Many people use AI in their daily lives, yet they don't pay attention to how their data is processed. Nesa raises a question that raises awareness of this indifference.
Key Takeaways
Now that artificial intelligence has become a part of our daily lives, people upload a lot of data without hesitation, but they overlook the fact that the data actually passes through a central server.
Even the acting director of the CISA, which is responsible for US security, exposed classified documents to ChatGPT.
To address this, NESA uses data transformation (EE) before data transmission and node-to-node partitioning (HSS-EE) to ensure that no party can see the original.
Nessa is technologically advanced through substantial academic verification and has secured use cases from large corporations such as P&G.
However, the overall market prefers centralized APIs from big tech companies, so it remains to be seen whether more clients will adopt decentralized privacy AI in the future.
1. Is the data you entered safe?
In January 2026, it was revealed that Madhu Gottumukkala , the acting director of the Cybersecurity and Infrastructure Security Agency (CISA), the U.S. cybersecurity agency, had uploaded sensitive government documents to ChatGPT for the simple purpose of summarizing and organizing contract-related documents.
Of course, the content was not stored within ChatGPT and reported to the government. This is a case where the content was detected by the company's own security system and investigated for violating security regulations.
Even the US National Security Agency uses AI routinely, even uploading classified documents.
User-entered data is encrypted, so it's safe. True, the data is explicitly encrypted. However, it's actually structured so that it can be decrypted. Information can be provided only with a valid warrant or in an emergency, but we don't know what happens behind the scenes.
Be the first to discover insights from the Asian Web3 market, read by over 23,000 Web3 market leaders.
2. Nesa: AI for Privacy in Everyday Life
AI is already a part of our daily lives. It's deeply embedded in everything from summarizing articles to writing code and even writing emails. What's even more alarming is that, as in the case above, we're entrusting confidential documents and personal information to AI without much caution.
The crux of the problem is that all of this data passes through the service provider's central server. Even if it's encrypted, the service provider holds the decryption key. How can we trust this?
User input data can be exposed to third parties through various channels, including model improvement, security reviews, and legal requests. For corporate plans, organization administrators can access chat history, and even for personal plans, data can be accessed with a warrant.
As AI becomes deeply embedded in our daily lives, it's time to re-examine privacy.
Nesa is a project that aims to change this very structure. It creates a decentralized infrastructure that enables AI inference without entrusting data to a central server. User input data is processed in an encrypted form, and no node can view the original data.
3. How does Nessa solve this?
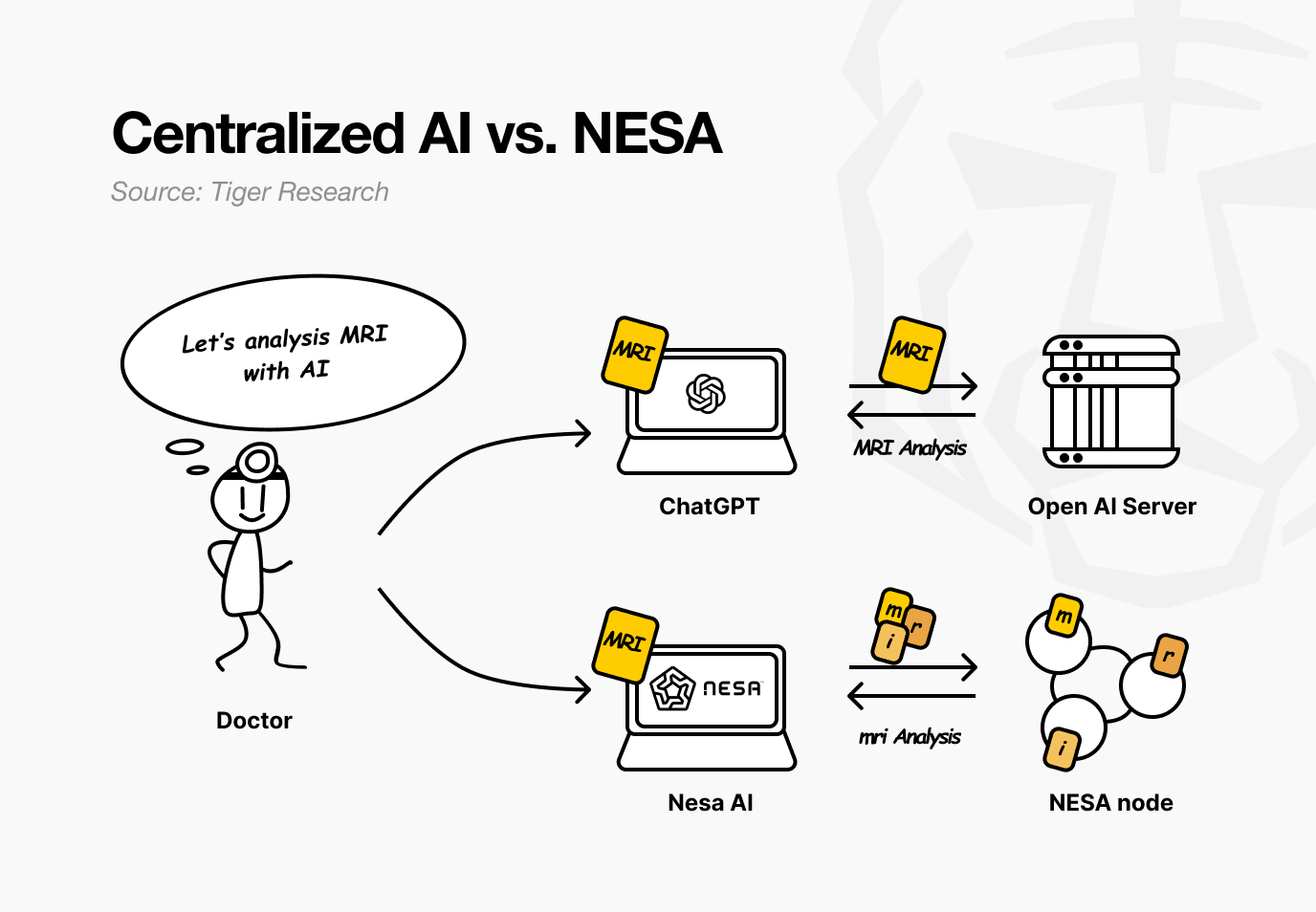
Let's say there is a hospital that uses NESA.
A doctor wants to diagnose a patient's MRI image for tumors. With current AI services, the image is simply transmitted to OpenAI or Google servers. But with NESA, the image is transformed using specific rules before leaving the doctor's computer.
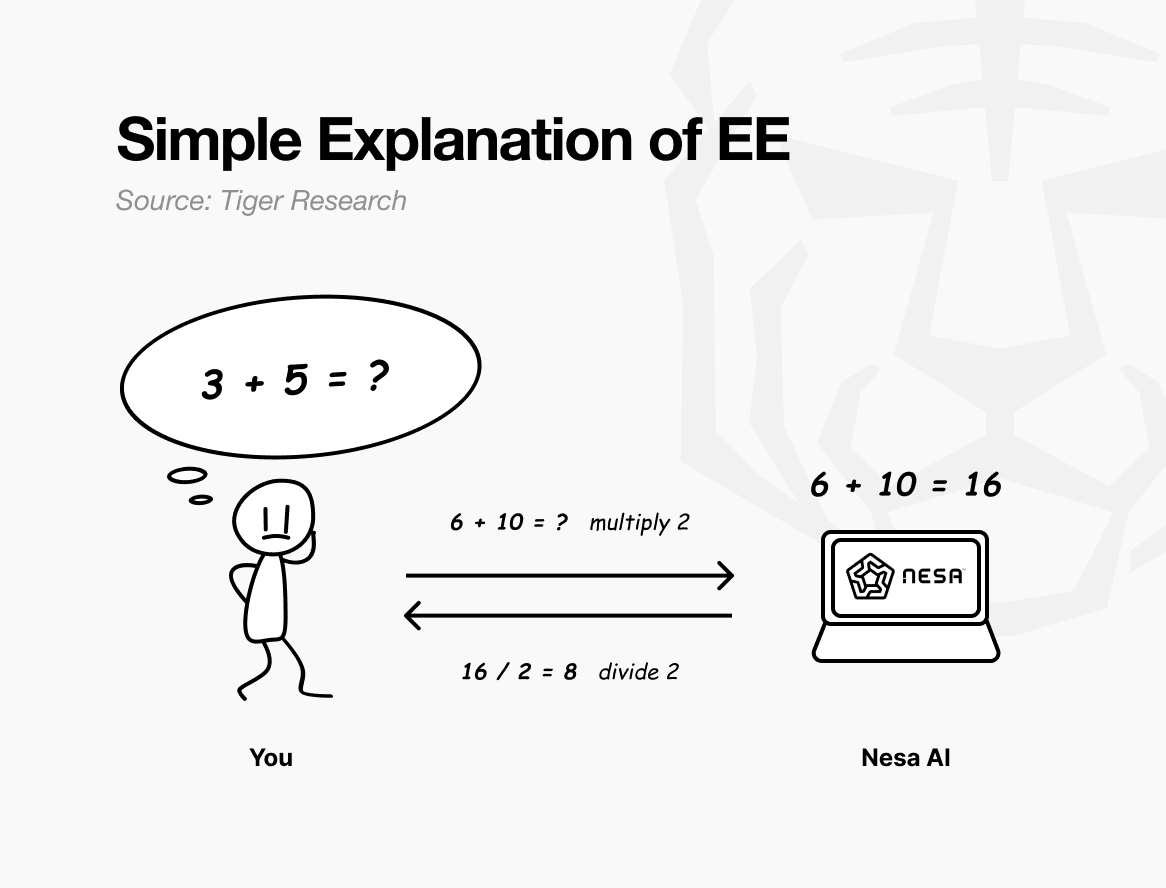
To put it simply, let's think about a math test. Let's say the original question is "3 + 5 = ?" If you show this problem to someone else, they'll immediately know what calculation you're trying to do.
But if you multiply all the numbers by 2 before sending, the problem the other person receives becomes “6 + 10 = ?” The other person solves this and returns the answer as 16.
I apply ÷2 again and get 8. This is the same answer as if I had solved the original problem. The other person did the calculation for me, but they didn't know that my original numbers were 3 and 5.
This is precisely what Nesa's Equivariant Encryption (EE) does. Before sending data, it transforms it according to a set of mathematical rules. The AI model then performs calculations on the transformed data. When the user applies the reverse transformation to the result, the result is the same as when the original data was input. This property is called equivariance in mathematics, meaning that the final result is the same whether the transformation or the calculation is performed first.
In practice, rather than simple rules like ×2, complex transformations tailored to the AI model's internal computational structure are used. The key is not to randomly shuffle data, but to apply rules that mesh with the model's computational flow. Therefore, even when the model processes transformed data, the resulting accuracy remains intact.
Back at the hospital, the doctor feels nothing. The process of uploading images and receiving results remains the same. What's different is that no node in the process can see the patient's original MRI.
NESA goes one step further. While EE alone prevents nodes from viewing the original data, the transformed data itself resides entirely on a single server. HSS-EE (Homomorphic Secret Sharing over Encrypted Embeddings) is a technology that splits even this transformed data.
Let's go back to our math test analogy. EE applied the ×2 rule to the test papers they sent. HSS-EE takes this a step further. The test paper, with the rule applied, is torn in half, with the first half sent to A and the second half sent to B. A solves only his/her own part, and B solves only his/her own part. Neither party can see the entire problem. The complete result is obtained only when the two answers are combined, and only the sender can combine them.
In summary, EE is a technology that "converts data so the original data is invisible," while HSS-EE "splitting even the converted data so it's not collected in a single location." This structure provides double privacy protection.
Strengthening privacy means slowing down. This is a long-standing principle in cryptography. The most widely known, fully homomorphic encryption (FHE), is 10,000 to 1,000,000 times slower than standard computation. This makes it impractical for real-time AI services.
Nesa 's isomorphic encryption (EE) is different. Returning to the math test paper analogy, the additional cost of applying ×2 and then later reverting to ÷2 is minimal. This is because, rather than completely transforming the problem into a different mathematical framework like FHE, it's a structure that simply adds a light transformation to the existing calculation.
EE (Equivalent Encryption): Based on LLaMA-8B, delay time increase less than 9% (accuracy is 99.99% or more of the original)
HSS-EE (distributed encryption): 700-850 milliseconds per inference based on LLaMA-2 7B
Here, a meta-learning scheduler called MetaInf controls the efficiency of the entire network. This system automatically selects the fastest inference technique based on model size, GPU specifications, and input characteristics. Compared to existing machine learning-based selectors, it achieved 89.8% accuracy and a 1.55x acceleration rate. It was also presented at the COLM 2025 conference, further confirming its academic validity.
The above figures are from a controlled testing environment. However, NESA's inference infrastructure is already in use in real enterprise environments, demonstrating real-world performance.
5. Who writes and how?
There are three main ways to approach Nessa.
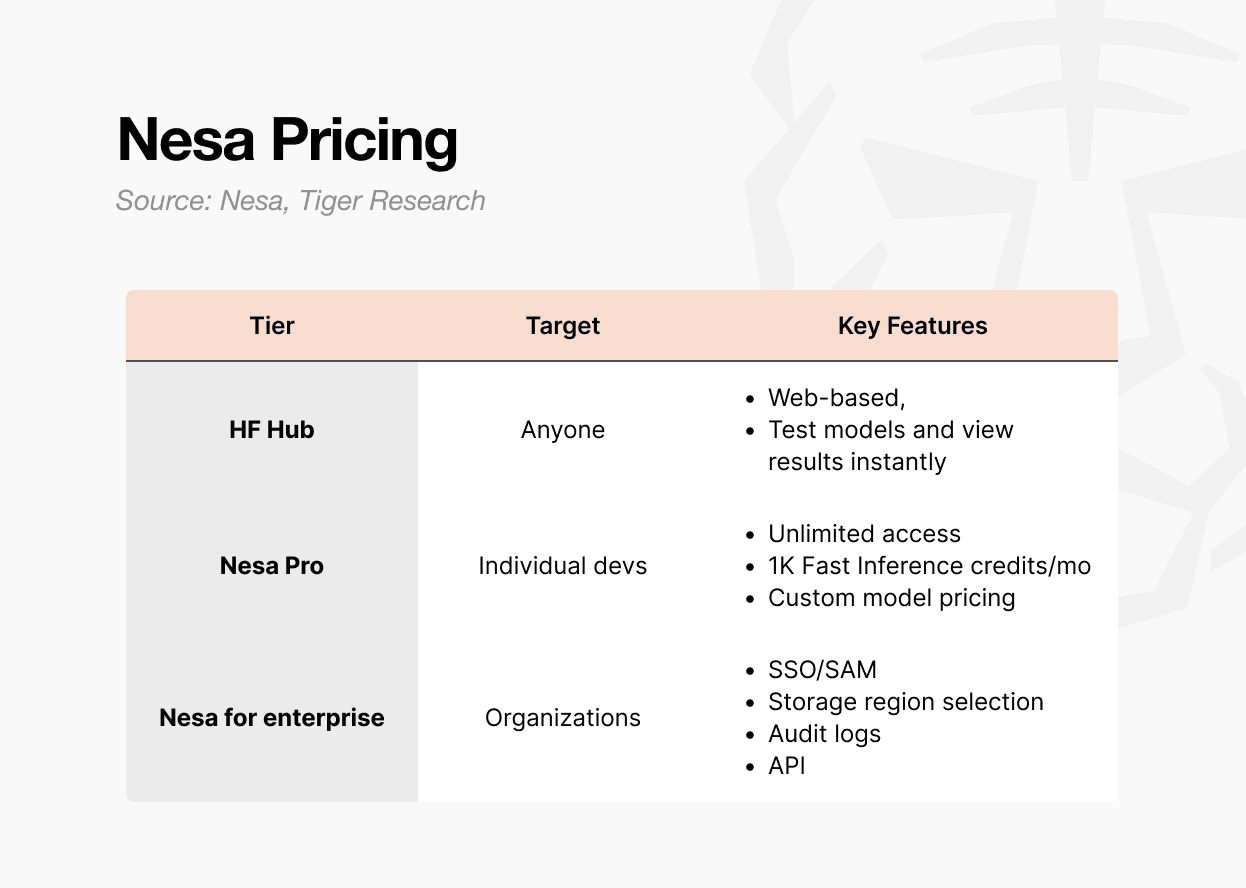
The first is Playground. This is an environment where you can select and test models directly from the web. You don't need to be a developer to use it. You can experiment with inputs for each model and see the results. It's the fastest way to see firsthand how decentralized AI inference actually works.
The second option is the Pro subscription. For $8 per month, it includes unlimited access, 1,000 Fast Inference credits per month, the ability to set custom model pricing, and model Featured page exposure. This plan is ideal for individual developers or small teams looking to upload and monetize their own models.
The third option is Enterprise. This is a separate contract structure, not a public plan. It includes SSO/SAML support, storage region selection, audit logs, granular access control, and annual commitment-based billing.
Pricing starts at $20 per user per month, but actual terms are negotiated based on scale. This structure is designed for companies looking to integrate Nessa into their internal AI pipelines, with APIs available through a separate contract and management at the organizational level. Furthermore, it's already being used by major corporations like P&G.
To summarize, if you want to try it out lightly, choose Playground, if you want to develop individually or on a small scale, choose Pro, and if you want to introduce it at the organizational level, choose Enterprise.
Decentralized networks lack a central administrator. Both the entities running the servers and the entities verifying the results are scattered across the globe. This raises the question: Why do these individuals power up their GPUs and process AI inference for others?
The answer is economic rewards. On the NESA network, the reward is the $NES token .
The structure is simple. When a user requests AI inference, a fee is charged for that request. Nesa calls this "PayForQuery." It consists of a fixed fee per transaction and a variable fee proportional to the data size. Higher fees are prioritized for processing, similar to gas fees in blockchain.
The recipient of these fees is the miner. Miners must stake a certain amount of $NES to participate in the network. This structure requires them to stake their own money to entrust work. If they produce incorrect results or fail to respond, a penalty is deducted from their staked tokens. Conversely, if they process accurately and quickly, they receive greater rewards.
It also serves as a governance tool that determines the direction of the network. $NES Holders can propose and vote on core network parameters, such as the fee structure and reward rate.
In summary, $NES serves three purposes: it serves as a means of payment for inference requests, acts as collateral and rewards for miners, and participates in network governance. Tokens are required for nodes to operate, and nodes must operate for privacy AI to function.
However, there's one point worth noting: for a token economy to function as designed, there are prerequisites.
There must be sufficient demand for inference to ensure meaningful rewards for miners, meaningful rewards to keep miners, and sufficient miners to maintain network quality.
Ultimately, demand drives supply, and supply, in turn, supports demand, creating a virtuous cycle. However, the initial stages of this cycle are the most challenging. While it's encouraging that enterprise customers are currently using it, it remains to be seen whether the balance between token value and mining rewards will be maintained as the network scales.
The problem NESA is trying to solve is clear: it wants to change the structure in which data is exposed to third parties when using AI.
The technical foundation is solid. Core encryption technologies, such as equivariant encryption (EE) and HSS-EE, originated from academic research, and the inference-optimized scheduler MetaInf was presented at the COLM 2025 plenary session. This structure goes beyond simply citing papers; researchers directly design the protocol and implement it on the network.
Among decentralized AI projects, it's rare to see a paper-level validation of proprietary cryptographic primitives and their deployment on a real-world infrastructure. The fact that enterprise customers like P&G are running inference on this infrastructure is a significant signal for such an early-stage project.
However, the limitations are also clear.
First, the breadth of the target market. Realistically, this technology will first take hold in institutions. It will still take time for general users to recognize AI privacy and even pay for it. In the retail market, privacy is a "nice-to-have," not something worth paying for. Ultimately, Nesa's growth at this stage hinges on consistently securing institutional customers, which is by no means an easy task.
Second, product usability. While Playground is a space where users can experience models firsthand, its current configuration closely resembles a Web3 service designed to attract investment. It's a far cry from the AI services we use on a daily basis.
Third, validation of scale. Benchmarking in a controlled environment is different from a production environment with thousands of nodes running simultaneously. Whether the network can maintain the same performance when fully scaled is a separate issue.
Fourth, market timing is crucial. While institutional demand for privacy AI is clear, whether that demand extends to "private AI on decentralized infrastructure" is another matter. Most companies are still accustomed to centralized APIs, and the barrier to entry to blockchain-based infrastructure remains high.
We live in an era where even the US National Security Agency is uploading classified documents to AI. The demand for privacy-focused AI already exists and will only grow over time. NESA possesses academically proven technology and a working infrastructure to address this demand. While it has limitations, it's a head start compared to other projects.
When the privacy AI market fully opens, it will be one of the first projects to be named.
이번 리서치와 관련된 더 많은 자료를 읽어보세요.
Disclaimer
This report was partially supported by Nesa, but was independently researched and based on reliable sources. However, the conclusions, recommendations, forecasts, estimates, projections, objectives, opinions, and views in this report are based on information current at the time of preparation and are subject to change without notice. Accordingly, we are not responsible for any losses resulting from the use of this report or its contents, and we make no express or implied warranties regarding the accuracy, completeness, or suitability of the information. Furthermore, the opinions of others or organizations may differ from or be inconsistent with those of others. This report is provided for informational purposes only and should not be construed as legal, business, investment, or tax advice. Furthermore, any reference to securities or digital assets is for illustrative purposes only and does not constitute investment advice or an offer to provide investment advisory services. This material is not intended for investors or potential investors.
Terms of Usage
Tigersearch supports fair use in its reports. This principle allows for broad use of content for public interest purposes, as long as it doesn't affect commercial value. Under fair use, reports can be used without prior permission. However, when citing Tigersearch reports, 1) "Tigersearch" must be clearly cited as the source, and 2) the Tigersearch logo ( in black and white ) must be included in accordance with Tigersearch's brand guidelines. Republishing materials requires separate consultation. Unauthorized use may result in legal action.