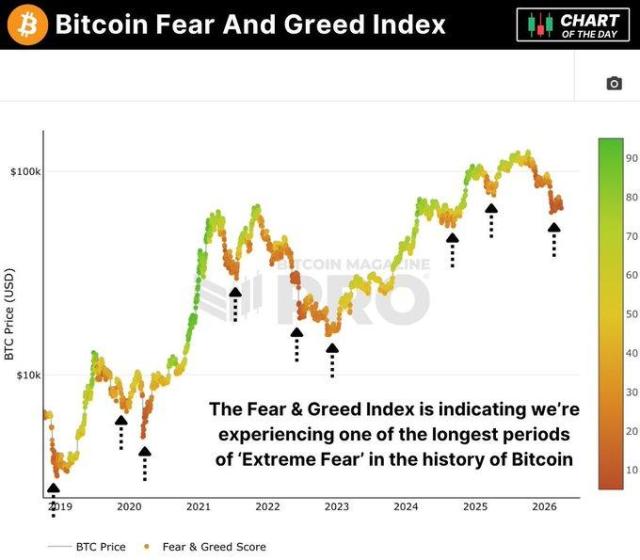
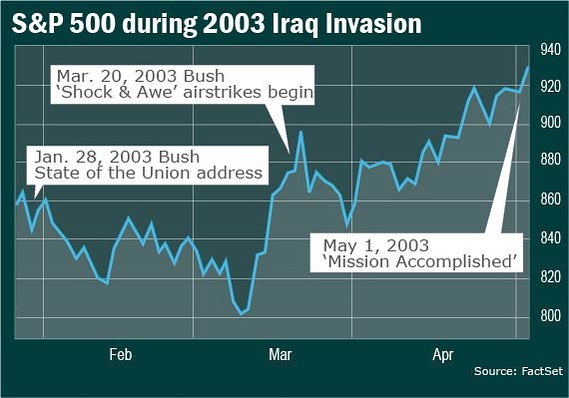
This article is machine translated
Show original
The next-generation LLM benchmark should no longer be run on swe-bench lite/verified/pro/ultra.
Instead, it should be a closed, separate, and randomly selected platform each month, finding 5000 issues on GitHub, running them with the same harness on all models, and having a referee agent write test cases to determine success.
Since the issues are randomly selected, there's no need to worry about the number or percentage of resolved issues; just look at the relative ranking.
This eliminates concerns about using swe-bench for fine-tuning or even cheating, and removes uncontrollable factors like vendor A being able to reproduce the problem while vendor B cannot, or vendor C cherry-picking the best result.
Everyone only needs to look at the latest official leaderboard ranking for the month.
This is far superior to the previous method of running two models simultaneously and having users manually vote on whether the left or right side was better.
Note that this ranking's longitudinal comparison is meaningless. Perhaps model A, ranked first in March, solved 60% of the problems, while model B, ranked first in April, only solved 40%, because the issues in March and April are completely different, making longitudinal comparisons unnecessary.
Just look at the relative rankings for this month.
This is the real cyber cricket fighting.
From Twitter
Disclaimer: The content above is only the author's opinion which does not represent any position of Followin, and is not intended as, and shall not be understood or construed as, investment advice from Followin.
Like
Add to Favorites
Comments
Share
Relevant content