
ByteDance dropped its text to (scripted) video model, it's contextually aware, high fidelity, packed with scripted hooks.. West models are physics simulators vs this one is legit AI director
Compute constraints force optimization. The West has the chips. The East has the grit (and the data)
It creates better video from text than from reference images comp/ other models maybe due to ByteDance understands the semantic link between language and motion better than anyone (owning both Tiktok and Douyin)
Very likley ByteDance will be the only company to leverage both Chinese and English training in terms of token efficacy, so bullish in top chinese tech firms thriving through coercions coming from everywhere
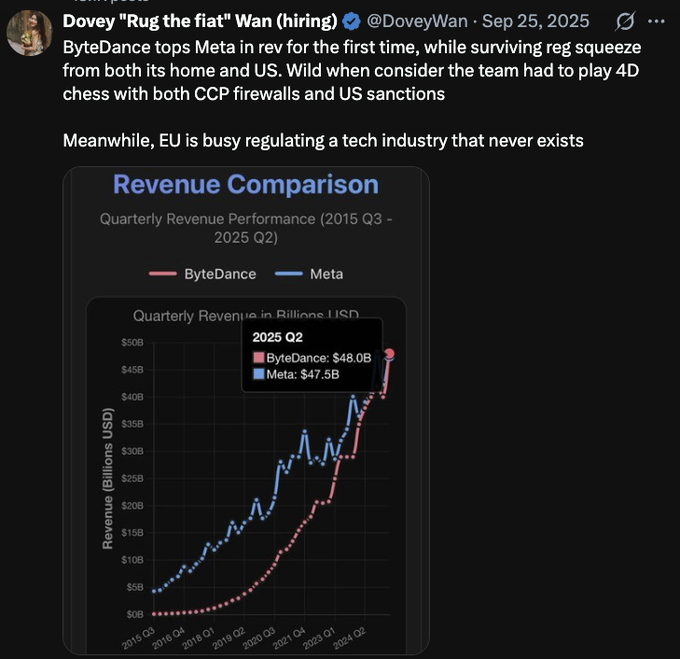
more UGC vid, pretty crazy level cinematic production and workflow optimization
Dorksense
@Dork_sense
Seedance 2.0 from China will be the SOTA
This is AI
We are cooked.
• Native multi-shot storytelling from a single prompt (no more stitching scenes)
• Phoneme-level lip-sync in 8+ languages
• 30% faster generation than v1 via RayFlow optimization • 1080p cinematic quality,
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content





