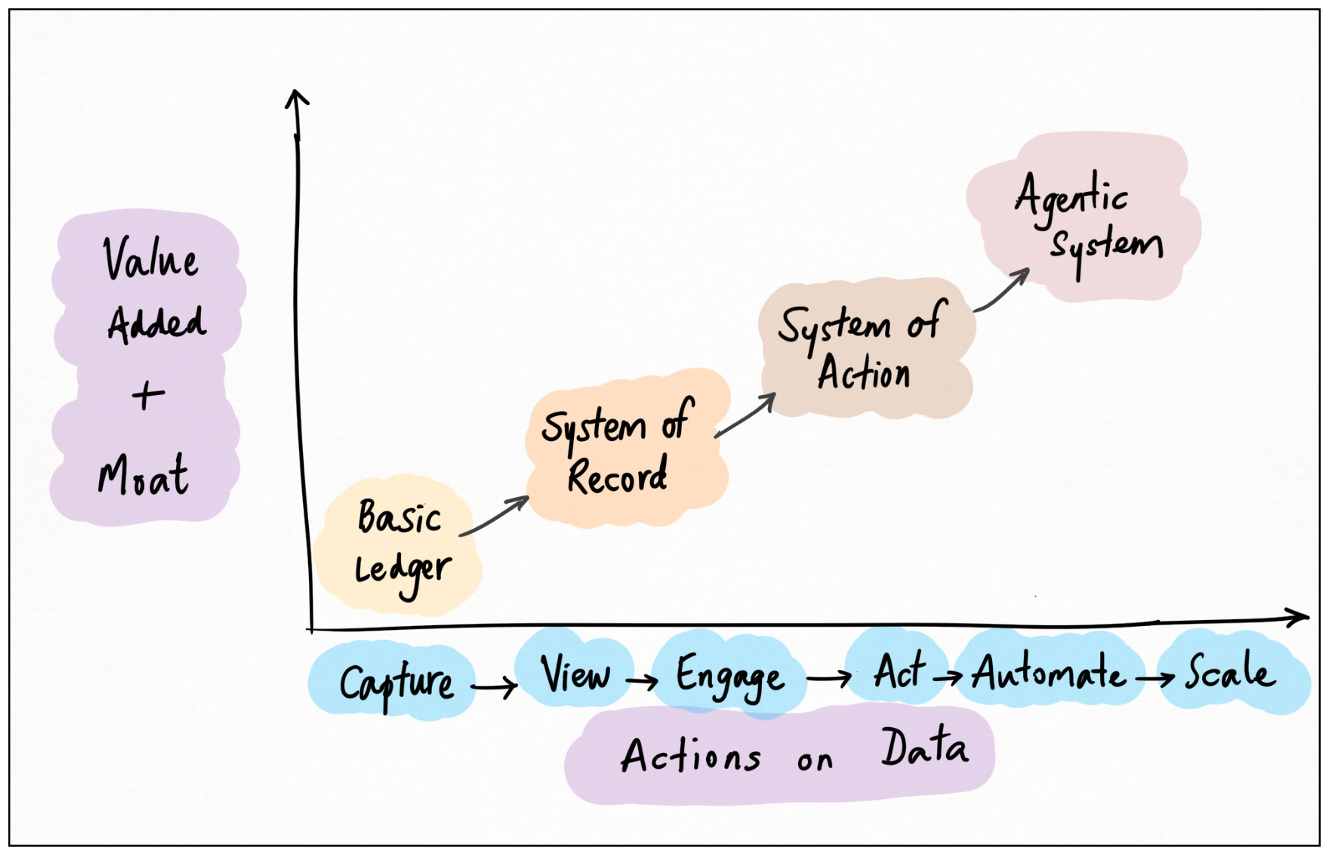
An example will make this clear. Consider “version control” — the process of maintaining a software code base. This is a classic System of Record: you want a centralized repository of all your source code with no ambiguity about what’s in production, what’s under development, and what’s deprecated. The earliest version control systems did this, and not much more; they were essentially just file management systems.
Over time, it became clear that version control required specialized hooks corresponding to the needs of code management: “locking” (so two programmers don’t work on the same file at the same time), “deltas” (store only the differences between successive versions, for efficiency), “repos” (manage groups of files instead of piecemeal), and “checkin/checkout” (another way to solve the conflicts problem). These were still SoR-ish; still fundamentally based on managing records.
But as codebases (and programming teams) expanded, even more functions became necessary. Modern version control systems offer atomic commits, complex branching logic, pull requests, “blame” and other collaboration features, hosting, CI/CD integrations, social profiles, metadata and asset management, co-pilots, and much more. Calling Github or Gitlab a mere SoR vastly undersells how tightly embedded — and finely tuned these systems are with every aspect of a programmer’s productive life. Systems of Action.
Agentic Systems
The obvious next step is for the system to take action itself. Wait ... whose music is that I hear?

Enter LLMs.
Systems-of-record store data; systems-of-action empower humans to act on data; systems-of-agents act on data themselves.
Let’s continue with the example above. What’s the primary action that humans take, on top of a software SoR / code repository? Why, programming, of course!
It turns out that LLMs are very very good at programming.
Possibly the hottest area within the supernova that is AI, is LLM code agents. Multiple firms are staking out this space, each with different lines of attack: “virtual junior devs” like Devin, in-IDE tools like Replit’s Ghostwriter, workflow solutions like Cursor, Bolt and Lovable, and of course SoR-level agents like Github Co-pilot.
Which approach will win? That’s the ten-billion-dollar question22 . I like this summary of the disruptor thesis:
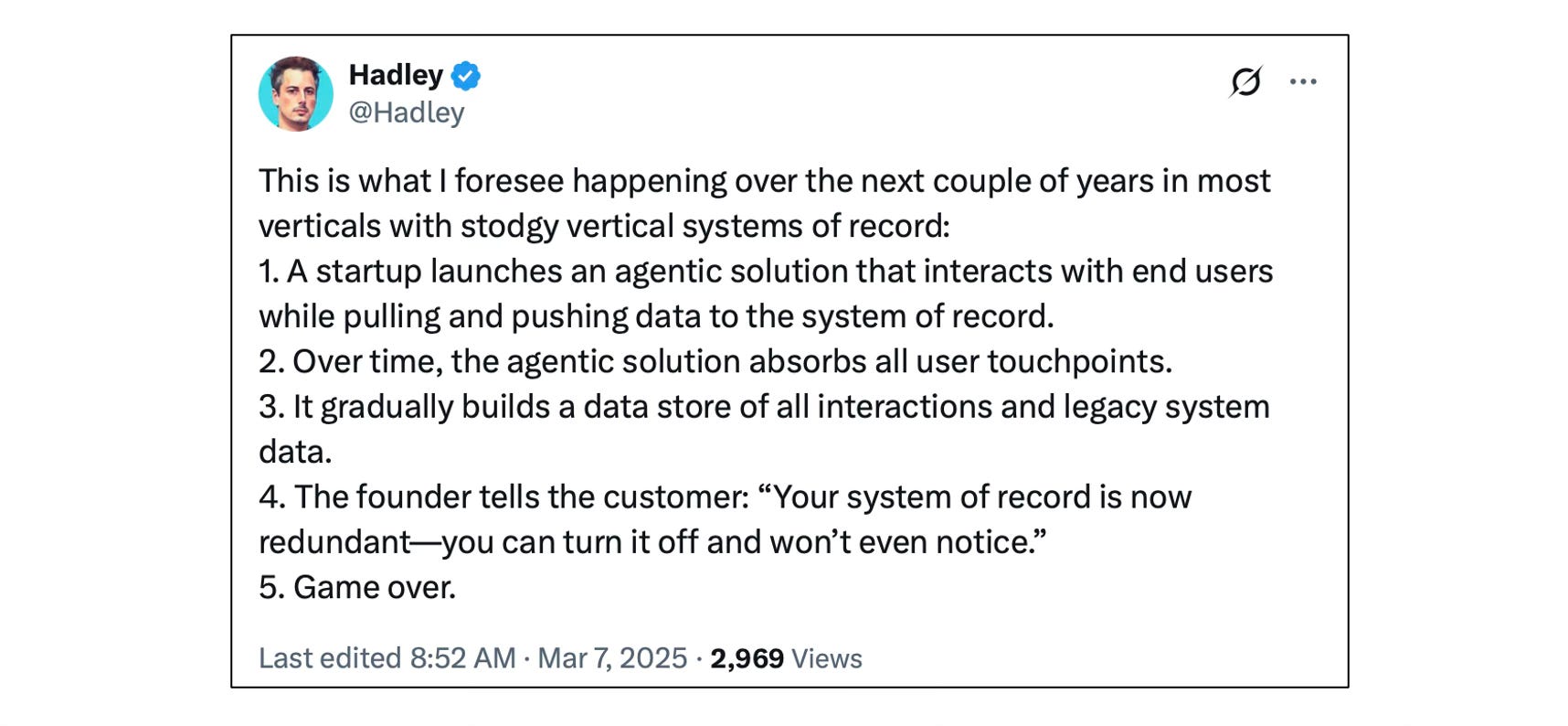
The counter-thesis is that SoR owners will block these apps, build them on their own, and fast-follow any user-facing improvements; and their head-starts in data and distribution will suffice to win the market.23
Exogenous Control
The next set of data moats is a catch-all category that I call exogenous control. In this pattern, you control the usage of data, not through any attribute of the data itself, nor even of the software that manages the data, but instead through external carrots or sticks. Here are some examples:
IP Rights: it doesn’t matter if the data is unique, or fragmented, in a SoR, protected by process power, or none of the above: if you have exclusive IP rights to its usage, you control it. Consider the S&P 500 Index: the underlying data is public, and the index itself is trivially easy to replicate, yet S&P Global makes ~$1B a year from licensing it — to asset managers (for benchmarking and ETFs), exchanges (for index-linked derivatives) and banks (for structured products).24
Contractual Monopolies: where you corner a primary data source via a favourable contract. Impossible in an efficient market, but data markets are not efficient; datasets are often (massively) mispriced. Unfortunately, this moat is temporary: if the data turns out to hold value, the contract will almost certainly get renegotiated on renewal. The best strategy here is to use your contractual moat to buy time to establish other sources of defensibility; IQVIA did precisely this for pharmacy data, while Neustar failed to do this for telecom data.
Regulatory and Compliance Moats: If the government mandates that people use a particular dataset, that’s a moat for the company owning, controlling, or implementing that data. A good case study here is the ENERGY STAR program: companies like ICFI, Leidos, DNV and Guidehouse make massive annual revenue providing these certifications to both government and private sector customers. Similar patterns exist for other programs like CAFE, air and water quality, FDA labeling ...
You’ll notice that exogenous control is often linked to government action. And government action is strongly inertial: hard to get started, but even harder to stop once started. State-sponsored data moats! 25
Catalyst Data
A specific flavour of unique data that’s worth calling out is catalyst data: data whose value comes from enabling or activating the usage of other data. This category is interesting because it’s a type of “indirect control” — you don’t need to control the enabled data directly, it may not be unique or proprietary to you, but you do control the ability to extract value from it — which means you can capture disproportionate economics.
Here are a few examples; in each case, “activates” is a synonym for “materially increases the value of”.
Google: user intent data activates search results data
Amazon: purchase history data activates product listings data
Acxiom: customer profile data activates basic marketing lists
Any social media company: viewer history activates new content
CUSIP, DUNS, LiveRamp, Datavant: unique identifiers activate siloed intel
FICO, Nielsen, ratings agencies, IQVIA: consensus benchmarks activate unanchored performance data
In each example, the second dataset has some baseline value in itself, but is made very much more valuable by the addition of the first. Indeed, you could argue that the above companies grew to dominate their respective industries precisely because they were the first to figure out how to unlock the value of the “enabled” datasets.26
An interesting aspect of catalyst data is that, empirically, it seems to result in winner-take-all or at least winner-take-most markets. This is partly survivorship bias: after all, you never hear of the catalyst datasets that don’t result in huge outcomes.
But it also reflect two patterns. First, catalyst data, when it works, tends to work really well — it adds substantial value to (untapped but often very lucrative) data assets. Second, catalyst data often works in sync with various data loops: industry standards, consensus benchmarks, user network effects and so on. We’ll explore this in more detail later in this essay.
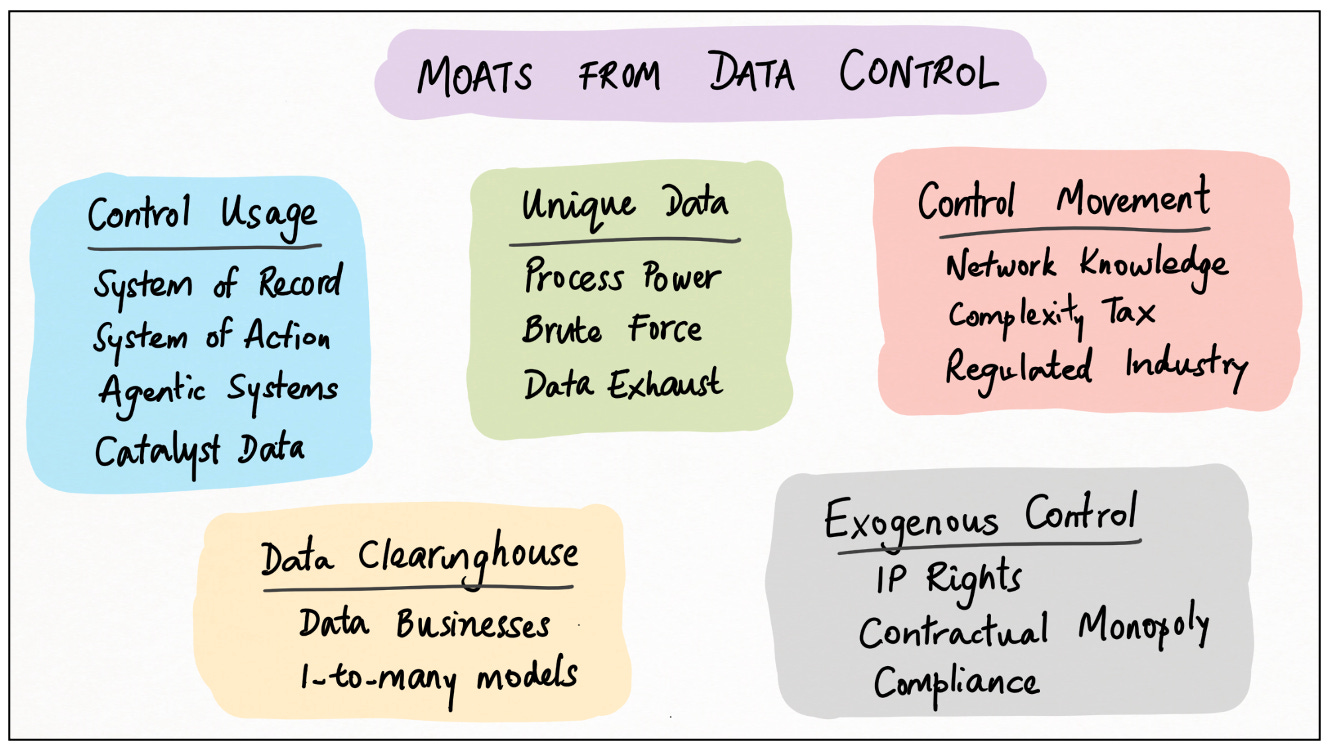
Data Control, Summarized
Here’s a handy chart summarizing what we’ve learned so far:
Interlude
We’re about halfway through this essay. If you haven’t subscribed to my newsletter yet, now is a great time to do so.
I write infrequent, in-depth, original explorations of topics that I have substantial professional expertise in: data, investing, and startups. Learn more here.
PART TWO: DATA LOOPS
The second major category of data moat is the data loop: a positive feedback process that links data and business value in a virtuous cycle. Data improves the business, and the business improves the data (for some value of the word “improve”), and the flywheel spins sufficiently fast that no competitor can catch up.
This, for many, is the most familiar form of data moat27. It’s also the most misunderstood. Some data loops make strong and certain moats. Others are weak, have limited scale, or hidden vulnerabilities. Still others are effective, but they’re not data moats at all; they rely on scale or network effects, and you could take the data part out with no loss.
There are three main families of data loop: the quantity loop, the learning loop, and the usage/value loop. Let’s dig deeper into each of these.
Quantity Loops
The quantity loop is the simplest family of data loop: data attracts data. This can occur through quite a few different mechanisms:
User-Generated-Content (UGC) Loop
This is the loop that drives Facebook, Youtube, Instagram, TikTok, X, and even LinkedIn. All these platforms host user-generated content for free: photos, videos, posts, resumes. This content attracts other users, who post even more content. The more content, the more users; also, the more content, the better the recommendations, and hence again, the more users. The presence of all these users (and their attention!) attracts advertisers, who subsidize all of this.
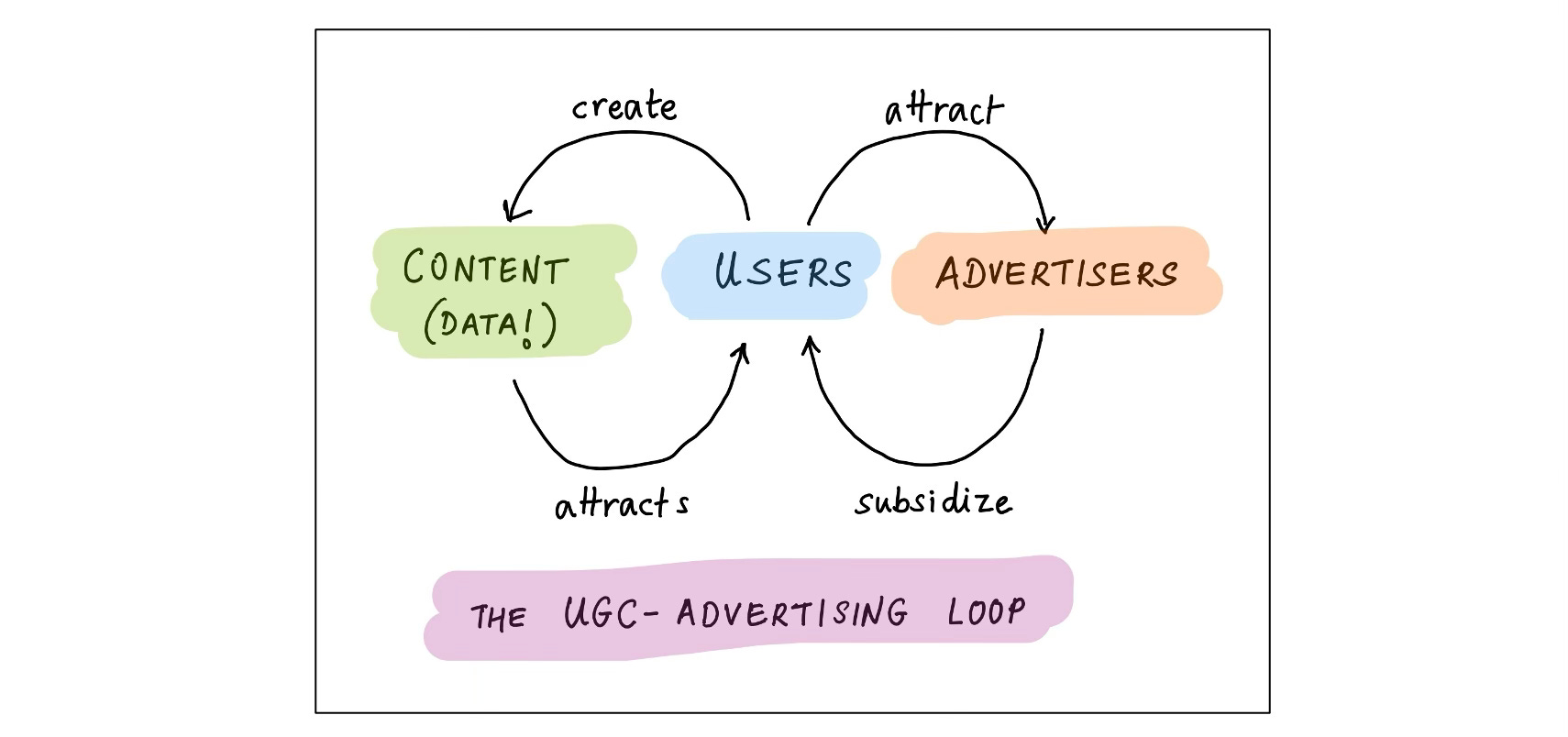
Content, of course, is just another word for data. This is a perfect data quantity loop, and once it reaches maturity, both lucrative and very hard to displace.
Equally fascinating are the firms that fizzled after reaching non-trivial scale using this loop. Consider MySpace, Tumblr, Quora, Vine, Digg, and perhaps Stack Overflow28. What happened to their (supposed) data moats?
The reasons are varied — failure is overdetermined! — disastrous M&A (MySpace by News Corp, Tumblr by Yahoo), failure to monetize effectively (Quora’s paywall), self-inflicted wounds (Tumblr’s NSFW ban), product missteps and technical debt (most of them), and competing with the apex predator that is Facebook (all of them). 2930
But fundamentally, these are just triggers. The problem with the UGC data loop is that it can reverse just as fast as it builds. Everybody goes where the lights are brightest; and conversely, everybody flees the ghost town. Missteps, if not quickly reversed, become death sentences; momentum is a fickle friend. So this moat is deceptive: more vulnerable than it appears.
Search-Engine-Optimization (SEO) Loop
Once scaled, the classic UGC loop tends to lead to “walled gardens” of content, that users never leave or indeed want to leave. But there’s another, very similar loop where users are constantly re-acquired, and SEO is the engine of this re-acquisition.
This is the SEO data loop. Users create content, or the platform itself generates content programmatically; other users, looking for that specific content, find their way to the platform via Google or another search engine.31
The phrase “looking for that specific content” is important. Unlike the UGC loop, the SEO loop is task-oriented, not feed-oriented. The content has to be useful, and actually answer the user’s search query.
What are some examples of useful content? It’s a wide spectrum:
Reddit and Quora answer specific questions
Expedia, Booking, Kayak et al provide travel information and actions
Yelp and TripAdvisor provide service reviews
Zillow does house prices
Glassdoor and LinkedIn cover various aspects of professional life
These companies monetize in different ways. The broad horizontal platforms tend to monetize via ads, while the vertical ones mostly do affiliate or lead-gen. And then there are a few that monetize via subscriptions or services. Lead-gen, in particular, is sufficiently lucrative — think insurance, financial products, legal services, healthcare, education, travel, home maintenance — that there’s a whole cottage industry of service directories that exist solely to aggregate provider data, capture Google traffic, and take an introducer’s fee.
In each case, adding more data gives these sites more search equity, leading to more traffic, and hence (either directly or indirectly) more data. Flywheel unlocked, moat established.
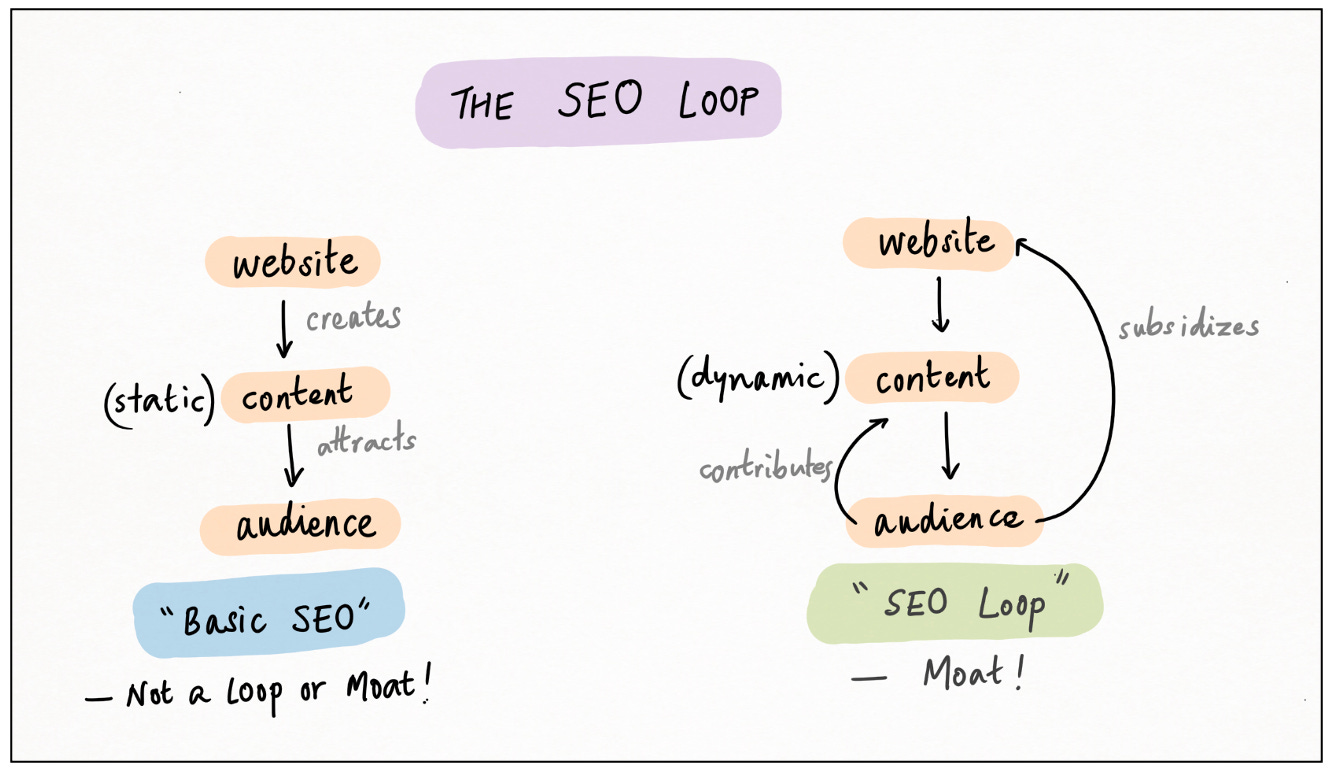
How moaty is this moat? In the Google Era — roughly speaking, 2005 to 2020 — it was pretty damn moaty. Multiple billion-dollar businesses were built, and defended, using this loop.
But this era might be coming to an end, along with this moat. One reason is over-saturation: there’s so much AI slop out there, Google search is simply less useful32 33. Another is dis-intermediation: LLMs are already replacing search for purely informational queries, and agents may soon do the same for navigational and transactional queries. This would bypass the entire search-learn-select-purchase funnel on which the SEO loop is built.34 A final headwind for the SEO loop is the migration of content behind paywalls and logins. People are locking down their data assets; farewell, fully-open web.
Stack Overflow offers a cautionary tale. This graph of monthly questions posted on the popular programming site, created by Gergely Orosz based on data from Theodore Smith, says it all:
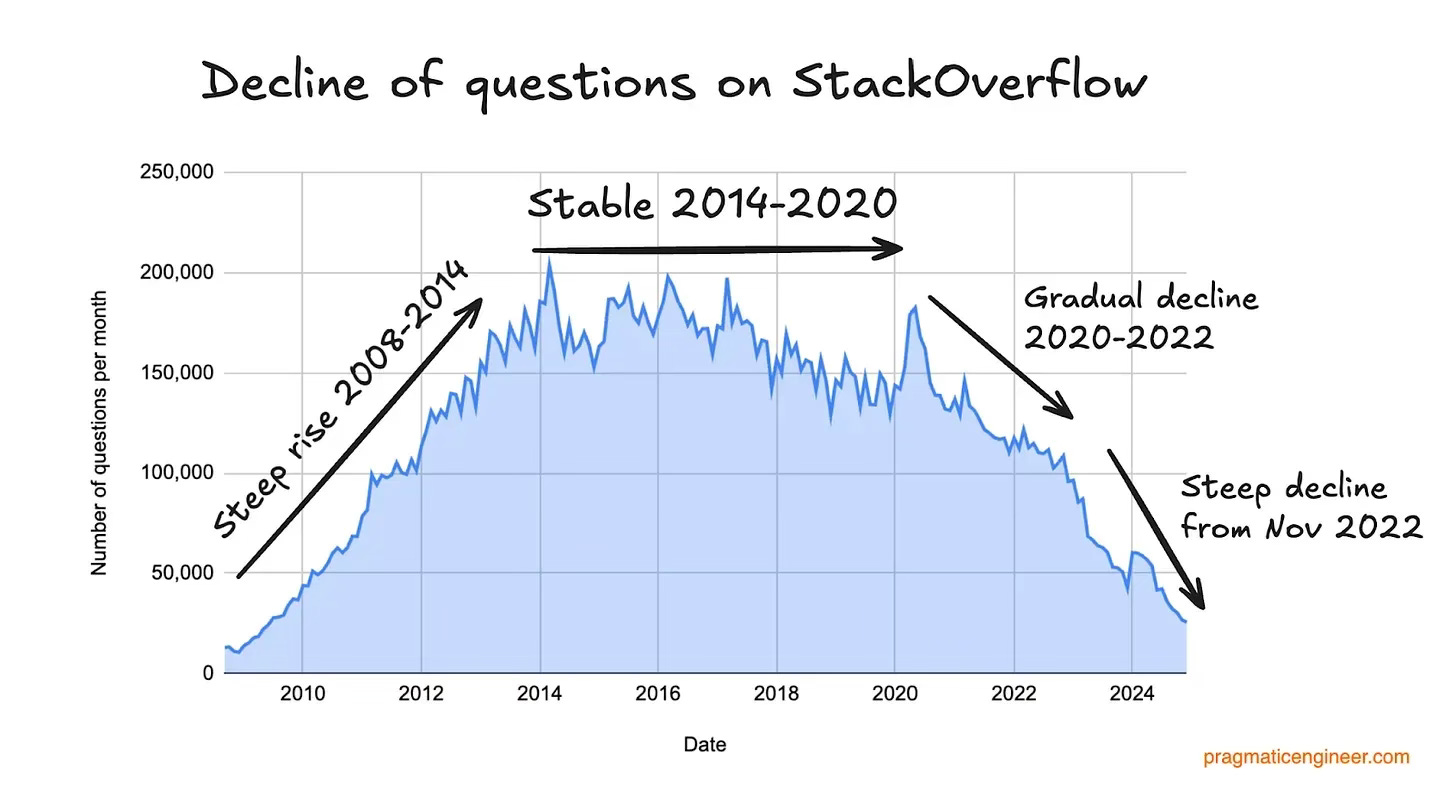
There’s an initial steep rise fuelled by search traffic. Then there’s an almost ten-year period of stability, despite minimal changes to the product. Surely competitors should have emerged during that window? The fact that they didn’t is testament to the power of this moat.
And indeed, the final decline isn’t due to direct competition; it’s because the world suddenly bypassed Google + Stack Overflow as the best way to answer coding questions. The dates line up almost perfectly: Stack Overflow’s traffic peaks in May 2020, and then in June, OpenAI releases GPT-3 ...
SaaS Data Gravity
Stars form by accretion. Amidst vast clouds of diffuse cosmic dust, local concentrations of matter attract more matter, in a gravitational spiral that ends with temperatures and pressures high enough to initiate nuclear fusion.
Empirically, software exhibits a similar pattern: diffusion is replaced by concentration. Here’s how it works.
A lot of software is initially sold via a “wedge” — a tightly-scoped, low-cost, low-risk insertion into the target customer’s stack. Step two is to “land-and-expand” into more users, applications, and revenue; often, this entails “going multi-product”.
But which software tools are able to expand, and which ones fizzle? The analogy with star formation provides the answer: the winners are those that already have local concentrations.
Sometimes, it’s a local concentration of “workflows” — customers like the productivity boost from combining multiple tools into one, but they hate switching their processes, so whichever platform owns the most frequent or most important workflows will tend to swallow the others.
And sometimes, it’s a local concentration of “data”. This is data gravity.
Tools that control the most important or valuable data tend to swallow tools whose data is peripheral or less productive or worse integrated.
Toast is a great case study here. Toast started out as a point-of-sale (POS) system for restaurants. Owning front-of-house order data gave them pole position to expand into kitchen display tickets, online and mobile ordering, consumer-facing apps, delivery integrations, gift cards, payments — and then, eventually, into restaurant financing, payroll, HR and more. All those other functions had competitor apps with their own data, but Toast’s POS data was both the most important and the most central; its gravity enabled Toast to swallow the rest.35
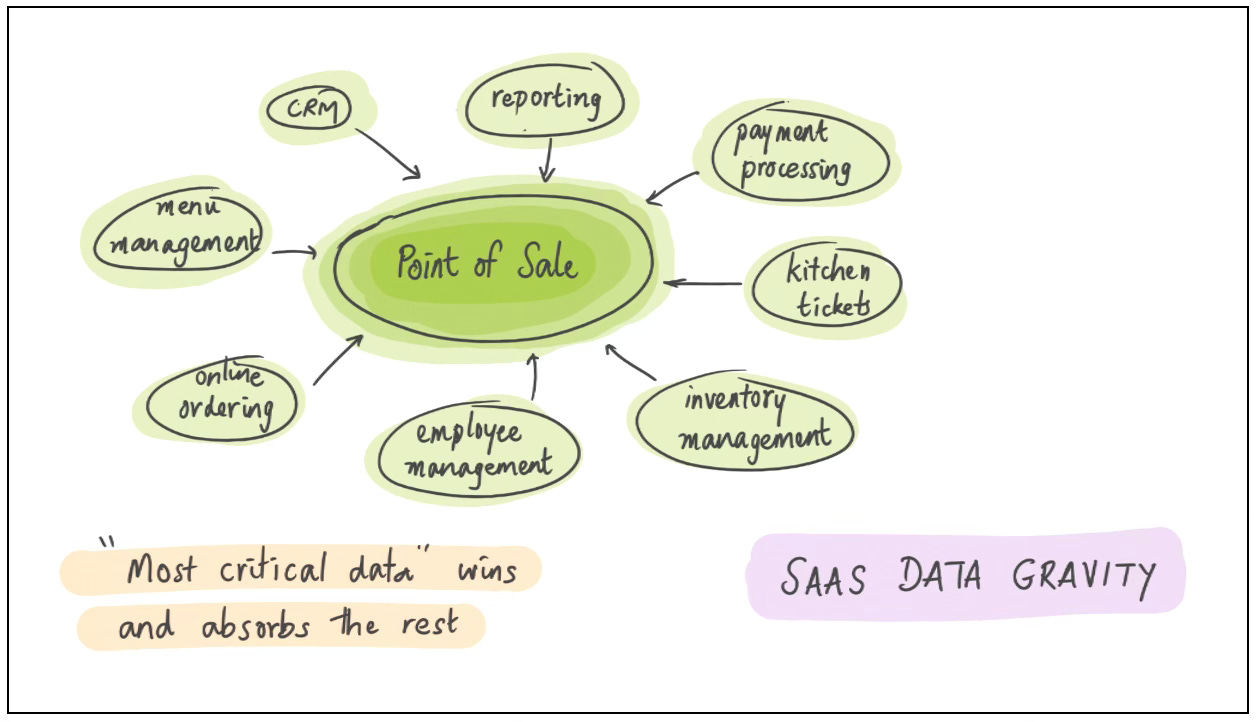
Data gravity moats are similar to, but not quite the same as system-of-record moats. Both moats benefit from workflow lockin, data viscosity, and controlling usage. Where they differ is the dynamics.
There’s no inherent requirement or expectation of growth in a SoR: they are perfectly sticky even when static. But growth is everything for a data gravity loop: growth in data coverage, in product use cases, in audience, in surface area.36
Data gravity in vertical saas is one of the best data moats out there, not least because it feeds into many other (non-data) moats: workflow, trust, revenue control and network effects.
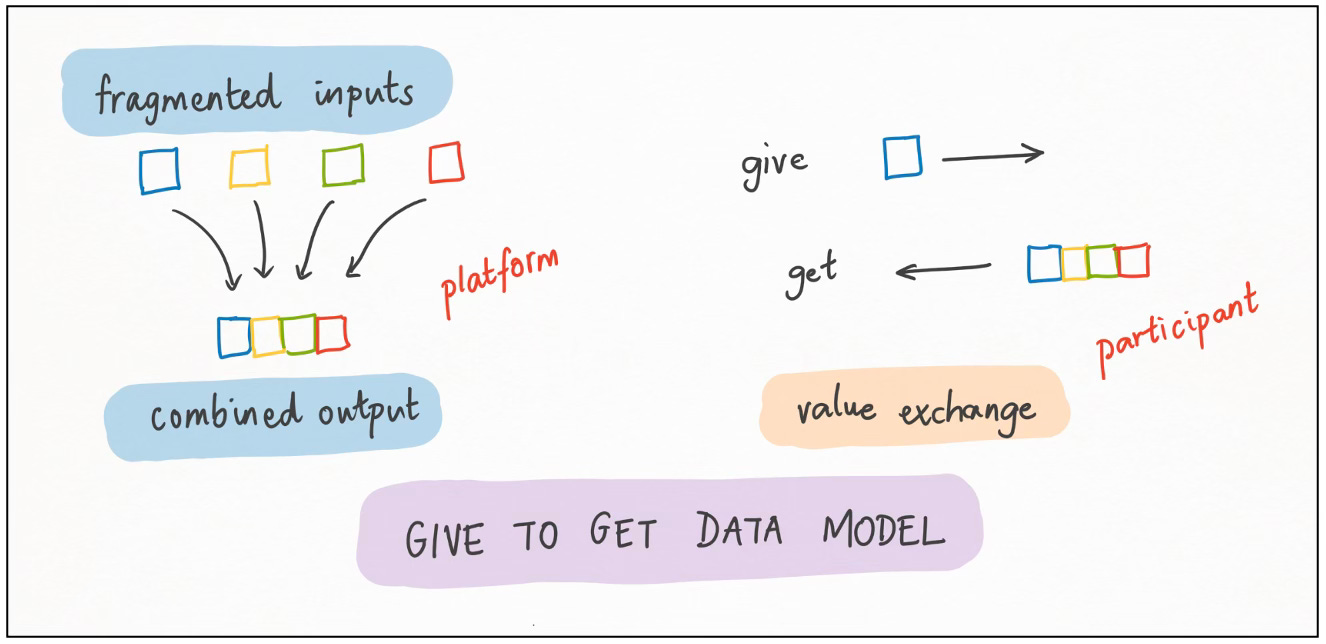
Give-To-Get (G2G) Loop
This is a well-known pattern for data businesses. In a G2G loop, customers of the business receive data if (and sometimes only if) they also contribute data to the business. The more data the business has, the more attractive it is to customers — and hence the more likely they will sign up and contribute data! Positive feedback thus kicks in above a certain initial critical mass.
A pure give-to-get loop is when the data contributed is the same as the data received; and value is created by the act of aggregation. Waze is a great example: users contribute (individual) and receive (aggregated) traffic data. Geographic aggregation in fact seems to be a common theme for G2G models — think of OpenStreetMap, Weather Underground and GasBuddy.
Data consortia (aka data co-ops) are a special case of G2G where a group of competing businesses decide to pool their data resources to generate insight unavailable to them individually — and thus outperform rivals outside the group. The canonical example here is Verisk. Verisk’s ISO (Insurance Sales Office) served as “neutral territory” for a consortium of 7 large insurers; they aggregated and standardized data from these 7 firms, leading to better underwriting for all of them.
Marketplaces with 2-way review systems (like Airbnb — hosts review guests, guests review hosts) are also give-to-get, but here the value isn’t in aggregation, it’s in eliminating selection bias in the reviews, and hence fostering trust.
The theme of eliminating bias is why benchmarking is a very common application area for give-to-get data models. Dun & Bradstreet does this for B2B credit; PayScale does it for salaries; Glassdoor does it for employer reputation; Cambridge Associates does it for private fund performance; and so on.
Of course, the very best examples of benchmarking using a give-to-get data model are the big consulting firms: McKinsey, BCG, Bain et al. The G2G part isn’t explicit, and these certainly aren’t software or data firms, but the loop (and the moat) is very real. (The data in question is sometimes called “best practices”.)
Give-to-get is pretty moaty once you reach critical mass. The hard part is getting there: it’s a classic “cold start” problem, with challenges and solutions that are very reminiscent of the 0-to-1 step for marketplace businesses.37
Anonymization
Aggregation is not the only benefit of clearinghouse and give-to-get models. Anonymization also matters. This is for competitive reasons — there will always be specific business details that companies don’t want to share with competitors, but sometimes it’s hard to “give” data without also giving away those details. So you need a neutral party who can navigate those nuances. And it’s for regulatory reasons — privacy laws dictate what information companies can and cannot share, and adding an anonymity layer makes the process much easier, safer, and more compliant. This isn’t really a moat in itself, but it makes the actual moat (clearinghouse or quantity loop) more resilient.
Learning Loops
The learning loop is the next major family of data loop. Businesses use (“learn from”) data to run better; and running better helps them get more and better data. I wrote about this flywheel in Data in the Age of AI; here’s a stylized view:
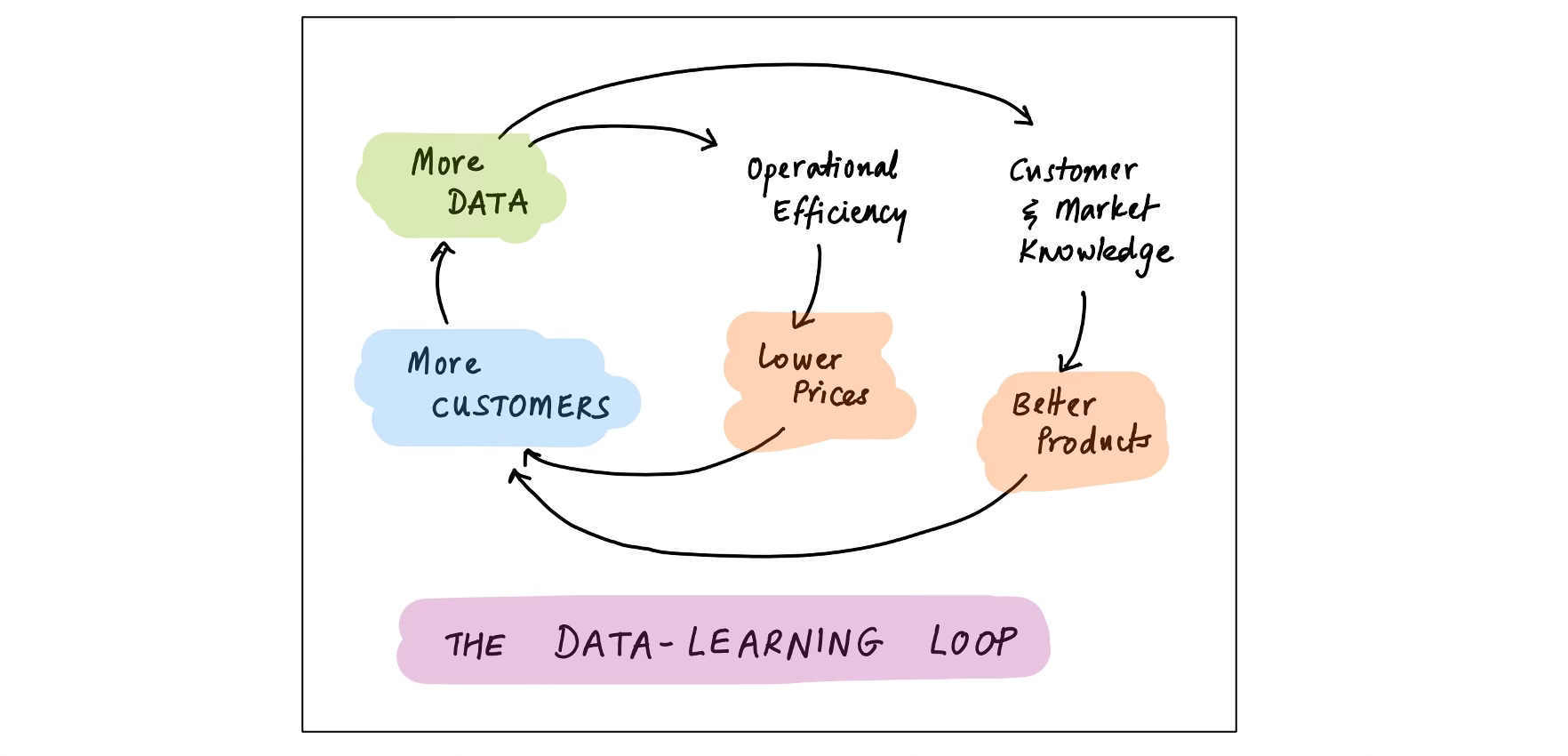
This loop works, and at scale, it works extraordinarily well. But it is not a moat.
In fact, “data learning loops” are tied with “unique data” for first place in the category of “moats that aren’t really moats”. I already talked about unique data; but why is learning so un-moaty?38
It’s a question of limits. Business efficiency doesn’t scale indefinitely with data inputs; instead, the value of learning plateaus above a certain level. Meanwhile, costs show the opposite pattern: long-tail and edge-case effects kick in at scale, making “move-the-needle” data collection more expensive. Acquisition costs go up and marginal data value goes down; in other words, advantages diminish with scale instead of accelerating. This is no moat.
There are two and a half exceptions.
The first is what I call the business model unlock: when your learning loop reaches a magic threshold that enables a business model that simply isn’t possible without that learning. Threshold effects are important here: you need a discontinuity in the customer value function for this moat to work.
Amazon Prime is a good example of the business model unlock. Once Amazon acquired enough data (“learned”) about customer behaviour, purchase patterns, order frequency, warehouse location, inventory management, delivery scheduling, route optimization and so on, it was able to offer “free” 2-day delivery. This unlocked multiple virtuous cycles (in both time — order frequency and packed routes — and space — warehouse and driver density), which demolished every other horizontal marketplace. The data didn’t merely drive an iterative, incremental, quantitative improvement in Amazon’s operations (the classic, un-moaty learning loop); it enabled a whole new service that competitors simply could not match. An incredible moat.
The second exception is data businesses. It’s not that (increasing) cost and (diminishing) value effects don’t apply to data businesses; it’s just that the data gives them access to a bunch of other levers (unique data products, easier GTM, price discrimination, ecosystem tactics) that counter these effects. I wrote about these levers in The Economics of Data Businesses.
The half-exception is AI. In AI, outcomes do appear to scale indefinitely with data inputs, taking away that particular limit. On the other hand, there’s no actual loop here; it all happens during pre-training. Recent advances in test-time inference (and especially the tantalizing prospect of cross-user / cross-session learning) could change this, but we’re not quite there — yet.39
Secondary Learning Loops
There also exist “non-core” or “secondary” data learning loops, which are even weaker and less moat-y than core learning loops. I include them here for the sake of completeness:
Data quality loop: somewhat valuable, but quality is not a moat.
Product recommendation loop: eigenvalues and e-commerce are a cool combination, but also not a moat.
Product optimization loop: lol, no. A/B testing is not even a shallow ditch.40
I’ve heard each of these being referred to as a material source of defensibility. Nope.
If all these data learning loops are so weak, why do they have such a hold on the popular imagination? I suspect the reason is largely political. “We win because we use data and technology to provide a better service” is a much better sell than “we win because we charge monopolistic tolls on attention, commerce, and devices”.
Aside: The Barton And Von Ahn Loops
I want to highlight two data-loop entrepreneurs: Rich Barton and Luis von Ahn. They’ve each founded multiple decacorns or decacorn equivalents, using clear and distinctive approaches:
The Rich Barton Playbook: find an industry with knowledge that is valuable, fragmented, and opaque; make this hidden knowledge public; dominate search traffic; own “customer demand” in the industry; repeat. He’s done this for travel (Expedia), employment (Glassdoor), and homebuying (Zillow). Kevin Kwok wrote an excellent essay about this.
The Luis von Ahn Playbook: find a labelling problem where users get utility from the act of labelling — aka the two-sided learning loop. In Duolingo, users learn a language but also translate untranslated books. In Recaptcha, users authenticate themselves, but also label ambiguous images. (Mercor, not a von Ahn company, appears to be working along similar lines.)
What other repeatable data-moat playbooks exist? In The Economics of Data Businesses, I hypothesized that we’d see the emergence of lots of niche, vertical-specific, B2B data businesses. A year later, Travis May launched Shaper Capital to incubate precisely that style of business — “solving data fragmentation in various industries”, as he previously did at unicorns LiveRamp (identity) and Datavant (health). I’ll be watching the Travis May Playbook with great interest.
The Bootstrap And Switch
While learning loops may not be a sustainable moat in and of themselves, they are still valuable as the first leg of an extremely effective pattern that I call the bootstrap and switch.
In this pattern, you begin with a data learning loop to improve your product and grow your customer base; but as you reach scale, you build out other network effects and defensibilities that become your long-term moat. This is seen most often in content businesses (Facebook, Netflix, Youtube), and in marketplaces (Doordash, Uber, Airbnb).
Whenever recommendation or matching plays an important role in the value added by a platform — as in the examples listed above — learning becomes super valuable, and drives rapid growth. But the long term moats for those businesses come from network density, user trust, economies of scale, and attention-aggregation. Not from learning.
Usage/Value Loops
The next type of data loop, and possibly my favourite, is the usage/value loop: the more widely a particular data asset is used, the more valuable it becomes to its users. Whoever owns or controls this data asset mints money.
This loop comes in a few different flavours:
Data Exchange Standards
You provide an industry-wide “primary key” that can link records held by different companies. Factset’s CUSIP identifier is a good example: it allows capital markets participants to agree on precisely which securities they’re trading, clearly and unambiguously.
In a financialized world, with multiple debt and equity classes, listing venues, and security types, this is critical: firms simply cannot function in capital markets without CUSIP. And the more people use it, the more valuable / universal / lucrative / essential it becomes. It’s a toll on the industry, with increasing returns to adoption!
(Similar products to CUSIP are DUNS, VIN and ISBN; this category seems to have a fondness for acronyms.)
Business Evaluation Standards
You provide an industry-wide “benchmark” that everybody uses to evaluate or price transactions. S&P’s eponymous S&P 500 Index is a good example: every investment manager (and every LP in an investment manager) compares their performance to this index, and it’s also used to price derivatives, structured products, ETFs, you name it. Again, the more it’s used, the more dominant it becomes. Another tax!
(Similar products: Nielsen’s viewership benchmarks, corporate and sovereign risk ratings, FICO scores.)
Pass-Through Loop
I talked earlier about why most data learning