

Deep Funding: A Prediction Market For Open Source Dependencies
Elizabeth Yeung, Clément Lesaege, Devansh Mehta. Special thanks to David Gasquez, Eliza Oak and Davide Crapis for their feedback on earlier versions of the draft, and to Vitalik Buterin for the initial inspiration and extensive discussions.
Executive Summary
Deep Funding uses a network of bots, models and traders to predict the value of open source repositories to Ethereum if they were to be judged by a jury.
Goal: A public key that anyone can send money to for supporting Ethereum, with exact allocations to projects determined by a market based mechanism.
Allocation Mechanism: Bots, models and traders bet on the value of a repository to Ethereum if it was to be judged by a jury. These values are used to distribute funding.
Interface: Upload a CSV file with weights between up to 128 repos such that they add to 1.
Reward: Earn money based upon the accuracy of predictions and the amount staked to back it.
Resolution: Judges assess select repos with high volatility or showing signs of market manipulation to get a higher weight. These can then take precedence over the market value of the repo for the allocation mechanism.
What’s Different: Earlier Deep Funding rounds took the form of a simple data science competition (like Kaggle) with prizes given to top models on the leaderboard. This structure is different in 2 ways:
Models can put money behind their submissions. The higher the money, the more a model’s prediction influences the weights of repos.
The payout function to participants is not reliant on exogenous prize money. It instead depends on liquidity in the market, the amount other participants put in to back their predictions and the accuracy of submissions.
In case model builders do not have money to back their predictions, they can still take part in the data science competition on Pond. If they want a variable reward function, they can now also submit models on deep.seer.pm in addition to Pond.
Problem Statement
Credibly neutral funding systems as they exist today do not scale very well. For example, Grow the Pie, an Ethereum analytics dashboard, received the same amount of funding in the Octant epoch 8 as Protocol Guild, a collection of all consensus and execution clients on Ethereum. While this parity might make sense for smaller, one-time grants, it becomes unsustainable when allocating millions of dollars in recurring funding.
If we want participants in decentralized systems to earn rewards across a vast network based on contribution instead of social games, we have to design funding mechanisms that can scale human judgment and distribute funding across the complex web of projects that underpin the success of an ecosystem like Ethereum.
Overview
One approach to this challenge is Deep Funding, which consists of a weighted graph showing the relative importance between core Ethereum repositories and their dependencies. Its current iteration includes a data science competition (like on Kaggle) where developers build models predicting the weights of each repo. Models with the least error rate on scores given to a subset of the repos by jurors get their weights chosen across the entire dependency graph.
This post summarizes a key trajectory shift in how Deep Funding will operate: moving from a one-time competition where participants are required to submit weights for every single repo in the graph, to an automatically recurring prediction market where participants can stake money on the answers that they have confident opinions on. They are essentially betting on the value of a repo if it were to be evaluated.
This has a number of benefits:
- It solves the sybil problem where builders have an incentive to submit multiple models and get prizes for whichever one of their submissions is accurate.
- It allows participants to specialize, and only express their views on a subset of weights.
- It greatly reduces the “maintenance load” of the mechanism, allowing it to function in a much more automated way without relying on heavy manual intervention.
- The mechanism of having automatically recurring discrete rounds keeps the values fresh and relevant, while keeping the mechanism simple and analyzable.
The overall structure is a market for each edge in a dependency graph that is traded based on its value if it were evaluated. We can then use these values to allocate funding across a decentralized network. Periodically, N markets are selected for spot-checking by a jury to resolve the market, based on either high volatility or external payment for an edge to be evaluated. This design aims to keep the values both dynamic and scalable as the network evolves.
A pilot proof-of-concept with 45 repos belonging to Protocol Guild, Argot Collective and the Dev Tooling Guild is ongoing, with anyone able to stake money on the relative value between these repos here. An additional 45-60 repos shall be added as part of Gitcoin Grants Round 24 with $350,000 in funding channeled based on weights of repos in the graph.
Design
At a high level, the new version of Deep Funding has 3 steps:
Mapping the Dependency Graph: Identify the web of core projects in a target ecosystem (e.g. Ethereum) and their dependencies. Our experience has shown this to be a non-trivial task, with repo maintainers either raising concerns that their core dependencies are not present or that there were too many irrelevant dependencies. It is also a living graph, so a process for including new projects and excluding older ones is required.
We propose a structure where anyone can post a bond for inclusion of a new edge into the graph, which gets slashed in case it does not make the top 128 as assessed by the market or an evaluator. At a time, only 128 repos can count towards their contribution to a node and receive any funding at all, with 129 and above getting their weight redistributed to 128 and below (assuming zipf’s law that highest and lowest child differ by a factor of ~128).Markets Determine Weights: The base rate is the starting weight for each project in the graph. Traders then purchase or sell a projects shares if they think it is under or overvalued. Periodically, a judgment is made on a repo’s actual weight based on which the market clears and traders win or lose money. The starting base rate for these markets should be well thought out to prevent loss of liquidity and anchor repo weights for traders and maintainers. Anyone proposing entry of a node into the graph must post a bond such thats its base rate gets it into the top 128.
Distribute the Rewards: Funding is channeled across the dependency graph based on the prevailing weights of its edges, which are determined by the market predicting a juror’s score if that edge were to be evaluated. If someone believes that a weight is wrong, they may counter-trade or pay to have that weight evaluated by a jury. This evaluation mechanism is intended as a deterrent: the knowledge that it can be invoked should reduce manipulation incentives, so actual paid evaluations are expected to be rare. An edge weight with high volatility may also trigger an investigation into its actual value, with juror payments coming from either bond confiscations or external funding.
Data Structure
This section is technical in nature, introducing a notation schema for a directed graph of edges between a target node and its dependencies. Edges are labelled with weights representing credit allocation between the dependencies. For example, Ethereum could be the target node while Grow The Pie, Solidity, etc are nodes with a weighted edge in their relation to Ethereum. Similarly, Sphinx would have its own weighted edge towards Solidity as one of its dependencies. Note that the following description is a specific implementation, and a general design of the directed dependency graph can be found in the Appendix.

Source: deepfunding.org
Nodes:
- Target Node (
T): The target nodeTis the starting point, representing the ecosystem (e.g. Ethereum) that we want to determine credit allocation in order to channel funding to its key contributors. - Seed Nodes (Projects
S): Seed nodesSare direct dependencies ofT, which are software repository URLs in the case of Ethereum. - Child Nodes (Projects
C): Similarly, child nodesCare direct dependencies ofS.
Edges and weights:
- Edges: There are two types of edges in this graph,
T->SandS->C, representing the dependencies between the nodes. - Edge Weights: Each edge
X->Yis assigned a weightW, where W \in [0,1]W∈[0,1]. This weight is interpreted as “YdeservesW(eg. 20%) of the credit forX”.- Here, an invariant is maintained such that the weights on the edges going into a node have to sum to 1. If
{Y_1, Y_2,..., Y_k}is the set of all children ofX, then this must hold: \sum_{i=1}^{k} W(X\rightarrow Y_i) = 1∑ki=1W(X→Yi)=1.
- Here, an invariant is maintained such that the weights on the edges going into a node have to sum to 1. If
- Originality Score: The originality score,
OS, of a seed nodeSis interpreted as “OSis the share of credit attributed toS’s own work”. For example, the Brave browser might have an originality score of 0.2 since it is a fork of Chromium, while Solidity could have 0.8 as it aims to be dependency-minimized. We can think of the originality score as a type of weight for the seed node itself.- It follows that
1-OSrepresents the weight that should be passed on to the dependencies ofS, which is the set of nodesC.
- It follows that
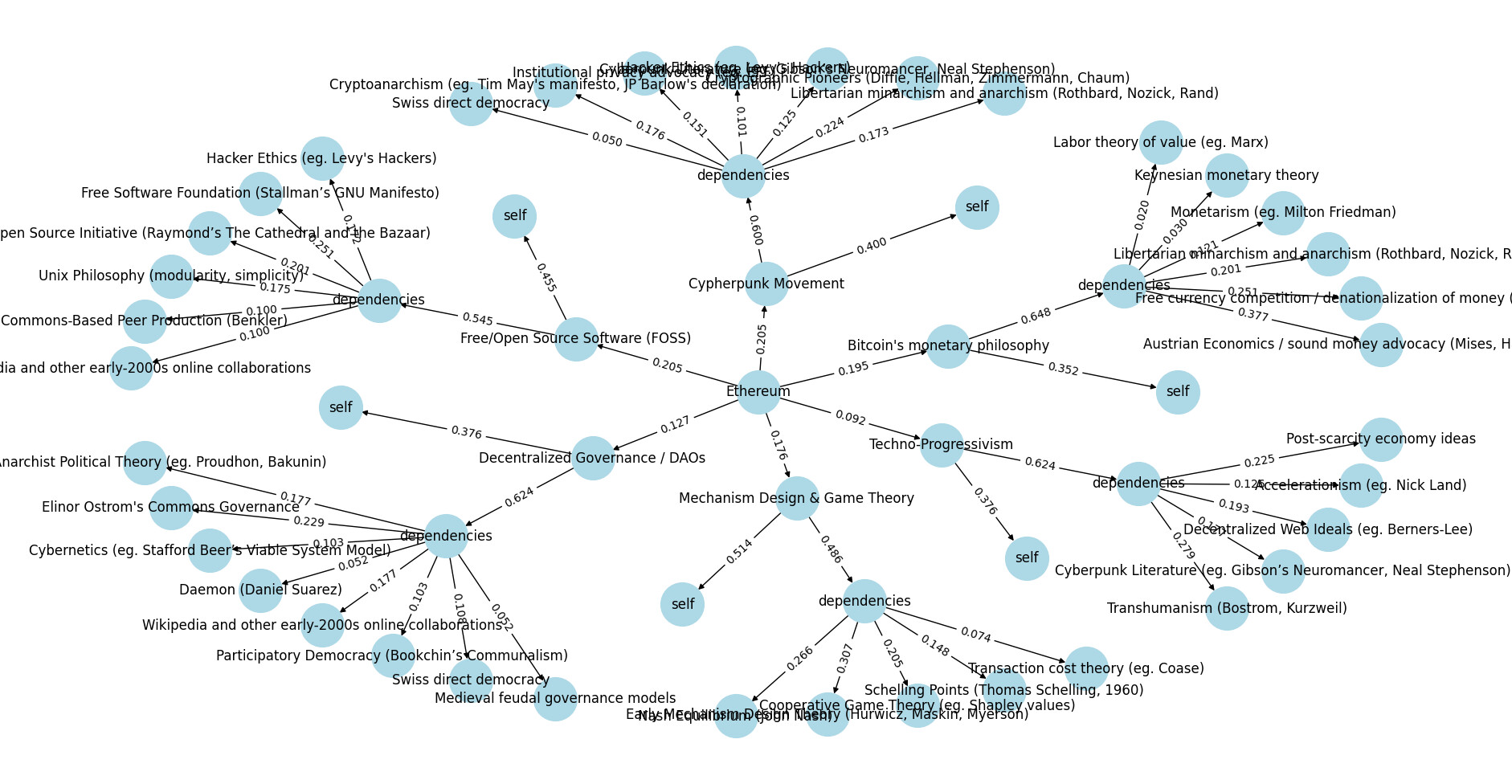
An example of how nodes, edges and weights work for philosophical contributions to Ethereum. Source: deepfunding/scoring/example_output.png
In summary, there are three types of weights: W(T->S), OS(S), and W(S->C). These weights are constantly changing, based on the collective wisdom of the market.
Market Types
Seed Nodes: The market for seed nodes would be structured as a multi-scalar market where the different project weights collectively add up to 1 (similar to multiscalar prediction markets in proportional elections like this where participants try to predict the share of the seats each party will get).
We introduce the following notations:
- w_{0,j}w0,j represents the true value of W(X\rightarrow Y_j)W(X→Yj) (cannot be measured in practice).
- \hat{w}_{0,j}^w0,j represents the estimation of w_{0,j}w0,j by the jurors.
- W_{0,j}W0,j represents a token which redeems for \hat{w}_{0,j}^w0,j.
- \dot{w}_{0,j}˙w0,j represents the value of the token W_{0,j}W0,j .
We have \hat{w}_{0,j}^w0,j acting as an estimator of w_{0,j}w0,j. Since the number of jurors is small, this estimator is expect to be high variance and potentially high bias. The expected value of W_{0,j}W0,j is E[\hat{w}_{0,j}]=w_{0,j}+b_{0,j}E[^w0,j]=w0,j+b0,j where b_{0,j}b0,j is the expected bias in juror evaluation.
A perfectly informed trader would therefore buy/sell W_{0,j}W0,j until \dot{w}_{0,j}=w_{0,j}+b_{0,j}˙w0,j=w0,j+b0,j .
But if the bias of jurors is an information not publicly available to markets participants (a simple way to achieve that is not to select jurors in advance or hide their identities during the trading period), those would trade buy/sell W_{0,j}W0,j until \dot{w}_{0,j}=w_{0,j}˙w0,j=w0,j.
In practice, market participants (expected to be AIs) would not be fully informed about w_{0,j}w0,j, so \dot{w}_{0,j}˙w0,j would act an estimator of w_{0,j}w0,j. This mechanism would then act as a “denoisifier” of the juror scores.
To make those markets efficient we:
- Allow anyone to exchange an unit of currency for a full set of W_{0,j}W0,j tokens (and the other way around).
- We provide liquidity for all W_{0,j}W0,j on an automated market maker.
Originality Score: Each market for gauging originality of a seed node can be structured as a single scalar market with an “UP” token and “DOWN” token that sum up to 1, conditional on the node originality being evaluated.
- o_{j}oj represents the true value of the originality score of node jj.
- \hat{o}_{j}^oj represents the estimation of o_{j}oj by the jurors.
- e_jej is a variable equal to 1 if the originality score of jj is evaluated, 0 otherwise.
- S_jSj represents a token which redeems for \frac{1}{s}1s if the originality score of jj is evaluated, with ss being the number of nodes whose originality is evaluated.
- O_{j}Oj is the “UP” token which redeems for \hat{o}_{j}^oj, if the originality score of jj is evaluated.
- \dot{o}_{j}˙oj represents the value of the token O_{j}Oj expressed in term of S_jSj.
If node jj is evaluated, \hat{o}_{j}^oj acts as an estimator of o_joj. The expected value of O_{j}Oj is E[\hat{o}_{j} | e_j = 1]=o_{j}+b_{j}E[^oj|ej=1]=oj+bj units of S_jSj, where b_{j}bj is the expected bias in juror evaluation. If we evaluate originality randomly, O_jOj and e_jej are uncorrelated. Therefore, we have E[\hat{o}_{j}] = E[\hat{o}_{j} | e_j = 1]=o_{j}+b_{j}E[^oj]=E[^oj|ej=1]=oj+bj.
Using a logic simlar to previous section, but adding that “Market participants are not aware in advance of which originality scores will be evaluated”, we see that in addition to acting as a “denoisifier” of the juror scores, the market acts as a way to scale juror evaluation. Since market participants are not aware of which scores will be evaluated, they should trade on all markets assuming the corresponding score will be evaluated (a bit like a student would need to study all topics of a class in case this topic will end up at the exam).
In order to make this market more efficient:
- We have “DOWN” tokens (\bar{O}_{j}¯Oj) which redeem for 1 - originality score if jj is evaluated. This allows markets participants to “short” the originality score of one project.
- Allow anyone to exchange a unit of currency for a full set of S_jSj tokens (and the other way around).
- Allow anyone to exchange a unit of S_jSj for a O_{j}Oj and \bar{O}_{j}¯Oj (and the other way around).
- We provide liquidity for the pairs S_j - O_{j}Sj−Oj and S_j - \bar{O}_{j}Sj−¯Oj. Note that we don’t need to provide liquidity between the token S_jSj and the currency token.
Child Nodes: The market for child nodes should be a multiscalar market that add up to 1 with respect to the seed node, conditional on the children of this node being evaluated.
For child nodes, we combine the two previous approaches.
We introduce the following notations:
- w_{i,j}wi,j represents the true value of W(X_i\rightarrow Y_j)W(Xi→Yj).
- \hat{w}_{i,j}^wi,j represents the estimation of the jurors.
- C_iCi represents a token which redeems for \frac{1}{c}1c if the weights of X_iXi children are evaluated, with cc being the number of nodes whose children are evaluated.
- W_{i,j}Wi,j represents a token which redeems for \frac{\hat{w}_{i,j}}{c}^wi,jc if the weights of X_iXi children are evaluated.
- \dot{w}_{i,j}˙wi,j represents the value of the token W_{i,j}Wi,j expressed in term of C_iCi.
Using the same logic as the two previous sections, we see that \dot{w}_{i,j}˙wi,j acts an estimator of w_{i,j}wi,j. Here the mechanism denoisifies and scales the evaluation of human jurors.
Juror Evaluation Strategy
Unlike regular prediction markets that resolve based on an objective truth in the world, these markets depend on subjective assessment by jurors. This not only adds more pressure on judges but also implies the need for a jury improvement track that’s as rigorous as the prediction mechanism improvement track.
While we haven’t fully formalized juror design, here are some broad considerations:
- The information presented to jurors is as important as selection of the jury itself. This can take the form of a juror UI that includes the ability to get summaries from various LLMs. Another option is to separate roles: analysts who dig deeply into a repo’s worth, and judges who use the information from the analysts to make the final evaluation.
- A related consideration is the mix of expertise within the jury. Some jurors may be domain specialists while others are generalists. Scores that are agreed upon by both specialized and generalized jurors should be given higher priority.
- There should be some method to identify and reduce the impact of outlier ratings from jurors. In its current phase, we have decided to use the Huber loss function for the multiscalar prediction market on Seer, and continue with the L2 norm in log-space for the competition on Pond, both in log-space, to process the pairwise comparisons from jurors.
Call to Action
- Model builders can participate in 3 competitions, which carry a prize pool and trading subsidies.
- Seed Nodes:
- The currently open deep funding contest lets participants propose weights for all 45 OSS repos that are either part of Protocol Guild, Argot Collective or the Dev Tools Guild. This competition will go on until October 6th.
- The same competition is also available as a multiscalar prediction market where anyone can bet on the value of a repo if it were to be evaluated. Unlike on Pond, the payout function here is not dependent on exogenous prize money but on the accuracy of your predictions vs the total amount wagered by all participants in the market.
- If you want to bet money on your models results, submit in the prediction market; if you just want to test your model without money, submit on Pond.
- Originality Score: Next month, you can predict the originality score that repos would receive if it were to be evaluated. This will indicate how much of the funding should remain with seed nodes versus passed on to its dependencies. To take part, simply build a model that makes originality score predictions, load it up with some money and let it make predictions.
- Child Nodes: The final segment is a competition on Pond for model builders to predict the weights between dependencies of seed nodes. The results of this competition can again be taken as the base rate for launching a multi-scalar market on the value of each dependency to a seed node.
- Seed Nodes:
- Jurors who want to provide comparisons between seed nodes can apply here to become a part of the jury.
- Maintainers: If you are a maintainer for repos that are part of Deep Funding, we need your help to:
- Create an accurate dependency graph, which includes identifying missing repos or removing irrelevant ones, and
- Submit scores indicating the importance between various dependencies in your repos, and you can apply here.
Lastly, if you simply want to follow along with the experiment, express your ideas or have further questions, please join the Deep Funding telegram group.
Appendix
A generalized structure for the directed dependency graph
Here, we propose a more formal, generalized version of what is described in the above specification. For each project P, we define three types of nodes that have edges directed into P.
P:SELF: This node represents the project’s own contributions.- The edge
P->P:SELFwith edgeWis interpreted as “Wis the share of credit attributed toP’s own work”. For example, the Brave browser might have a weight of 0.2 since it is a fork of chromium, while Solidity could have a weight of 0.8 as it aims to be dependency-minimized. This can also be called theoriginalityof a project. - This type of node does not have any children, and there’s only 1 for each
P.
- The edge
P:OTHER: Nodes of this type can be seen as the collective set of direct dependencies ofP. Under this type of node, we can further classify it into two subtypes:P:OTHER_KNOWN: These are known dependencies ofP, and are projects themselves.P:OTHER_UNKNOWN: This represents all unknown dependencies ofP.- This type of node does not have any children, and there’s only 1 for each
P.
- This type of node does not have any children, and there’s only 1 for each
Therefore, for any project with known dependencies (i.e. type P:OTHER_KNOWN) D_1,...,D_kD1,...,Dk, we have
Alternatively, we can also simply say
The following equations also hold
Note that here, we treat W(P \rightarrow D_i)W(P→Di) as the weight that has been scaled or normalized by P_{other\_known}Pother_known. The unscaled weight is W(P_{other\_known} \rightarrow D_i)W(Pother_known→Di).
As an example, if we reference again the following graph, we can see that:
Cypherpunk Movement->Cypherpunk Movement:SELF= 0.4Cypherpunk Movement->Cypherpunk Movement:OTHERS_KNOWN= 0.6Cypherpunk Movement->Cypherpunk Movement:OTHERS_UNKNOWN= 0Cypherpunk Movement:OTHERS_KNOWN->Swiss direct democracy= 0.050Cypherpunk Movement->Swiss direct democracy= 0.6*0.050 = 0.03
Source: deepfunding/scoring/example_output.png







{kind=link}