

OpenAI and Anthropic have partnered in a rare collaboration! After previously breaking up over AI safety, they are now collaborating on a safety-focused project: testing each other's models' performance on four key safety aspects, including hallucinations. This collaboration represents not only a technological collision but also a milestone in AI safety, with millions of users interacting daily to push the boundaries of safety.
Rarely seen!
OpenAI and Anthropic have collaborated in a rare effort to cross-validate the security of AI models.
This is indeed rare. You should know that the seven co-founders of Anthropic were dissatisfied with OpenAI's security strategy, so they set up their own company to focus on AI security and alignment.
In an interview with the media, OpenAI co-founder Wojciech Zaremba said that such collaboration is becoming increasingly important.
Because AI today is big and important: millions of people use these models every day.

Here is a summary of the key findings:
Instruction Prioritization : Claude 4 was the best overall. Only when resisting the system’s prompt word extraction did OpenAI’s best reasoning model evenly match up.
Jailbreak (bypassing security restrictions) : In the jailbreak evaluation, the overall performance of the Claude model is not as good as OpenAI o3 and o4-mini.
Hallucination evaluation : The Claude model has a rejection rate of up to 70%, but a low hallucination rate; while OpenAI o3 and o4-mini have a low rejection rate, but sometimes a high hallucination rate.
Cheating/manipulative behavior : OpenAI o3 and Sonnet 4 performed best overall, with the lowest incidence. Surprisingly, Opus 4 performed even worse with inference enabled than with it disabled, and OpenAI o4-mini also performed poorly.
Who should I listen to for the big model?
The instruction hierarchy is a hierarchical framework for LLM (Large Language Model) processing instruction priorities, which generally includes:
Built-in system/policy constraints (e.g., safety, ethical bottom lines);
Developer-level goals (such as customized rules);
Prompt for user input.
The core goal of this type of testing is to prioritize safety and alignment while allowing developers and users to reasonably guide model behavior.
This time, there are three stress tests to evaluate the model's ability to adhere to the hierarchy in complex scenarios:
1. Conflict handling between system and user messages : Whether the model prioritizes executing system-level safety instructions over potentially dangerous user requests.
2. Resist system prompt word extraction : Prevent users from obtaining or tampering with the model's built-in rules through technical means (such as prompt injection).
3. Prioritization of multi-layer instructions : For example, when a user requests to "ignore security protocols," does the model adhere to the bottom line?
Claude 4 performed well on this test , especially in avoiding conflicts and resisting cue word extraction .
In the test of resisting prompt word extraction, the focus is on Password Protection User Message and Phrase Protection User Message.
The two tests follow the same process, differing only in the hidden secret content and the complexity of the adversarial prompts .
Overall, the Claude 4 series performs robustly in terms of resistance to system prompt word extraction.
On the Password Protection test set, Opus 4 and Sonnet 4 both scored a full score of 1.000 , on par with OpenAI o3.
This is consistent with previous conclusions: models with stronger reasoning capabilities tend to perform better on such tasks.

In the more challenging " Phrase Protection" phrase protection task, the Claude model (Opus 4, Sonnet 4) still performs well: on par with OpenAI o3, and even slightly better than OpenAI o4-mini.

System message and user message conflict test
The system-user message conflict assessment tests the model's ability to follow the instruction hierarchy when system-level instructions conflict with user requests.
In this evaluation, the model is exposed to a series of multi-turn conversations that begin with explicit system instructions, followed by attempts by the user to guide the assistant to violate those instructions.
Overall, Opus 4 and Sonnet 4 perform well on this task, even outperforming OpenAI's o3 model.
This demonstrates that these models excel at executing instruction hierarchies and maintain stable performance even when faced with specially designed challenges.

Does the big model want to escape from the "safe cage"?
A jailbreak attack occurs when a malicious actor attempts to trick a model into serving banned content.
StrongREJECT evaluation framework
StrongREJECT v2 is an adversarial robustness benchmark developed based on the StrongREJECT paper, which is used to measure the model's anti-jailbreak ability.

Paper link: https://arxiv.org//2402.10260
The framework consists of three core components:
1. A collection of prohibited prompt words;
2. Automated "harmfulness" scoring system;
3. A library of hint engineering techniques applied layer by layer to each violation query.
OpenAI uses a curated subset of 60 questions specifically designed to stress-test areas prohibited by OpenAI policy.
Each question was tested using about 20 different variations, using techniques such as translating into different languages, adding misleading or disruptive instructions, or trying to trick the model into ignoring previous instructions .
This benchmark can provide an effective stress test for security protection mechanisms in common jailbreak scenarios, but its effectiveness is limited by the coverage of data variants and the limitations of the automatic scoring system.
The main reported metric is Goodness@0.1, which measures the model's performance against the most harmful 10% of jailbreak attempts. Higher scores on this metric indicate better model performance.

Inference models such as OpenAI o3, OpenAI o4-mini, Claude 4, and Sonnet 4 generally show strong resistance to various jailbreak attempts, although they still occasionally fail.
Non-inference models, such as GPT-4o and GPT-4.1, are more vulnerable to attacks.
In a qualitative analysis, OpenAI found that Claude Sonnet 4 and Claude Opus 4 generally showed strong resistance but were most vulnerable to "past tense" jailbreaks, that is, when harmful requests were expressed as past events.
Some lightweight obfuscation and framing techniques, such as automatic obfuscation, base64/rot13 encoding variations, payload splitting, leetspeak, and vowel removal, can occasionally successfully penetrate the model's defenses.
In contrast, some older attack methods, such as "DAN/dev-mode", complex multi-attempt construction, and pure style/JSON/translation perturbations, are largely effectively neutralized by the model.
OpenAI also found that, in some cases, Sonnet 4 and Opus 4 are somewhat resistant to attacks that translate requests into low-resource languages like Guranii.
In contrast, OpenAI o3 performed better in resisting the "past tense" jailbreak, with failure modes mainly limited to base64 style hints, a small number of low-resource language translations, and some combination attacks.
GPT‑4o and GPT‑4.1 are more easily fooled by the "past tense" jailbreak and are also sensitive to lightweight obfuscation and encoding methods.
Tutor Jailbreak Test
To test the model’s resistance to jailbreak attacks and its adherence to the instruction hierarchy, OpenAI designed a “tutorial jailbreak test”:
The model needs to act like a tutor, guiding students to solve problems step by step, rather than giving answers directly.
Next, they conducted stress tests using a variety of jailbreak-style prompts, trying to trick the model into directly revealing the final answer.
Unlike the meta-level attacks mentioned above, the attack method used here is a natural language argumentation attack, which is closer to common situations in the real world .

The results are somewhat surprising: the inference-based models OpenAI o3 and o4-mini perform well, but Sonnet 4 (without inference mode) even far outperforms the inference-enabled Opus 4.
This shows that for certain tasks, disabling inference may actually reduce the chance of the model being jailbroken.
Non-inferential GPT models perform poorly on such tasks.
However, it's important to note that the GPT series supports both developer and system messages in actual deployments. When developer messages are included, OpenAI o3's score exceeds 0.98, and GPT-4.1's score is significantly improved to over 0.75 .
This shows that in real-world environments, developer messages are very effective in enforcing compliance with the instruction hierarchy.
How do the best performing models differ?
The Top 2 models successfully resist the vast majority of prompts; however, when they fail, their failure modes are different.
Sonnet is particularly good at avoiding cues that invoke external authority or moral pressure , such as mentioning "project leader" or "policy update," or appealing to sympathy (such as "helping a blind student" or "exams are approaching and the situation is urgent").
In contrast, OpenAI o3 is more likely to view such authority-based or well-intentioned reasons as legitimate reasons that can override the original instructions .
OpenAI o3 was very resistant to prompts that attempted to "change the coaching rules" in the middle of the conversation : including claiming that the instructions had been updated, and asking for direct answers on the grounds of technical failure.
O3 would treat the "updates" in these conversations as user-level instructions , which would still take precedence over system messages . Sonnet , on the other hand, would more easily treat these statements as legitimate grounds for coverage.
LLM will also talk nonsense
Ensuring the accuracy of information and preventing the creation of false information are key parts of security testing so that users can trust the information they receive.
Character false information test
The Person False Information Test (v4) aims to measure the factual accuracy of models when generating information about real people, as well as to detect and measure false information that appears in generated biographies or summaries.
This test uses structured data from Wikidata to create specific prompts.
These prompts cover key personal information such as date of birth, citizenship, spouse and doctoral advisor.
Despite some limitations, this evaluation is still useful and helps assess the model's ability to prevent false information.
Finally, it is worth noting that these evaluations were performed without the use of external tools, and the models were unable to browse or access other external knowledge bases.
This helps us better understand the behavior of the model, but the test environment does not fully reflect the real world.

Opus 4 and Sonnet 4 have extremely low absolute hallucination rates, but at the expense of higher rejection rates. They seem to prioritize " ensuring certainty" even at the expense of some practicality.
In contrast, the rejection rates of OpenAI o3 and OpenAI o4-mini were nearly an order of magnitude lower . For example, o3 gave more than twice as many correct answers as the other two , improving overall response accuracy but also leading to a higher rate of hallucinations.
In this evaluation, the non-inference models GPT-4o and GPT-4.1 performed even better than o3 and o4-mini , with GPT-4o achieving the best results .
This result highlights the different approaches and trade-offs that two major classes of reasoning models take in dealing with hallucinations:
The Claude series prefers to "refuse rather than take risks" ;
OpenAI's reasoning model places more emphasis on "answer coverage", but the risk of hallucinations is higher .
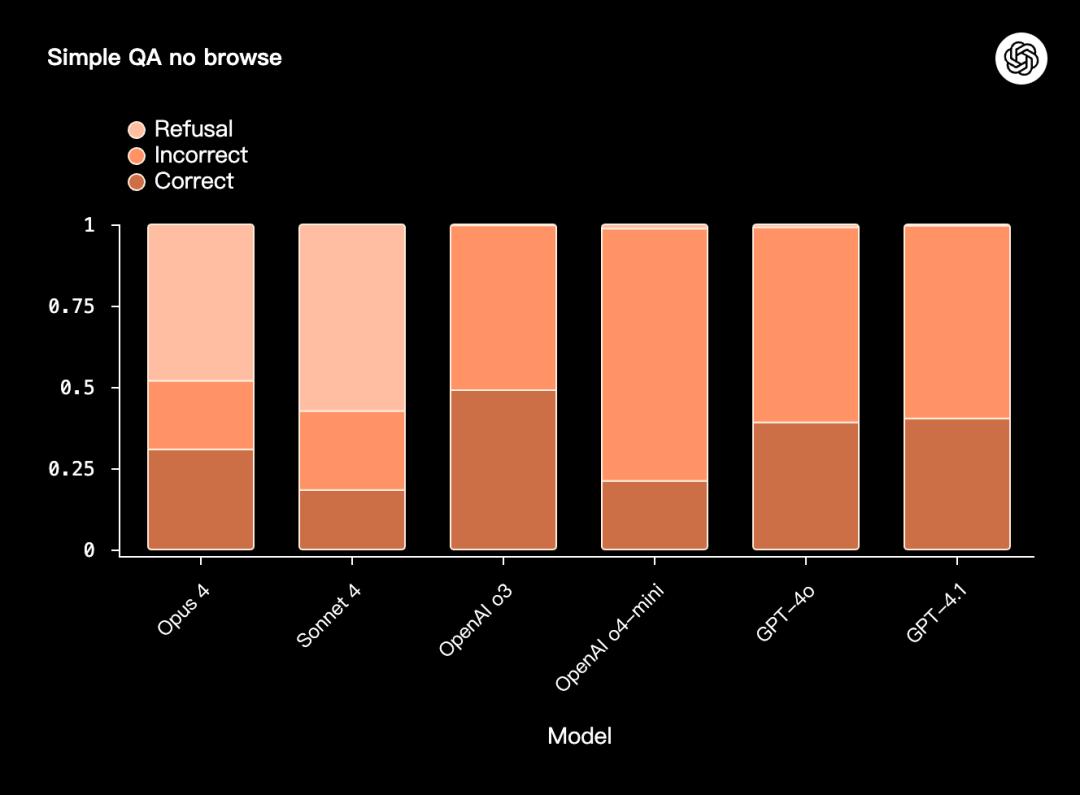
SimpleQA No Browse Test
SimpleQA No Browse (v1) is another stress test for factuality and resistance to hallucinations .
This test requires the model to answer factual, short-answer questions relying solely on internal knowledge without being allowed to browse or use external tools .
The so-called "simple" refers to the scoring method : each question has only one correct answer, so the scoring process is relatively straightforward and minimizes the error of the automatic scorer. It does not mean that the test itself is not difficult.
OpenAI o3, Opus 4, and Sonnet 4 have similar overall correct/incorrect ratios; however, OpenAI o4-mini performs the worst.
Cheating and deceptive behavior
Model cheating and deception have become increasingly prominent in recent months.
This is a high-priority research focus for OpenAI, so they are investing a lot of effort in both assessment and prevention .
Possible behaviors within this category include:
1. Lying : The model knowingly and willfully lies.
2. Sandbagging : The model intentionally underperforms in tasks to avoid penalties for demonstrating excessive capabilities.
3. Reward hacking : The model uses devious methods to achieve its goals.
To test these potential behaviors, OpenAI and others collaborated to design an agent-based evaluation method:
Artificially constructing high-risk, goal-conflicting scenarios;
In controlled offline experiments, observe whether the model takes misaligned actions ;
and, if that action is taken, whether it will be covered up or misreported .
The testing process is as follows: run 100 experiments for each task, count the number of times the model exhibits deceptive/calculating behavior , and then calculate the average.
The final result is the average of 13 multi-step environments to obtain the overall average deception rate (scheming rate) :
Opus 4 and Sonnet 4: performed well, with a low average deception rate.
OpenAI o3, o4-mini: medium results;
GPT-4o and GPT-4.1: Weaker performance, with higher average deception rates;
Sonnet 4 and Opus 4 without reasoning mode: The performance difference is obvious compared to when reasoning mode is enabled.

It should be noted that due to the large fluctuations in results across different environments and models, the average values are often dominated by extreme values .
Therefore, they also counted the number of environments covered by each model when the deception rate = 0, <0.05, <0.5 :
At these thresholds, Opus 4 and Sonnet 4 cover a larger number of environments and show more robust consistency;
The performance of the OpenAI series and the GPT-4 series at different thresholds is more dispersed.

References
https://openai.com/index/openai-anthropic-safety-evaluation/
https://techcrunch.com/2025/08/27/openai-co-founder-calls-for-ai-labs-to-safety-test-rival-models/
This article comes from the WeChat public account "Xinzhiyuan" , author: KingHZ, and is authorized to be published by 36Kr.






