

This article is machine translated
Show original
In the AI era, core assets are memory and abstract thinking. After some trial and error, I finally got the "local memory + cloud LLM" architecture up and running.
Core idea: Memory is a core asset; it can't all be given to the cloud.
Input → Local Memory (Complete) → Filtering Layer → Cloud LLM → Auditing → Output
My approach consists of several layers:
1. Store complete memory locally* — Markdown file + local vector database
- Record everything, no filtering
- This is the "real me"
2. The cloud only retrieves the filtered context
- Sensitive information is stored separately, not included in the LLM context
- Output auditing — a check before sending.
👌
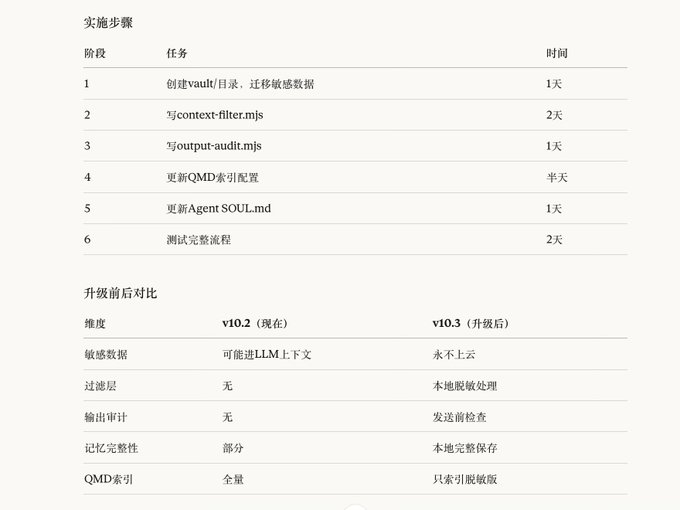
Send this prompt to the AI.
Execution Upgrade: Local Memory + Filtering Layer Architecture
Core Principle: Memory is a core asset; sensitive information should never be uploaded to the cloud.
== Security Rules (Highest Priority) ==
1. Test each step after modification to ensure the system functions correctly before proceeding to the next.
2. Do not modify multiple things simultaneously.
3. Back up configurations before making changes: cp openclaw.json openclaw.json.bak
4. x.com/bitfish/status…
It seems likely that in the future, terminal manufacturers like Apple will also be able to successfully implement local LLM edge computing models.
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content





